
This is a guest post from Mateo Rojas-Carulla, CTO at Lakera AI
Introduction to the Model Robustness Experiment
Model selection is a fundamental challenge for teams deploying to production: how do you choose the model that is most likely to generalize to an ever-changing world?
In this blog post, we will focus on two aspects of model selection:
- Given multiple models with similar test mAP, which model should you actually deploy? Are all mAPs created equal?
- Adding augmentations is an important tool for building reliable models. When you add augmentations to your models, do they always have the desired effect (e.g., does adding blur always protect against blur)? And do they lead to "better" models?
To answer these questions, we trained models with different augmentation strategies using the Roboflow platform, and stress-tested the robustness of these models using Lakera’s MLTest.
TL;DR:
- Aggregate test metrics like mAP are helpful but they do not tell the whole story. Two models with the same mAP can have very different behaviors in production. Extensive robustness analysis can help to successfully choose between these models.
- Augmentation strategies should be tested as part of the development process. Sometimes, adding no augmentations at all can lead to a better model. As we will see, sometimes adding the augmentation can make the model worse with respect to that augmentation! This has big implications for operational performance. Again, the mAP score doesn't tell the whole story.
- Model robustness scoring, which you can do with Lakera’s MLTest, goes deeper and allows you to differentiate between models that look otherwise identical. It will tell you if the augmentations you have added are having the desired effect; if not, it will let you know which augmentations you need to focus on in your next training iteration.
What is Model Robustness Testing?
Lakera’s MLTest looks for vulnerabilities in computer vision systems, and helps developers identify which models will generalize to production during development.
Probing for generalization requires multiple angles of attack, from analyzing the robustness of the model, to understanding data issues (such as mislabeled images) or model failure clustering and analysis. For the purpose of this experiment, we focus only on robustness analysis.
First, what do we mean by the model’s robustness? To ensure performance in production, you’ll want to stress test your model by directly modifying your dataset in ways that are likely to affect the model in production, such as changes in image quality and lighting. This stress testing answers a fundamental question: how does my model behave when the data starts to deviate from the training distribution in ways that I can realistically expect to see in production?
While knowing how brittle a model is provides important signals, robustness scores can tell us much more about a model. It provides a strong indicator of a system’s ability to generalize: if a system breaks down under mild deviations from the original training distribution, it is likely to fail under the variations it will undoubtedly face in production. Common pre-trained backbones have very different robustness properties, which may end up being inherited by your fine-tuned model.
Let’s look at what this means for a few models trained on the Roboflow platform.
How to Test and Understand Model Robustness
In this section, we take you step by step through running MLTest on Roboflow models.
We start from a simple quest, standard for developers building product computer vision systems:
- Train a few models with different augmentation strategies.
- Select the model most likely to generalize to the production environment.
We want to dig deeper into these models: can we tell these models apart, and how do they differ? What implication does this have for you when selecting the best models to ship into the world?
We give a detailed overview of the experiments so that you can also run MLTest on your own Roboflow models to select better models in the future.
Select a Dataset
To get started, we need to select a dataset. We used the Construction Site Safety Dataset, which represents several of the challenges faced by teams aiming to ship a reliable system to their customer, with multiple customer sites, a constantly changing environment, etc.
