
Update: On December 13th, 2023, Google released access to Gemini. Read our post testing Gemini across different tasks or explore Gemini's capabilities using your Google API key.
On December 6th, 2023, Google announced Gemini, a new Large Multimodal Model (LMM). Referred to by Google as their "largest and most capable AI model", Gemini is able to interact with and answer questions about data presented in text, images, video, and audio.
Gemini can be used directly through the Google Bard interface or through an API. Support has been launched for using Gemini with text queries through the web interface. Multimodal support, and API support, is expected over the coming weeks and months.
In this guide, we are going to discuss what Gemini is, for whom it is available, and what Gemini can do (according to the information available from Google). We will also look ahead to potential applications for Gemini in computer vision tasks.
Without further ado, let's get started!
What is Gemini?
Gemini is a Large Multimodal Model (LMM) developed by teams across Google, including the DeepMind research laboratory and Google Research. Gemini can answer questions about images, text, video, and audio ("modalities" of data).
Google has conducted extensive evaluations on the Gemini model, reporting that performance "exceeds current state-of-the-art results on 30 of the 32 widely-used academic benchmarks used in large language model (LLM) research and development."
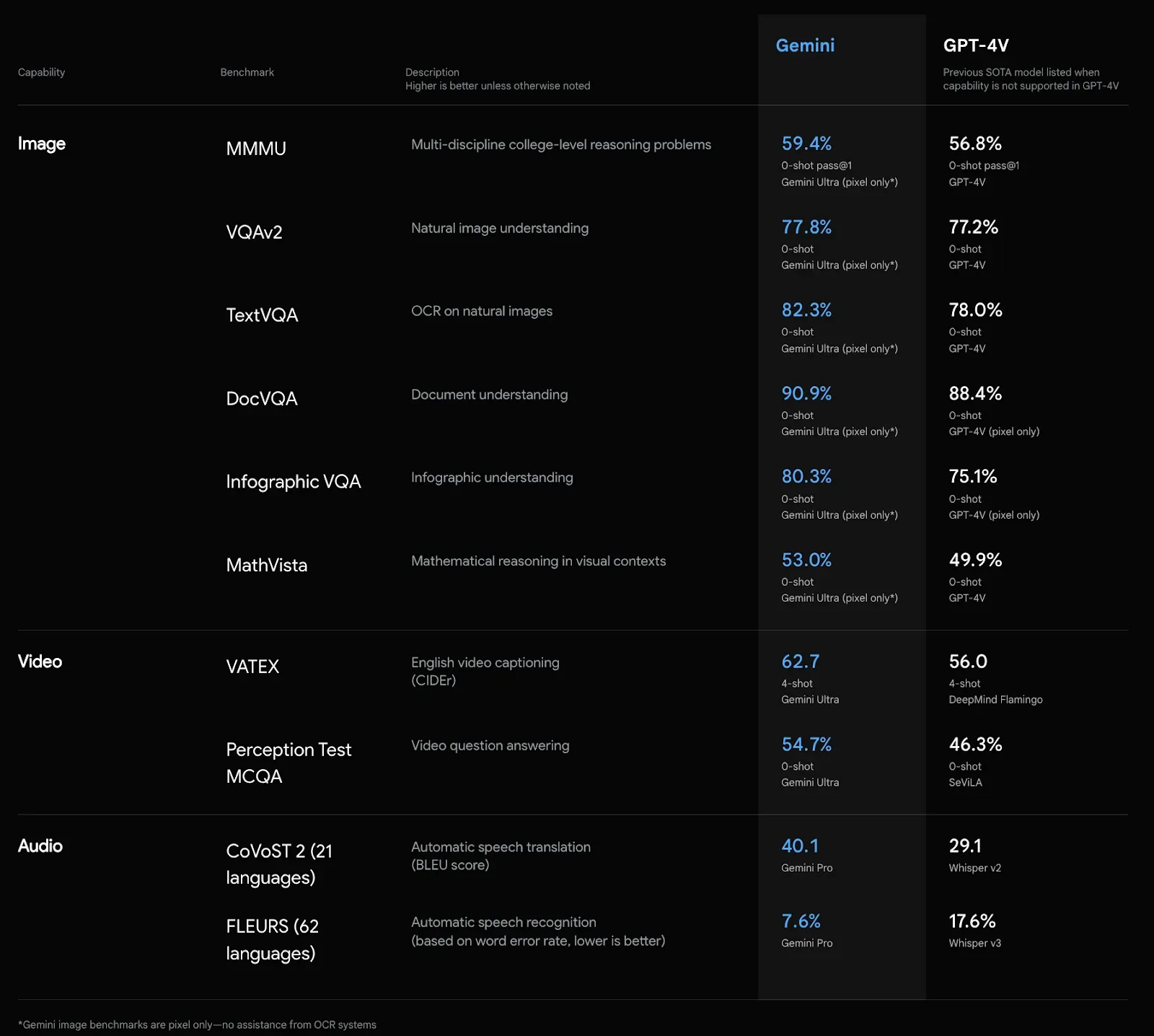
These benchmarks include Big-Bench Hard, used to evaluate multi-step reasoning, HumanEval, used to evaluate a model's ability to generate Python code, and VQAv2, which evaluates a model's ability to understand the contents of an image.
