
The year 2014 marked a pivotal moment in the field of computer vision with the publication of the R-CNN paper. This paper not only demonstrated the potential of Convolutional Neural Networks (CNNs) for achieving high performance in object detection but also addressed a challenging problem: the precise localization of objects within images through the creation of bounding boxes.
While CNNs had already gained prominence for image classification tasks, object detection required a more intricate solution. This is where the R-CNN algorithm entered the scene, offering a novel approach to this complex problem.
R-CNN paved the way for subsequent innovations in object detection, including Fast R-CNN, Faster R-CNN, and Mask R-CNN, each building upon and enhancing the capabilities of its predecessor. To grasp the nuances of these advanced R-CNN variants, it is essential to establish a solid foundation in the original R-CNN architecture.
In this blog post, we will delve deep into the workings of R-CNN, providing a comprehensive understanding of its inner workings.
What is R-CNN? How Does R-CNN Work?
Region-based Convolutional Neural Network (R-CNN) is a type of deep learning architecture used for object detection in computer vision tasks. RCNN was one of the pioneering models that helped advance the object detection field by combining the power of convolutional neural networks and region-based approaches.
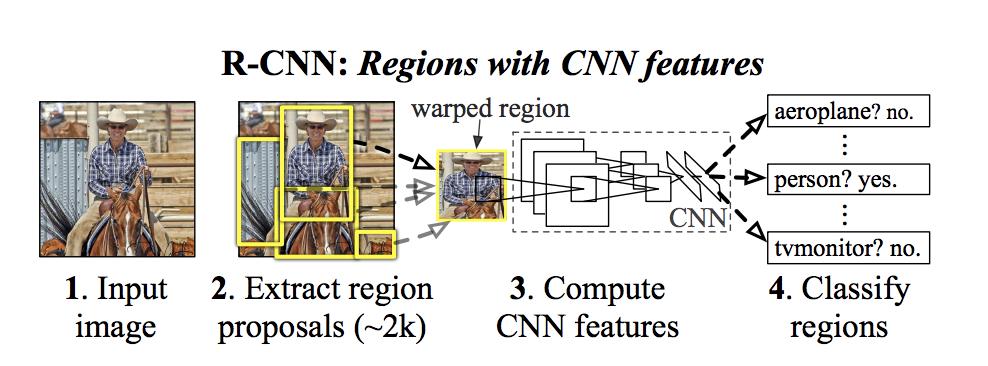
Let's dive deeper into how R-CNN works, step by step.
Region Proposal
R-CNN starts by dividing the input image into multiple regions or subregions. These regions are referred to as "region proposals" or "region candidates." The region proposal step is responsible for generating a set of potential regions in the image that are likely to contain objects. R-CNN does not generate these proposals itself; instead, it relies on external methods like Selective Search or EdgeBoxes to generate region proposals.
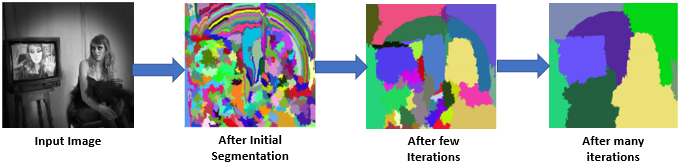
Selective Search, for example, operates by merging or splitting segments of the image based on various image cues like color, texture, and shape to create a diverse set of region proposals.
Below we show how Selective Search works, which shows an input image, then an image with many segmented masks, then fewer masks, then masks that comprise the main components in the image.
Feature Extraction
Once the region proposals are generated, approximately 2,000 regions are extracted and anisotropically warped to a consistent input size that the CNN expects (e.g., 224x224 pixels) and then it is passed through the CNN to extract features.
Before warping, the region size is expanded to a new size that will result in 16 pixels of context in the warped frame. The CNN used is AlexNet and it is typically fine-tuned on a large dataset like ImageNet for generic feature representation.
The output of the CNN is a high-dimensional feature vector representing the content of the region proposal.
