
The combination of artificial intelligence (AI) and robotics is turning science fiction into reality. Robots today are no longer just machines that repeat tasks, they can think, learn, and adapt. By adding AI, robots gain the ability to see, make decisions, and interact with their surroundings, allowing them to work on their own in real-world, unpredictable environments.
AI changes robots from simply following instructions to acting more like intelligent assistants. With tools like computer vision, natural language processing (NLP), and machine learning, robots can recognize images, understand speech or text, and get better through experience. They can now sense what’s around them, make smart choices based on the situation, and keep learning as they go, bridging the gap between movement and intelligence.
In recent years, this field has grown rapidly. Robots trained with deep reinforcement learning can move through rough terrain, handle new objects, and even work together in groups. At the same time, vision-language models help them better understand their environment, follow complex commands, and work more naturally with humans.
In this blog, you'll explore the many facets of AI in robotics, from foundational techniques such as computer vision, NLP, and machine learning to real-world robot types and standout models to inspiring projects and leading companies shaping the field. Together, these elements paint a comprehensive picture of how AI is driving the next generation of intelligent robots and what that means for industry, research, and society.
What Is AI Used For In Robotics?
Today's robots represent a fundamental shift from traditional automation, moving beyond rigid, pre-programmed behaviors to become intelligent, adaptive systems. This transformation is powered by the integration of artificial intelligence, which enables robots to perceive their environment, understand human communication, and learn from experience in ways that were previously impossible.
Unlike conventional industrial robots that follow fixed sequences of actions, modern AI-powered robots can make real-time decisions, adapt to changing conditions, and handle uncertainty. They process visual information to navigate complex spaces, interpret natural language to follow human instructions, and continuously improve their performance through machine learning algorithms.
This convergence of AI technologies transforms robots from simple automated machines into sophisticated partners capable of working alongside humans in unpredictable environments. The practical impact spans multiple sectors such as:
- In manufacturing, robots collaborate safely with human workers while adapting to product variations.
- In logistics, they navigate dynamic warehouse environments and optimize their routes.
- In homes, they learn family routines and preferences to provide personalized assistance.
The foundation of this AI driven evolution lies in three fundamental pillars that collaborate to develop truly intelligent robotics systems. Understanding how computer vision, natural language processing, and machine learning integrate is essential to understand advanced robots function autonomously in real-world settings such as homes, factories, and warehouses.
Computer Vision Powering Robotics
Computer vision empowers robots to "see" and interpret their surroundings with remarkable sophistication. By processing video streams and sensor data, robots can recognize objects, estimate distances, understand spatial relationships, and make sense of complex visual scenes which enable precise navigation and intelligent physical interaction with their environment.
It works using:
- Object detection & segmentation: Advanced deep learning models locate and classify multiple objects simultaneously in cluttered, real-world scenes, distinguishing between different items even when partially obscured.
- Depth perception: Stereo vision systems and structured light sensors provide accurate distance estimates and determine object poses in three-dimensional space. Additional techniques include monocular depth estimation using deep learning networks, Time-of-Flight (ToF) sensors for direct distance measurement, and LiDAR systems for high-precision 3D point clouds. Photometric methods like shape from shading and multi-view techniques such as Structure from Motion (SfM) offer alternative approaches for depth reconstruction in robotic applications.
- Scene understanding: Robots analyze relationships between objects and environments to make context-appropriate decisions about how to interact with their surroundings.
Some examples of computer vision applications are:
- Navigation & mapping: Robots employ camera-based SLAM (Simultaneous Localization and Mapping) to construct detailed 3D maps while navigating and avoiding obstacles in constantly changing environments.
- Robotic manipulation: In logistics and manufacturing, vision-guided robotic arms precisely detect, identify, and align items for picking, placing, or barcode scanning operations - for example, Almond's robots.
- Inspection & quality control: Industrial robots perform detailed visual inspections of infrastructure, equipment, and products, automatically flagging defects like corrosion, leaks, misaligned components, or manufacturing flaws.
The benefits of computer vision in robotics are as follows:
- It enables real-time decision-making in dynamic, unpredictable visual environments.
- It allows robots to navigate, manipulate objects, and adapt their behavior based on visual feedback.
- It promotes safer human-robot collaboration through advanced obstacle detection and human presence recognition.
Natural Language Processing (NLP) In Robotics
Natural Language Processing transforms how humans interact with robots by enabling machines to understand spoken and written language and convert it into actionable tasks. This capability makes robot interaction intuitive and natural, eliminating the need for complex programming interfaces or specialized control systems.
It works using:
- Speech recognition & parsing: Advanced systems convert human speech into text and analyze grammatical structure to identify specific intentions and commands (e.g., transforming "Pick up the red cup from the table" into structured robotic instructions).
- Semantic understanding: Sophisticated language models map linguistic elements to specific robot actions, object references, and spatial relationships through context-aware semantic analysis.
- Dialogue and task management: Systems process multi-step instructions and maintain conversational context to execute complex task sequences while handling clarifications and follow-up commands.
