
This article was contributed to the Roboflow blog by Abirami Vina.
AI and computer vision make it possible for machines to understand images and videos as humans do. Innovations like autonomous vehicles, robotics, and advanced photo editing are beneficiaries of this technology. OpenCV is a leading open-source library for computer vision applications, and plays a vital role in providing tools for real-time image and video processing.
OpenCV boasts over 2500 algorithms, including classical ones like Support Vector Machines (SVMs) and K-Nearest Neighbors (KNN), and cutting-edge deep learning techniques. These algorithms help with tasks such as object detection, image segmentation, and facial recognition.
In this article, we're diving into what OpenCV does, how it grew over the years, and the exciting ways people are using it.
What is OpenCV?
OpenCV, short for Open Source Computer Vision Library, is an essential toolkit for anyone working with computer vision and machine learning. It's open-source, which means anyone can use and tweak it, fitting for all sorts of projects, from big companies like Google to smaller startups and academic research.
OpenCV is packed with algorithms that help with everything from recognizing objects to tracking the movement of objects and even creating 3D models. It's incredibly popular, with a huge community of over 47,000 users and more than 18 million downloads.
OpenCV supports C++, Python, Java, and MATLAB and works on Windows, Linux, Android, and MacOS. Thanks to its efficient use of computer processing, it's especially good for projects that need to work in real-time. With ongoing developments in tech like CUDA and OpenCL, OpenCV is at the heart of countless innovative applications worldwide, from surveillance and robotics to interactive art.
OpenCV's Architecture
OpenCV's architecture is designed to handle a wide range of computer vision and machine learning applications. It is built around a core component, CXCore, which includes its main functions and algorithms. This setup minimizes redundancy and boosts efficiency.
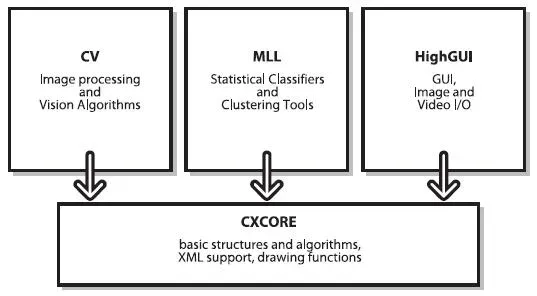
In addition to the core, there are components like CV, which focuses on image processing and vision algorithms, and MLL, which includes statistical classifiers and clustering tools. Another key component is HighGUI, which is geared towards graphical user interface functions, image, and video input/output operations. This modular design allows for the flexible integration of different machine-learning features.
OpenCV's Algorithms
The OpenCV Library has a suite of over 2500 optimized algorithms. These algorithms enable a variety of tasks, including image classification, object detection, and segmentation, feature extraction, and even recognition of human handwriting.

Let's learn more about some of these algorithms. Support Vector Machines (SVM) and K-Nearest Neighbors (KNN) algorithms are good options for image classification by grouping similar data points. This process can be used to differentiate between categories such as animals or objects.
Decision Trees are commonly used with other machine learning techniques, such as deep learning, to improve performance in tasks like object detection and image segmentation.
The deep learning aspect of OpenCV includes neural networks, with support for frameworks such as TensorFlow and PyTorch. Also, OpenCV is always evolving and integrating new models like RF-DETR, a real-time transformer-based object detector, and Vision Transformers (ViTs) that apply transformer architecture for tasks such as image classification and detection.
Brief History and Evolution
How did OpenCV come to be?
The development of OpenCV Library started in 1999 at Intel Research Labs. It was first created in C and C++ languages and was later expanded to include support for modern programming languages like Python and many others. Created by Gary Bradski, the library mainly aims to provide a common infrastructure for various computer vision applications and accelerate research in the field.
OpenCV in the 2000s
The first version was publicly released in 2000, version 1.0, and it offered many image processing and analysis functionalities. Six years later, version 1.1 introduced the new C++ interface, which made it more accessible to developers and enabled faster prototyping. In 2008, version 1.5 made use of the power of graphical processing units to accelerate computationally intensive tasks. This was done by adding support for GPU acceleration.
The Evolution in the 2010s
OpenCV released version 2.0 in 2010, and it surpassed everything that came before it. It gave developers enhanced performance, a modular structure, and compatibility with various platforms like Windows, Linux, Mac, and mobile devices. OpenCV brought major changes in 2015 with version 3.0. It had a new C++11 interface, improved Python bindings, and also integrated the latest machine-learning algorithms at the time. Later on, in 2018, deep learning capabilities and a DNN module for efficient neural network inference were introduced with Version 4.0.
