
StyleGAN-T, released in January 2023, is a text-to-image generation model built on the GAN architecture that brings competitive performance back to GANs after diffusion models had largely dominated the space. Unlike diffusion models that require many evaluation steps per image, StyleGAN-T needs only a single forward pass, making it substantially more efficient. The model combines a GAN backbone with a pre-trained CLIP text encoder and finds practical applications in data augmentation, game asset generation, and design workflows.
This article was contributed to the Roboflow blog by Abirami Vina.
StyleGAN is a type of Generative Adversarial Network (GAN), used for generating images. In January 2023, StyleGAN-T, the latest release in the StyleGAN series, was released. This model has brought GAN back into the image generation race, after models based on architectures such as diffusion took the world by storm in 2023 and early 2023.
StyleGAN-T has been designed for text-to-image synthesis. Text-to-image synthesis is a rapidly developing area of AI where natural language processing meets computer vision. Images are created based on textual descriptions, like a fog rolling into New York.

In this article, we will talk about what StyleGAN-T is, how the model came to be, how it works, where it can be applied, and how you can get started with it. Let’s get started.
What is StyleGAN-T?
StyleGAN-T is a text-to-image generation model based on the Generative Adversarial Network (GAN) architecture. With the introduction of diffusion models to the image generation space, GAN models were becoming irrelevant until StyleGAN-T came out in January 2023.
Typical text-to-image generation models require many evaluation steps to generate one image. However, the GAN architecture requires only one forward pass and is thus much more efficient. Older GAN models, while efficient, did not perform as well as more modern text-to-image generation models.
StyleGAN-T brought to the table the advantage of efficiency and strong performance that competes with more modern diffusion-based models.
A Brief History of StyleGAN
In the past five years, multiple versions of StyleGAN have been released. With each release, the architecture has become progressively better. Below, we outline the history of how StyleGAN has evolved over the years.
StyleGAN (Dec 2018)
When released in December 2018, StyleGAN was a groundbreaking GAN model released by a team of NVIDIA researchers. StyleGAN was designed to create realistic images while manipulating and controlling certain features or styles of the image. These styles associated with the generated images could be features like color, texture, pose, etc.
First, StyleGAN takes a random vector as an input. This vector is mapped into a style vector representing different aspects of the image's style and appearance. The generator network then generates an image using the style vector. The discriminator network evaluates whether the generated image is real or fake (generated).
When StyleGAN is trained, the generator and discriminator are trained together in an attempt to outsmart each other. The generator tries to generate images that can trick the discriminator, and the discriminator tries to pick out real and generated images correctly.
An interesting and popular application of StyleGAN was the ability to create realistic human faces. The image below shows various human faces that are not real and were generated by StyleGAN.

StyleGAN 2 (Feb 2020)
StyleGAN was popular. As usage grew, awareness of the limitations of StyleGAN grew. For instance, the tendency for random blob shapes to appear on generated images. This motivated researchers to improve the image quality of generated images. This led to it brought around StyleGAN 2, a new iteration of the StyleGAN idea.
StyleGAN 2 had a more intricate generator architecture called skip connection or skip connections with noise. Skip connections result in better information flow and improved gradient propagation during training. Adding noise to skip connections resulted in generating more high-quality images. Also, StyleGAN 2 was built to be more stable during training.
StyleGAN 3 (June 2021)
StyleGAN 3 aimed to solve a problem called “texture sticking” using an alias-free GAN architecture. Texture sticking is when a generated image has a pattern that repeatedly appears out of place instead of generating a variety of patterns. The issue of texture sticking was combated by an alias-free architecture. Aliasing is the visual distortion or jaggedness that happens when an image or signal is sampled at a lower resolution than its original quality. You can think of aliasing as the pixelation you see when you zoom in too much on an image. A number of changes were made to the StyleGAN model architecture to eliminate the use of aliasing.
StyleGAN XL (August 2022)
The previous versions of StyleGAN had demonstrated impressive achievements in generating facial images. However, these models faced difficulty when it came to generating diverse images from datasets with a wide variety of content. Researchers set out to work on StyleGAN XL to train StyleGAN3 on a vast, high-resolution, unstructured dataset such as ImageNet.
