
OneFormer is a universal image segmentation framework that handles semantic, instance, and panoptic segmentation with a single model trained once, using task-conditioned joint training and query representations to switch between segmentation modes at inference time. Benchmarked on Cityscapes, ADE20K, and COCO, it delivers strong results across all three tasks, though its larger model size can constrain deployment in memory-limited environments.
Image segmentation has long been a fundamental task in computer vision, enabling machines to understand and interpret visual content. Over the years, numerous techniques have emerged to tackle different aspects of segmentation, such as semantic, instance, and panoptic segmentation. However, these approaches have often existed as separate entities, each requiring individual training and fine-tuning.
But what if there was a groundbreaking solution that could bring all these segmentation tasks together? Enter OneFormer, a revolutionary universal image segmentation framework that aims to unify and simplify the segmentation process like never before.
This blog post will delve into the inner workings of this innovative model, assessing its strengths and weaknesses. Let’s get started!
What is OneFormer?
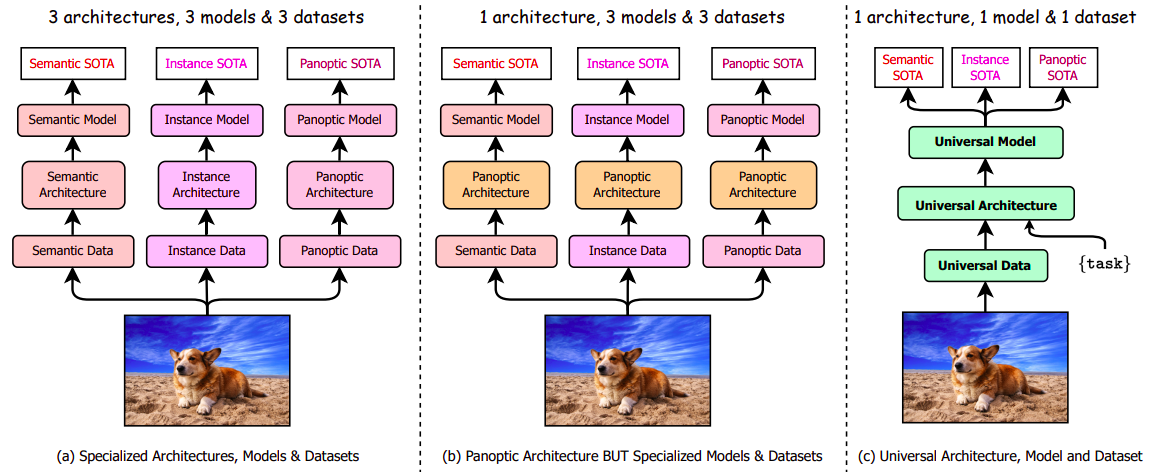
OneFormer breaks the barriers between semantic, instance, and panoptic segmentation by introducing a novel multi-task train-once design. Instead of training and fine-tuning models separately for each task, OneFormer leverages a single unified framework that covers all aspects of image segmentation.
OneFormer is trained just once, significantly reducing the complexity and time required to achieve remarkable results.
With OneFormer, you do not need to invest substantial effort in training multiple models for different segmentation tasks. This universal framework promises to streamline your segmentation pipeline, making it more efficient and accessible for various applications.
OneFormer Architecture
The two key components of OneFormer are the Task Conditioned Joint Training, which enables the framework to simultaneously train on panoptic, semantic, and instance segmentation tasks and the Query Representations which facilitates the communication and interaction between different parts of the model architecture.
Let's go deeper into these two components.