The Present (2020s)
OpenCV is continually improving. At the time of writing this article, OpenCV recently introduced enhancements to its object detection modules along with a new object tracking API called TrackerVit, which is based on vision transformers. Their latest version, v4.9, also had enhanced Android support capabilities, experimental CUDA language support, and the latest AppleVisionOS platform support.
Using GPUs for Faster Processing with OpenCV
What type of scenario is OpenCV commonly used in? OpenCV is widely used for real-time applications. It can leverage SIMD instructions such as MMX and SSE to improve performance.
Also, it seamlessly integrates tools like CUDA and OpenCL to accelerate the processing of graphical data. This transition to GPU-based processing streamlines operations, reducing overheads and enhancing efficiency in computer vision applications. The graph below clearly shows this.
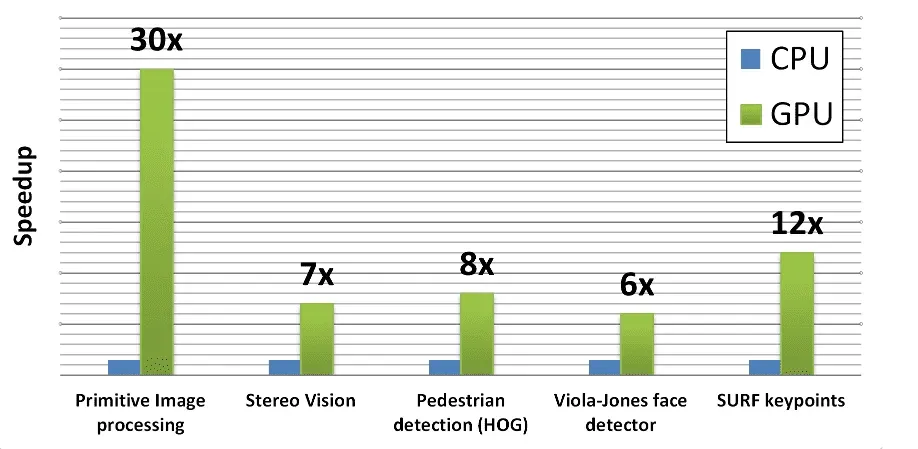
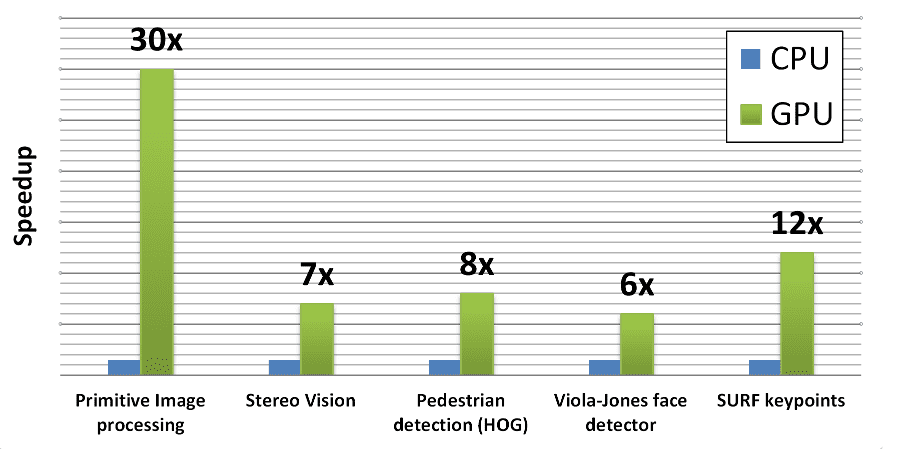{kind=link}
Use Cases
Below are a few cases where OpenCV can be used.
2D and 3D Feature Toolkits
OpenCV offers robust toolkits for analyzing both 2D and 3D features within images and videos. This functionality can be used for tasks like image matching, object tracking, and augmented reality applications.
For example, OpenCV can detect and match key features in images to create panoramic images or generate 3D models from multiple images. OpenCV can even be used to reconstruct a scene, as shown below. In the original image, the building is hidden behind the foreground. In the output image, the scene is reconstructed so the building is no longer hidden.

For instance, it could power a facial recognition system that unlocks a smartphone or grants access to secure areas based on recognized faces.
Gesture Recognition and Human-Computer Interaction
The development of gesture recognition systems is made easy with OpenCV. Gesture recognition allows users to interact with computers or devices through gestures and movements.
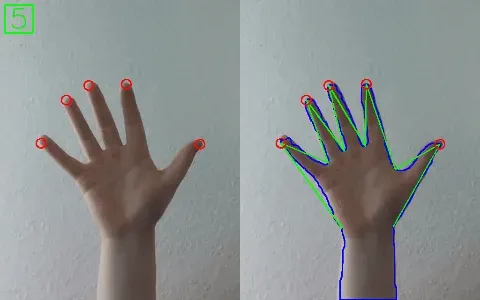
It can be used in gaming, virtual reality, and interactive digital signage. For example, a webcam could track hand movements, enabling users to control on-screen actions such as navigating menus or playing games without physical controllers.