Some examples of NLP applications are:
- Voice-controlled assistance: Home service robots, hotel concierge systems, and companion robots execute diverse tasks based on natural spoken instructions, adapting to different speaking styles and accents
- Autonomous vehicle interaction: Self-driving cars and delivery robots process passenger voice commands for destination changes, route preferences, and service requests while providing spoken status updates and navigation guidance.
The benefits of NLP in robotics are as follows:
- Intuitive interaction dramatically reduces training time and eliminates the complexity of traditional robot programming interfaces.
- Supports multilingual communication and context-aware dialogue that adapts to conversational nuances and cultural differences.
- It enables robots to respond dynamically to conversational cues, emotional tone, and implicit requests.
Machine Learning in Robotics
Machine Learning represents the most transformative aspect of modern robotics, allowing robots to acquire new behaviors through experience and environmental interaction rather than explicit programming. Reinforcement learning, a key ML technique, enables robots to develop sophisticated motor skills and decision-making capabilities through trial-and-error learning.
It works using:
- Imitation learning: Robots observe and mimic human demonstrations to acquire foundational behaviors, learning complex task sequences by watching expert performance.
- Reinforcement learning: Robots explore different approaches to task execution and receive reward signals to progressively refine their actions learning optimal strategies for grasping objects, maintaining balance, or navigating obstacles.
- Simulation-to-real transfer: Advanced training occurs in detailed virtual environments before deployment on physical robots, with domain randomization techniques ensuring robust performance across diverse real-world conditions.
Some examples of ML applications are:
- Dexterous manipulation: Robotic hands and arms learn intricate motion sequences for tasks like precise picking, component insertion, fabric folding, and delicate assembly operations.
- Locomotion control: Quadruped and humanoid robots develop stable, efficient gaits for traversing varied terrains, stairs, and obstacles while maintaining balance and energy efficiency.
- Adaptive task execution: Robots automatically adjust their behavior when encountering novel environments, unexpected objects, or changing task requirements without requiring manual reprogramming.
The benefits of ML in robotics are as follows:
- Enables generalization to previously unseen objects, environments, and task variations.
- Minimizes the need for hand-coded behavioral rules or extensive manual programming.
- Scales effectively with data diversity, improving performance across multiple domains and increasingly complex tasks.
Integrated Intelligence: How the Three Pillars Create Autonomous Systems
The revolutionary capability of modern robots emerges from the integration of these three AI pillars working in harmony. Consider a logistics robot tasked with "organizing the returned items by category and condition":
Natural Language Processing interprets the instruction, understanding that items need sorting by both type and quality status. Computer Vision simultaneously identifies objects, assesses their condition through visual inspection, and maps the workspace layout. Machine Learning coordinates the entire operation, applying learned manipulation skills to handle different item types while optimizing the sorting strategy based on accumulated experience. This integrated approach enables robots to tackle complex, multi-faceted challenges that would be impossible with traditional automation.
The result is a new generation of robots that don't merely execute programmed routines but truly understand their environment, communicate naturally with humans, and evolve their capabilities through experience that mark a fundamental advancement in robotics that enables autonomous operation in the unpredictable complexity of real-world environments.
Example in Practice: Figure 02 Humanoid Robot + Helix AI
Helix is a Vision‑Language‑Action (VLA) model developed in-house by Figure AI. It unifies computer vision, language understanding, and learned control within a single end-to-end model. It powers Figure 02, a humanoid robot that controls the entire upper body (torso, head, wrists, fingers) via neural networks.

Figure 02 is controlled by the Helix AI model, embodies how modern robotics unites computer vision, natural language processing, and reinforcement‑based learning into one cohesive system. It perceives visual scenes, understands human language commands, and performs dexterous manipulation in real‑world environments exemplifying how AI is transforming robots into adaptable, intelligent agents.
Helix AI system architecture has two parts, each optimized for different thinking speeds:
System 2 (S2): The Thinker
Is a 7-billion-parameter vision-language model that runs at 7-9 times per second. Think of it as the “big-picture” system. It understands what’s going on, what you said, and what needs to be done. S2 processes camera images, voice commands, and robot state (like wrist position), then condenses this into a single “goal vector”, a high-level instruction.
System 1 (S1): The Doer
It is an 80-million-parameter visuomotor transformer running 200 times per second. This is the “fast reflex” system. It takes S2’s goal vector and translates it into smooth, real-time wrist, finger, head, and torso movements. It reacts continually to visual feedback to adjust motions as needed.
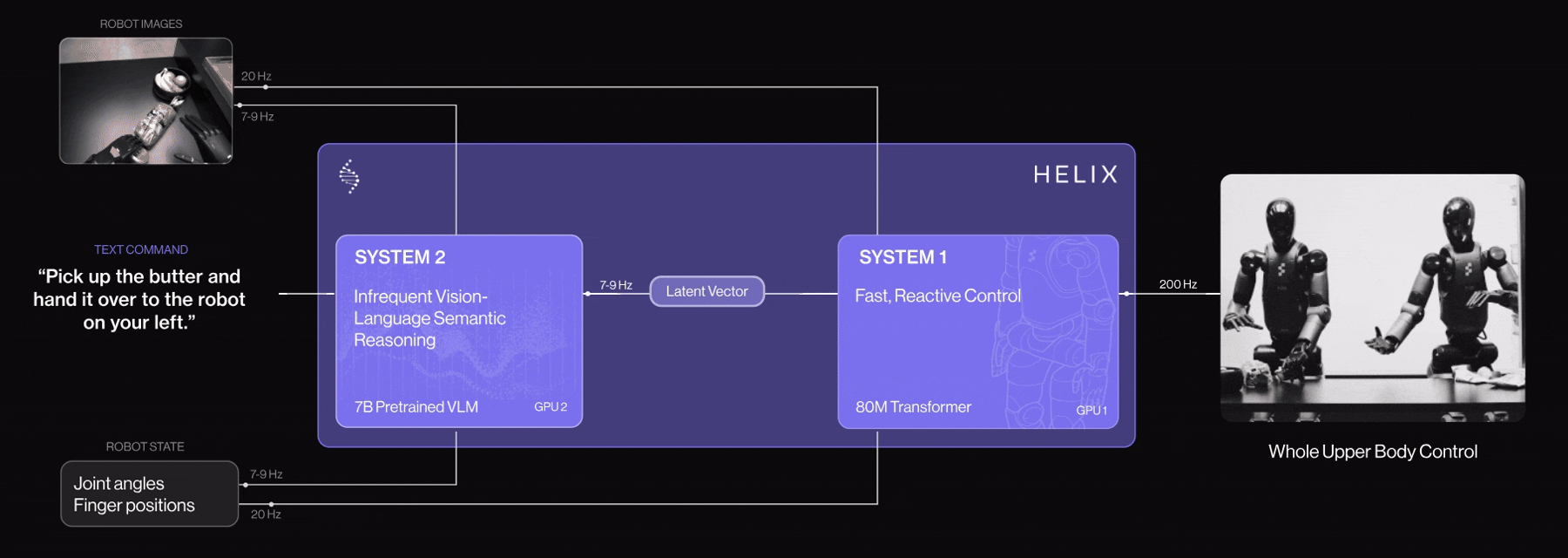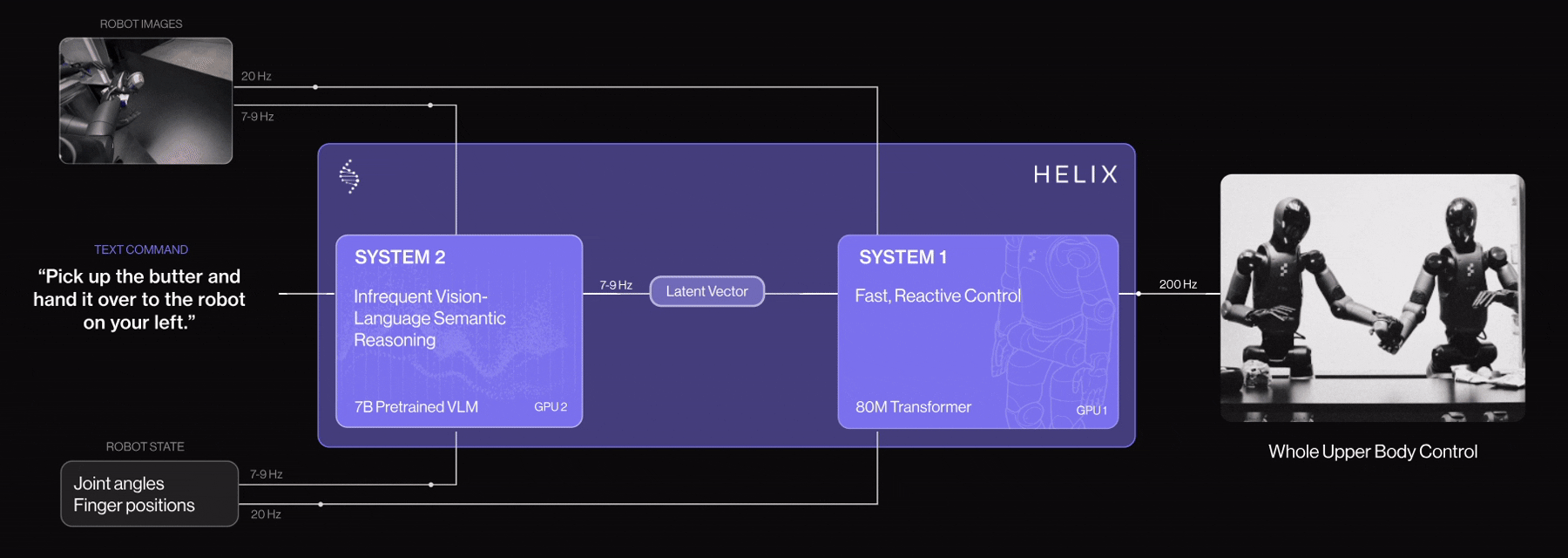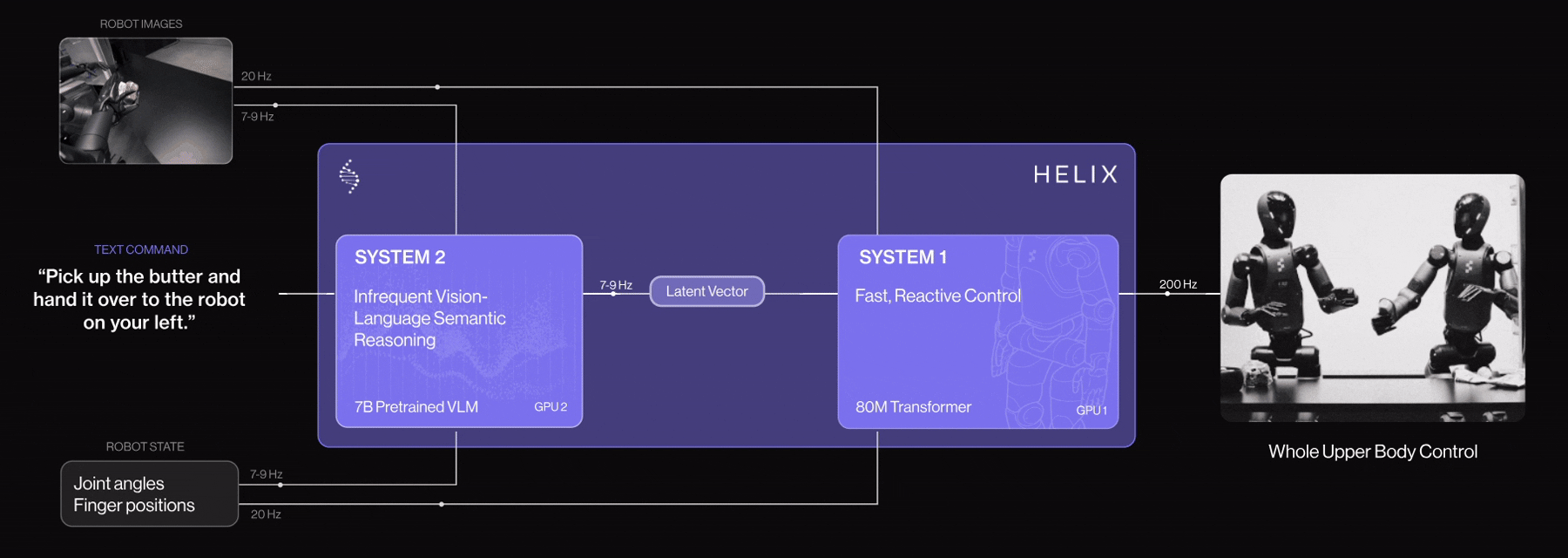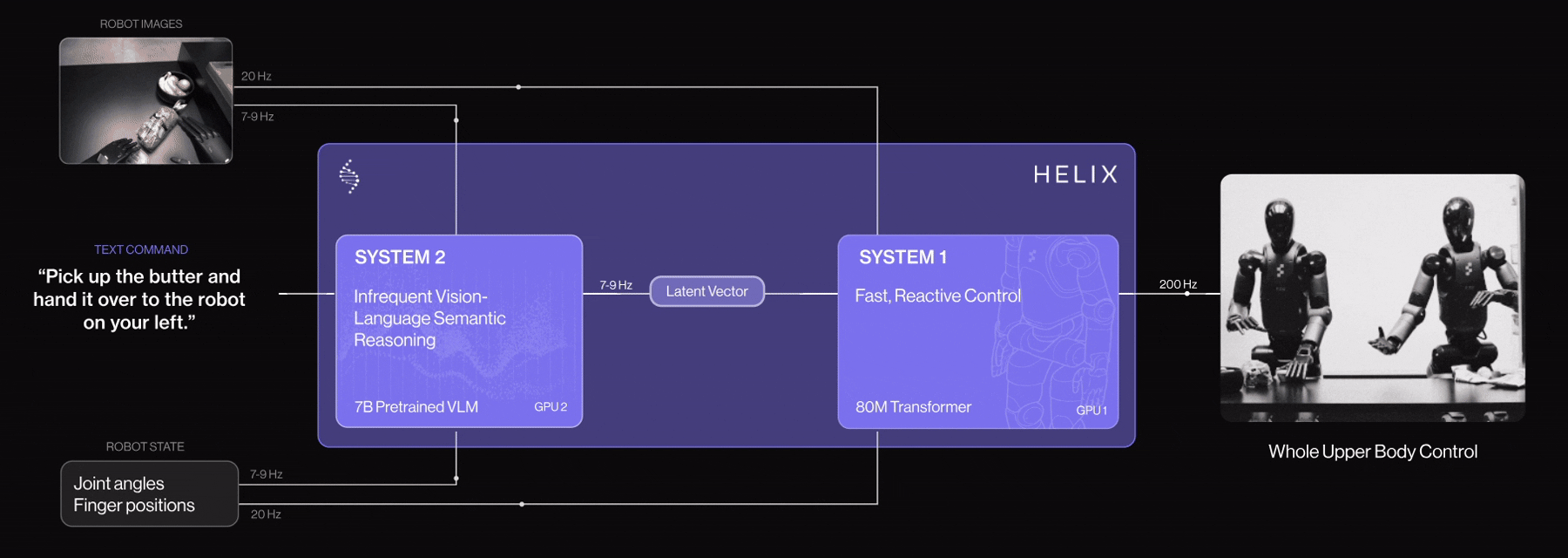
System 1 (S1) in Helix AI has been upgraded with 4 key enhancements for logistics tasks:
- Implicit stereo vision for accurate 3D depth perception.
- Multi-scale visual features that balance detail and scene context.
- Visual proprioception, enabling each robot to self-calibrate using its cameras.
- A “Sport Mode” that boosts action speed by 20–50% without sacrificing precision.
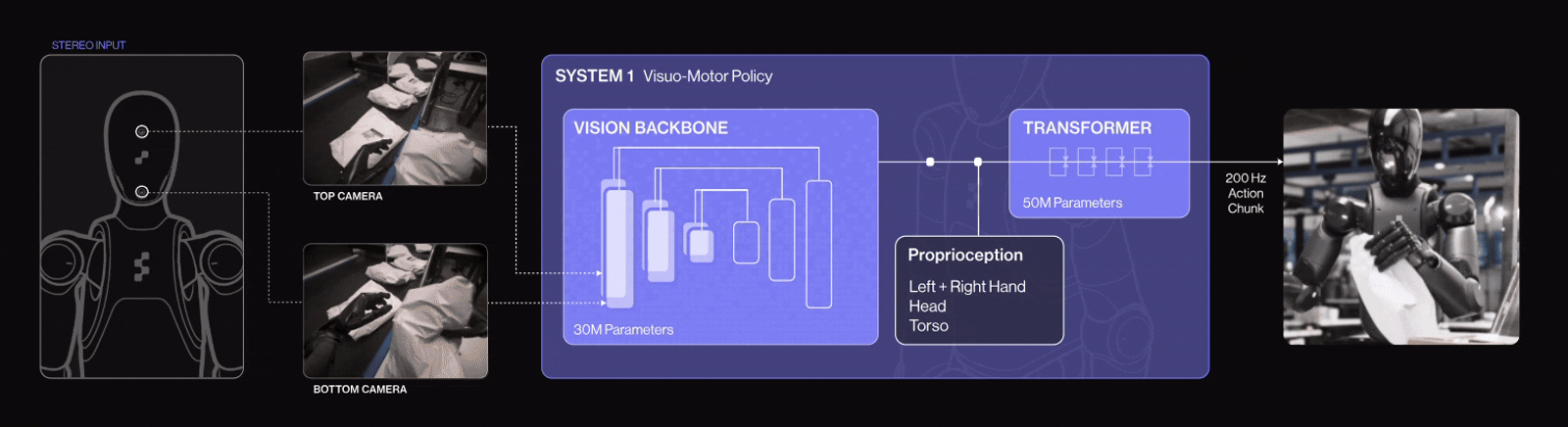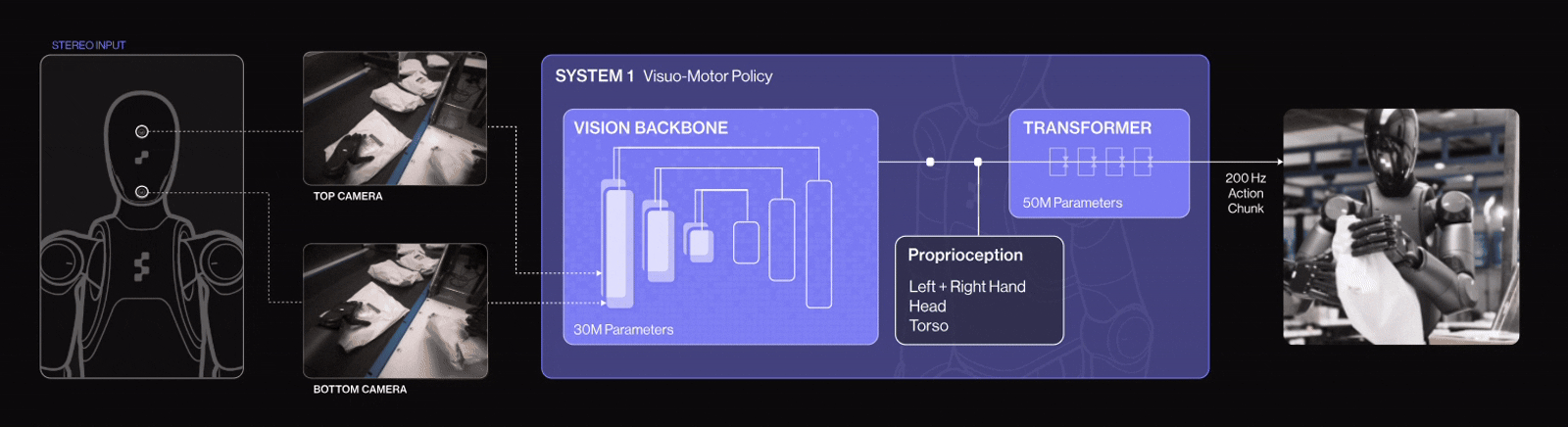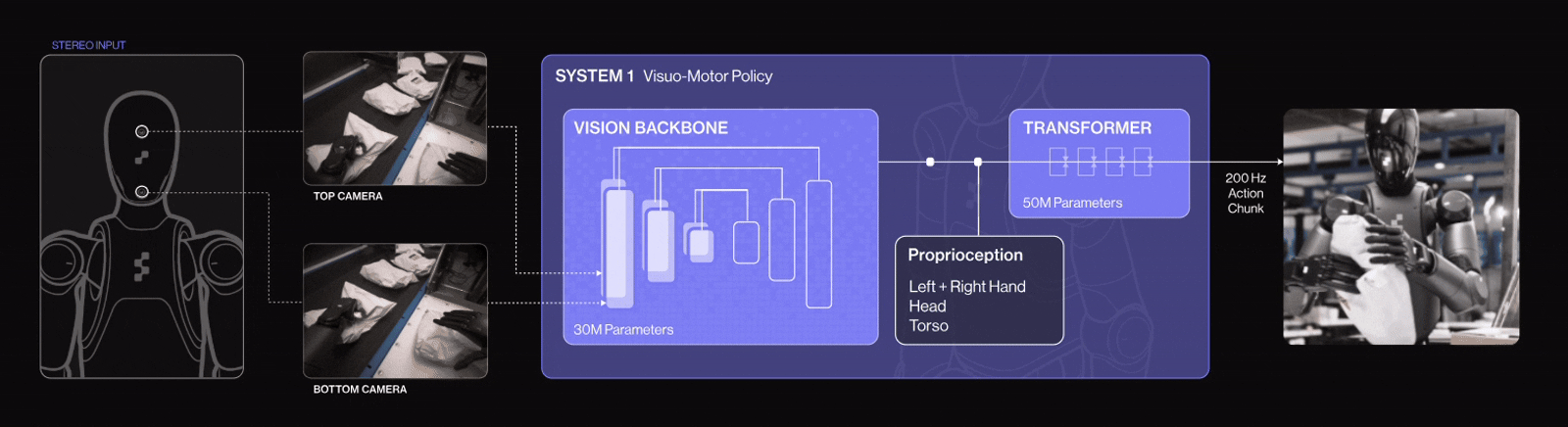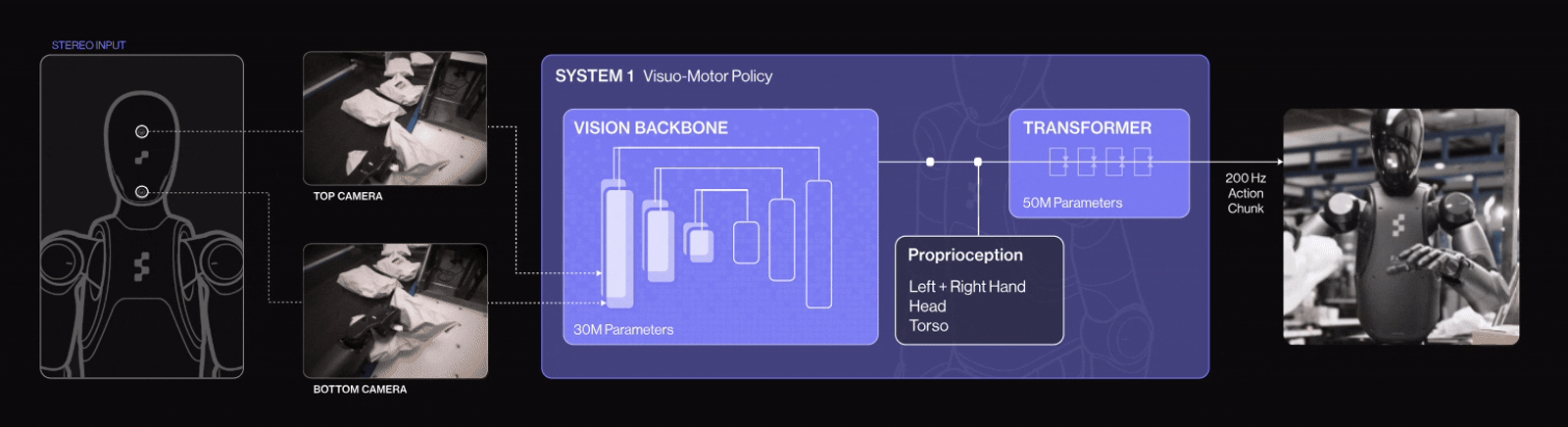
These improvements make Figure 02 robots faster, more precise, self-adjusting, and robust ideal for high-throughput package handling.