To run MLTest with Roboflow, you will need to download the dataset to your machine. The train/validation/test split for this dataset looks as follows:
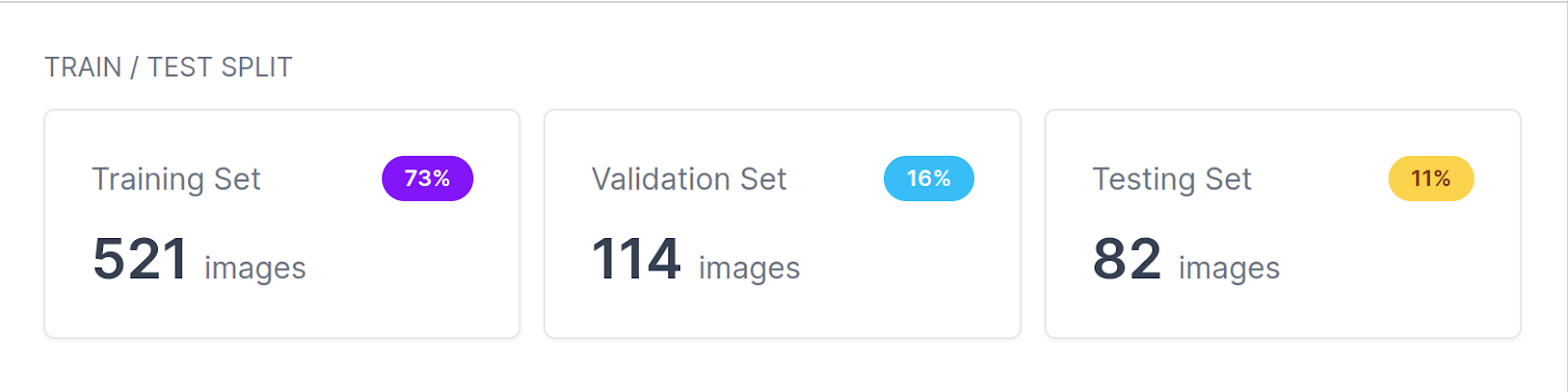
Train a Model with Roboflow
The next step is to create a project of your own. We created a brand new project and copied all the data from the original site safety dataset. We can train our first model by going to the Generate tab.
All models were trained with the Accurate model, which trains for longer. The models were then deployed using Roboflow’s hosted API.
For the purpose of this experiment, we trained three models with different augmentation strategies. All augmentations use the default parameters. Let’s look at these three models in a bit more detail.