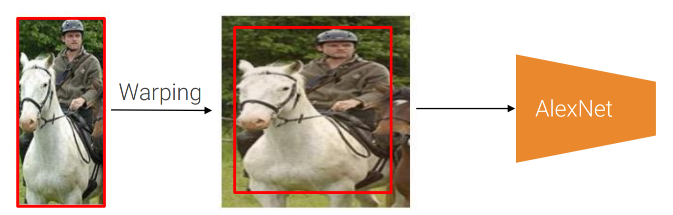
An example of how warping works in R-CNN. Note the addition of 16 pixels of context in the middle image.
Object Classification
The extracted feature vectors from the region proposals are fed into a separate machine learning classifier for each object class of interest. R-CNN typically uses Support Vector Machines (SVMs) for classification. For each class, a unique SVM is trained to determine whether or not the region proposal contains an instance of that class.
During training, positive samples are regions that contain an instance of the class. Negative samples are regions that do not.
Bounding Box Regression
In addition to classifying objects, R-CNN also performs bounding box regression. For each class, a separate regression model is trained to refine the location and size of the bounding box around the detected object. The bounding box regression helps improve the accuracy of object localization by adjusting the initially proposed bounding box to better fit the object's actual boundaries.
Non-Maximum Suppression (NMS)
After classifying and regressing bounding boxes for each region proposal, R-CNN applies non-maximum suppression to eliminate duplicate or highly overlapping bounding boxes. NMS ensures that only the most confident and non-overlapping bounding boxes are retained as final object detections.

R-CNN Strengths and Disadvantages
Now that we've covered what R-CNN is and how it works, let’s delve into the strengths and weaknesses of this popular object detection framework. Understanding the strengths and disadvantages of R-CNN can help you make an informed decision when choosing an approach for your specific computer vision tasks.
Strengths of R-CNN
Below are a few of the key strengths of the R-CNN architecture.
- Accurate Object Detection: R-CNN provides accurate object detection by leveraging region-based convolutional features. It excels in scenarios where precise object localization and recognition are crucial.
- Robustness to Object Variations: R-CNN models can handle objects with different sizes, orientations, and scales, making them suitable for real-world scenarios with diverse objects and complex backgrounds.
- Flexibility: R-CNN is a versatile framework that can be adapted to various object detection tasks, including instance segmentation and object tracking. By modifying the final layers of the network, you can tailor R-CNN to suit your specific needs.
Disadvantages of R-CNN
Below are a few disadvantages of the R-CNN architecture.
- Computational Complexity: R-CNN is computationally intensive. It involves extracting region proposals, applying a CNN to each proposal, and then running the extracted features through a classifier. This multi-stage process can be slow and resource-demanding.
- Slow Inference: Due to its sequential processing of region proposals, R-CNN is relatively slow during inference. Real-time applications may find this latency unacceptable.
- Overlapping Region Proposals: R-CNN may generate multiple region proposals that overlap significantly, leading to redundant computation and potentially affecting detection performance.
- R-CNN is Not End-to-End: Unlike more modern object detection architectures like Faster R-CNN, R-CNN is not an end-to-end model. It involves separate modules for region proposal and classification, which can lead to suboptimal performance compared to models that optimize both tasks jointly.
R-CNN Performance
In the following segment, we will delve into the performance of R-CNN, accompanied by visual demonstrations showcasing its object detection capabilities using the Pascal VoC 2007 dataset.