Helix AI enables Figure Robot to perform human like task and collaboration. Let’s see the following video example how two Figure robots coordinates and perform the tasks following the instructions.
Figure Robot Collaboration
Different Types Of AI Robots
AI robots integrate artificial intelligence to perform tasks autonomously or semi-autonomously, and they vary widely based on their purpose. AI robots can be categorized based on their functionality, application, or level of autonomy. Below, we explore the main categories, highlighting how AI enhances their functionality.
AI Robots Based On Functionality
This category focuses on the specific tasks or capabilities the AI robot is designed to perform. Based on functionality, AI Robots can be classified into following types.
- Industrial Robots: Used in manufacturing for tasks like monitoring, assembly, welding, painting, or packaging. They are highly precise and operate in controlled environments (e.g., robotic arms in car factories).
- Service Robots: Designed to assist humans in non-industrial settings. Examples include:
- Domestic Robots: Vacuum cleaners, lawn mowers, or personal assistants.
- Healthcare Robots: Surgical robots, rehabilitation robots, or companion robots for elderly or child care.
- Hospitality Robots: Robots in hotels or restaurants for tasks like serving food or guiding guests.
- Entertainment Robots: Built for amusement, like toy robots or robots in theme parks.
- Military/Defense Robots: Used for reconnaissance, bomb disposal, or combat support (e.g., drones, Boston Dynamics’ Spot in military applications).
- Educational Robots: Designed to teach or engage users in learning, such as programmable robots like LEGO Mindstorms.
AI Robots Based On Application Domain
This categorizes robots based on the industry or environment they operate in. These types of robots are following.
- Medical Robots: Assist in surgeries, diagnostics, or patient care (e.g., robotic exoskeletons for physical therapy).
- Agricultural Robots: Handle tasks like planting, harvesting, or monitoring crops (e.g., autonomous tractors or drones for crop surveillance).
- Logistics Robots: Used in warehouses for sorting, packing, or transporting goods (e.g., Amazon’s warehouse robots).
- Space Exploration Robots: Designed for extraterrestrial tasks, like NASA’s Mars rovers (e.g., Perseverance).
- Search and Rescue Robots: Operate in hazardous environments for disaster response (e.g., drones or crawlers in earthquake zones).
AI Robots Based On Level Of Autonomy
This categorizes robots by how independently they operate. These types of robots are following.
- Fully Autonomous: Make decisions and act without human input (e.g., self-driving cars, mobile warehouse bots), using AI for perception and planning.
- Semi-Autonomous: Work alongside humans but still need supervisory input (e.g., surgical bots like da Vinci).
- Teleoperated: Controlled remotely by humans, with AI assistance for stabilization and perception (e.g., underwater ROVs).
- Pre-programmed: Follow explicit instructions with minimal decision-making (e.g., early assembly-line arms).
AI Robots Based On Physical Form
This category classifies robots by their physical structure or movement. These types of robots are following.
- Humanoids: Bipedal form mimicking humans (e.g., Sophia, Atlas) for interaction and manipulation in human-centered environments.
- Wheeled Robots: Mobile platforms (e.g., delivery bots) using wheels and AI navigation.
- Legged Robots: Use legs to traverse rough terrain, AI controls balance, perception and walking (e.g., Spot, ANYmal).
- Drones: Aerial robots for surveillance, delivery, and mapping with onboard vision and autonomous flight.
- Soft Robots: Made with flexible materials, ideal for handling delicate items or interacting with humans (e.g., soft grippers).
AI Robots Based On AI Capability
This categorizes robots based on the sophistication of their AI systems. These types of robots are following.
- Reactive AI: Uses real-time sensor input, no memory or learning (e.g., basic obstacle-avoiders).
- Limited-Memory AI: Recall recent states (e.g., autonomous vehicles that use past frames for decision-making).
- Theory-of-Mind AI: Understands human emotions and intentions, still largely experimental (e.g., advanced social bots).
- Self-Learning AI: Learn and adapt over time via ML or RL (e.g., drones that learn optimal navigation routes through training).
AI is transforming robotics in powerful ways. Many robots fall into multiple categories like humanoid medical assistants combining caregiving with mobility. Advanced AI technologies, especially computer vision, natural language processing, and machine learning, give robots the ability to see, understand, decide, and adapt autonomously. The categorical distinctions between robotic systems are increasingly converging due to the integration of generalized, multimodal AI capabilities making them more versatile.
AI Models Revolutionizing Robotics: Top Computer Vision Models for Robotic Applications
The world of robotics is changing a lot because of advanced AI. These AI models help machines see, understand, and interact with their surroundings better than ever before. They allow robots to move around on their own and handle objects precisely. Essentially, these AI models act like the brains for robots, helping them understand their environment with great accuracy and intelligence. Let's look at some of the most powerful AI models that are helpful for the future of robotics.
We will explore some of the key performance models for various tasks in robotics such as object detection (RF-DETR), keypoint detection (YOLO-NAS Pose), instance segmentation (SAM 2), semantic segmentation (SegFormer), VLM (PaliGemma, Qwen2.5 VL) and multimodal modal (GPT-4o).
RF‑DETR
RF‑DETR is Roboflow’s transformer-based object detection model designed for real-time, high-accuracy performance. It comes in two configurations, Base (29M parameters) and Large (128M parameters), and breaks the 60+ mAP barrier on the COCO dataset. Its architecture blends a DINOv2-pretrained backbone with lightweight DEtection TRansformer (LW-DETR) decoding under an Apache 2.0 open-source license.
RF‑DETR stands out by combining top-tier detection accuracy with low latency and adaptability. It’s ideal for real-world robotic systems requiring reliable object detection across diverse conditions, from industrial to domestic environments.
The following are the key benefits of using RF-DETR for robotics applications:
- Real-time Perception for Autonomous Robots: With processing times around 6 ms per image on T4 GPUs and no NMS overhead, RF‑DETR enables robots to scan environments continuously and react immediately to changes such as identifying a fallen box on a conveyor belt or a tool dropped on a factory floor.
- High-Precision Detection Across Diverse Domains: Achieving over 60+ mAP on COCO and strong performance on RF100‑VL, RF‑DETR excels across environments from industrial setups to orchards allowing robots to detect both common and novel objects with confidence.
- Edge AI Deployment: RF-DETR can be deployed on edge devices like NVIDIA Jetson or even Intel OpenVINO setups for real-time inference essential for robotics applications.
- Domain Adaptability for Custom Use Cases: Trained on 100+ RF100‑VL datasets and fine-tuning option, it empowers robots for various specialized tasks like pick and place sorting, part detection etc. in a warehouse or industrial environment.
RF‑DETR stands out by combining top-tier detection accuracy with real-time speed and adaptability. It’s ideal for real-world robotic systems requiring reliable object detection across diverse conditions, from industrial floors to domestic environments.
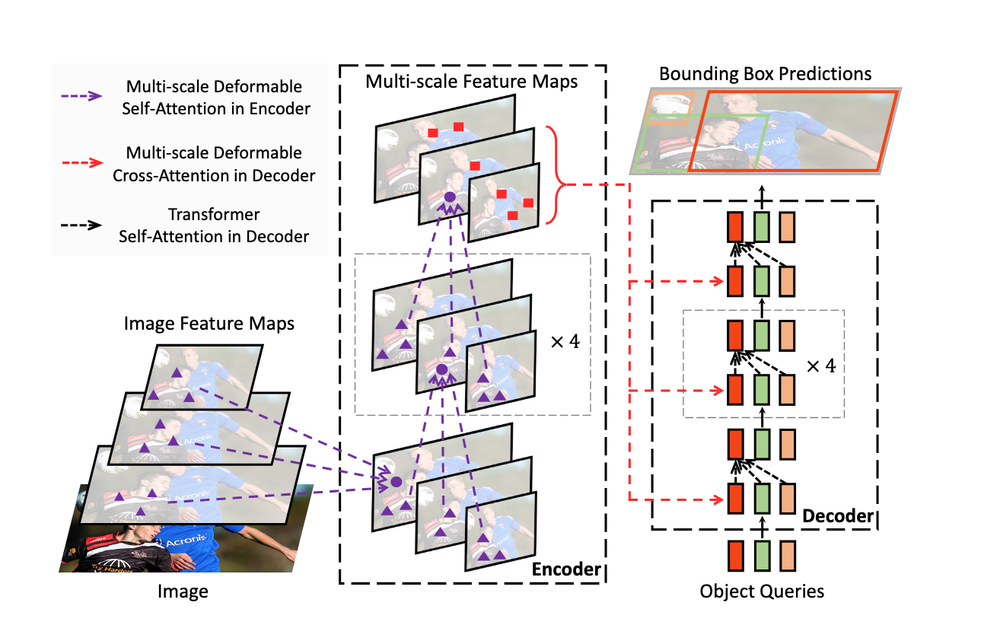
YOLO‑NAS Pose
YOLO‑NAS Pose is a state-of-the-art keypoint detection and pose estimation model crafted by Deci AI. Built upon the efficient YOLO‑NAS object detection backbone, it performs real-time estimation of body or object keypoints (joints, landmarks) in just one inference sweep. It is open-source under the Apache 2.0 license and available in Roboflow.
The following are the key benefits of using RF-DETR for robotics applications:
- Ultra-Low Latency Pose Estimation: YOLO‑NAS Pose delivers up to 425 FPS on NVIDIA T4 and still achieves 20–63 FPS on edge devices like Jetson Xavier NX, ensuring robots can perceive and react to human or object movements in real time.
- High Accuracy with Efficient Models: Due to Deci’s AutoNAC neural architecture search, it achieves state-of-the-art pose estimation accuracy, outperforming YOLOv8 Pose across all model sizes without sacrificing speed.
- Single-Step, End-to-End Inference: Its unified architecture detects people (or objects) and estimates poses in one pass, reducing computational overhead and simplifying deployment which is critical for resource-constrained robotic systems.
- Scalable for Edge Deployments: Available in Nano, Small, Medium, and Large variants, YOLO‑NAS Pose can be tailored for different robot platforms, from high-performance servers to compact embedded units, without losing inference speed or accuracy.
YOLO-NAS Pose is fast, highly accurate, and detects poses in a single step. This makes it perfect for robotics, especially for safety checks, human-robot interaction, and real-time pose tracking.