Motion Understanding and Object Detection
OpenCV's algorithms for motion understanding and object detection can be used in surveillance, autonomous vehicles, and robotics. For example, they could be used to develop a motion detection system that monitors security camera feeds. Such a system could alert operators to suspicious movements in real time. In the image below, a technique called background subtraction detects motion and thus knows that an object (in this case, a dog) has entered the image.
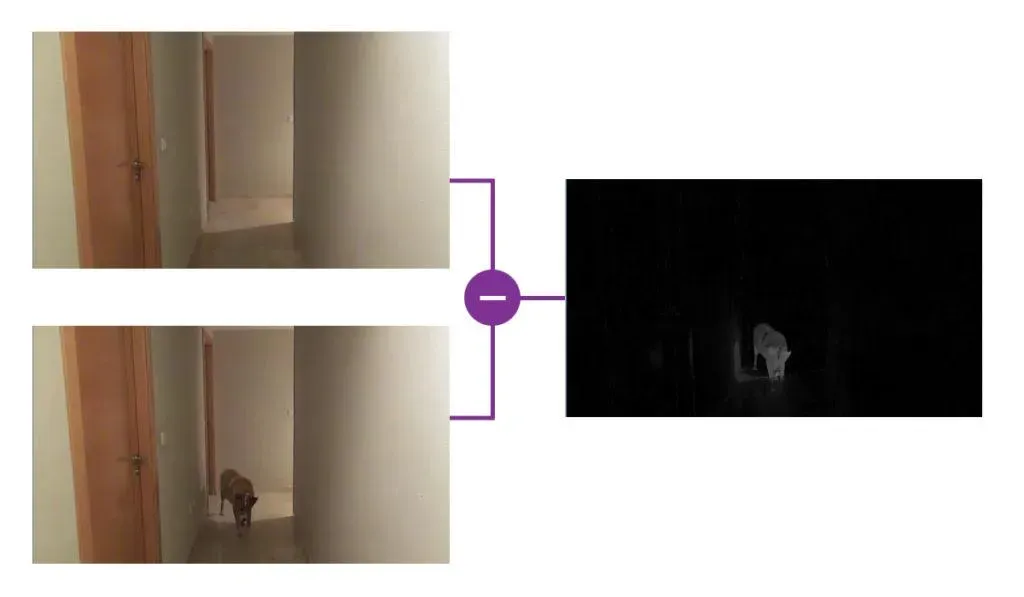
Augmented Reality
OpenCV plays an important role in augmented reality applications by letting developers overlay digital content onto the real world in real time. This technology is used in gaming, education, and marketing.
For example, OpenCV can be used to detect markers or objects in the physical environment and superimpose virtual elements, such as 3D models or information, onto them. This makes user experiences more exciting by blending digital and physical worlds.
Try It Yourself
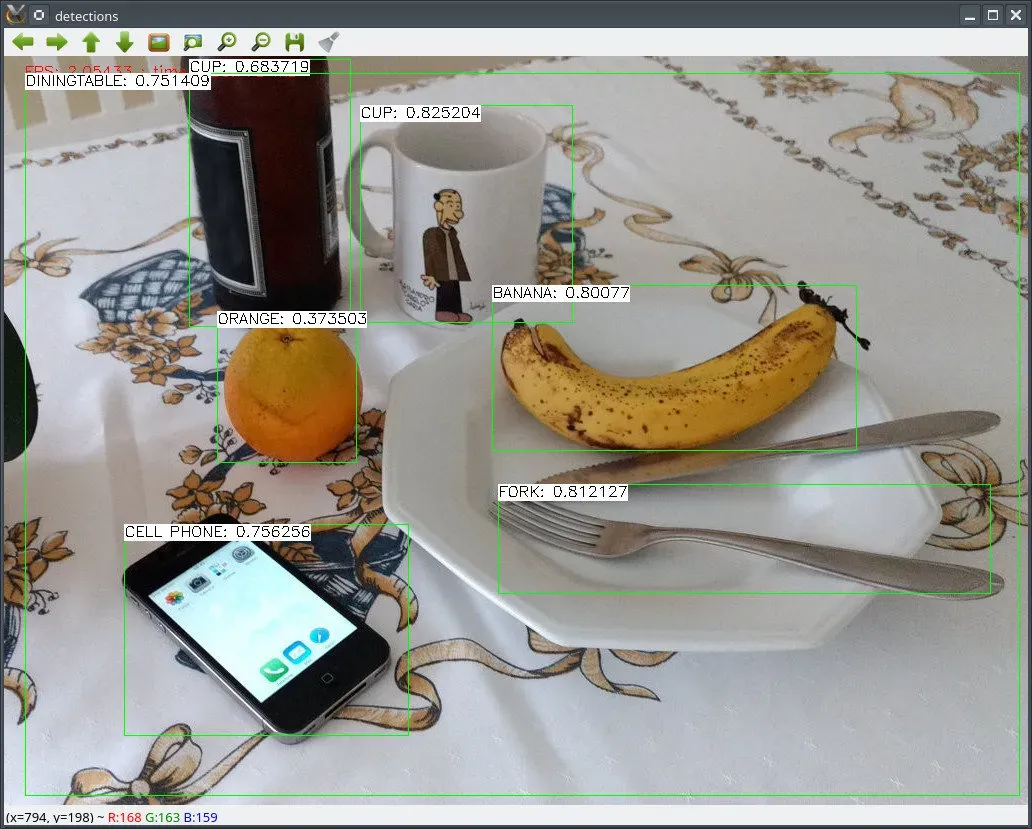
You can try implementing a quick OpenCV object detection solution to count the number of bicycles in an image yourself in less than 5 minutes.