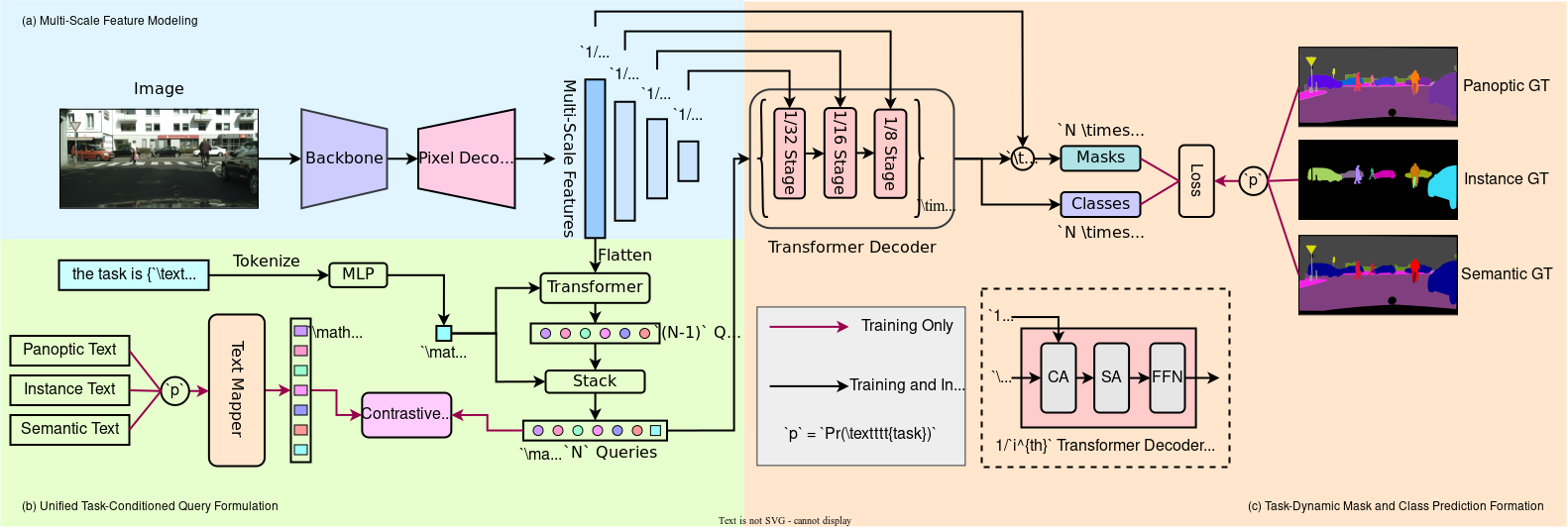
Task Conditioned Joint Training
Task Conditioned Joint Training empowers the framework to train concurrently on panoptic, semantic, and instance segmentation tasks. This methodology guarantees that the model becomes proficient in all tasks, resulting in precise and reliable segmentations across the board.
During the training process, OneFormer uses a task conditioning mechanism to dynamically adapt the model's behaviour based on the specific segmentation task at hand. This conditioning is achieved through the inclusion of a task input that follows the format "the task is {task}".
For each training image, the task input is randomly sampled from the set of available tasks, which includes panoptic, semantic, and instance segmentation. This random sampling allows the model to learn and adapt to different types of segmentation tasks during training.
The task input is tokenized to obtain a 1-D task token, which is then used to condition the object queries and guide the model's predictions for the given task. By incorporating this task token, OneFormer ensures that the model has knowledge about the task it needs to perform and can adjust its behaviour accordingly.
Additionally, the task input influences the creation of a text list that represents the number of binary masks for each class in the ground truth label. This text list is mapped to text query representations, providing task-specific information that helps guide the model's predictions and segmentations.
By conditioning the model on the task input and incorporating task-specific information, OneFormer enables task-aware learning and fosters the development of a unified segmentation framework.
Query Representations
Query representations facilitate communication and interaction among various components within the model architecture. Query representations are utilised in the transformer decoder, where they are responsible for capturing and integrating information from both the input image and the task-specific context.
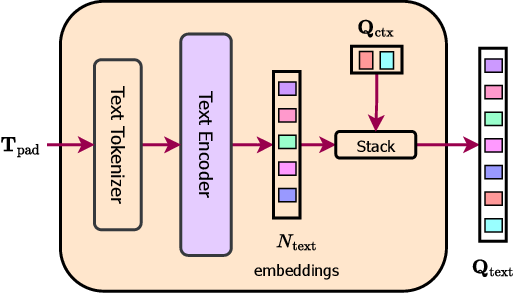
During the training process, OneFormer uses two sets of queries: text queries (Qtext) and object queries (Q).
Qtext represents the text-based representation of segments within the image, while Q represents the image-based representation. To obtain Qtext, the text entries Tpad are tokenized and passed through a text-encoder, which consists of a 6-layer transformer. This encoding process produces Ntext text embeddings that capture information about the number of binary masks and their corresponding classes present in the input image.
Next, a set of learnable text context embeddings (Qctx) is concatenated with the encoded text embeddings, resulting in the final N text queries (Qtext). The text mapper is illustrated in the figure below.
To obtain Q, the object queries (Q') are initialized as a repetition of the task-token (Qtask) N − 1 times. Subsequently, Q' is updated using guidance from flattened 1/4-scale features within a 2-layer transformer. The updated object queries are concatenated with Qtask, resulting in a task-conditioned representation of N queries, denoted as Q.
This initialization and concatenation step, in contrast to using all-zeros or random initialization, is crucial for the model to effectively learn multiple segmentation tasks.
Qtext captures information from the text-based representations of image segments, while Q represents the image-based query representation. These query sets, with their task-conditioned initialization and concatenation, enable effective learning of multiple segmentation tasks within the OneFormer framework.
OneFormer Model Performance
OneFormer was evaluated by researchers on three extensively used datasets that encompass semantic, instance, and panoptic segmentation tasks. The datasets are Cityscapes, ADE20K, and COCO. Below, we describe each dataset used alongside the results obtained by OneFormer compared to other models.