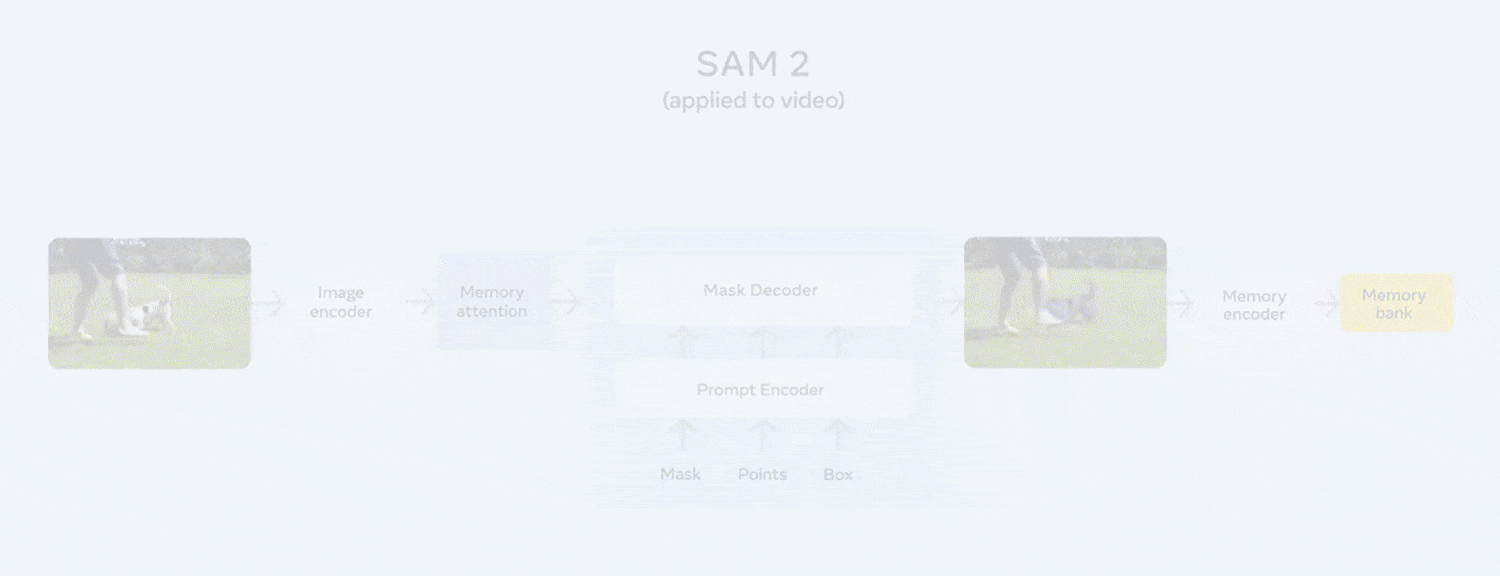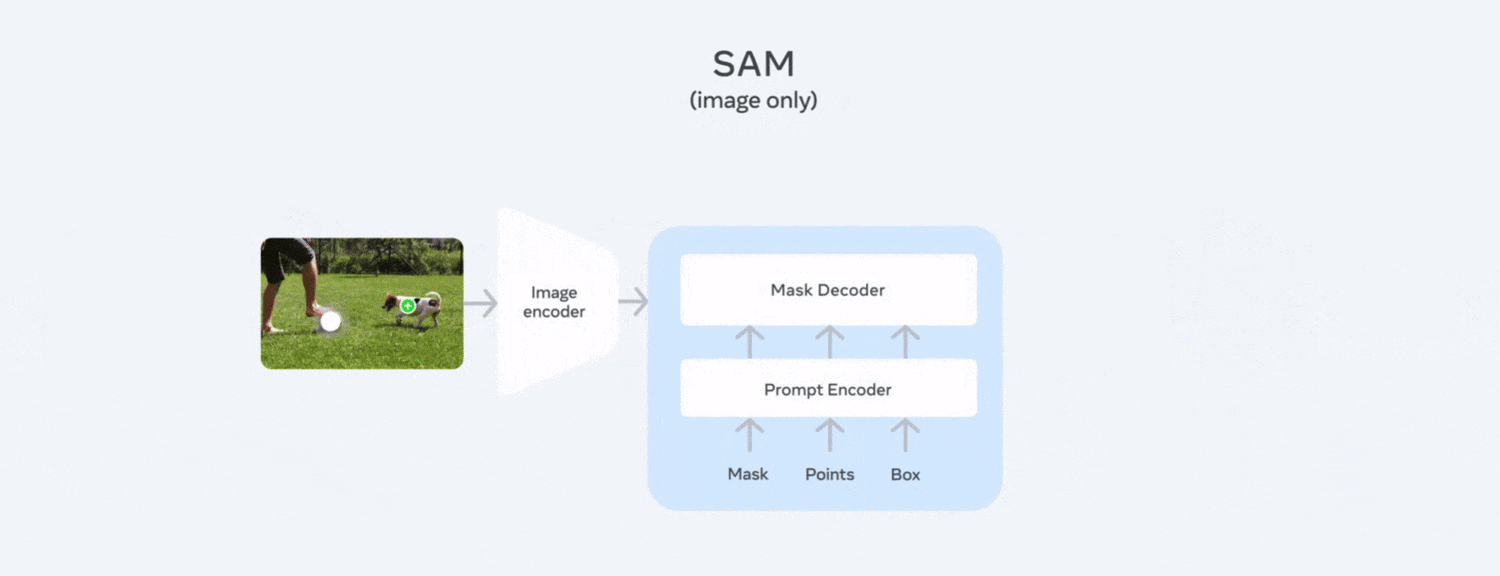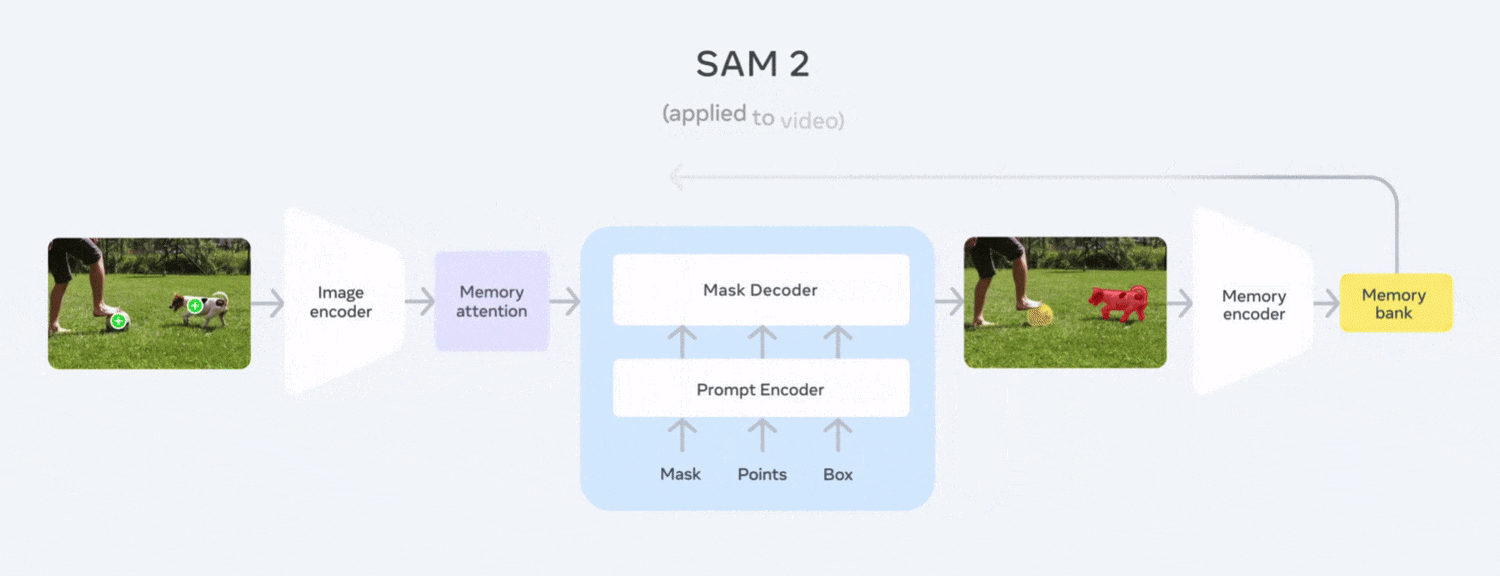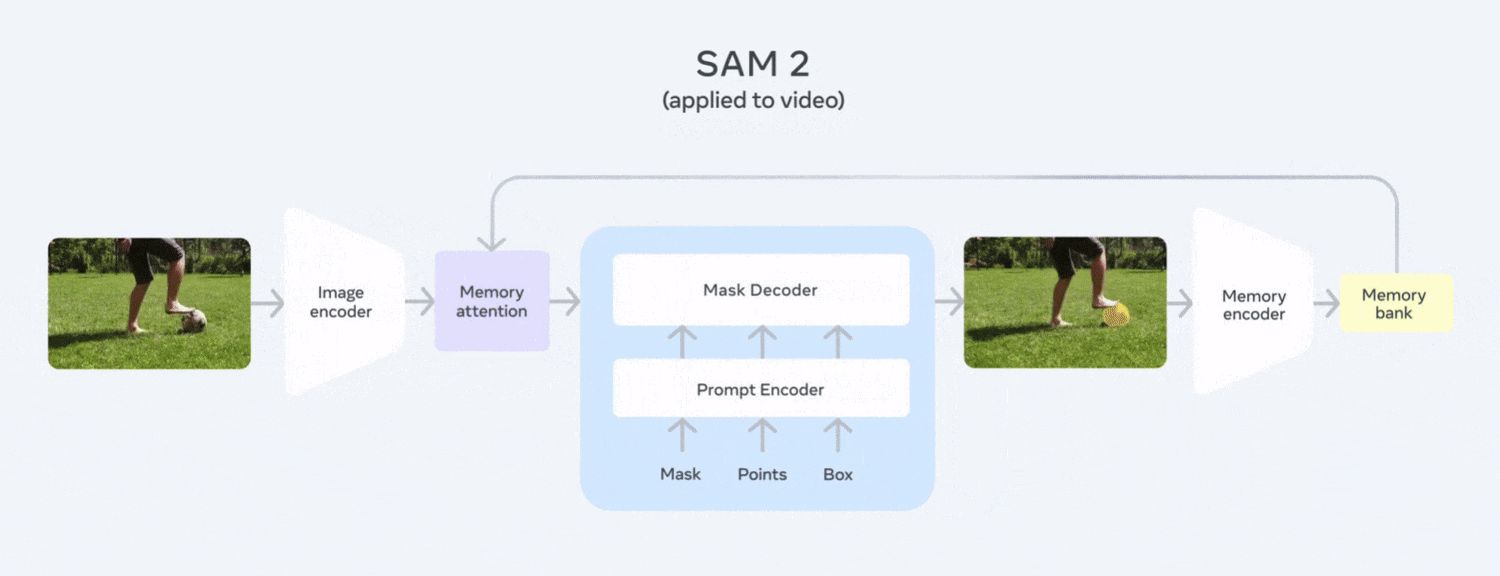
Segment Anything 2 (SAM 2)
Segment Anything 2 (SAM 2), an evolution of Meta’s foundation model that delivers promptable, pixel-level segmentation across both images and video. It supports interactive inputs such as clicks, box or mask to isolate any object instantly without fine-tuning. It’s released under an open-source Apache 2.0 license and available in Roboflow.
The following are the key benefits of using SAM 2 for robotics applications:
- Unified Image & Video Support: One model handles both images and videos treating live camera input as real-time video that simplify perception pipelines for mobile and dynamic robot platforms.
- Memory-Aware Temporal Consistency: Built-in memory and attention mechanisms track objects smoothly across frames, even through occlusions and camera movements which is critical for persistent object tracking during navigation or manipulation.
- Promptable, Zero-Shot Segmentation: Able to segment any object on the fly with minimal prompting without task-specific training, ideal for robots encountering new items in unstructured environments.
- Real-Time Performance: Fast enough to run alongside robot control loops, enabling responsive decision-making such as grasping, obstacle avoidance, and environment mapping.
- Robustness to Occlusions & Visual Noise: Demonstrates high resilience in complex scenes, including surgical tool tracking, camera shake, blur, and real-world visual distortions which is required for safe robotic operation.
The ability of SAM 2 to promptably segment diverse objects, track them consistently across video, generalize zero-shot, and run in real time makes it an invaluable perception tool for robotics. It can be utilized in use cases such as locating items to pick, tracking humans during collaboration, or mapping complex environments such as robotic surgery. SAM 2 brings reliable, precise visual understanding to onboard AI systems.
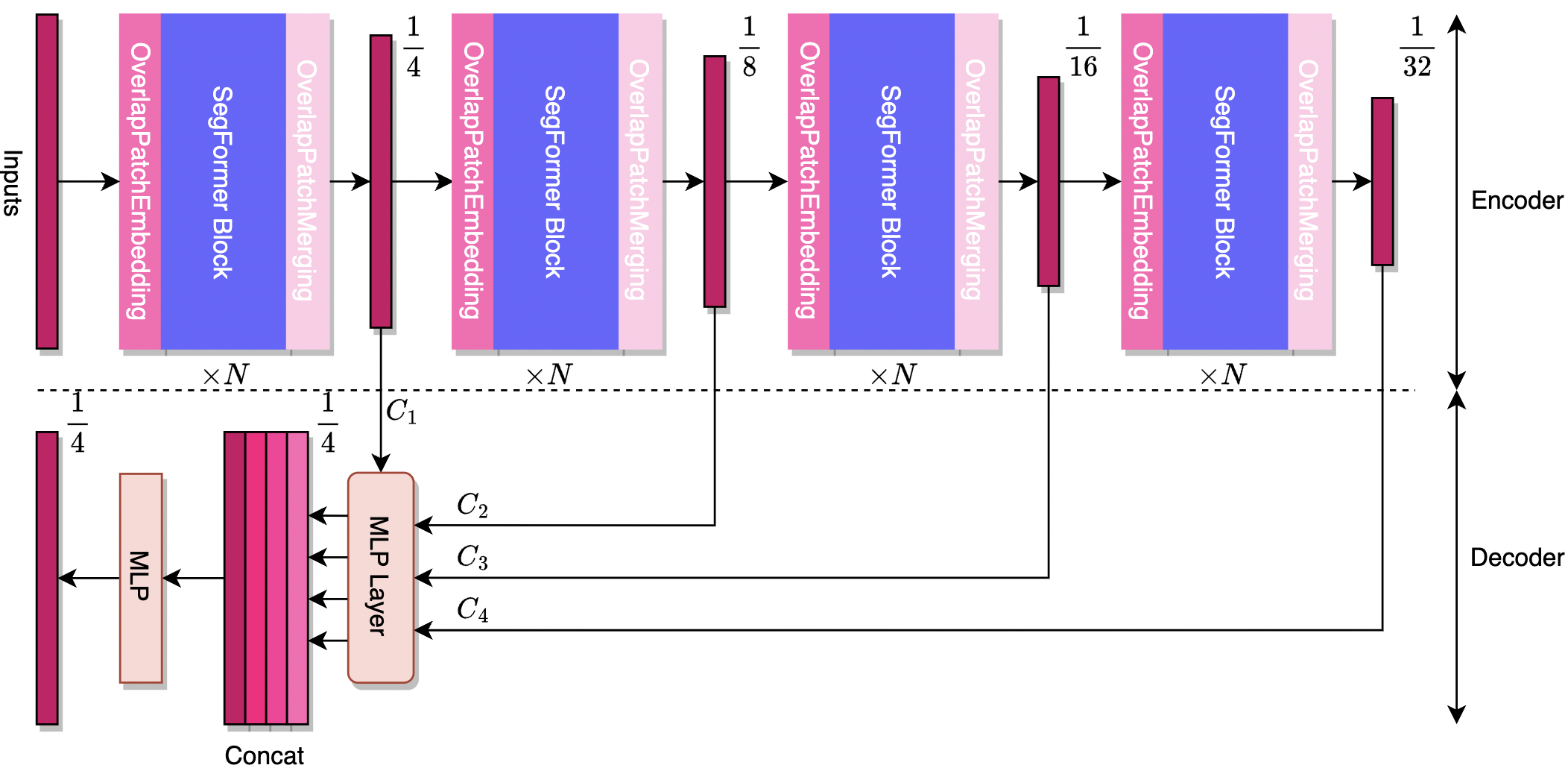
SegFormer
SegFormer is a semantic segmentation model combining a hierarchical Transformer encoder (Mix Transformer) with a lightweight multilayer-perceptron (MLP) decoder. It processes images at multiple scales without positional encodings and achieves state-of-the-art accuracy with high efficiency. SegFormer-B4 scores 50.3% mIoU on Cityscapes using just 64M parameters.