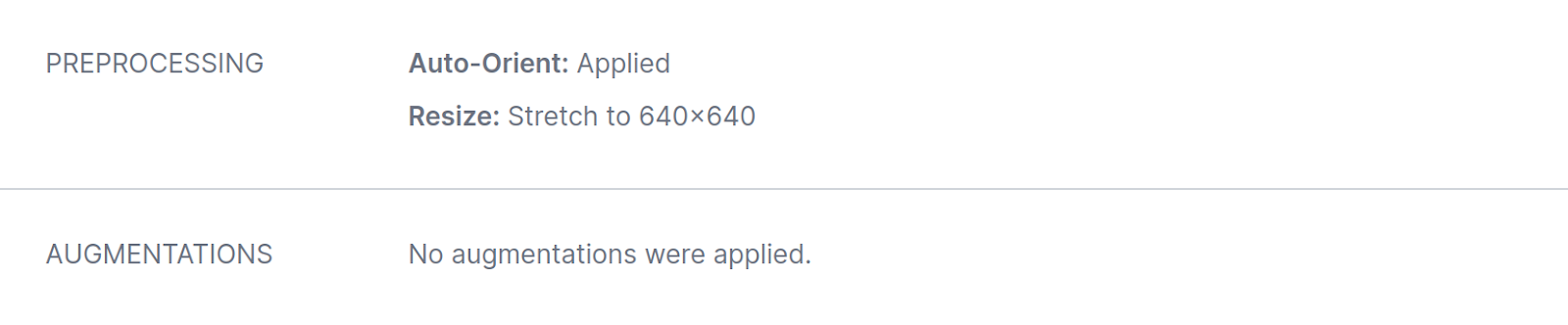
Model A was trained using an RF-DETR backbone, with no augmentations added to the model:
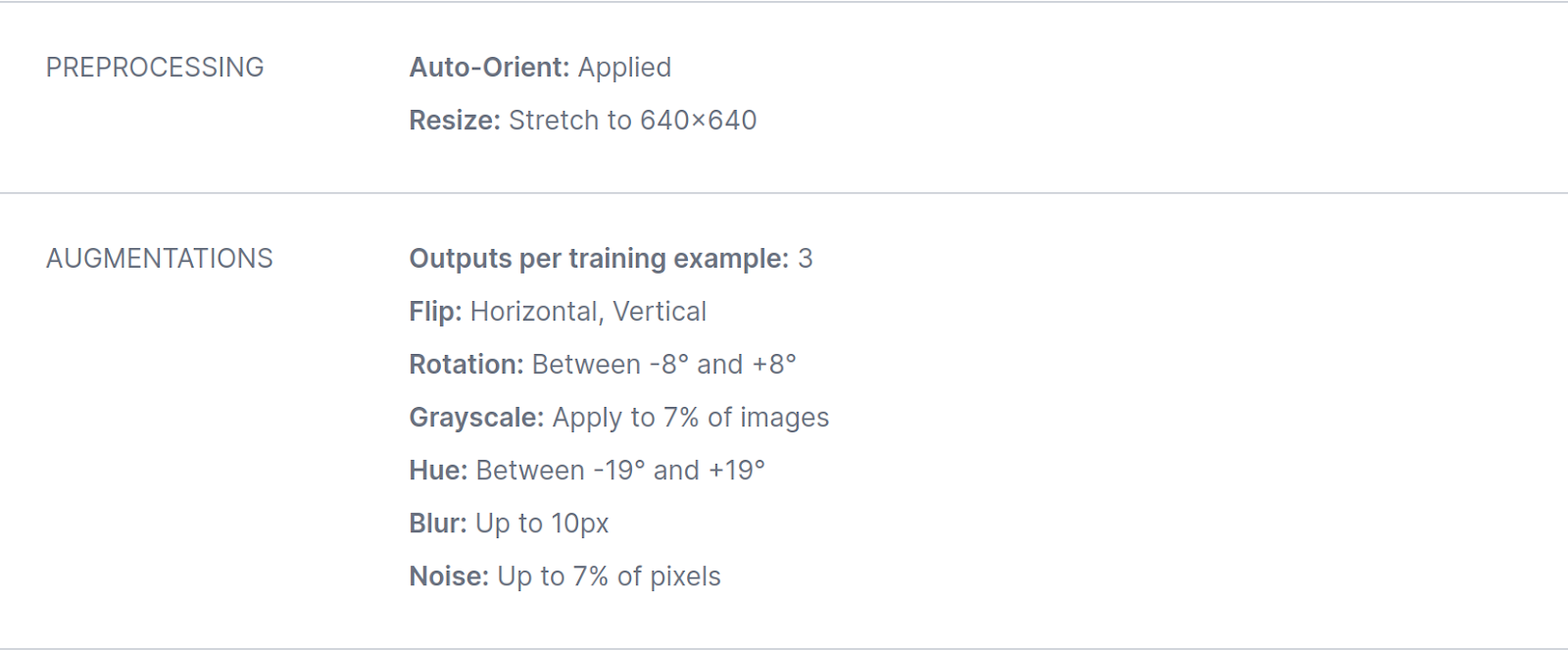
Model B was trained using an RF-DETR backbone, with several augmentations added during training:
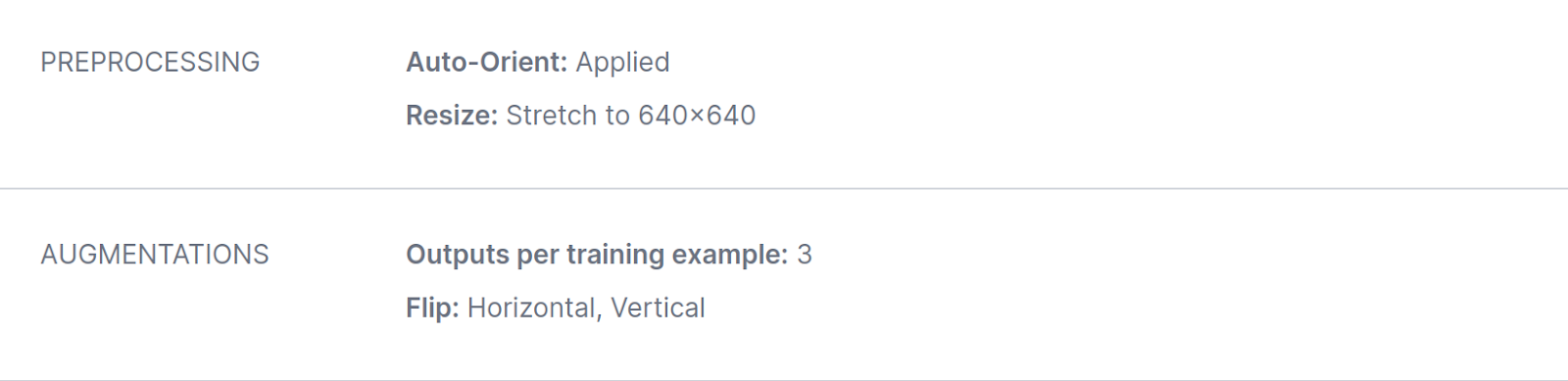
Finally, Model C was trained starting from the checkpoint from model A, while also adding a targeted augmentation - vertical and horizontal flips:
Standard Model Metrics
Let’s take a look at the test mAPs for all three models, both overall and by individual class. As you can see, there is little difference between the three models. There are some discrepancies for the different classes, but all models have a mAP around 0.5.
