
Knowledge distillation compresses a large, computationally expensive neural network (the teacher) into a smaller, faster one (the student) by training the student to mimic the teacher's predictions or internal feature representations rather than just learning from ground-truth labels. The technique covers three knowledge types (response-based, feature-based, relation-based) and three training schemes (offline, online, self-distillation), and has proven effective across computer vision, NLP, and speech recognition for deploying capable models on resource-constrained hardware.
Deep neural networks have become increasingly popular for solving a range of tasks, from identifying objects in images using object detection models to generating text using GPT models. However, deep learning models are often large and computationally expensive, making them difficult to deploy on resource-constrained devices such as mobile phones or embedded systems. Knowledge distillation is a technique that addresses this issue by compressing a large, complex neural network into a smaller, simpler one while maintaining its performance.
In this blog post, we will explore:
- What is knowledge distillation?
- How does knowledge distillation work?
- What are the different types of knowledge distillation?
Let's get started!
What is Knowledge Distillation?
Knowledge distillation is used to compress a complex and large neural network into a smaller and simpler one, while still retaining the accuracy and performance of the resultant model. This process involves training a smaller neural network to mimic the behavior of a larger and more complex "teacher" network by learning from its predictions or internal representations.
The goal of knowledge distillation is to reduce the memory footprint and computational requirements of a model without significantly sacrificing its performance. Knowledge distillation was first introduced by Hinton et al. in 2015. Since then, the idea has gained significant attention in the research community.
The concept of knowledge distillation is based on the observation that a complex neural network not only learns to make accurate predictions but also learns to capture meaningful and useful representations of the data. These representations are learned by the hidden layers of the neural network and can be thought of as "knowledge" acquired by the network during the training process.
In the context of knowledge distillation, the "knowledge" captured by the teacher network is transferred to the student network through a process of supervised learning. During this process, the student network is trained to minimize the difference between its predictions and the predictions of the teacher network on a set of training examples.
The intuition behind this approach is that the teacher network's predictions are based on a rich and complex representation of the input data, which the student network can learn to replicate through the distillation process.
One recent example of knowledge distillation in practice is Stanford’s Alpaca. This model, fine-tuned from LLaMA, learned knowledge from 52,000 instructions that were fed to OpenAI’s text-davinci-003 model. Stanford reported that the Alpaca model “behaves qualitatively similarly to OpenAI’s text-davinci-003, while being surprisingly small and easy/cheap to reproduce (<600$).”
How Does Knowledge Distillation Work?
Knowledge distillation involves two main steps: training the teacher network and training the student network.
During the first step, a large and complex neural network, or the teacher network, is trained on a dataset using a standard training procedure. Once the teacher network has been trained, it is used to generate "soft" labels for the training data, which are probability distributions over the classes instead of binary labels. These soft labels are more informative than hard labels and capture the uncertainty and ambiguity in the predictions of the teacher network.
In the second step, a smaller neural network, or the student network, is trained on the same dataset using the soft labels generated by the teacher network. The student network is trained to minimize the difference between its own predictions and the soft labels generated by the teacher network.
The intuition behind this approach is that the soft labels contain more information about the input data and the teacher network's predictions than the hard labels. Therefore, the student network can learn to capture this additional information and generalize better to new examples.
As shown below, a small “student” model learns to mimic a large “teacher” model and leverage the knowledge of the teacher to obtain similar or higher accuracy.