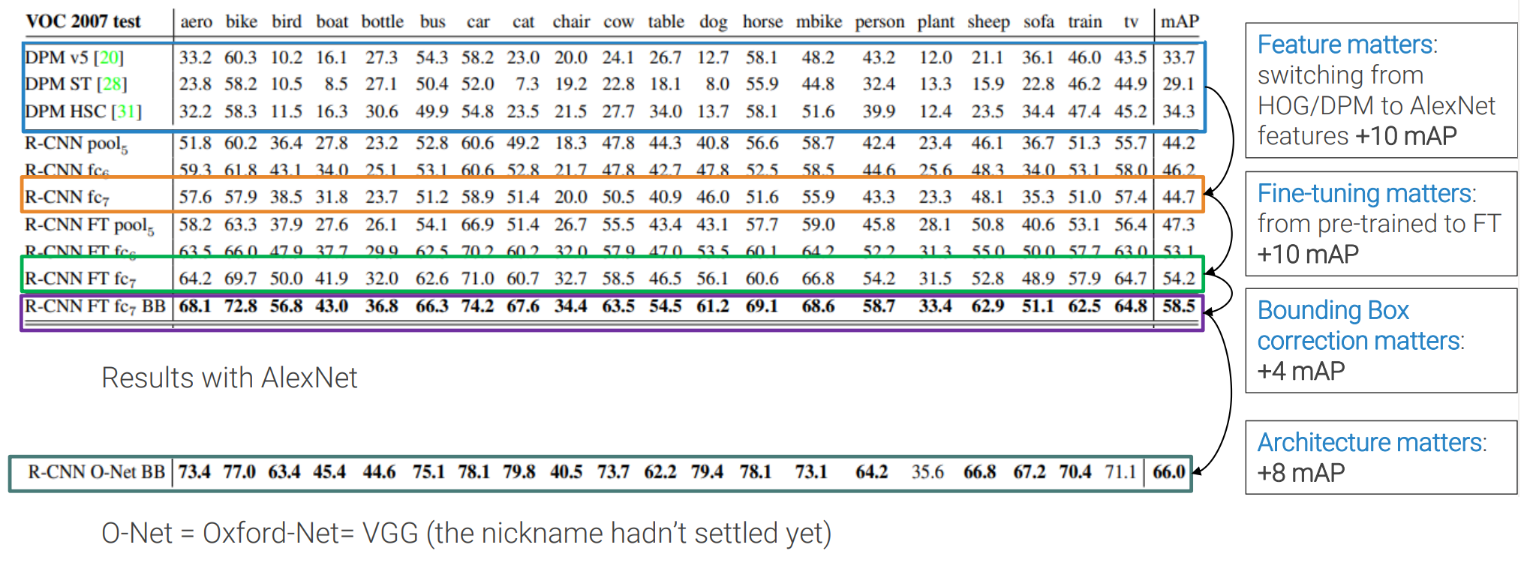
The image above provides insights into several key factors:
- Significance of features: Transitioning from a HOG/DPM algorithm to a Convolutional Neural Network like AlexNext results in a substantial increase in mAP, approximately 10 points higher.
- Impact of Fine-Tuning: Opting for fine-tuning, rather than starting from solely pre-trained weights, also yields a notable improvement, raising the mAP by around 10 points.
- Influence of Bounding Box Correction: The introduction of bounding box correction further enhances the mAP by approximately 4 points.
- Role of architecture: Shifting from AlexNet to VGG (referred to as O-Net in the table, reflecting the evolving nomenclature) brings yet another improvement, boosting the mAP by an additional 8 points.
Next, we present visual illustrations of R-CNN's object detection performance on the Pascal VoC 2007 dataset.

Conclusion
In this blog post, we have embarked on a journey through the intricacies of this object detection framework. R-CNN's architecture has demonstrated its prowess in delivering good accuracy in object detection tasks. In particular, R-CNN examined the pivotal factors that influence the mAP score, shedding light on the importance of features, fine-tuning, bounding box correction, and architectural choices.
However, R-CNN is not without its challenges. Its computational complexity and slower inference times can be daunting, particularly in real-time scenarios. As we conclude this journey through R-CNN, it's clear that this framework has left an indelible mark on the field of computer vision. Its contributions to object detection and related tasks have paved the way for subsequent advancements, each building upon its foundations.
Cite this Post
Use the following entry to cite this post in your research:
Petru P.. (Sep 25, 2023). What is R-CNN?. Roboflow Blog: https://blog.roboflow.com/what-is-r-cnn/