Are these models created equal, have they learned the same behaviors? Are there any differences hiding between these numbers?
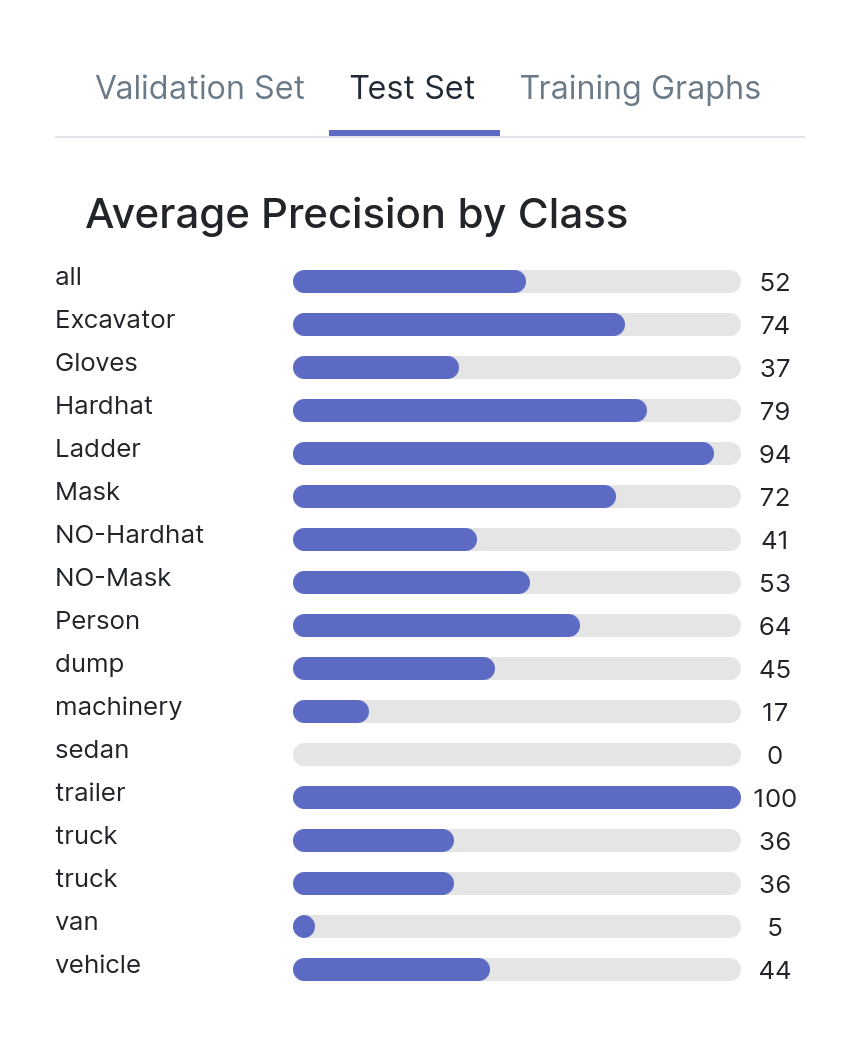
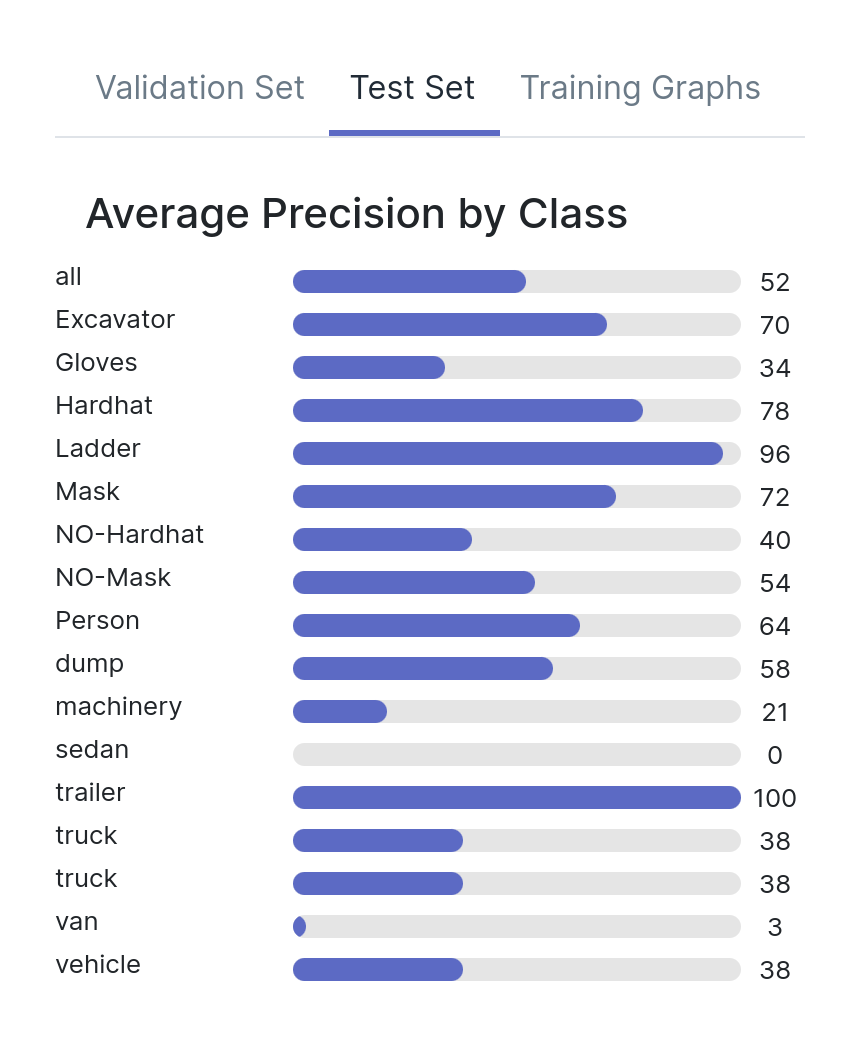
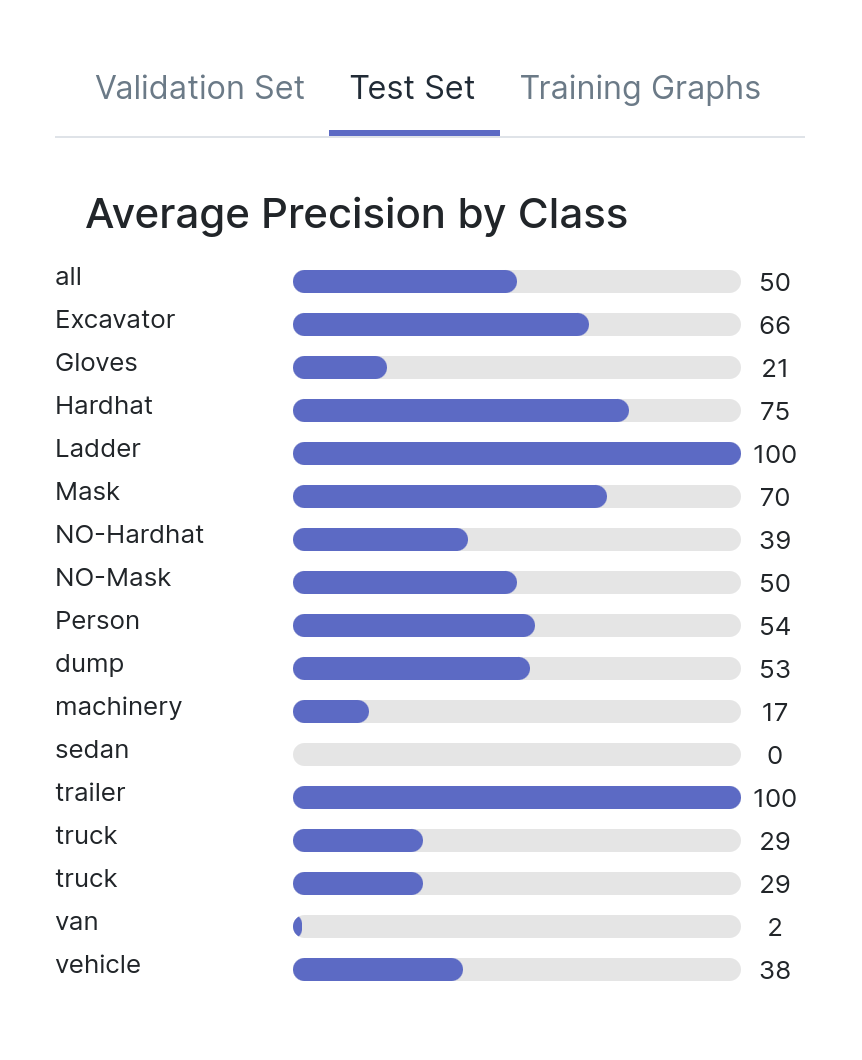
Model A, Model B, Model C
Robustness Scoring Unveils Deeper Insights
To see model robustness, we will use MLTest which is straightforward and requires writing two simple classes, a RoboflowDataset which indicates how to read the images and their labels, as well as a RoboflowAPIPredictor which, given an input image, queries Roboflow’s hosted API. You can find all the code required to run MLTest in this repository. You can also explore all the results from this experiment in this hosted dashboard
Remember that all three models here had roughly the same mAP, so distinguishing them based on standard test metrics, even by class, was difficult. Here’s what MLTest had to say about these models.