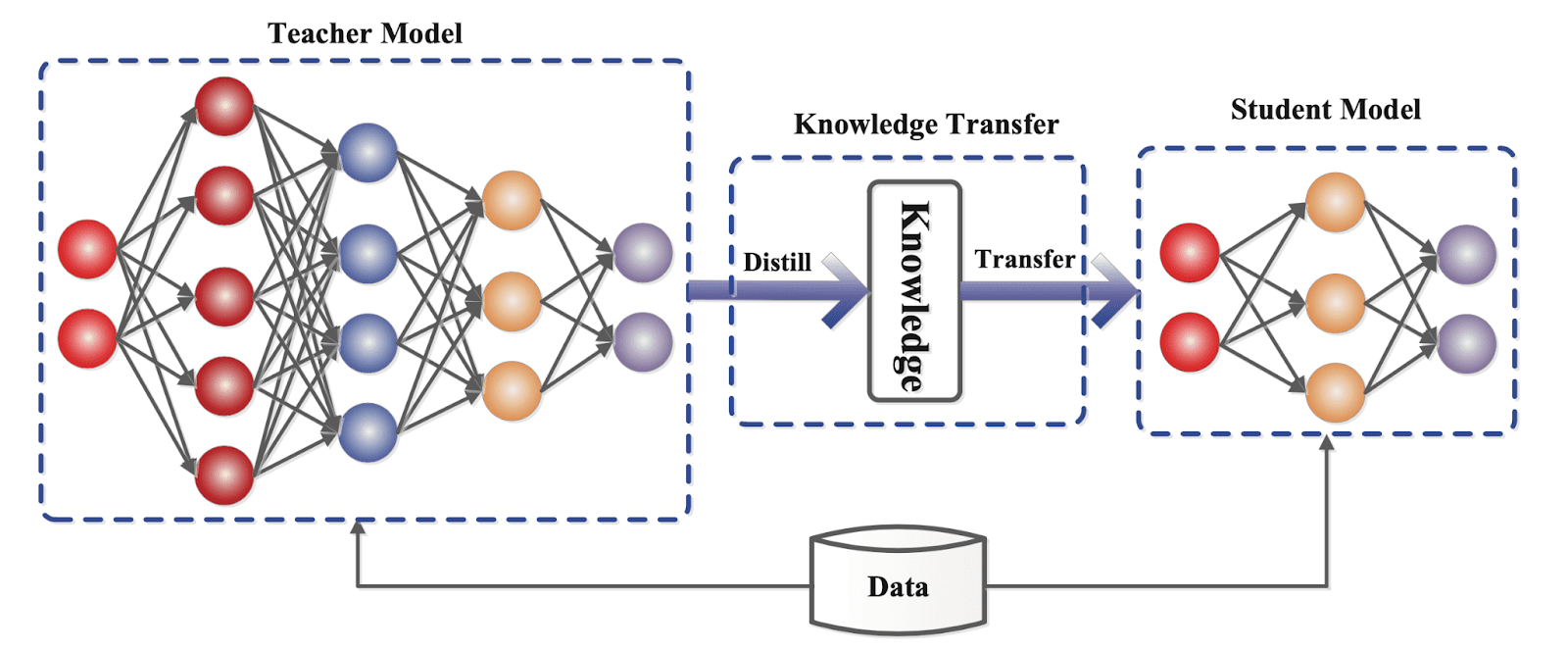
Knowledge Distillation Use Cases
One of the key benefits of knowledge distillation is that it can significantly reduce the memory and computational requirements of a model while maintaining similar performance to the larger model.
This is particularly important for applications that require models to run on resource-constrained devices such as mobile phones, embedded systems, or Internet of Things (IoT) devices. By compressing a large and complex model into a smaller and simpler one, knowledge distillation enables models to be deployed on these devices without compromising their performance.