StyleGAN XL introduced a new training strategy to be able to handle this better and enhanced the capabilities of StyleGAN3 to be able to generate high-quality images from large and varied datasets, opening up new possibilities for image synthesis.
How does StyleGAN-T work?
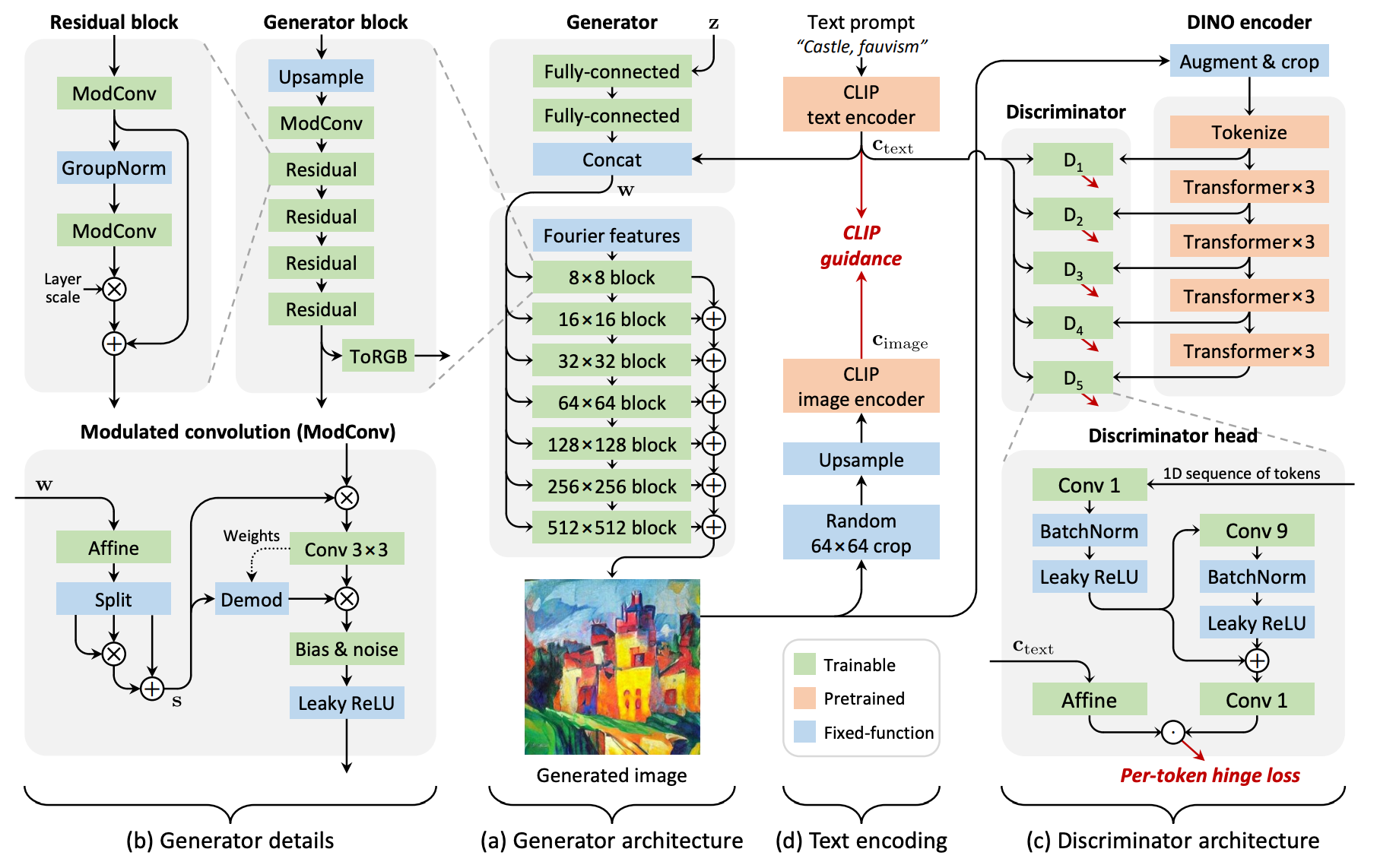
A text prompt is encoded using a pre-trained CLIP text encoder, which captures the semantic meaning of the text in a high-dimensional vector representation. Then a random latent vector (z) is generated as a starting point for image synthesis. The latent vector (z) is passed through a mapping network that converts it into intermediate latent codes, allowing for better control and manipulation of the generated images.
