
ResNet-50 is a 50-layer convolutional neural network developed by Microsoft Research Asia in 2015 that solved a core problem in deep learning: as networks grew deeper, training accuracy would degrade rather than improve. The fix was residual (skip) connections wrapped in bottleneck blocks, which let gradients flow directly through layers and bypass the vanishing gradient problem. The architecture remains a foundational reference point for image classification and a common backbone in more recent computer vision models.
Have you ever wondered what goes on behind the scenes when your smartphone instantly recognizes your pet in a photo or your social media feed displays images similar to what you've liked before?
A large part of the magic lies in deep learning architectures. One such architecture is called ResNet-50. ResNet-50 is a convolutional neural network (CNN) that excels at image classification. It's like a highly trained image analyst who can dissect a picture, identify objects and scenes within it, and categorize them accordingly.
In this blog post, we'll delve into the inner workings of ResNet-50 and explore how it revolutionized the field of image classification and computer vision.
Train ResNet-50 on your own custom dataset with ease with Roboflow. Try it free.
What Is ResNet-50?
ResNet-50 is a convolutional neural network (CNN) from the ResNet (Residual Networks) family, introduced by Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun at Microsoft Research in the 2015 paper Deep Residual Learning for Image Recognition.
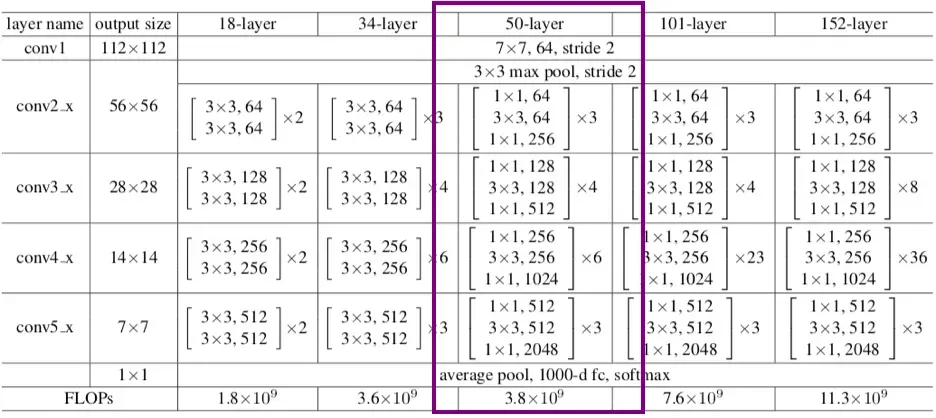
The family spans several depths (ResNet-18, ResNet-34, ResNet-50, ResNet-101, ResNet-152), with ResNet-50 as the middle variant that became the default: deep enough for strong accuracy, small enough (about 25.6 million parameters) to train and serve economically.
An ensemble of ResNets won the 2015 ImageNet classification challenge, and the paper became one of the most cited in deep learning. The reason is not the benchmark score but the idea inside it, which nearly every network trained since has borrowed.
The Problem ResNet Solved
Before ResNet, stacking more layers onto a network eventually made it worse. Accuracy would saturate and then degrade, and not because of overfitting: the deeper network had higher training error too. Very deep networks were simply hard to optimize, in large part because gradients shrink as they propagate back through many layers, the vanishing gradient problem.
The ResNet insight: instead of asking a stack of layers to learn a full mapping, let it learn only the residual, the difference between input and desired output, and add the unaltered input back via a skip connection. If the best thing a block can do is nothing, it can learn zero and pass the input through untouched. Gradients also get a direct path backward through the skips, so networks of 50, 101, even 152 layers train cleanly.
ResNet-50 Architecture and Residual Blocks
The primary problem ResNet solved was the degradation problem in deep neural networks. As networks become deeper, their accuracy saturates and then degrades rapidly. This degradation is not caused by overfitting, but rather the difficulty of optimizing the training process.
ResNet solved this problem using Residual Blocks that allow for the direct flow of information through the skip connections, mitigating the vanishing gradient problem.
The residual block used in ResNet-50 is called the Bottleneck Residual Block. This block it has the following architecture:
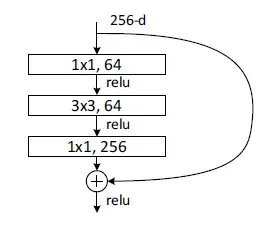
Here's a breakdown of the components within the residual block:
ReLU Activation: The ReLU (Rectified Linear Unit) activation function is applied after each convolutional layer and the batch normalization layers. ReLU allows only positive values to pass through, introducing non-linearity into the network, which is essential for the network to learn complex patterns in the data.
Bottleneck Convolution Layers: the block consists of three convolutional layers with batch normalization and ReLU activation after each.:
- The first convolutional layer likely uses a filter size of 1x1 and reduces the number of channels in the input data. This dimensionality reduction helps to compress the data and improve computational efficiency without sacrificing too much information.
- The second convolutional layer might use a filter size of 3x3 to extract spatial features from the data.
- The third convolutional layer again uses a filter size of 1x1 to restore the original number of channels before the output is added to the shortcut connection.
Skip Connection: As in a standard residual block, the key element is the shortcut connection. It allows the unaltered input to be added directly to the output of the convolutional layers. This bypass connection ensures that essential information from earlier layers is preserved and propagated through the network, even if the convolutional layers struggle to learn additional features in that specific block.