Google notes that Gemini is a singular model with multiple modalities of input and output, rather than a "Mixture of Experts" model where multiple models are tied together. The Mixture of Experts approach has received speculation as the way in which GPT-4 is implemented, where multiple specialized models can be triggered to solve a problem.
Gemini follows on from a series of multimodal models released this year.
In September 2023, GPT announced GPT-4(V)ision (more commonly referred to as GPT-4 with Vision), which enables you to ask questions about images. GPT-4 was further extended with an integration, allowing you to use audio with the model.
Several open-source models, such as LLaVA and CogVLM, serve as alternatives to GPT-4 and Gemini, which allows you to run them on your own hardware unlike Gemini and GPT-4 with Vision.
Gemini is available in three versions, each tailored to a different use case:
- Ultra: The most capable (and largest) model;
- Pro: The "best model for scaling across a wide range of tasks.", and;
- Nano: A smaller model for use on mobile devices (i.e. the Pixel 8).
The Nano model is a particularly exciting development, as we strive to see how large language and multimodal models can be integrated into mobile devices.
Gemini Availability
A "specifically tuned" version of Gemini Pro is available in English for use with Google Bard, Google's large language model. This model is accessible through a web interface. You will need a Google account to use Bard, and thus Gemini through Bard.
The version of Gemini in Google Bard only supports text interactions. The multimodal capabilities of Gemini are not yet integrated into Bard, which we tested by running the tests we previously conducted on Bard, seeing comparable results, leading us to believe Gemini's multimodal input capabilities are not yet available.
In the case of Gemini Ultra, the most advanced model, Google is actively working on trust and safety exercises. This includes reinforcement learning from human feedback (RLHF), a technique extensively used by OpenAI in models such as ChatGPT and GPT-4 to ensure the model returns safe, high-quality responses to user queries.
Gemini is available in a wide range of nations across the globe. For an up-to-date list, refer to the official Google documentation on Gemini Pro availability.
From December 13th, you can integrate Gemini directly into your own applications. You can do this through two of Google's cloud offerings: Google AI Studio and Google Cloud Vertex AI.
What Can Gemini Do? (According to Google)
As part of Google's announcement of Gemini, they released a webpage with metrics and details regarding its capabilities and sixteen YouTube videos, with a specific playlist highlighting examples of specific use cases of Gemini. Let's analyze what Google claims Gemini can do.
Visual Understanding
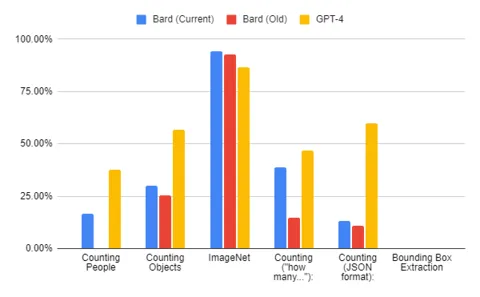
A use case that we've already found Bard and other LMMs are good at is the understanding of image contexts.
It is interesting to us that Gemini, which according to Google's provided metrics, only scores a marginal 0.6% better than GPT-4V, which is the only model that failed our visual question answering (VQA) tests, compared to other open-source LMMs like LLaVA, BakLLaVa, Qwen-VL and CogVLM. While interesting, given the basic understanding of images that almost all LMMs have now, we expect that Gemini will perform well on visual understanding, especially given the numerous examples provided of this aspect.
Object Detection
Object tracking, which we cover later on, is mentioned in detail throughout the examples and reports. But, object detection, which involves identifying the coordinates of an object of interest in an image. was not mentioned once. We could not find an explicit mention of object detection in the examples, the website or the sixty-page technical report. For context, GPT-4 with Vision has extremely limited object detection capabilities.
With that said, we evaluated the available examples to see if there were any close behaviors.
One note we found interesting was this video demonstrating Gemini's ability to correct an example student's math work on an assignment. Here, it draws a box around the part that Gemini believes the student got wrong.