Model A and model B are not created equal. They have the same risk score and aggregate metrics, indicating that the overall, average robustness of the model did not improve despite the extensive augmentation strategy.
However, the side-by-side comparison below (in the images below: A on the left, B on the right) shows you that both models behave differently depending on the type of the augmentation:
- Model B became more robust to geometric transformations and blur, indicating a positive effect of the transformation strategy.
- However, model B also responds much worse to diverse types of noise in the image, even though corresponding augmentations were added during training!
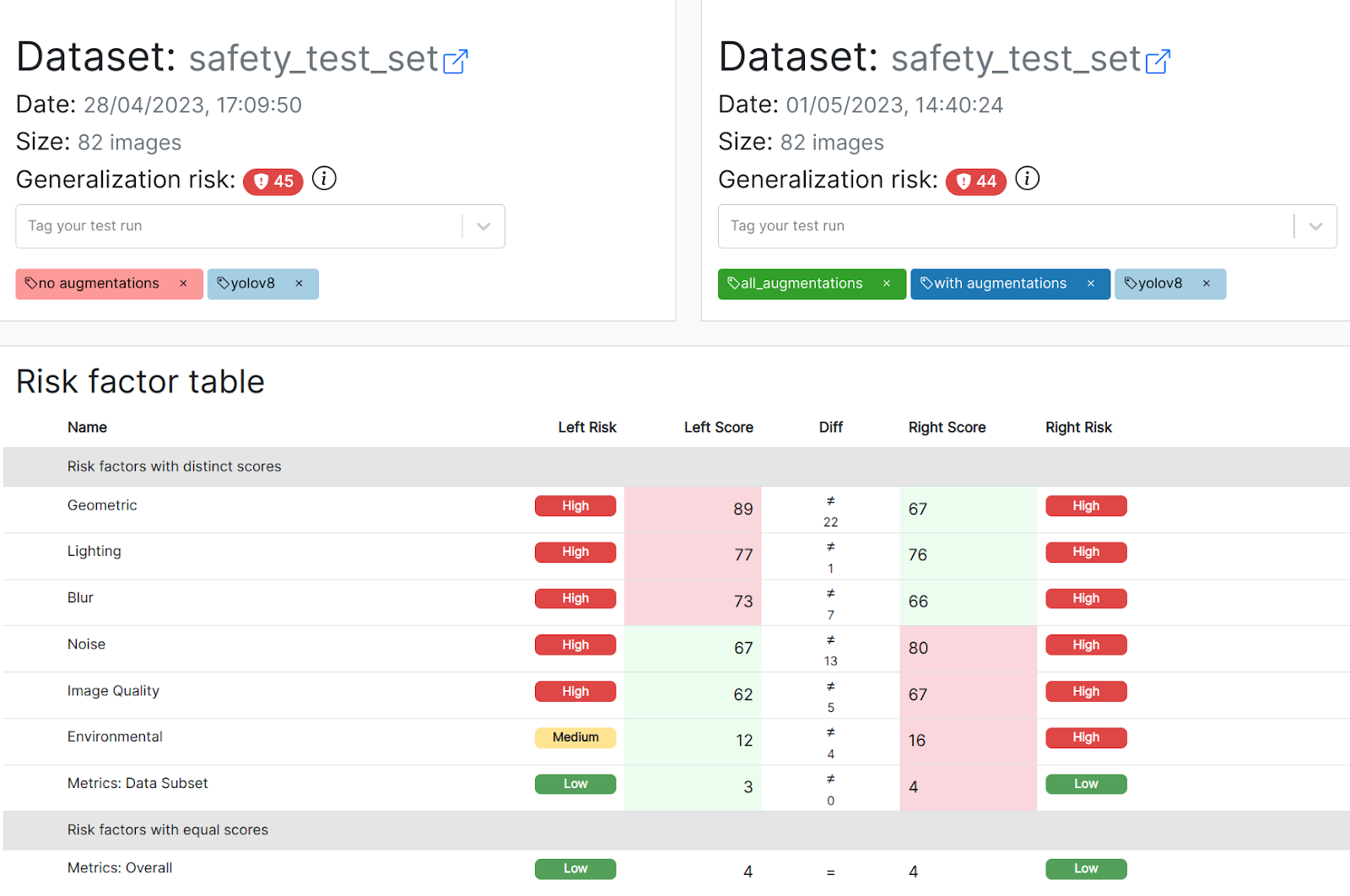
In other words, depending on the attribute most likely to appear in production, you would certainly prefer one model over the other. For example, if you expect blur artifacts to be faced in production, model B is superior. Without these insights, these models would seem the same based on mAP.