By combining convolutional layers for feature extraction with shortcut connections that preserve information flow, and introducing a bottleneck layer to reduce dimensionality, bottleneck residual blocks enable ResNet-50 to effectively address the vanishing gradient problem, train deeper networks, and achieve high accuracy in image classification tasks.
Stacking the Blocks: Building ResNet-50
ResNet-50 incorporates 50 bottleneck residual blocks, arranged in a stacked manner. The early layers of the network feature conventional convolutional and pooling layers to preprocess the image before it undergoes further processing by the residual blocks. Ultimately, fully connected layers positioned at the pinnacle of the structure utilize the refined data to categorize the image with precision.
Through the strategic integration of bottleneck residual blocks and shortcut connections, ResNet-50 adeptly mitigates the vanishing gradient issue, enabling the creation of more profound and potent models for image classification. This innovative architectural approach has opened the door to notable strides in the field of computer vision.
Trained on ImageNet, ResNet-50 reaches roughly 76% top-1 accuracy, and modern training recipes push the same architecture measurably higher, which is part of why it refuses to retire as a baseline.
ResNet Performance
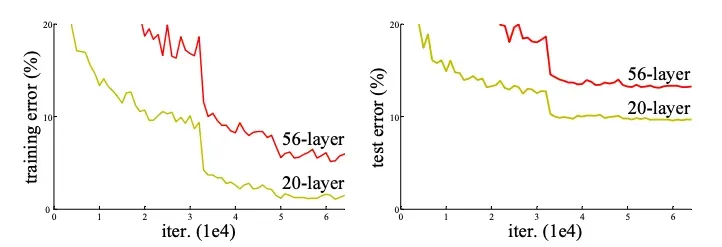
In this section, we are going to show the ResNet-20, -32, -44, -56, and -110 performance compared to plain neural networks.
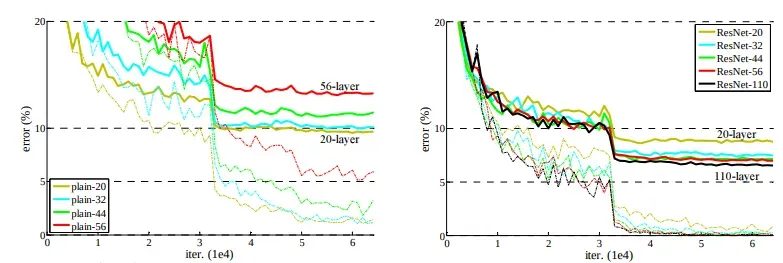
The dashed lines denote training error, and bold lines denote testing error on CIFAR-10. The left chart shows the training and testing errors using plain networks. The error of plain-110 is higher than 60% and is not displayed. The right chart shows the training and testing errors using ResNets.
In essence, the charts demonstrate the advantage of using skip connections in neural networks. By mitigating the vanishing gradient problem, skip connections allow for deeper networks that can achieve higher accuracy in image classification tasks.
Where ResNet-50 Fits Today
ResNet-50 plays three roles today.
- It is the reference baseline: when papers and vendors report classification results or benchmark training speed, ResNet-50 is the common yardstick.
- It is a backbone: detection, segmentation, and embedding models still frequently use ResNet-50 as their feature extractor.
- And it is a dependable production classifier: for many classification tasks (product types, quality grades, scene categories), a fine-tuned ResNet-50 delivers strong accuracy with fast, cheap inference.
Newer families outscore it at similar cost: ConvNeXt modernized the convolutional recipe, and Vision Transformers lead when pretraining data is plentiful. For classification with limited labeled data, transfer learning from a pretrained checkpoint matters more than the architecture choice, and ResNet-50 remains one of the best-supported starting points in every framework.
To train one on your own categories, follow our guide on how to train and deploy a ResNet-50 model, with labeling accelerated by Roboflow Annotate. For object detection rather than classification, transformer detectors are the current standard; that is what Roboflow's RF-DETR is for.
You can also read more about how to use ResNet-50 here.
How many parameters does ResNet-50 have?
About 25.6 million, requiring roughly 3.8 billion FLOPs for a forward pass on a 224x224 image. That footprint is small by current standards, which is why it's still relevant today.
Why is it called ResNet-50?
Res for residual, Net for network, 50 for the number of weighted layers: 48 convolutional layers in 16 bottleneck blocks, plus the opening convolution and the final fully connected layer.
Is ResNet-50 still worth using?
Yes, for classification baselines, resource-constrained deployment, and as a backbone. For maximum accuracy on large datasets, benchmark it against ConvNeXt or a Vision Transformer; for small custom datasets, a pretrained ResNet-50 with transfer learning remains hard to beat for the cost.
What is the difference between ResNet-50 and ResNet-101?
Depth: ResNet-101 uses 23 blocks in its third stage instead of 6, giving 101 layers and higher accuracy at roughly double the compute. The block design and training approach are identical.
Can I use ResNet-50 for object detection?
Not by itself; it classifies whole images. It can serve as the backbone inside a detection architecture, but for a custom detection task today, train RF-DETR, which pairs a modern transformer detector with fast fine-tuning and a commercially permissive license.
Cite this Post
Use the following entry to cite this post in your research:
Petru P.. (Mar 13, 2026). What Is ResNet-50? Architecture Explained. Roboflow Blog: https://blog.roboflow.com/what-is-resnet-50/