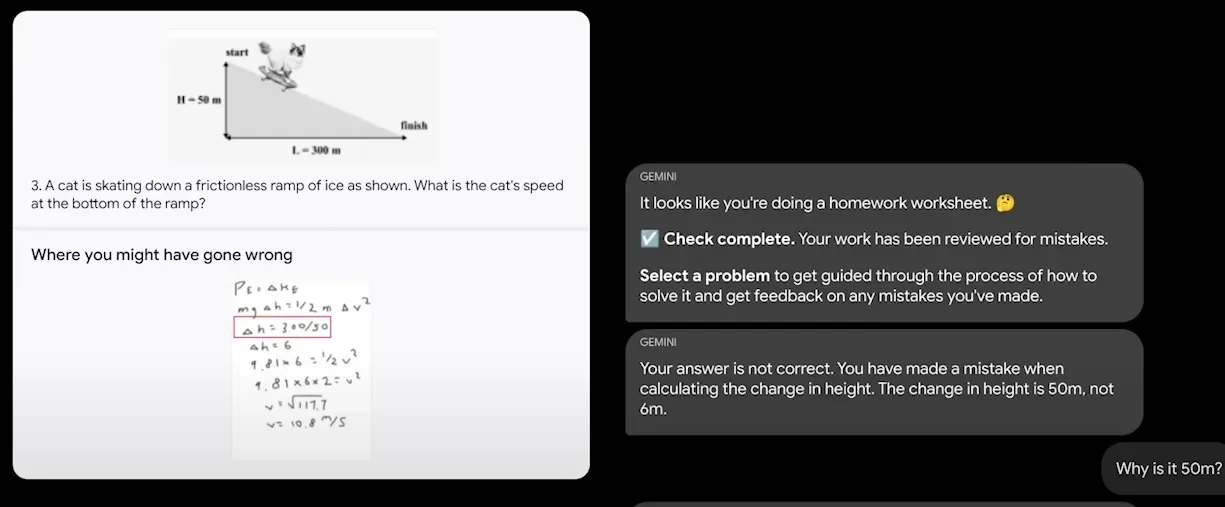
This example speaks to the model's mathematical understanding. There is a red box drawn around the error. We are not sure if this was a learning aid applied by the videographers and interaction designers involved with the video production. With that said, if this is a bounding box – used to indicate the location of an object of interest – this is a promising sign that there is more to explore in terms of Gemini's object detection capabilities.
Data Extraction
We have observed LMMs have trouble extracting key quantitative figures from infographic materials, like graphs. In our website tracking GPT-4's vision capabilities, we see that it consistently fails to accurately extract key points on a graph line, despite a clearly labeled line.