As a natural next step, we could go back to the Roboflow platform, and train a model where we more aggressively add noise augmentations. We could then use MLTest to verify that we preserve the properties we gained on the first augmentation round, while also becoming more robust to noise in the input.
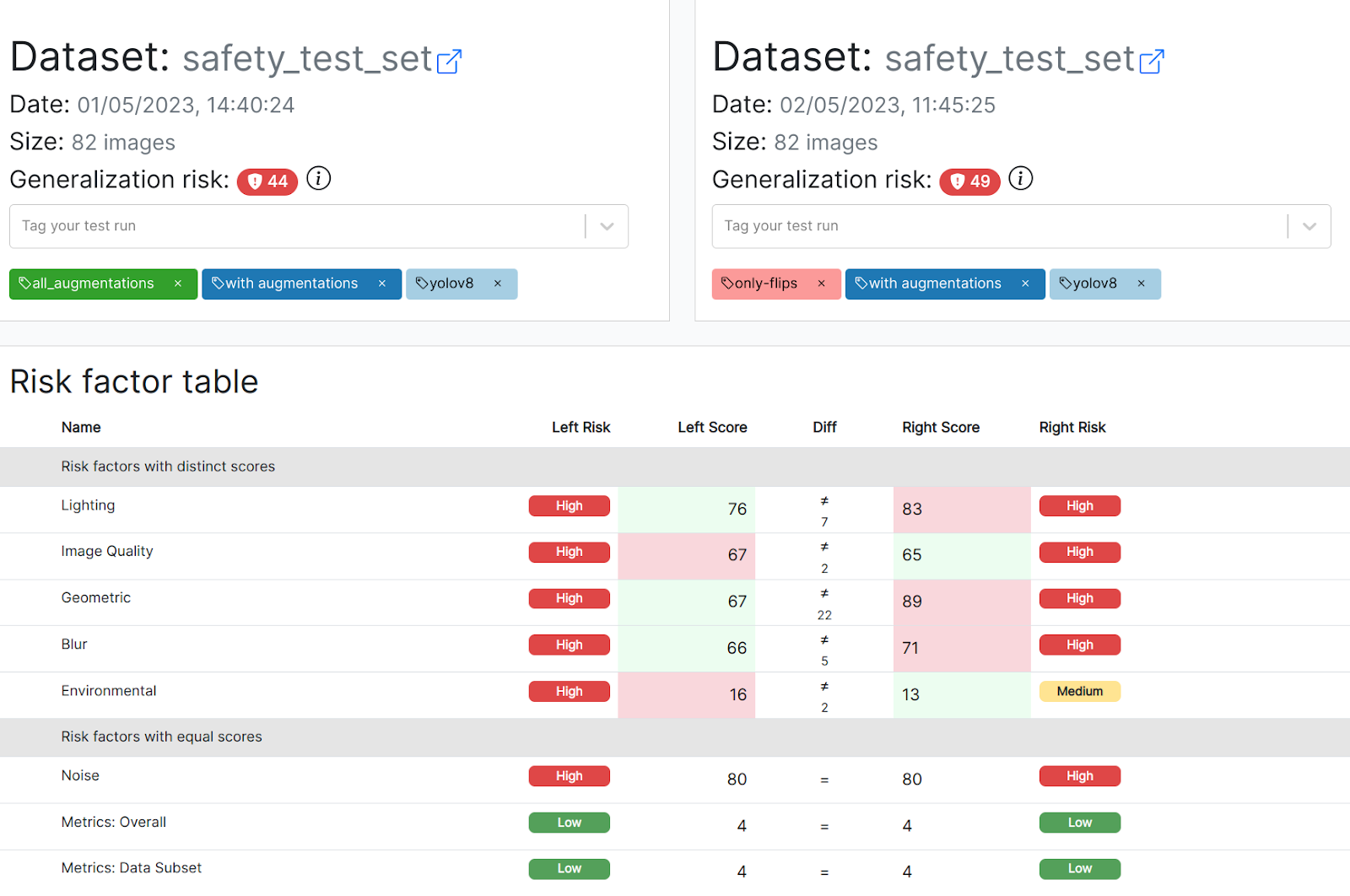
Model C, which adds horizontal and vertical flips during training, performs worse across the board compared to model B, including on flips! The model’s generalization risk score is over 10% worse than model B (44 -> 49). Between these two models, it is clear that the non-augmented model is safer to deploy to production. The following comparison shows B on the left, C on the right.
Examples of Model Failures with Augmentations