The following are the key benefits of using SegFormer for robotics applications:
- Multi-scale perception with global context: The hierarchical Transformer encoder captures detailed local features and broader scene context simultaneously, important for robots that must understand both fine and large-scale elements in an environment.
- Lightweight all-MLP decoder: With a simplified decoder design, SegFormer avoids heavy convolutional processing, enabling fast and efficient inference which is good for robotic applications.
- Resolution-agnostic performance: By eliminating fixed positional encodings, SegFormer generalizes well across varying image sizes. This is important for robotics systems encountering diverse camera feeds during navigation.
- Robust segmentation under real-world conditions: Strong zero-shot resilience demonstrated on corrupted Cityscapes (Cityscapes-C) indicates reliable performance despite motion blur, lighting changes, or environmental noise.
- Broad scalability (B0-B5 variants): Ranging from ultra-light (B0) to high-capacity B5, SegFormer allows robotics developers to balance model size, speed, and accuracy according to hardware constraints from compact drones to powerful factory robots.
SegFormer is a state-of-the-art Transformer-based model for real-time semantic segmentation, featuring a hierarchical encoder and efficient all-MLP decoder that together enable fast, accurate scene parsing. It allows robots to perform real-time terrain and obstacle segmentation, precise object boundary detection, and robust operation in dynamic environments, all without needing retraining. With model variants, SegFormer delivers scalable performance powerful enough for complex robotic perception tasks and lightweight enough for edge deployment.
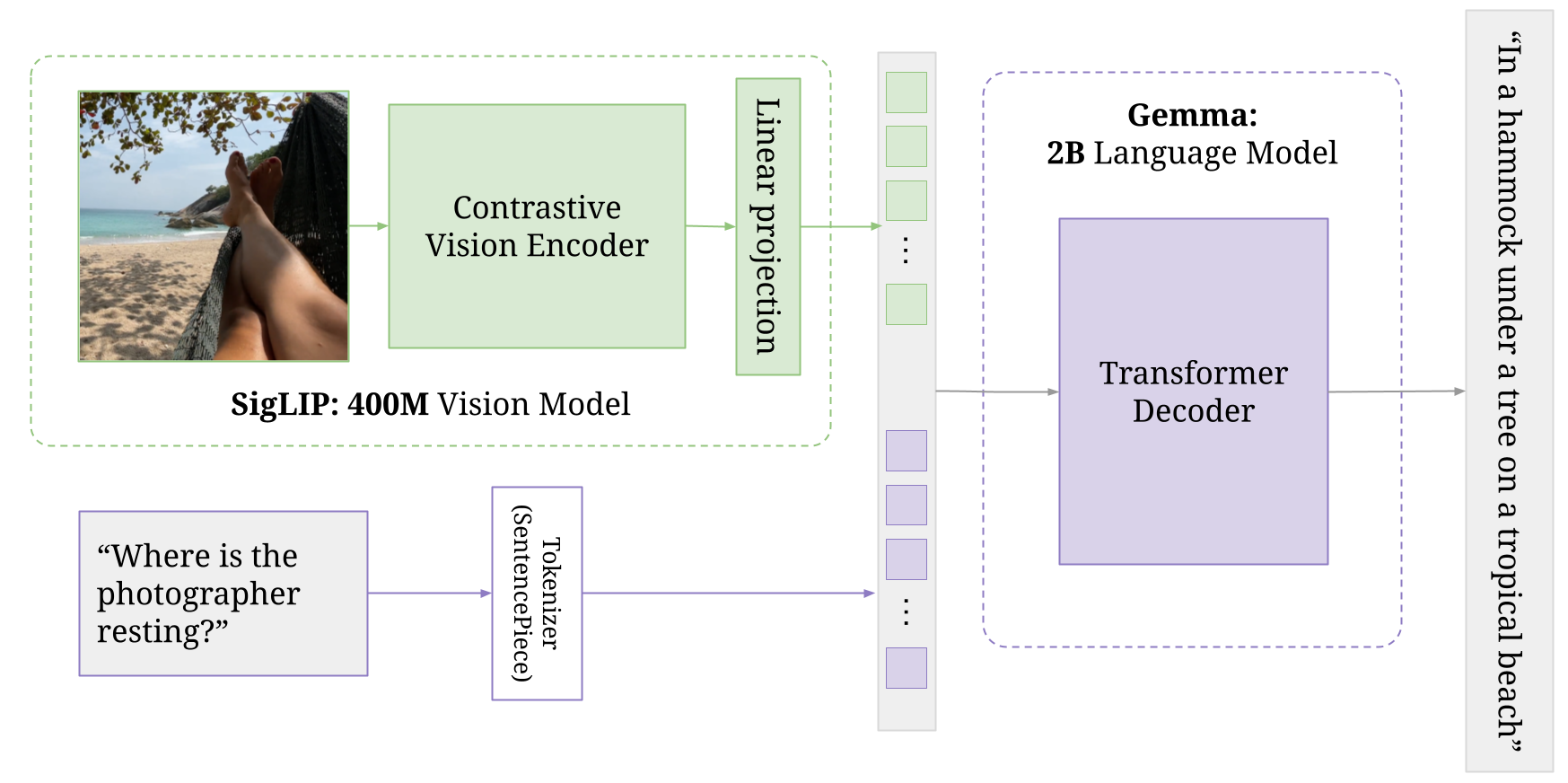
PaliGemma
PaliGemma is a compact, open multimodal VLM introduced by Google. It merges a SigLIP vision encoder with a Gemma-2B language model, enabling the system to process both images and text as input, and produce textual or action-oriented outputs.
The following are the key benefits of using PaliGemma for robotics applications:
- Balanced size-performance: At only 3B parameters, PaliGemma delivers strong vision-language understanding while remaining lightweight enough for on-device (i.e. NVIDIA Jetsons) robotic deployment.
- Multimodal perception: Capable of tasks like image captioning, visual question answering, referring segmentation, and object detection, PaliGemma offers robots a unified framework for seeing and understanding their environment.
- Fine-tuneable and task-adaptable: Available in three versions i.e. pretrained (PaliGemma PT), task-finetuned (PaliGemma FT), and mixed (PaliGemma mix). PaliGemma allows customization for specific robotic uses, from inventory management to interactive assistance.
- Scalable resolution support: PaliGemma 2 extends capabilities with higher input resolutions (224×224 to 896×896), making it suitable for fine-grained visual tasks like part inspection or control panel monitoring in robotic cells.
- Strong generalization across tasks: Its high performance on various benchmarks ranging from captioning to document recognition and medical imaging ensures the model supports robust comprehension in diverse operational contexts.
PaliGemma delivers a compact yet capable multimodal model ideal for robotics. Its feature-rich architecture makes it adept for use cases like visual question answering, object recognition, scene interpretation, and interactive dialogue and enable robots to see, understand, and respond effectively in complex environments.
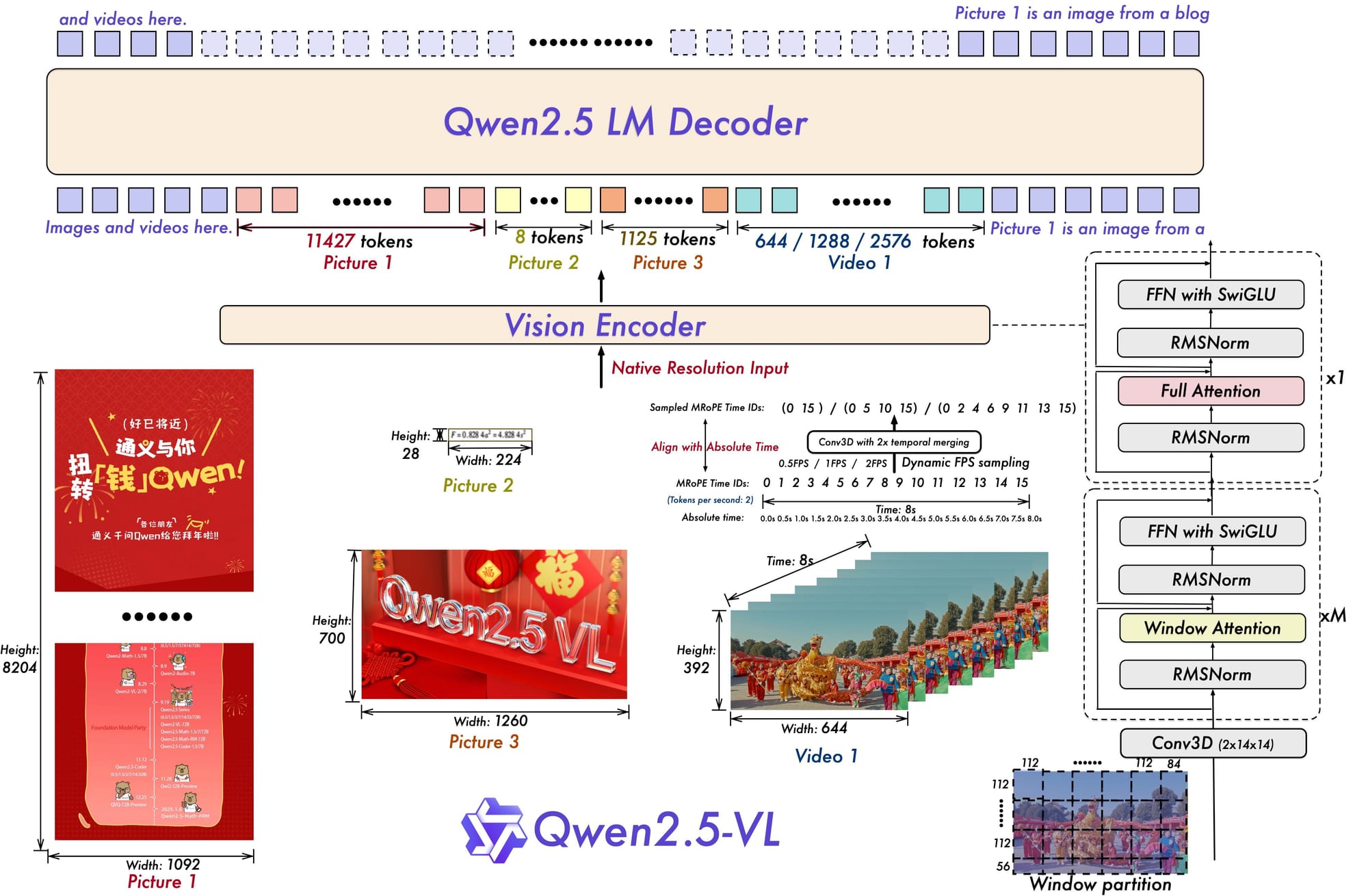
Qwen2.5‑VL
Qwen2.5‑VL is Alibaba Cloud’s advanced vision‑language model series, available in multiple sizes (3B, 7B, 72B parameters). It combines a native Vision Transformer (ViT) with multimodal rotary position embeddings and dynamic resolution/frame-rate support, enabling unified understanding of images, documents, and long videos.
The following are the key benefits of using Qwen2.5‑VL for robotics applications:
- Vision-Language Reasoning at Any Scale: Its ViT supports dynamic resolution processing and handles varying image and video sizes, including hour-long clips which make it ideal for inspection robots, autonomous drones, and continuous monitoring systems.
- Precise Object Localization & Grounding: Qwen2.5‑VL accurately identifies and localizes objects using bounding boxes or point coordinates, with structured JSON outputs, ideal for pick-and-place, navigation, or scene analysis.
- Robust OCR & Document Parsing: With omni-document parsing including tables, handwritten text, and forms, the model supports mobile robots or logistics systems that need to scan labels, signs, and documents autonomously.
- Advanced Video Understanding: The model excels in long-video comprehension, using temporal encoding (M-RoPE) and dynamic frame-rate sampling which is key for surveillance robots, autonomous inspection units, or media-analysis drones.
- Multilingual & Multimodal Reasoning: Supports multiple languages across visual tasks like document Q&A, scene description, and UI understanding. It is useful for globally deployed robots in multilingual environments.
- Modular Scalability: Available in compact (3 B), mid-range (7 B), and large (72B) variants. Qwen2.5‑VL offers flexible deployment from edge devices (e.g. Jetsons) to cloud-based robotics fleets.
Qwen2.5‑VL merges advanced visual perception, object grounding, document intelligence, and long-video reasoning into one model. Its versatile, multilingual capabilities and multi-resolution support make it a powerful foundation for robotics applications from warehouse inspection and package reading to autonomous navigation, surveillance, and intelligent human-robot interaction.
GPT 4o
GPT‑4o (omni) is OpenAI’s flagship multimodal generative pre-trained transformer. It natively accepts text, images, audio, and video as inputs and can output responses in the same modalities all within a single unified model.
The following are the key benefits of using GPT-4o for robotics applications:
- Multimodal input/output: Robots can feed simultaneous voice, camera, and visual sensor data into GPT‑4o and receive integrated outputs such as text responses, audio feedback, and even visual understanding without needing separate models.
- Real-time low latency: Responds with small delay (low latency) on average, It enable robots to engage in flowing, conversational interactions and timely motor decisions.
- Vision + audio understanding: Achieves state-of-the-art results in multimodal benchmarks which enhances situational awareness and interaction capabilities of a robot.
GPT‑4o equips robots with human-like multimodal intelligence, allowing them to perceive complex scenes, understand spoken and visual prompts, reason across modalities, and respond swiftly and naturally.
AI In Robotics Examples
In this section, we’ll explore some of the cutting-edge robots powered by AI models.
NEO Gamma
The NEO Gamma is a next-generation home humanoid robot designed by 1X Technologies, equipped with compliant, tendon-driven motion and soft protective covers for safe human interaction within domestic settings. It uses Redwood AI, a compact vision-language transformer developed for humanoids, running fully onboard its embedded GPU. Redwood bridges perception and action end-to-end. It jointly controls whole-body locomotion and mobile manipulation including walking, running, climbing stairs, kneeling, retrieving objects, and leaning etc. as a unified system. Trained on a wide array of teleoperated and autonomous episodes from real-world home environments, Redwood learns to generalize to novel objects and layouts, thanks to auxiliary tasks like hand and object localization that keep its representations grounded. In combination, NEO Gamma + Redwood AI represents a milestone in home robotics, enabling a humanoid to perceive, reason, and act autonomously in unstructured environments without relying on cloud connectivity.