The encoded text prompt is concatenated with the intermediate latent codes, forming a fused representation that incorporates both the latent space and the textual information.
Affine transformations (a type of geometric transformation) are applied to the fused representation, generating per-layer styles that modulate the synthesis layers of the generator. These styles (as shown above) control various visual attributes of the generated image, such as color, texture, and structure. The generator utilizes the modulated synthesis layers to generate a preliminary image that aligns with the given text prompt.
The generated image is then fed into a CLIP image encoder, which encodes the image into a corresponding high-dimensional vector representation. The squared spherical distance between the encoded image and the normalized text embedding is calculated. This distance represents the similarity between the generated image and the input text conditioning.
During training, the objective is to minimize the squared spherical distance, guiding the generated distribution toward producing images that match the textual description. The generated image and real images are evaluated by a discriminator network with multiple heads.
Each discriminator head assesses specific aspects of image quality and authenticity. The discriminator's feedback and the computed distance loss are used to update both the generator and discriminator through gradient-based optimization algorithms, such as backpropagation.
The training process iterates, continually refining the generator and discriminator until the model learns to generate high-quality images that align well with the input text prompts. Once the training is complete, the trained StyleGAN-T model can be used to generate images based on new text prompts. The generator takes the text prompt and a random latent vector as inputs and produces images that match the given textual description.
StyleGAN-T Use Cases
StyleGAN-T can be applied in various industries and scenarios that involve text-to-image synthesis. Below, we walk through use cases in data augmentation, gaming, and fashion tasks.
Data Augmentation
There are situations in computer vision when an image dataset used in training a model is too small or doesn't have enough variety.
Often, new versions of images are generated by making slight changes to the images using image processing. But, this method often results in overfitting of the model (especially when the image dataset is small). The model is essentially seeing the same images again and again. The image dataset could be expanded using StyleGAN-T to generate synthetic images with more variety.
Gaming
Many video games are set in imaginary locations with fictional characters and objects. These fictional places, creatures, and items can be generated using StyleGAN-T. Check out the examples in the image below.

Fashion, Design, and Art
While reading this article and perusing the images, you may have noticed the vast array of creative assets that StyleGAN-T can produce. The creativity and aesthetics in images generated by StyleGAN-T could be used for fashion projects, design projects, art projects, etc. The possibilities are endless.
How To Start Using StyleGAN-T
The training code behind the StyleGAN-T paper is available on GitHub. There are instructions for how to prepare your data in the appropriate format.
There is a training script provided that you can use to train the model on different datasets. The training command parameters can be adjusted according to your dataset, image resolution, batch size, and desired training duration. If you have a pre-trained checkpoint, you can resume training from that point by specifying the checkpoint path.
The StyleGAN-T repository is licensed under an Nvidia Source Code License.
Conclusion
StyleGAN-T is a cutting-edge text-to-image generation model that combines natural language processing with computer vision. StyleGAN-T improves upon previous versions of StyleGAN and competes with diffusion models by offering efficiency and performance.
The StyleGAN-T model uses a GAN architecture and a pre-trained CLIP text encoder to generate high-quality images based on text prompts. StyleGAN-T finds applications in data augmentation, e-commerce, gaming, fashion, design, and art.
Frequently Asked Questions
Are pre-trained checkpoints available on the StyleGAN-T GitHub repository?
The pre-trained weights for StyleGAN-T aren't available on the GitHub repository.
What datasets can be used to train StyleGAN-T?
StyleGAN-T can be trained on unconditional and conditional datasets, and instructions are available on the GitHub repository for how to format them.
Cite this Post
Use the following entry to cite this post in your research:
Contributing Writer. (Jun 27, 2023). What is StyleGAN-T? A Deep Dive. Roboflow Blog: https://blog.roboflow.com/stylegan-t/