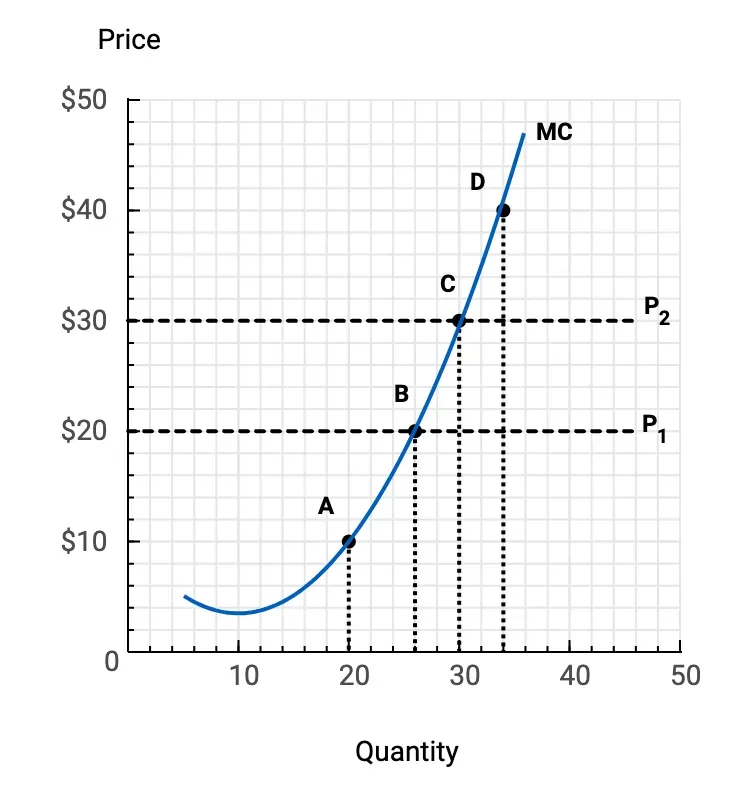
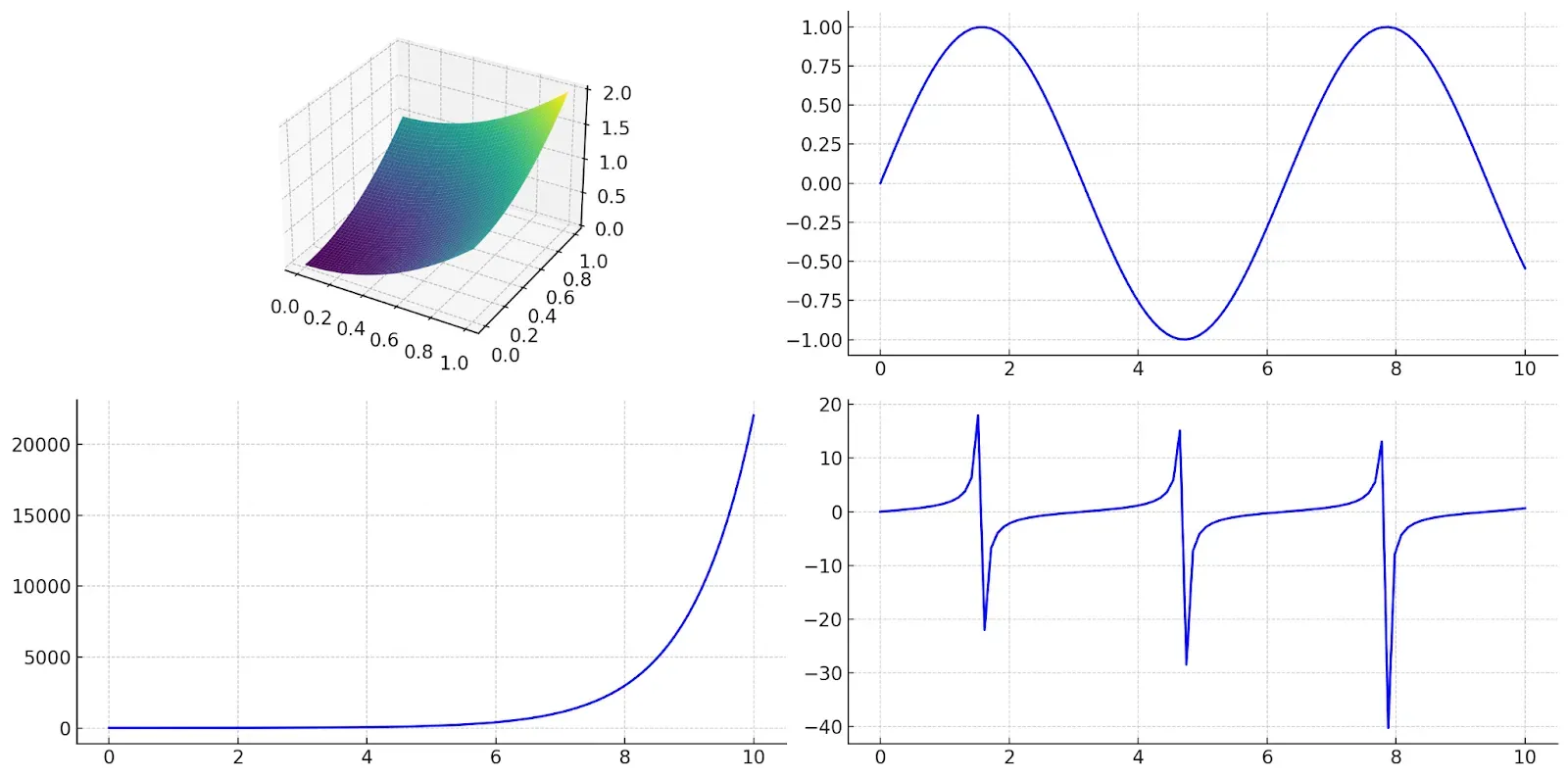
In a video called "Gemini: Unlocking insights in scientific literature", they highlight a capability where Gemini generates code to plot a graph line from a screenshot of a graph, similar to the one pictured above.
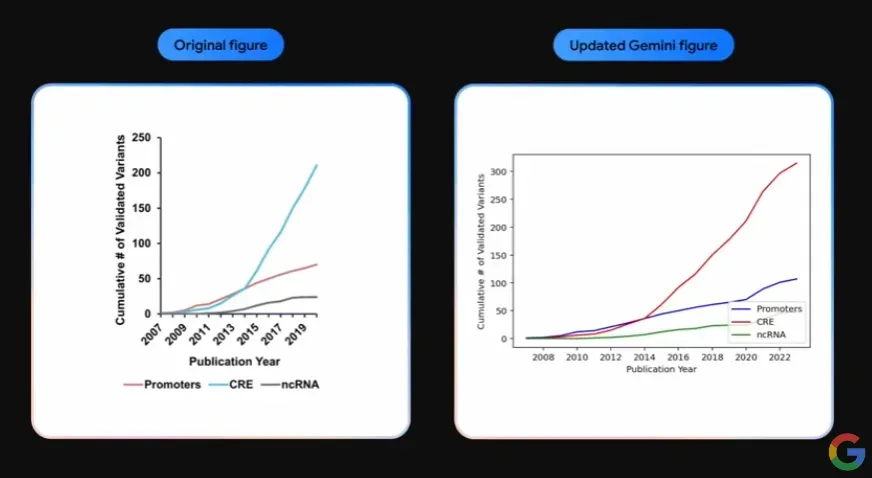
As far as we can tell from this image of the two graphs, it seems to do a proficient job of extracting quantitative data from graph images.
Further, Gemini's technical report contains an example where Gemini is able to recreate and manipulate different graph visual representations.