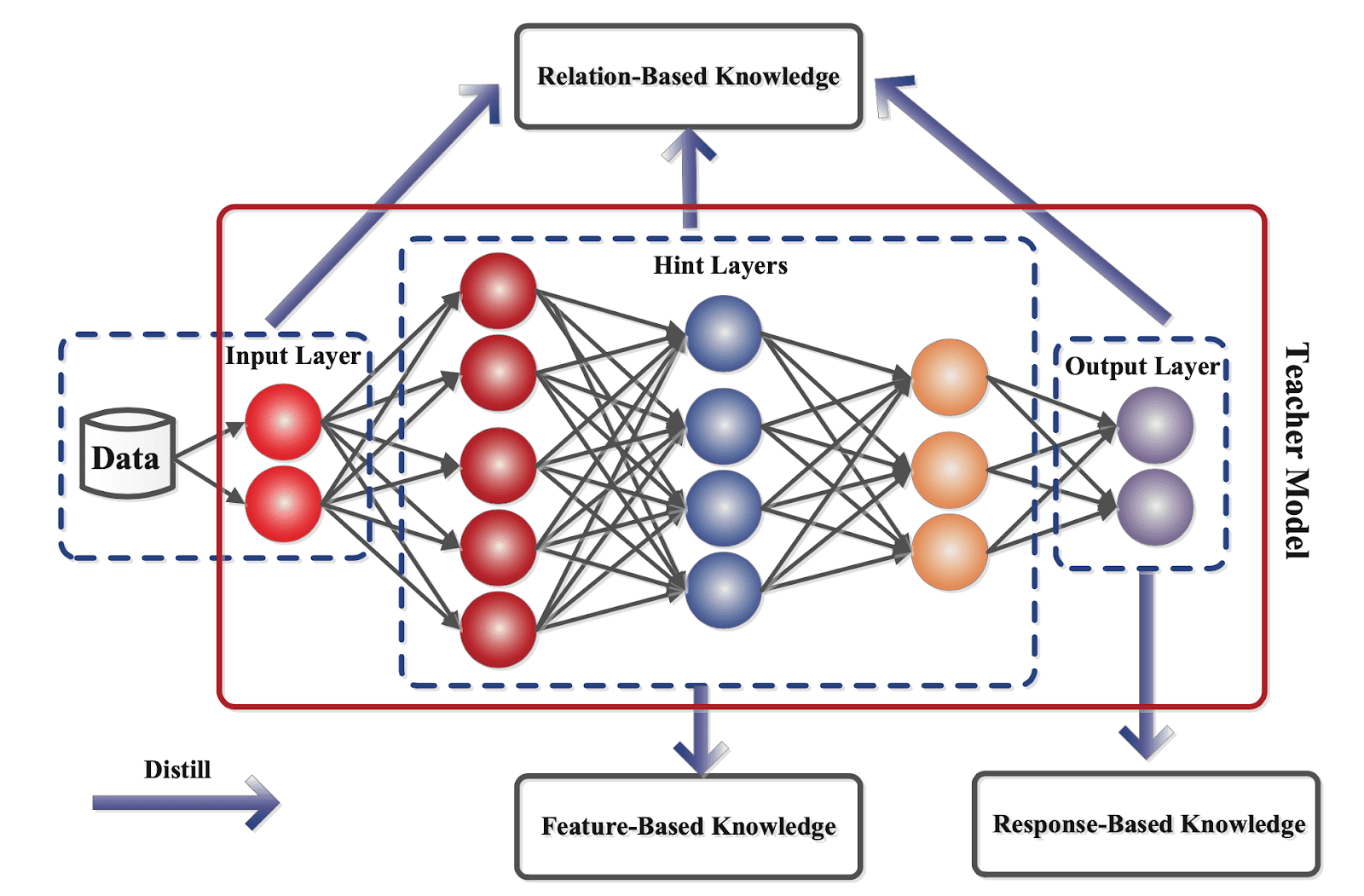
Distillation Knowledge Types
Knowledge distillation can be categorized into different types depending on how the information is gathered from the teacher model.
Generally, there are three types of knowledge distillation, each with a unique approach to transferring knowledge from the teacher model to the student model. These include:
- Response-based distillation;
- Feature-based distillation, and;
- Relation-based distillation.
In this section, we will discuss each type of knowledge distillation in detail and explain how they work.