First, download the following files:
- ssd_mobilenet_v3_large_coco_2020_01_14.pbtxt
- frozen_inference_graph.pb
- labels.txt
- An image to run inferences on.
Then, install the opencv-python package using pip install opencv-python and run the following code:
import cv2 as cv
# Paths to the configuration file and frozen model file
config_file = './ssd_mobilenet_v3_large_coco_2020_01_14.pbtxt'
frozen_model = './frozen_inference_graph.pb'
# Detection model using dnn - deep neural network module
model = cv.dnn_DetectionModel(frozen_model, config_file)
# labels.txt contains all the annotations for detection
classLabels = []
file_name = '/content/labels.txt'
with open(file_name, 'rt') as fpt:
classLabels = fpt.read().rstrip('\n').split('\n')
# Input parameters for detection model
model.setInputSize(320, 320)
model.setInputScale(1.0/127.5)
model.setInputMean((127.5, 127.5, 127.5))
model.setInputSwapRB(True)
# Read an image
img = cv.imread('./test.jpg')
# Run an inference on the image
classIndex, confidence, bbox = model.detect(img, confThreshold=0.6)
# Setting font scale and type to display text on the image after detection
font_scale = 3
font = cv.FONT_HERSHEY_PLAIN
counter = 0 # Counter to keep track of the number of bicycles detected
# Iterate over detected objects in the image
for ClassInd, conf, boxes in zip(classIndex.flatten(), confidence.flatten(), bbox):
# Draw rectangle around detected object
cv.rectangle(img, boxes, (255, 0, 0), 2)
# Display Label near detected object
cv.putText(img, classLabels[ClassInd-1], (boxes[0]+10, boxes[1]+40), font, fontScale=font_scale, color=(0, 255, 0), thickness=3)
# To check if there is a Bicycle in the Image
if classLabels[ClassInd-1] == 'bicycle':
counter = counter + 1 # Increment counter if a bicycle is detected
# Display the number of bicycles detected
print(f"Number of bicycles detected: {counter}")
# Save image with labels and boxes around the detected objects
cv.imwrite('./output.jpg', img)Below is an example of an output image, and the print statement would say that two bicycles were detected.

Future of OpenCV and Computer Vision
The future of OpenCV and computer vision is shaping up to look very exciting. The ongoing advancements are set to transform many industries. With the rise of edge computing and IoT, the demand for lightweight and efficient computer vision solutions will increase. We'll likely see OpenCV optimize its algorithms further for resource-constrained environments.
In parallel, the growing privacy concerns will lead to a focus on privacy-preserving techniques within computer vision systems. The future of AI will be all about ensuring we can use this powerful technology responsibly.
Conclusion
OpenCV has really come a long way since 1999. OpenCV's toolbox is massive, from the basics of image handling to innovations like AR gesture control.
Their ability to adapt and keep innovating is what makes them such a powerful tool for developers and researchers everywhere. They're constantly pushing the boundaries of what's possible in computer vision. Thanks to platforms like OpenCV, we can all contribute to AI's next big breakthroughs.
Continue Your Learning
Here are some more resources to help you get started with OpenCV:
Cite this Post
Use the following entry to cite this post in your research:
Contributing Writer. (Mar 21, 2024). What is OpenCV? A Guide for Beginners.. Roboflow Blog: https://blog.roboflow.com/what-is-opencv/