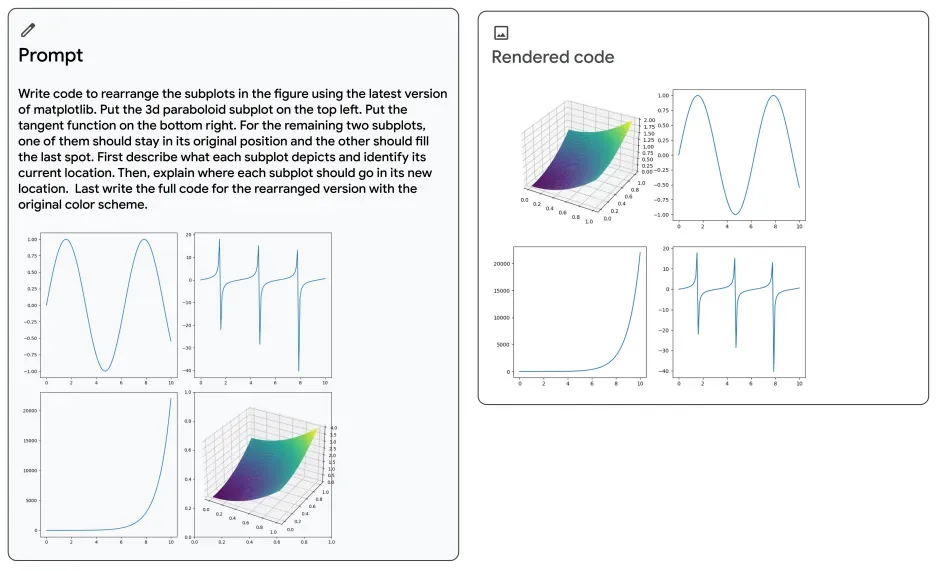
We tested this example in GPT-4. Here was the result:
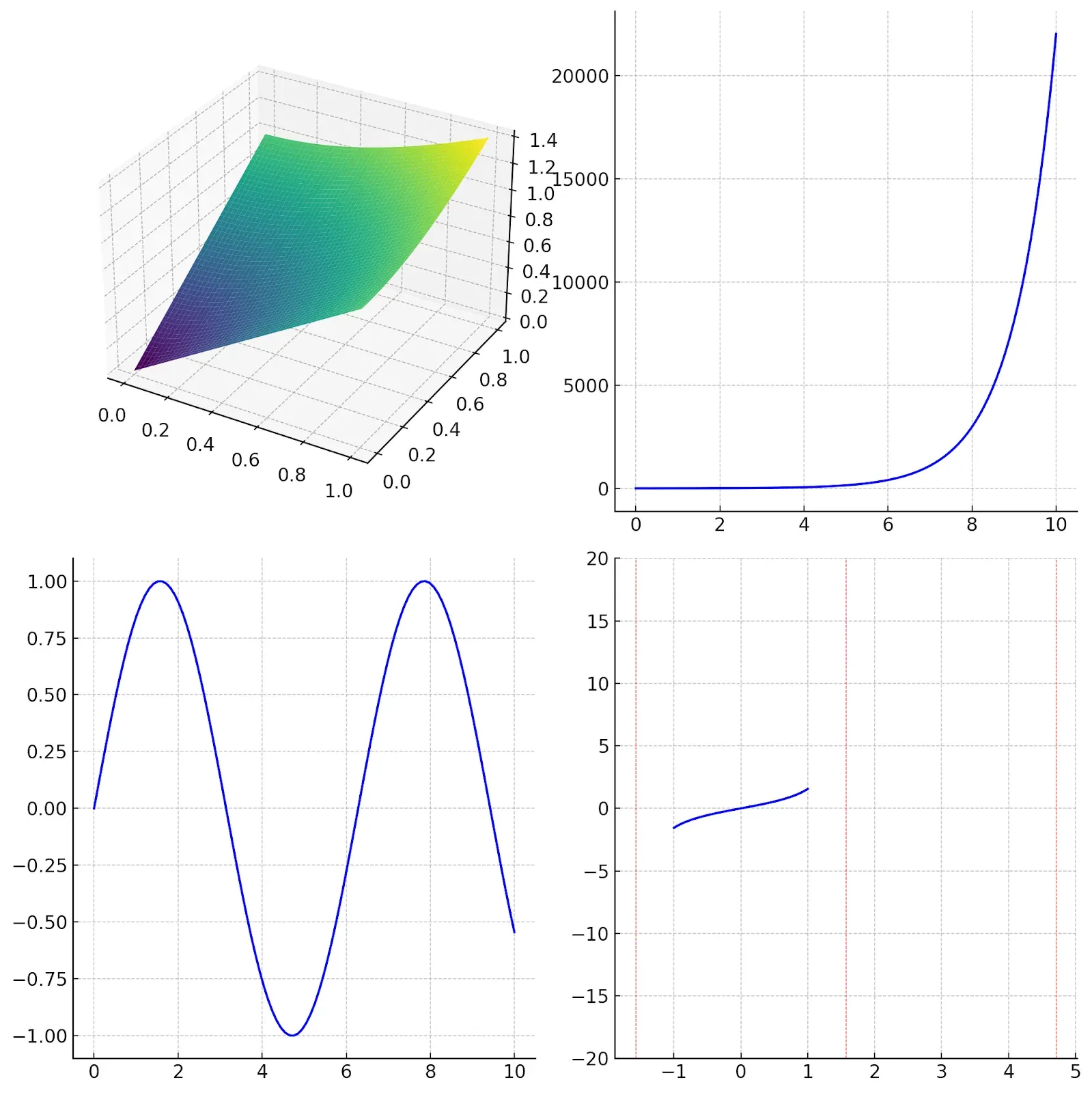
With the understanding that these are Google-provided examples, conceivable with the most preferable examples, we see that:
- Gemini is able to understand positioning instructions intuitive to a human well, placing all the functions in the correct place where GPT-4 could not.