NEO Gamma is 1X Technologies’ next-gen home humanoid robot, designed for everyday interaction with soft tendon-driven joints, compliant whole-body movement, and quiet operation akin to a household appliance. Powered by Redwood AI, a compact 160M-parameter vision-language transformer built for mobile manipulation, NEO Gamma performs real-world chores like opening doors, retrieving items, and navigating the home entirely onboard, no cloud needed.
Key AI features of NEO Gamma:
- Vision-Language Transformer: Redwood AI fuses language embeddings, visual tokens, and sensor data into a unified latent representation which enable it for context-aware mobile manipulation.
- Whole-body & Multi-contact Manipulation: Controls walking, torso, and arm movements simultaneously to support behaviors like leaning against surfaces or picking up items from the floor.
- Mobile Bi-manual Coordination: Trained end-to-end on diverse teleoperated and autonomous episodes, it learns to choose appropriate hands and navigate while manipulating in dynamic home environments.
- Cognitive Grounding Losses: Predicts auxiliary tasks like hand and object localization during training, which strengthens its ability to generalize to unseen objects and layouts.
- Voice-command Integration: Uses speech-to-text from an external LLM to derive user goals, then converts them into embeddings fed into Redwood AI, enabling intuitive voice-directed operation.
NEO Gamma Robot
Digit
Digit is Agility Robotics’ versatile humanoid robot, uses AI-driven perception, autonomy, and manipulation to work in real-world environments like warehouses and distribution centers. The demo video showcases Digit interpreting language prompts, processed by a large language model (LLM), which then guide its task planning and execution, demonstrating seamless integration of vision, language, and control.
Key AI features of Digit:
- Vision-based perception: Onboard depth cameras and LiDAR feed into neural networks for obstacle recognition, path planning, and scene understanding.
- Language-driven task planning: The robot uses an LLM to translate verbal or textual instructions into a structured action plan.
- Reinforcement-learned locomotion and manipulation: Digit’s smooth walking, precise grasping, and stable recovery are powered by RL-trained policies that enable it to handle objects and resilience in varied settings.
This integration enables Digit to see, understand, and act merging computer vision, natural language understanding, and model-based control into a unified, intelligent robotic system.
Digit Robot
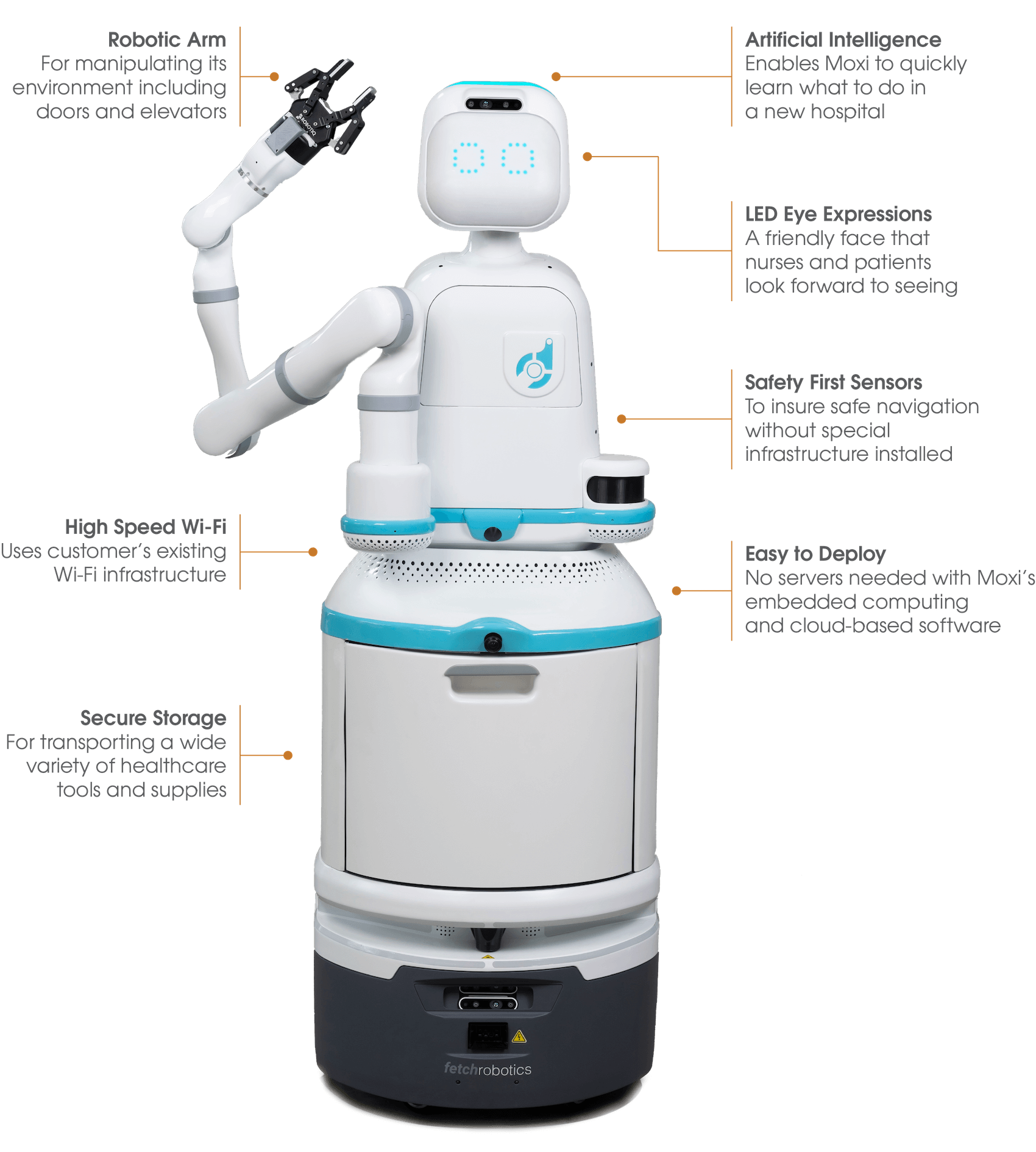
Moxi
Moxi from Diligent Robotics is an autonomous, socially intelligent mobile robot assisting medical staff by handling routine supplies and specimen deliveries across hospital environments. It performs complex actions such as navigating halls, opening doors, riding elevators, and interacting comfortably with staff and patients.
Key AI Features:
- Vision & Mapping: Uses front-facing cameras, LiDAR, and sensor fusion to map and recognize pathways, rooms, elevators, and doors, creating an accurate internal environment model during its initial deployment.
- Adaptive Navigation: Employs self-driving algorithms adapted for hospital settings to dynamically avoid people and obstacles, recalibrate routes, and operate over Wi-Fi or LTE with fallback systems.
- Human-guided Learning: Can learn new tasks through direct demonstration staff physically guide Moxi’s arm, with simultaneous voice cues, allowing it to store complex manipulation behaviors semantically.
- Social Intelligence: Displays intuitive face-like LEDs and social cues; interacts via kiosks, mobile devices, or EHR-integrated systems and engages with staff through simple voice interactions.
ANYmal
ANYmal by Anybotics is an autonomous, all-terrain quadruped robot designed for industrial inspection tasks in harsh environments like chemical plants, mines, and railways.
Key AI Features:
- AI-based Mobility & SLAM: ANYmal uses its 360° LiDAR, depth cameras, and IMU with SLAM algorithms to continually map complex facilities, localize itself with centimeter accuracy, and autonomously navigate through stairs, ramps, and narrow or rough terrain.
- Reinforcement-Learned Locomotion: Its agile and robust gait, including climbing grated stairs and slippery surfaces, is enabled by reinforcement learning optimized in simulation and transferred to real robots, ensuring stability and dynamic adaptation.
- Autonomous Mission Planning & Adaptation: ANYmal can execute inspection missions end-to-end using rule-based logic and adaptive route replanning in real time. It reacts to obstacles, pauses or re-routes when necessary, docks to recharge automatically, and resumes tasks all controlled by onboard AI.
- Edge-Enabled Inspection Intelligence: With built-in visual, thermal, acoustic, and optional gas sensors, AI models run on-device to detect anomalies (e.g., leaks, abnormal vibrations, overheating) and trigger alerts that integrate directly with enterprise databases or digital twins.
ANYmal uses advanced AI in perception, locomotion, autonomy, and inspection analysis to deliver a versatile, reliable, and intelligent robot capable of performing end-to-end industrial inspections without human supervision.
ANYmal
AI In Robotics Projects
Now that we've explored some real-world examples of AI powered robots, let’s dive into current research and experimental projects that are pushing the boundaries of what's possible with AI in robotics.
Ameca Gen 2: Advanced Humanoid Research Platform
Ameca Gen 2 is the second-generation humanoid robot created by Engineered Arts as a research and development platform for human–robot interaction, expressive AI, and modular robotics. Building on the original Ameca (launched 2021), Gen 2 introduces significantly enhanced facial fidelity and lifelike motion, supported by a powerful Tritium 3 OS (a cloud-centric control system that supports over-the-air software updates), telepresence, and fleet management.
Key AI & system features of Ameca:
- High-Fidelity Facial Expression: Equipped with 27 facial actuators and 5 neck motors, Ameca Gen 2 delivers nuanced expressions, like surprise, dismay, joy, and confusion all powered by algorithms that interpret detected emotions and map them into synchronised micro-movements.
- Multimodal Perception + Conversational AI: Uses binocular eye cameras, a chest camera, and microphones to detect faces, emotions, age, and gender. Coupled with GPT‑3 conversational AI, it supports smooth, context-aware dialogue, enabling interactive social engagements.
- Modular & Cloud-Connected Architecture: The modular hardware design allows easy upgrades like swapping components like arms or head units. Tritium 3 supports cloud-connected development, API access, telepresence, simulation tools, and intuitive browser-based programming.
- Smart Social Behaviors: Ameca uses face tracking and attention modeling to maintain natural eye contact, adjust gaze, recognize personal space, and deploy pre-programmed gestures (e.g., waves, shrugs) in response to speech and user presence
Ameca Gen 2 is a leading-edge humanoid research project emphasizing expressive interaction, multimodal intelligence, and cloud-upgradable design. It offers a reliable, modular platform for exploring empathy, telepresence, and AI-based social behavior specifically meant for R&D labs, educational environments, exhibitions, and development use, not locomotion or physical workloads.
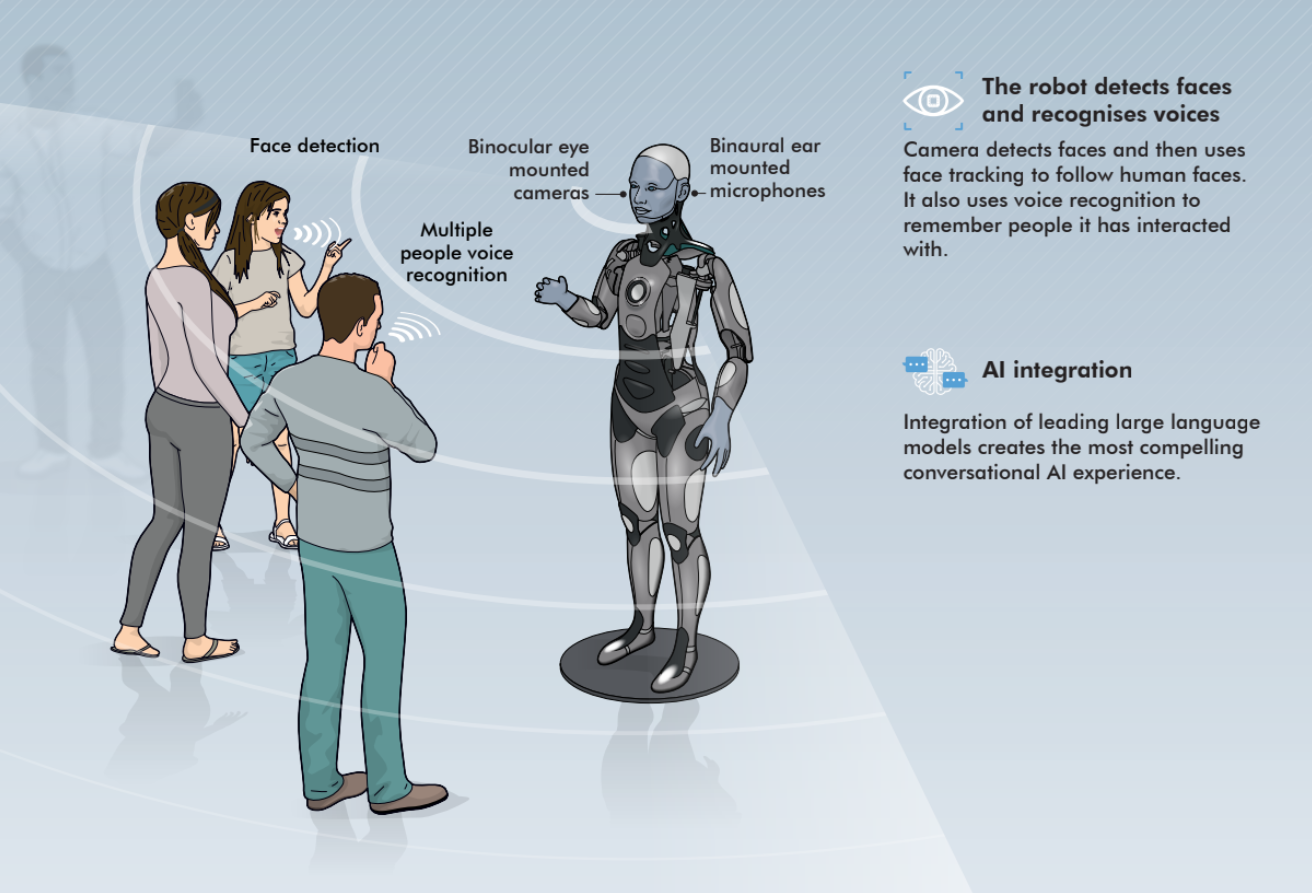
Trinity: A Modular Humanoid Robot AI System
Trinity is a pioneering AI architecture designed to endow humanoid robots with the capacity to understand natural language, perceive their environment, and execute full-body movements through a modular, hierarchical integration of three AI domains that are reinforcement learning (RL), visual-language models (VLM), and large language models (LLM).