The following is a small selection of images where the model’s behavior changes considerably after the images have been modified. Here for example, the model correctly identifies a person and the lack of a safety vest on the original image. However, the whole person is missed by the model on the modified image!

Similarly, in the following image all objects that are identified on the original image are missed in the modified image.

Conclusion
Two key takeaways from our model robustness experiment:
- Test metrics are a rough indicator of the behaviors that your model has learned. Even models that are indistinguishable based on these metrics have learned different behaviors, and some are clearly more likely than others to fail in production.
- Finding the right augmentation strategy for your model is key to success. However, the strategy should be thoroughly validated throughout deployment: adding augmentations can have unintended effects, and can even make models worse than not augmenting the dataset at all. A robust model is more likely to generalize and thus cope well with the challenging environments encountered in production.
What does this mean for you? MLTest can become an integral part of your development workflow with Roboflow, showing you whether your augmentation strategies are having the intended effect for each new model that you train.
Once you have a snapshot of your model’s robustness produced by MLTest, you can then go back to the Roboflow platform and add a new set of augmentations, or modify how many images are augmented during training, or how strong the augmentation is. As a result, you can expect a model much better prepared to handle the changes it will encounter in production. Getting started with MLTest is easy, simply fill in this form.
Cite this Post
Use the following entry to cite this post in your research:
Trevor Lynn. (May 17, 2023). Not All mAPs are Equal and How to Test Model Robustness. Roboflow Blog: https://blog.roboflow.com/how-to-test-model-robustness-computer-vision/