- GPT-4 was unable to properly model the plot with discontinuities.
Although the model was initially incorrect, it is worth noting that after five attempts in GPT-4 using no alterations of the prompt, we were able to generate a similar and correct image, which raises the question of whether Gemini could also require numerous attempts and if the result in the report was after a single attempt or multiple.
Regardless, we're excited to test these results quantitatively once the API is released.
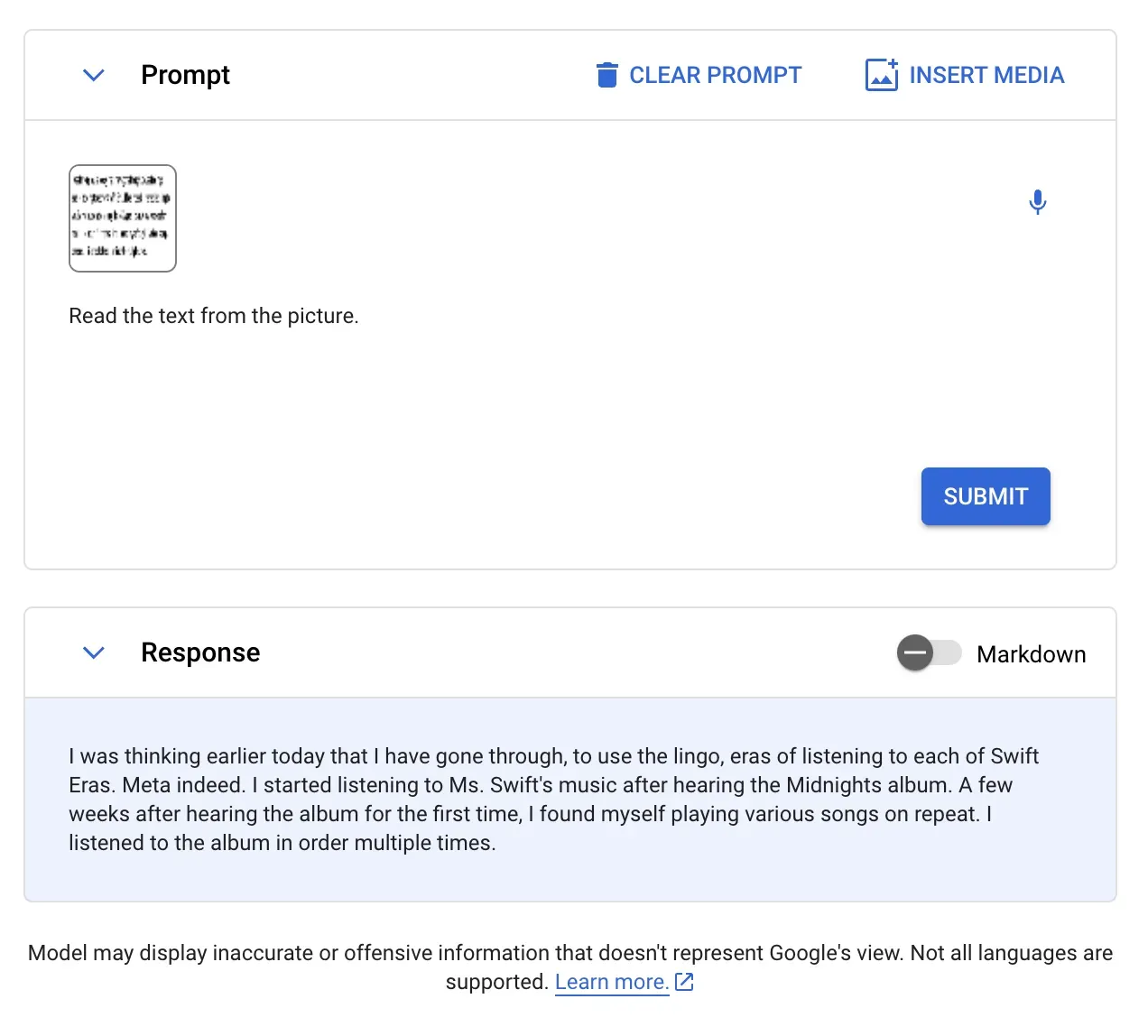
OCR
Printed or written text recognition, referred to as OCR, is an important part of visual understanding, and this is an area we've seen many multimodal models (including GPT-4) perform well.
