
Object detection models usually undergo training to identify a limited set of object classes to create checkpoints from which to train new models. For instance, the widely utilized MS COCO (Microsoft Common Objects in Context) dataset consists of only eighty classes, ranging from individuals to toothbrushes.
Expanding this repertoire of classes can be challenging. One needs to go through the laborious process of gathering diverse images for each object class, annotating them, and refining an existing model through fine-tuning. However, what if there existed a straightforward approach to enable a model to learn new categories right from the start? What if it could effortlessly incorporate thousands of additional categories? This is precisely the capability promised by the DETIC (Detic) model, as outlined in the publication by Meta Research.
In this blog post, we will delve into the workings of this novel model, evaluating its strengths and weaknesses by subjecting it to various potential use cases.
What is Detic?
Detic, introduced by Facebook Research and published in January 2022, is a segmentation model specifically designed for object detection. Detic has the ability to identify 21,000 object classes with strong accuracy, including for objects that were previously challenging to detect.
What sets Detic apart is its unique feature of not requiring retraining, making the model an efficient and time-saving solution.
Traditionally, object detection consists of two interconnected tasks: localization, which involves finding the object within an image, and classification, which involves identifying the object category. Existing methods typically combine these tasks and heavily rely on object bounding boxes for all classes.
However, it's worth noting that detection datasets are considerably smaller in both size and number of object classes compared to image classification datasets. This discrepancy arises due to the larger and more accessible nature of image classification datasets, which results in richer vocabularies.
To address this limitation and expand the vocabulary of detectors from hundreds to tens of thousands of concepts, Detic leverages image classification data during the training process.
By incorporating image-level supervision alongside detection supervision, Detic successfully decouples the localization and classification sub-problems. Consequently, the model becomes capable of detecting and classifying an extensive range of objects with exceptional precision and recall.
Detic is the first known model to train a detector on all 21,000 classes of the renowned ImageNet dataset. Detic is both an incredibly versatile and comprehensive foundation model suitable for a wide array of tasks.
Detic Model Architecture
Object detection involves identifying both the bounding box and the class or category of an object within an input image. On the other hand, object identification, or classification, solely focuses on determining the class name without considering the bounding box. Traditional object detection models face challenges due to the high cost associated with annotating bounding boxes. This limitation restricts the creation of small datasets and hampers training and detection on only a limited number of classes.
In contrast, object detection requires annotations of labels on a per-image basis, which is a faster process and allows for the creation of larger datasets. Consequently, it becomes feasible to train models to identify a larger number of classes. However, since the dataset lacks bounding box information, it cannot be utilized for object detection.
The Detic model overcomes this predicament by training the object detector on a dataset specifically designed for object detection. This innovative approach, known as Weakly-Supervised Object Detection (WSOD), enables the training of an object detector without relying on bounding box information.
Detic leverages Semi-supervised WSOD using the ImageNet-21K dataset, which is conventionally employed for object detection purposes, to train the Detic model detector. Notably, unlike previous studies, Detic does not provide class labels for the resulting bounding boxes generated by the object detector. Instead, it adopts a different approach.
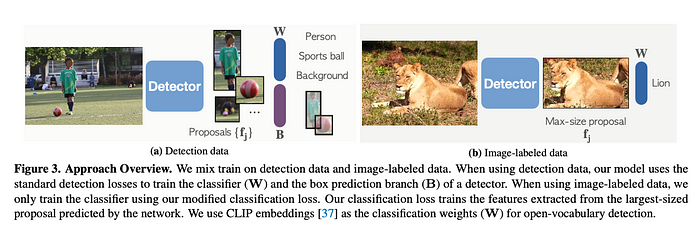
For each detected bounding box, Detic employs a CLIP embedding vector, which is trained on an extensive dataset. CLIP simultaneously trains an image encoder and a text encoder to predict the correct pairings of (image, text) training examples in a batch. During testing, the learned text encoder embeds the names or descriptions of the classes present in the target dataset.
By utilizing embeddings of classes instead of a fixed set of object categories, Detic establishes a classifier capable of recognizing concepts without explicitly encountering any examples of them. This unique approach expands the model's ability to identify objects beyond predefined categories and enhances its adaptability to various scenarios and datasets.
Datasets Used by Detic
The ImageNet21k dataset, which was utilized in the training of Detic, is primarily intended for object identification tasks. This dataset exclusively provides labels for entire images rather than individual objects within those images. Despite this distinction, ImageNet21k boasts an extensive collection of class labels, encompassing a remarkable 21,000 categories. Furthermore, it encompasses a vast pool of data, consisting of approximately 14 million images.
In order to evaluate the performance of Detic, the LVIS dataset was employed during training. Typically employed for object detection purposes, the LVIS dataset comprises over 1,000 class labels and comprises a significant number of images, totalling around 120,000. By utilizing the LVIS dataset for evaluation, Detic's efficacy in detecting and classifying objects across various categories can be comprehensively assessed.
Detic in Action: Showing Detic Inference on Images
In this section, we present a visual showcase of the results achieved by Detic. Through a series of visual examples, we demonstrate the model's capabilities in object detection and classification. These visual results provide a tangible glimpse into the power and accuracy of Detic's performance, showcasing its ability to identify and categorize a diverse range of objects with precision. Join us as we delve into this display of Detic's abilities.

From the images above, it is clear that Detic has a vast vocabulary. In the desk image, Detic identified classes from a computer mouse to a straw to books and envelopes. The confidence thresholds of all items identified is 50% or higher, too. Detic identified objects that are partially occluded, such as a bottle whose cap and top are visible in the bottom of the image, and an occluded wall-mounted vent.
Detic delivers comparable results in video inference, too. Video inference involves running a model across frames in an image to identify objects across the video. This inference information can then be used for a range of purposes (i.e. time-stamping when a certain object becomes visible in a video, counting the number of objects present, and more).

Detic Limitations
Large, foundation visual models like Detic present an abundance of unexplored opportunities, encouraging further investigation and experimentation. However, it is important to acknowledge certain limitations that have been identified.
When employing a custom vocabulary that includes descriptive phrases like "a person sitting on a bench," Detic occasionally struggles to capture the entire contextual meaning and instead focuses on individual words from the sentence. This limitation may be attributed to the fact that Detic extracts image labels from captions using a simplistic text-match approach, primarily trained on singular words.
Furthermore, Detic is a large model. The weights are 670 MB. This means Detic is not suitable for running in most edge or real-time environments. However, in almost all cases one doesn’t need to identify most of the 21,000 classes in Detic. Such a vocabulary is not needed for a real-time task or a model for use on the edge: a fine-tuned, task-specific model that can identify exactly what you are looking for is more efficient.
Conclusion
Typically, detection models are trained on specific data tailored to address specific use cases. The result is the model has a limited vocabulary. This is useful in a range of scenarios: models with limited vocabularies are easier to analyze and evaluate, and are more efficient to run on edge devices.
One of the key advantages of Detic is its flexibility for fine-grained detection. Achieving this level of precision is as simple as incorporating additional image-labeled classes into the model. By doing so, Detic can be fine-tuned to excel in detecting intricate details and specific objects.
Additionally, leveraging the power of CLIP embeddings empowers the model to excel in zero-shot detection tasks, further expanding its repertoire of capabilities.
Cite this Post
Use the following entry to cite this post in your research:
Petru P.. (Jun 16, 2023). What is DETIC? A Deep Dive.. Roboflow Blog: https://blog.roboflow.com/what-is-detic/