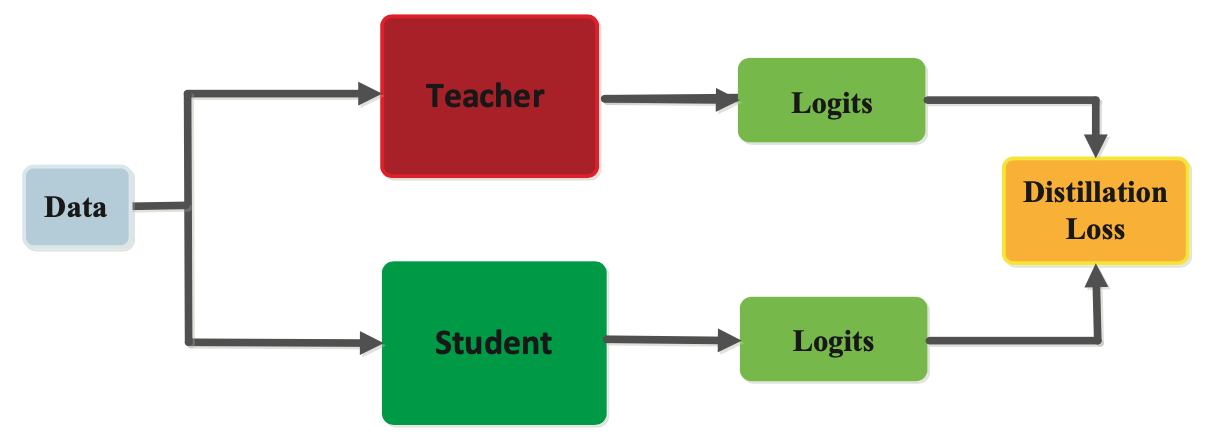
Response-based
In response-based knowledge distillation, the student model learns to mimic the predictions of the teacher model by minimizing the difference between predicted outputs. During the distillation process, the teacher model generates soft labels, which are probability distributions over the classes, for each input example. The student model is then trained to predict the same soft labels as the teacher model by minimizing a loss function that measures the difference between their predicted outputs.
Response-based distillation is widely used in various machine learning domains, including image classification, natural language processing, and speech recognition.
Response-based knowledge distillation is particularly useful when the teacher model has a large number of output classes, where it would be computationally expensive to train a student model from scratch. By using response-based knowledge distillation, the student model can learn to mimic the behavior of the teacher model without having to learn the complex decision boundaries that distinguish between all the output classes.
One of the main advantages of response-based knowledge distillation is its ease of implementation. Since this approach only requires the teacher model's predictions and the corresponding soft labels, it can be applied to a wide range of models and datasets.
Additionally, response-based distillation can significantly reduce the computational requirements of operating a model by compressing it into a smaller and simpler one.
However, response-based knowledge distillation has its limitations. For example, this technique only transfers knowledge related to the teacher model's predicted outputs and does not capture the internal representations learned by the teacher model. Therefore, it may not be suitable for tasks that require more complex decision-making or feature extraction.
Feature-based
In feature-based knowledge distillation, the student model is trained to mimic the internal representations or features learned by the teacher model. The teacher model's internal representations are extracted from one or more intermediate layers of the model, which are then used as targets for the student model.
During the distillation process, the teacher model is first trained on the training data to learn the task-specific features that are relevant to the task at hand. The student model is then trained to learn the same features by minimizing the distance between the features learned by the teacher model and those learned by the student model. This is typically done using a loss function that measures the distance between the representations learned by the teacher and student models, such as the mean squared error or the Kullback-Leibler divergence.
One of the main advantages of feature-based knowledge distillation is that it can help the student model learn more informative and robust representations than it would be able to learn from scratch. This is because the teacher model has already learned the most relevant and informative features from the data, which can be transferred to the student model through the distillation process. Furthermore, feature-based knowledge distillation can be applied to a wide range of tasks and models, making it a versatile technique.
However, feature-based knowledge distillation has its limitations. This technique can be more computationally expensive than other types of knowledge distillation, as it requires extracting the internal representations from the teacher model at each iteration. Additionally, a feature-based approach may not be suitable for tasks where the teacher model's internal representations are not transferable or relevant to the student model.