In our testing, some open-source models like LLaVA and BakLLaVa struggle with OCR. With that said, Bard and GPT-4 have proven proficient in this aspect, and Gemini seems to be no exception, with the metrics complementing their claim that "Gemini Ultra consistently outperforms … especially for OCR-related image understanding tasks" (Gemini Technical Report)
Speech Capabilities
Speech was also a major focus of Gemini's capabilities, with a dedicated video highlighting how nuances of speech can often be lost when using multiple separate models. (a suspected jab at OpenAI's implementation of using Whisper, their speech to text model, in combination with GPT-4)
This was one area where we saw the biggest improvement from the prior state of the art (SOTA) was voice/speech recognition and understanding, with much lower word error rates (10% less than Whisper v3) and significantly higher BLEU (a metric in speech translation) scores than Whisper v2. (It was not clear why they compared to Whisper v2 over Whisper v3 specifically in this test)
Video Understanding
An area where we've still seen room for improvement in the LMM space was video understanding. Gemini does have video understanding capabilities, but in the form of taking a sequence of frames as images and inputting them into the model. In their technical report, they claim that the usage of a sequence of video frames, combined with audio, lead to effective understanding of video.
The metrics used to evaluate this aspect of the model are not particularly informative, using VATEX and Perception Test MCQA.
VATEX is a video description dataset. Although comparative figures for GPT-4 were not available, it can be assumed that since Gemini uses a sequence of video frames, the impressive performance of CLIP and GPT-4 in image captioning would also translate to video captioning.
Perception Test MCQA is a multiple choice dataset made by Google Deepmind which presents several examples of object tracking tests, in the form of 2-10 frames, with answering options. For this test, DeepMind held a competition, where the top performing submission got a score of 73%, compared to Gemini's 54.7%.
Few Shot Learning
In Google's "How it's Made: Interacting with Gemini through multimodal prompting" blog post, their Creative Director showcased how Gemimi works with single and multiple images.
Given a photo of a hand making the gesture for "paper" in the game "rock, paper, scissors", Gemini identified the image as containing a hand. With three images of a rock, paper, and scissors gesture, the model identified the game. With this knowledge, the model was then able to answer questions about the images with greater comprehension.
Several other tests are run, including one on image sequences from movies. Google asked Gemini to identify what movie and scene someone was acting out based on four images. The model succeeded:

This shows the extent to which multiple images can be used as context to answer a query that cannot be answered effectively with a single reference image.
Gemini Applications in Computer Vision
The multimodal capability of Gemini, like GPT-4 with Vision, is a significant development in the computer vision industry. This follows on from a growing trend to integrate text and image models together. Multimodal models, as noted above, can develop a wide range of capabilities, likely attributable to their grounding in language.
You can use LMMs like GPT-4 with Vision for tasks like:
- Image classification (i.e. "is this food half-eaten?");
- Generating metadata for use in search engines;
- Identifying particular features in an image (i.e. "does this image contain a shipping container with a dent?");
- Asking questions about how objects relate in an image (i.e. "is there a package next to the camera on the conveyor belt");
- Reading text in an image, and more.
Performance across these tasks has been varied. In some cases, LMMs offer significant value, such as is the case with image classification, identifying how objects relate, and answering questions about images.
With that said, how one "prompts", or asks, a model, is critical. There are some "prompting techniques" that can help you improve a model's ability to accurately answer a question. We expect this to be the same with Gemini.
For example, you can use Set of Mark prompting to help a model understand how objects relate. You can use "few-shot" learning, which involves giving a model a few examples of something you want to identify or ask about, to give the model more context that can be used to solve a problem. You can use "spot the difference" to identify inconsistencies between two images, a key feature for use in defect and anomaly detection.

Roboflow has been working extensively on prompting models, experimenting with different techniques to see how models respond. We actively read research on new prompting breakthroughs which can help you better leverage LMMs.
From our experience, we launched Maestro, an open-source Python package that lets you use Set of Mark prompting to improve object detection and spatial reasoning performance with LMMs. We have plans to add more techniques, and support for Gemini when it is live.