System modules of Trinity:
- Reinforcement Learning Locomotion: Utilizes Proximal Policy Optimization (PPO) and Adversarial Motion Priors (AMP) to train robust, human-like bipedal walking and balance policies in simulation. These policies transfer to real hardware, enabling smooth and adaptive motion.
- Vision-Language Model Perception: Processes RGB-D camera input to detect objects and scene elements. The VLM builds semantic and spatial awareness, generating visual tokens e.g., bounding boxes and depth data to feed into the planner.
- Language-Based Task Planning: Parses natural language instructions with an LLM, decomposing complex tasks into sequential steps. The planner integrates environmental constraints and safety rules, outputting a task graph to the control module.
- Modular, Hierarchical Integration: Trinity’s framework is purposefully modular. Each AI component (RL, VLM, LLM) is independently trained and optimized. A hierarchical controller then orchestrates them. Vision feeds perception, language provides context and RL executes physical motion with clear semantic and safety boundaries.
Trinity marks a significant step toward embodied general intelligence by uniting perception, reasoning, and action in a full-scale humanoid. Through its modular design, it offers scalability, interpretability, and real-world feasibility and opening pathways for future autonomous humanoids capable of language-guided physical tasks.
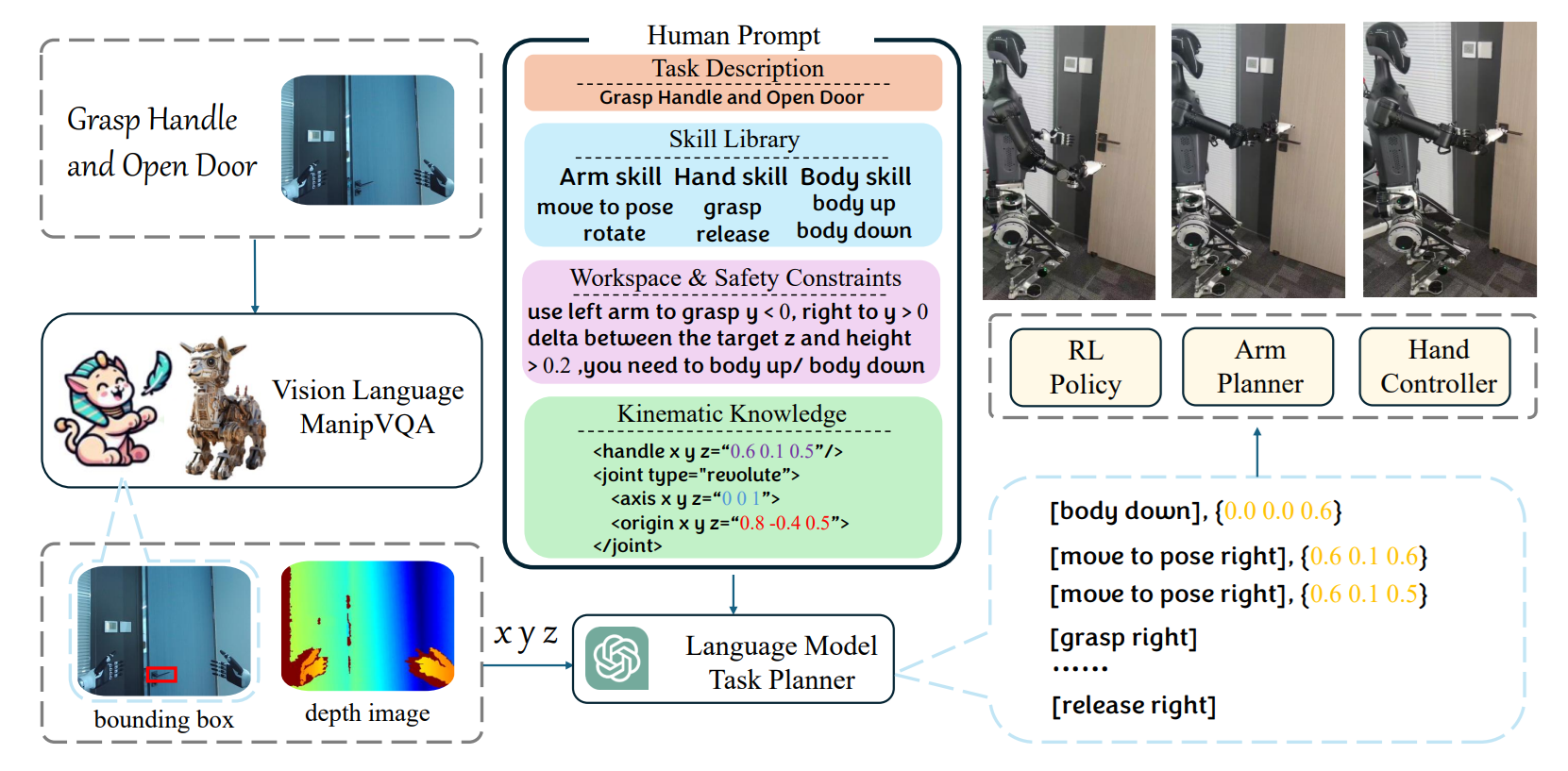
OptoMate: AI based Robotic Automation for Free-Space Optics
OptoMate is an autonomous platform that combines generative AI, computer vision, and precision robotics to fully automate tabletop free-space optics experiments, tasks that previously required meticulous manual setup or operation. It was introduced in May 2025 in research paper titled AI‑Driven Robotics for Free-Space Optics.
Key AI features & workflow integration of OptoMate:
- LLM-Based Experimental Design: Researchers provide high-level goals and a fine-tuned large language model interprets them into structured optical setup instructions such as selecting components, specifying placements, and generating control scripts.
- Precision Pick-and-Place with Vision: A robotic arm, guided by high-resolution cameras, identifies optical components (lenses, mirrors, beam splitters) and performs sub-millimeter accurate pick-and-place assembly. Vision algorithms also detect misalignments and correct position drift.
- Fine Alignment & Calibration: Using a custom robot-mounted alignment tool, OptoMate iteratively refines optical alignment like adjusting tilt, rotation, and focus until beam quality goals are met.
- Automated Experiment Execution & Measurement: Once assembled and aligned, the system runs experiments autonomously, such as beam characterization, polarization mapping, and spectroscopy and collect and process data to fulfill the initial research objective.
OptoMate represents a significant leap in scientific robotics: a fully autonomous AI-controlled system that integrates design, assembly, alignment, and measurement of optics experiments which make it as the first of its kind and paving the way for self-driving labs and robotic scientific instruments.

AI In Robotics Companies
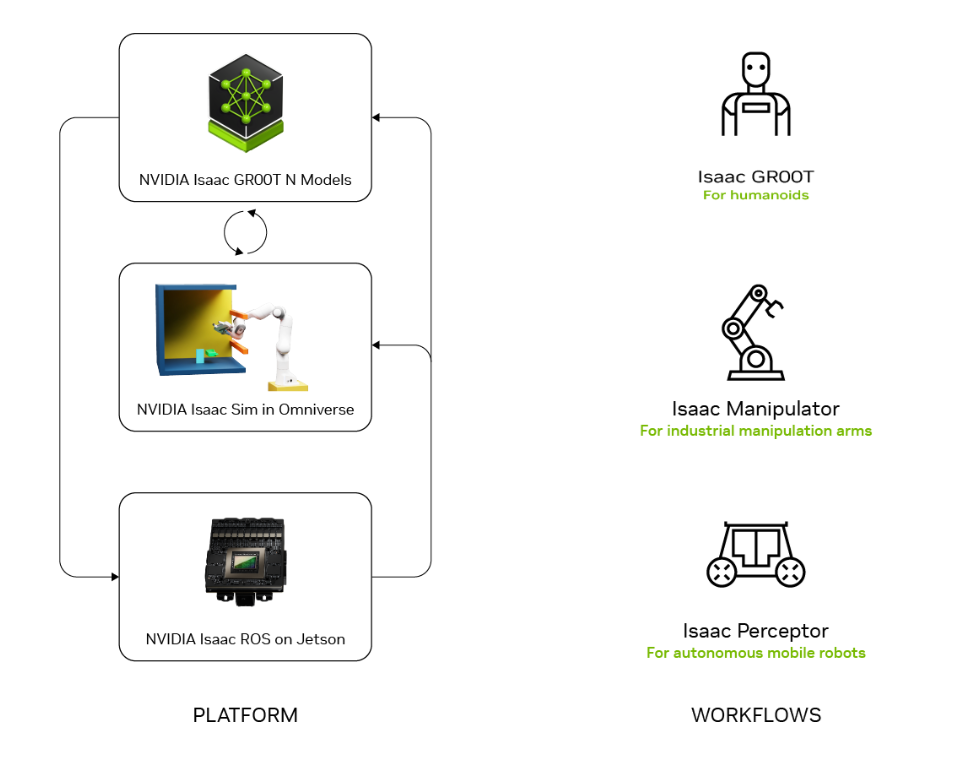
NVIDIA
NVIDIA empowers robotics with its end-to-end AI compute platforms from simulation to deployment. Its Isaac platform offers CUDA accelerated libraries and frameworks for perception, manipulation, and navigation. The Jetson family (Nano, Orin, Thor) delivers powerful, energy-efficient edge AI, capable of running vision-language models and ROS-based workloads. NVIDIA collaborates with robotics leaders (e.g., Universal Robots, MiR, Doosan) to bring AI‑powered simulation and inference to industrial and service applications.
Roboflow
Roboflow is a complete platform for computer vision development. It covers dataset management, annotation tools, model training, low-code workflow orchestration, and edge/cloud deployment. Roboflow provides an end-to-end pipeline for vision-based robotic systems including custom model training & pre-trained models, broad computer vision task support such as object detection, keypoint estimation, semantic/instance segmentation, object tracking, OCR, and vision-language workflows. It provides low-code Workflows builder tool. It enables various model deployment options via hosted API endpoints or self-hosted inference servers with SDKs.
Figure AI
Figure AI is pioneering humanoid robots for real-world applications such as logistics and home assistance. Their latest model, Helix, operates with near-human speed and uses AI based perception and motor control, including touch and short-term memory, to perform tasks like package handling continuously over long durations. Backed by major investors including OpenAI and Nvidia, Figure is purpose-built to bring "thinking" robots into everyday environments.

Building A Robot AI Assistant With Roboflow
Let’s explore how to build a Robot AI assistant using Roboflow Workflows. The platform offers a wide range of pre-trained models for tasks like object detection, keypoint estimation, segmentation, and even multimodal processing that integrates image/video with text. In this example, we’ll use Roboflow’s low-code Workflow interface to create a vision-powered assistant that runs on an edge device of a robot with mounted camera.
In this example we will create a multimodal Robot AI Assistant that integrates live video, natural language commands, and real-time AI reasoning. The user speaks a command, the system captures it as text and pairs it with video frames. These inputs are sent to a GPT‑4o Vision-Language block within Roboflow Workflows, which understands the visual context and generates an intelligent response. That reply is then converted into spoken audio, allowing the robot to “see,” “understand,” and verbally respond to queries about its environment.
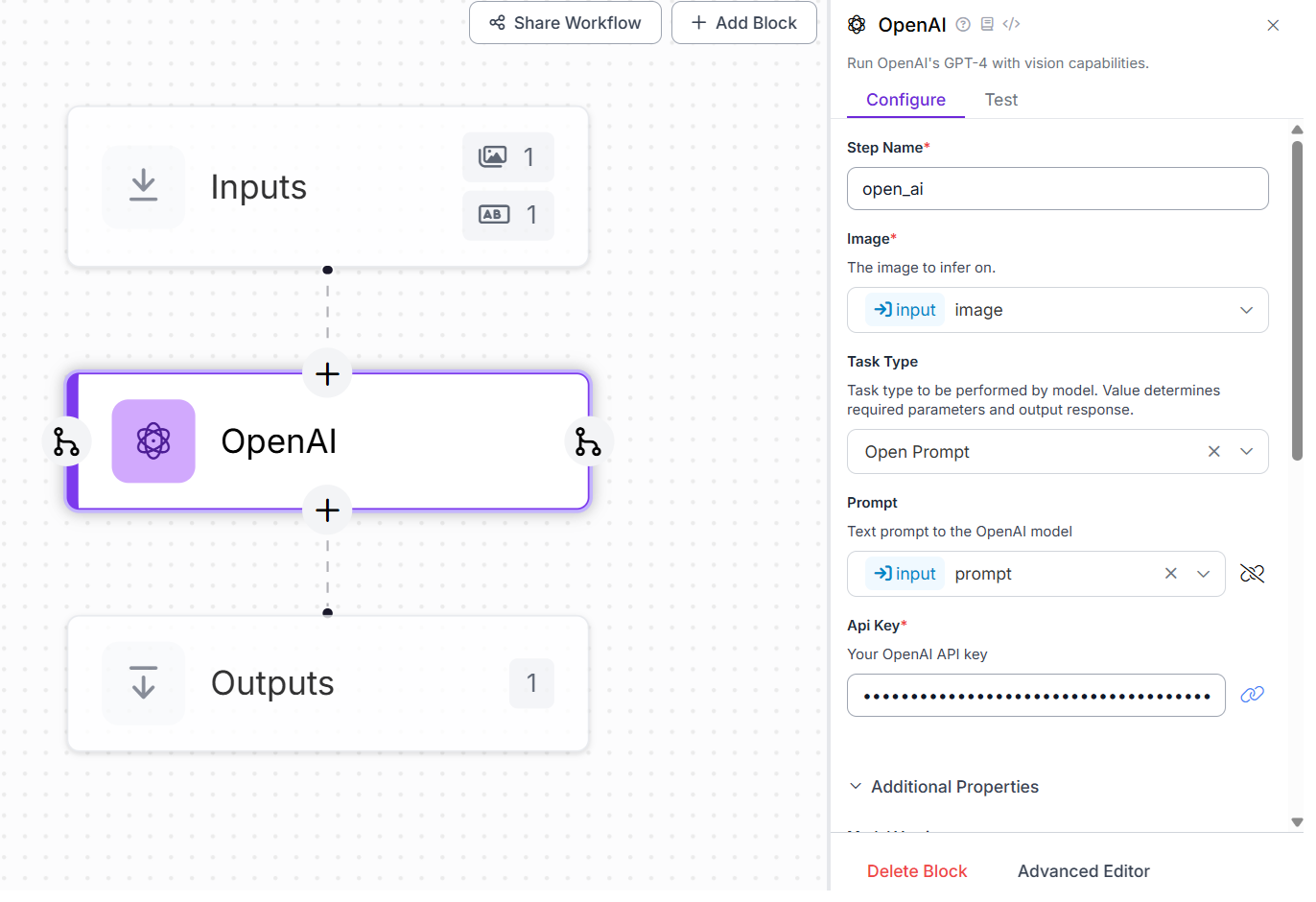
For this example, first build the Roboflow Workflows. This Roboflow Workflow enables a robot-mounted assistant to capture live video, accept a text prompt, understand its surroundings, and respond intelligently, all on-device. The system comprises three core components:
- Input Block: Defines two inputs, a text prompt (represents the user's spoken command) and a camera stream feeding video frames into the workflow.