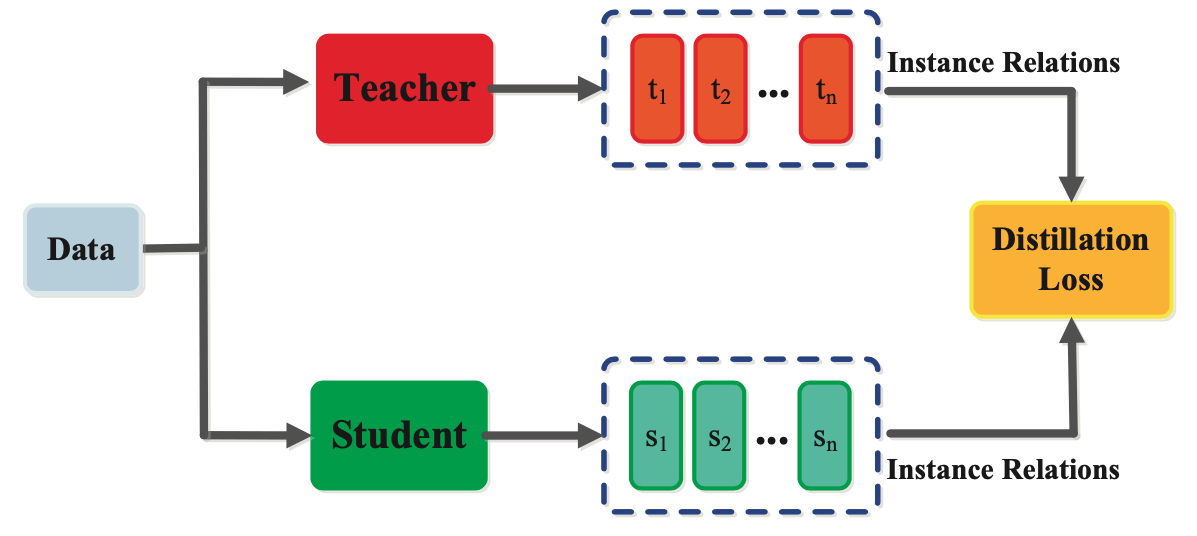
Relation-based
In relation-based distillation, a student model is trained to learn a relationship between the input examples and the output labels. In contrast to feature-based distillation, which focuses on transferring the intermediate representations learned by the teacher model to the student model, relation-based distillation focuses on transferring the underlying relationships between the inputs and outputs.
First, the teacher model generates a set of relationship matrices or tensors that capture the dependencies between the input examples and the output labels. The student model is then trained to learn the same relationship matrices or tensors by minimizing a loss function that measures the difference between the relationship matrices or tensors predicted by the student model and those generated by the teacher model.
One of the main advantages of relation-based knowledge distillation is that it can help the student model learn a more robust and generalizable relationship between the input examples and output labels than it would be able to learn from scratch. This is because the teacher model has already learned the most relevant relationships between the inputs and outputs from the data, which can be transferred to the student model through the distillation process.
However, generating the relationship matrices or tensors, especially for large datasets, can be computationally expensive. Additionally, a relation-based technique may not be suitable for tasks where the relationships between the input examples and the output labels are not well-defined or difficult to encode into a set of matrices or tensors.
Distillation Knowledge Training Methods
There are three primary techniques available for training student and teacher models:
- Offline;
- Online, and;
- Self Distillation.
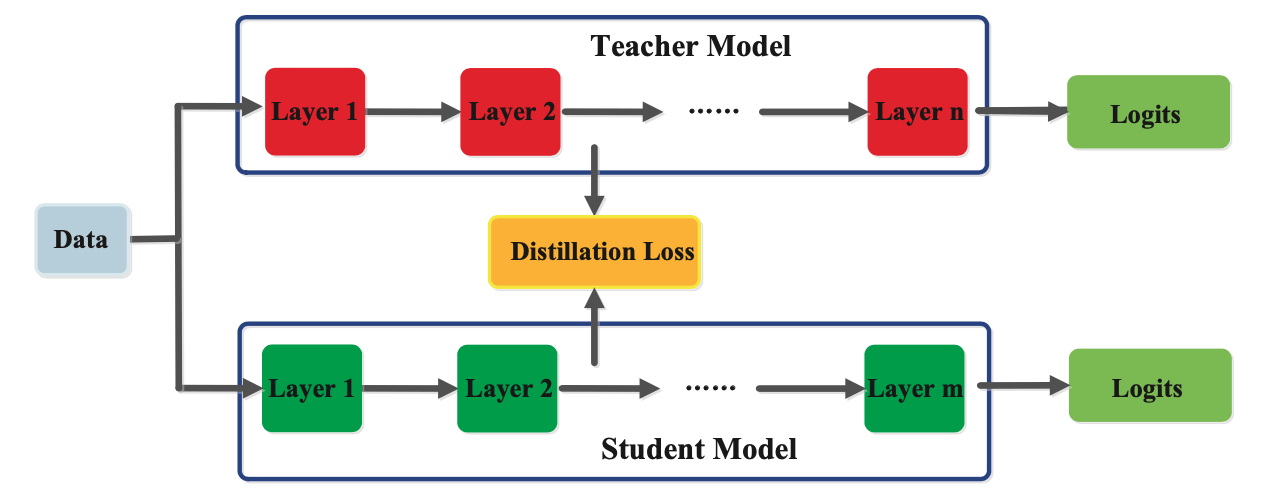
The appropriate categorization of a distillation training method depends on whether the teacher model is modified concurrently with the student model, as shown in the figure below:
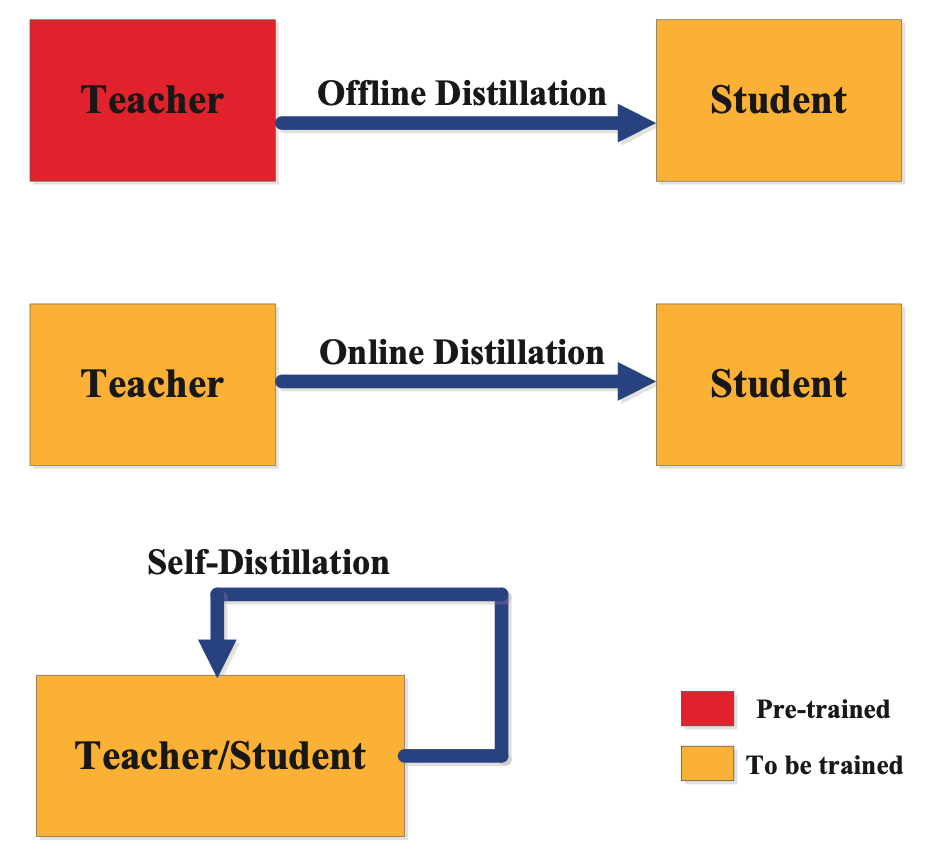
Offline Distillation
Offline Distillation is a popular knowledge distillation method in which the teacher network is pre-trained and then frozen. During the training of the student network, the teacher model remains fixed and is not updated. This approach is commonly used in many previous knowledge distillation methods, including the base paper by Hinton et al.
The main focus of research in this field has been on improving the knowledge transfer mechanism in offline distillation, with less attention given to the design of the teacher network architecture. This approach has allowed for the transfer of knowledge from pre-trained and well-performing teacher models to student models, improving overall model performance.
Online Distillation
Online knowledge distillation, also known as dynamic or continual distillation, is used to transfer knowledge from a larger model to a smaller one in a sequential or online manner.
In this method, the teacher model is updated continuously with new data, and the student model is updated to reflect this new information. The process of online knowledge distillation involves the teacher model and the student model being trained simultaneously. The teacher model is updated continuously as new data becomes available, and the student model learns from the teacher's output. The goal is to have the student model learn from the teacher model's updates in real-time, which enables the student model to continuously improve its performance.