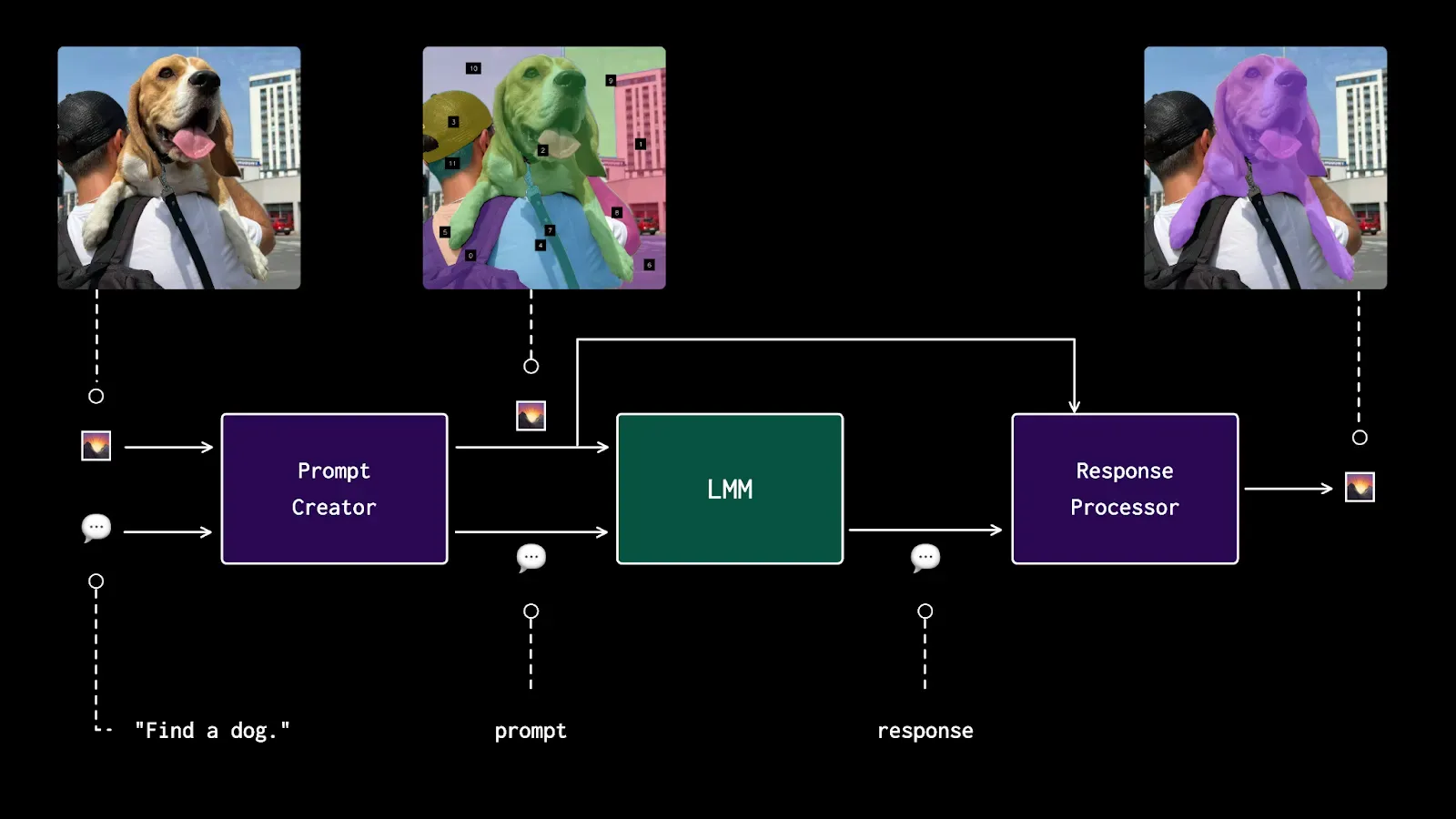
In particular, we are excited to evaluate its capabilities in object detection. We want to be able to answer the question "Can Gemini identify the location of an object in an image, and return bounding box coordinates?" We also have plans to integrate Gemini into Autodistill, a framework for using large vision models to auto-label data for use in training smaller, fine-tuned models.
As is always the case, Gemini is no substitute for a small, fine-tuned model if you want to identify objects in an image.
A fine-tuned model like RF-DETR can run at multiple frames per second, depending on the hardware you are using. A fine-tuned model can be trained to identify specialist objects, no matter how niche. You can tune your fine-tuned model as your needs evolve. Gemini, on the other hand, is unlikely to be viable for real-time video use cases and the extent to which you can tune the model is prompting, which only goes so far.
Conclusion
Gemini is a Large Multimodal Model (LMM) developed by Google. Gemini is capable of helping with a range of tasks, from visual understanding to answering questions about math to identifying how two images are similar and different.
In this guide, we discussed what Gemini is, the extent to which the Gemini series of models are available, capabilities of Gemini (according to Google), and Gemini's applications in computer vision. We also looked ahead at how Roboflow plans to help you use Gemini for vision tasks, from integrating Gemini into Maestro to help you prompt the model to using Gemini to auto-label data for use in training smaller, fine-tuned models.
We are excited to evaluate Gemini further!
Cite this Post
Use the following entry to cite this post in your research:
Leo Ueno, James Gallagher. (Dec 7, 2023). Google's Gemini Multimodal Model: What We Know. Roboflow Blog: https://blog.roboflow.com/gemini-what-we-know/