- OpenAI Block: Processes both the video frame and text prompt together using GPT‑4o’s multimodal reasoning capabilities to interpret visual context, answer user queries (e.g., “What’s that object?”), or execute instructions.
- Output Block: Collects the model’s response, typically text, which is routed back to the robot’s speech engine for audible feedback.
Install the following required libraries on your system.
pip install roboflow inference SpeechRecognition pyttsx3 pyaudioNow deploy this workflow to edge device using following code.
import time
import speech_recognition as sr
import pyttsx3
from inference import InferencePipeline
import cv2
import threading
# Initialize TTS engine
tts_engine = pyttsx3.init()
tts_engine.setProperty('rate', 170)
def speak(text):
print("> ", text)
engine = pyttsx3.init(driverName='sapi5') # Re-initialize TTS engine each time
engine.setProperty('rate', 170)
voices = engine.getProperty('voices')
engine.setProperty('voice', voices[0].id) # Or voices[1].id for female
engine.say(text)
engine.runAndWait()
engine.stop()
def listen(prompt=None):
recognizer = sr.Recognizer()
with sr.Microphone() as source:
if prompt:
speak(prompt)
print("Listening...")
audio = recognizer.listen(source)
try:
text = recognizer.recognize_google(audio)
print("You said:", text)
return text
except sr.UnknownValueError:
speak("Sorry, I didn't catch that.")
return ""
except sr.RequestError:
speak("There was a problem with the speech service.")
return ""
def run_inference_with_prompt(prompt_text: str):
result_container = {"response": None}
pipeline_ref = {"pipeline": None}
has_responded = {"done": False}
finished_event = threading.Event() # Sync marker
def callback(predictions, _video_frame):
if has_responded["done"]:
return
response = predictions.get("open_ai", {}).get("output", "")
if response:
has_responded["done"] = True
result_container["response"] = response
print("Model response:", response)
speak(response)
pipeline_ref["pipeline"].terminate()
finished_event.set() # Signal that we're done
# Create pipeline
pipeline = InferencePipeline.init_with_workflow(
api_key="API_KEY", # Replace with your key
workspace_name="tim-4ijf0",
workflow_id="custom-workflow-7",
video_reference=0,
max_fps=10,
on_prediction=callback,
workflows_parameters={
"prompt": prompt_text
}
)
pipeline_ref["pipeline"] = pipeline
pipeline.start()
# Wait until callback triggers OR timeout
finished_event.wait(timeout=8)
if not has_responded["done"]:
print("No response from model.")
speak("I didn’t get a response. Please try again.")
pipeline.terminate()
pipeline.join()
# Assistant voice loop
if __name__ == "__main__":
speak("Initializing your assistant...")
while True:
user_prompt = listen("What can I help you with?")
if not user_prompt:
continue
# Run inference for this prompt
run_inference_with_prompt(user_prompt)
# Only ask follow-up if model responded
follow_up = listen("Is there anything else I can help you with?")
if not follow_up:
continue
if follow_up.lower() in ["no", "nothing", "stop", "exit", "quit", "goodbye"]:
speak("Okay, have a great day!")
break
# Otherwise: treat follow-up as new prompt
run_inference_with_prompt(follow_up)
This Python script forms the backbone of a voice-interactive AI robot assistant powered by a Roboflow Workflow. Since the Roboflow Workflow expects a text prompt and image or video input, the script first uses the speech_recognition library to capture spoken commands from the user and convert them into text. This text prompt is then sent, along with a live video feed from the robot’s camera, to a Roboflow workflow that runs a vision-language model (like GPT-4o). Once the model processes the visual scene in context of the user’s query and generates a response, the script uses pyttsx3 to convert that response into audio feedback, enabling the robot to speak back to the user. The whole system runs in a loop, allowing continuous voice interaction, and intelligently handles follow-up questions or termination based on user input. This seamless integration of voice input, real-time vision, AI reasoning, and voice output makes the assistant a natural and responsive companion.
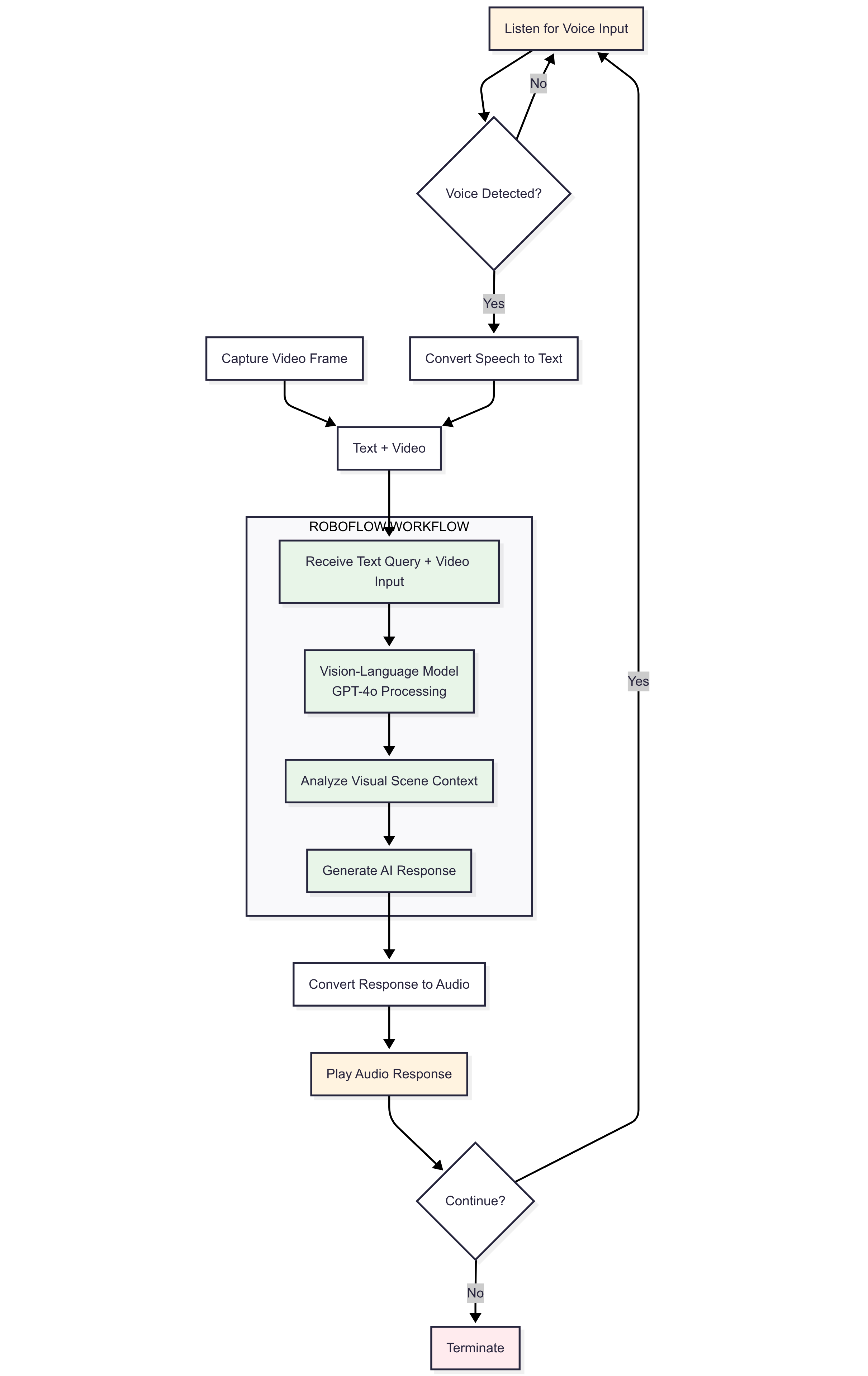
VideoFrame inside a custom sink (via inference.core.interfaces.camera.entities) to display or save annotated frames.Here's the data flow diagram describing the working of the application.
Following is the output when I run the application.
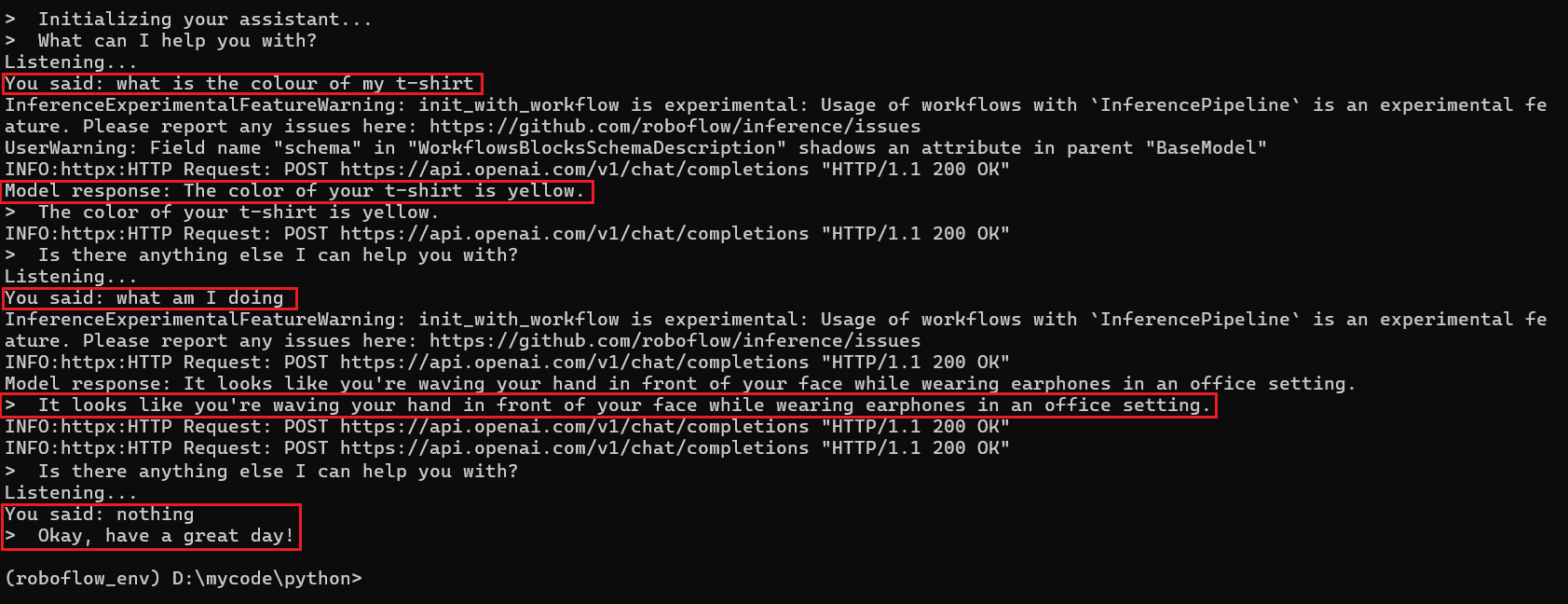
This image shows a successful interaction log between a user and an AI robot assistant. The user speaks:
USER: "What is the colour of my t-shirt"
The AI robot response is:
AI Robot: "The color of your t-shirt is yellow."
This answer indicates that the robot visually identified the t-shirt color in real-time and responded appropriately.
The assistant asks if the user has another question. The user (the user waves his hand) then asks:
USER: "What am I doing"
Again, the AI robot analyzes the live camera feed and responds:
AI Robot: "It looks like you're waving your hand in front of your face while wearing earphones in an office setting."
This shows that the AI robot understands complex visual scenes and provides detailed contextual replies.
This demonstrates a complete vision-language interaction cycle powered by Roboflow's inference pipeline and GPT-4o, showcasing a real-time AI robot assistant that:
- Listens to voice commands
- Understands them via text
- Sees the environment through the camera
- Responds intelligently using visual reasoning
- Speaks the answer back to the user
This is a foundational step toward building natural, multimodal AI robot companions.
AI In Robotics Conclusion
In this blog, we explored how AI is revolutionizing robotics by enabling perception, language understanding, and learning. Key areas covered include computer vision, natural language processing, and machine learning each playing a vital role in making robots intelligent and autonomous. We also looked at real-world robot types, key AI models, and projects that showcase the future of human-robot collaboration.
We have also covered an example by building visual perception system for robot using Roboflow Workflows. Roboflow enables you to train computer vision models for a wide range of tasks such as object detection, image segmentation, classification, keypoint detection, and OCR. You can either train your own models on custom datasets or leverage powerful pretrained models available on the platform. Using Roboflow Workflows, you can easily assemble these components to create the "brain" of your robot, capable of processing visual input and responding intelligently in real time, all deployable directly to the robot’s onboard hardware. Start free.
Cite this Post
Use the following entry to cite this post in your research:
Timothy M.. (Jul 17, 2025). AI in Robotics. Roboflow Blog: https://blog.roboflow.com/ai-in-robotics/