Online knowledge distillation typically involves a feedback loop where the teacher model's output is used to update the student model, and the student model's output is used to provide feedback to the teacher model. The feedback is usually in the form of an error signal, which indicates how well the student model is performing compared to the teacher model. The teacher model then uses this feedback to adjust its parameters and output new predictions.
One of the main advantages of online knowledge distillation is its ability to handle non-stationary or streaming data. This is particularly useful in applications such as natural language processing, where the distribution of the input data may change over time. By updating the teacher model and the student model in real-time, online knowledge distillation enables the models to adapt to changing data distributions.
Self Distillation
The conventional approach to knowledge distillation such as Offline and Online Distillation faces two main challenges. First, the accuracy of the student model is heavily influenced by the choice of teacher model. The highest accuracy teacher is not necessarily the best option for distillation. Secondly, student models often cannot achieve the same level of accuracy as their teachers, leading to accuracy degradation during inference.
To address these issues, the Self Distillation method employs the same network as both the teacher and student. This approach involves attaching attention-based shallow classifiers on the intermediate layers of the neural network at different depths. During training, the deeper classifiers act as teacher models and guide the training of the student models using a divergence metric-based loss on the outputs and L2 loss on the feature maps. During inference, the additional shallow classifiers are dropped.
Distillation Knowledge Algorithms
In this section, we will explore some of the popular algorithms used for knowledge distillation, a technique for transferring knowledge from a large model to a smaller model. Specifically, we will discuss three algorithms:
- Adversarial distillation;
- Multi-teacher distillation, and;
- Cross-modal distillation.
These algorithms enable student models to acquire knowledge from teacher models efficiently, leading to improved model performance and reduced model complexity. Let's dive into each one.
Adversarial Distillation
Adversarial distillation uses adversarial training to improve the performance of student models. In this technique, a student model is trained to mimic the teacher model's output by generating synthetic data that is difficult for the teacher model to classify correctly.
The adversarial distillation algorithm consists of two stages of training. In the first stage, the teacher model is trained on the training set to obtain the ground truth labels. In the second stage, the student model is trained on both the training set and the synthetic data generated by an adversarial network.
The adversarial network is trained to generate samples that the teacher model finds difficult to classify correctly, and the student model is trained to classify these samples correctly. During training, the adversarial network generates synthetic data by adding small perturbations to the original data samples, making them challenging to classify. The student model is then trained to classify both the original and the synthetic data. By doing so, the student model learns to generalize more effectively and thus perform better on real-world data.
The adversarial distillation algorithm has several advantages over traditional knowledge distillation techniques. It is more robust to adversarial attacks, as the student model learns to classify synthetic data that is more difficult to classify. Adversarial distillation also improves the generalization capability of the student model by forcing it to learn from challenging examples that are not present in the training set.
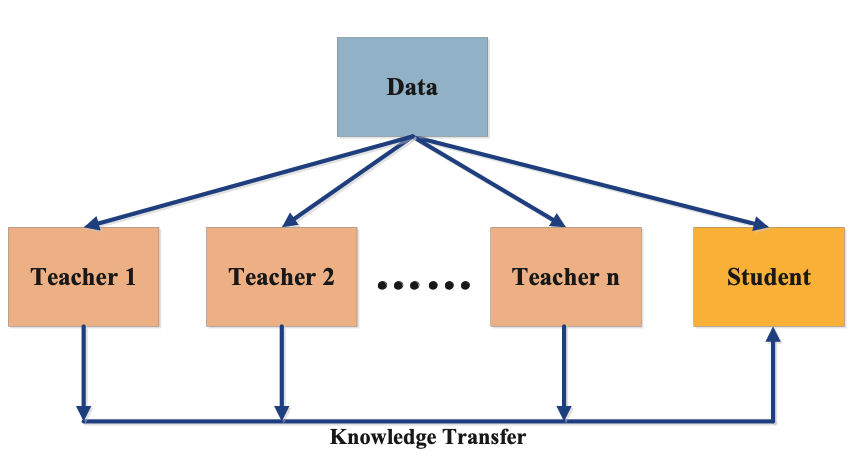
Multi-Teacher Distillation
Multi-teacher distillation involves using multiple teacher models to train a single student model. The idea behind multi-teacher distillation is that by using multiple sources of knowledge, the student model can learn a more comprehensive set of features, leading to improved performance.