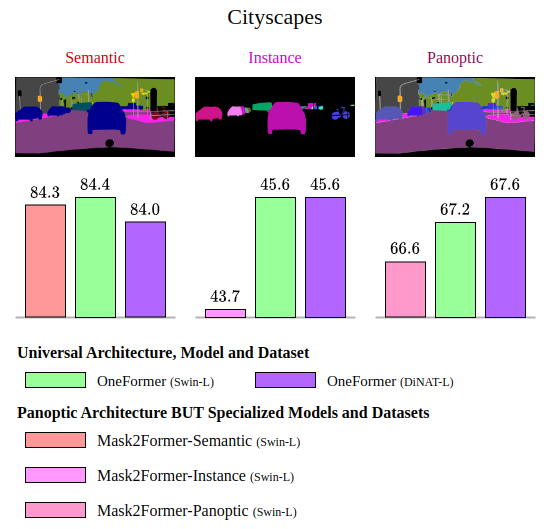
CityScapes Dataset
Cityscapes dataset consists of a total of 19 classes, comprising 11 "stuff" classes and 8 "thing" classes. The dataset comprises 2,975 training images, 500 validation images, and 1,525 test images.
ADE20K Dataset
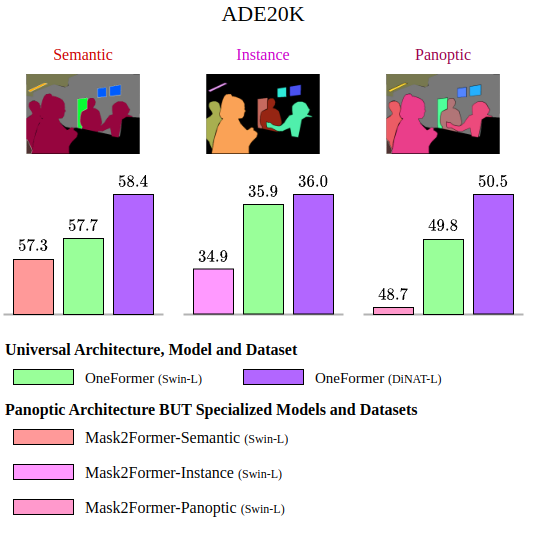
ADE20K serves as another benchmark dataset, offering 150 classes, including 50 "stuff" classes and 100 "thing" classes. It consists of 20,210 training images and 2,000 validation images.
COCO Dataset
COCO dataset comprises 133 classes, encompassing 53 "stuff" classes and 80 "thing" classes. The dataset includes 118,000 training images and 5,000 validation images.
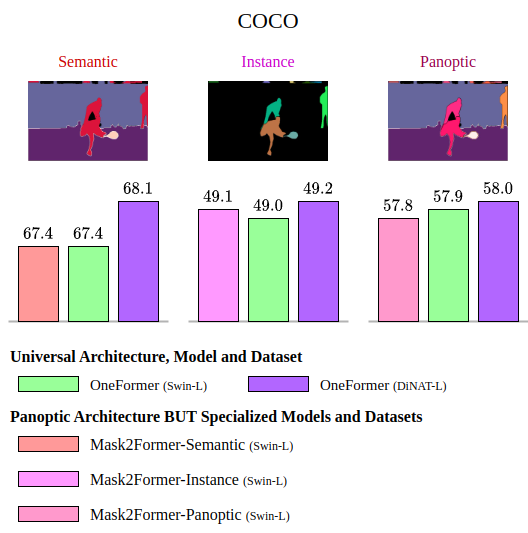
These datasets provide a diverse range of images and labels, enabling a comprehensive evaluation of OneFormer's performance across the three segmentation tasks.
OneFormer Limitations
OneFormer does have some limitations. These limitations include computational requirements, as the framework may demand significant computational resources for training and deployment.
Furthermore, the performance of OneFormer heavily depends on the availability and quality of training data, making it sensitive to the dataset used. Training OneFormer can be time-consuming due to the complexity of the model architecture and the joint training process.
The interpretability of OneFormer may be challenging due to its complex architecture, which may limit its application in domains where explainability is crucial.
While OneFormer performs well on benchmark datasets, its generalisation to new or domain-specific datasets may vary and require fine-tuning or additional training.
Finally, the larger model size of OneFormer, resulting from its multi-task components and transformer decoders, may impact memory usage and deployment feasibility in resource-constrained environments.
Conclusion
OneFormer represents a significant step forward in the field of image segmentation. By leveraging task conditioning and query representations, OneFormer achieves strong performance across these image segmentation tasks in various domains.
The architectural design of OneFormer, with its backbone, pixel decoder, transformer decoders, and multi-scale feature extraction, offers robustness and adaptability. The inclusion of task-specific information through query representations enhances the model's understanding and enables task-aware predictions.
The evaluation of OneFormer on widely used datasets, including Cityscapes, ADE20K, and COCO, showcases its proficiency across different segmentation tasks. OneFormer does have some limitations, however, as discussed above.
Cite this Post
Use the following entry to cite this post in your research:
Petru P.. (Jul 5, 2023). What is OneFormer? A Deep Dive.. Roboflow Blog: https://blog.roboflow.com/what-is-oneformer/