The multi-teacher distillation algorithm consists of two stages of training. First, the teacher models are trained independently on the training set to obtain their outputs. Second, the student model is trained on the same training set, using the outputs of all teacher models as targets. During training, the student model learns from the outputs of multiple teacher models, each providing a different perspective on the training set. This allows the student model to learn a more comprehensive set of features, leading to improved performance.
Multi-teacher distillation has several advantages over traditional knowledge distillation techniques. This technique reduces the bias that can be introduced by a single teacher model, as multiple teachers provide a more diverse set of perspectives. Multi-teacher distillation also improves the robustness of the student model as it learns from multiple sources of knowledge.
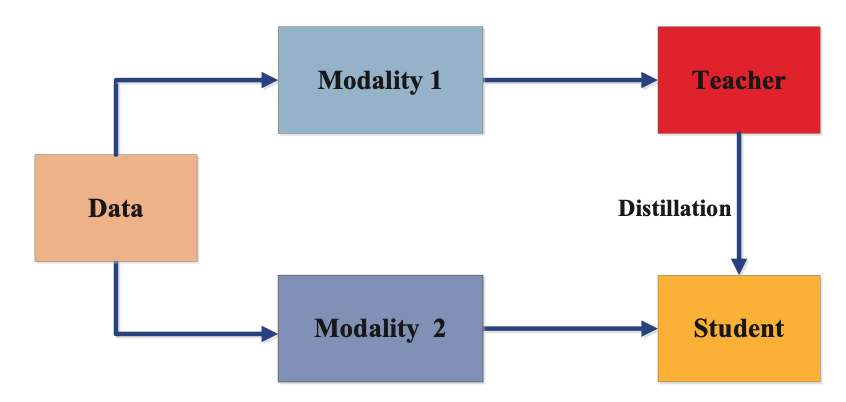
Cross-Modal Distillation
Cross-modal distillation is a knowledge distillation algorithm that transfers knowledge from one modality to another. This technique is useful when data is available in one modality but not in another. For example, in image recognition, there may be no text labels available for the images, but there may be available text data describing the images. In such cases, cross-modal distillation can be used to transfer knowledge from the text modality to the image modality.
The cross-modal distillation algorithm consists of two stages of training. In the first stage, a teacher model is trained on the source modality (e.g., text data) to obtain its outputs. In the second stage, a student model is trained on the target modality (e.g., image data), using the outputs of the teacher model as targets.
During training, the student model learns to map the target modality to the output of the teacher model. This allows the student model to learn from the knowledge of the teacher model in the source modality, improving its performance in the target modality.
Cross-modal distillation allows the transfer of knowledge from one modality to another, making it useful when data is available in one modality but not in another. Furthermore, cross-modal distillation improves the generalization capability of the student model, as it learns from a more comprehensive set of features.
Conclusion
Knowledge distillation is a powerful technique for improving the performance of small models by transferring knowledge from large and complex models. It has been shown to be effective in various applications, including computer vision, natural language processing, and speech recognition.
There are three main types of distillation knowledge technique: offline, online, and self-distillation. These labels are assigned depending on whether the teacher model is modified during training or not. Each type has its own advantages and disadvantages, and the choice depends on the specific application and resources available.
There are several algorithms for knowledge distillation, including adversarial distillation, multi-teacher distillation, and cross-modal distillation, each with its unique approach to transferring knowledge from teacher to student.
Overall, knowledge distillation provides a powerful tool for improving the efficiency and performance of machine learning models. This is an area of ongoing research and development, with many practical applications in the field of AI.
Cite this Post
Use the following entry to cite this post in your research:
Petru P.. (May 16, 2023). What is Knowledge Distillation? A Deep Dive.. Roboflow Blog: https://blog.roboflow.com/what-is-knowledge-distillation/