
Imagine having a dataset of one million images of cats and dogs and you want to build a model that is able to distinguish the two classes of animals. Unfortunately, only a small part of your dataset is labeled, say 100k images. You do not have the time to manually label the rest.
What should you do in this scenario? What if we could train a model in a supervised fashion using the 100k labeled images and then use this model to predict the label for the remaining 900k unlabeled images? This would eliminate the need to label the rest of our images by hand, an expensive and time-consuming task.
This is where Semi-Supervised Learning comes in. In this article, we're going to discuss:
- What is Semi-Supervised Learning?
- How does Semi-Supervised Learning work?
- When you should use Semi-Supervised Learning?
Let's get started!
What is Semi-Supervised Learning?
Semi-supervised learning (SSL) is a machine learning technique that uses a small portion of labeled data and lots of unlabeled data to train a predictive model.
To better understand the SSL concept, we should look at it through the prism of its two main counterparts: supervised learning and unsupervised learning. Their differences are shown in the below graphic.
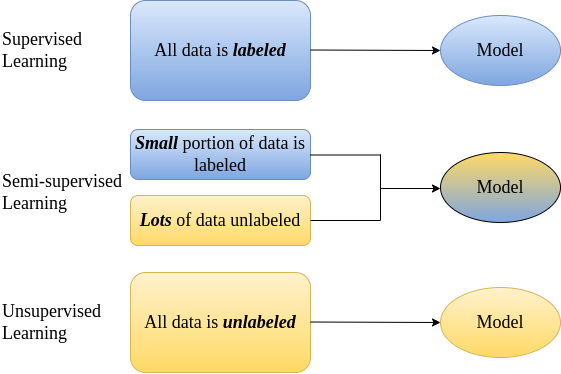
What is Supervised Learning?
Supervised learning is a method of training a machine learning model using a labeled dataset. The process may involve a human expert that adds tags to raw data to show a model the target attributes (answers). For example, a human may annotate all of the defects on a car part featured in an image.
Supervised learning has a few limitations. Supervised learning is slow as it requires human experts to manually label training examples one by one. In addition, supervised learning is costly as a model should be trained on large volumes of hand-labeled data to provide accurate predictions.
What is Unsupervised Learning?
Unsupervised learning is when a model tries to mine hidden patterns, differences, and similarities in unlabeled data by itself, without human supervision. Within this method, data points are grouped into clusters based on similarities. Unsupervised learning models are commonly used for clustering data and finding relationships between values.
While unsupervised learning is a cheaper way to perform training tasks, it isn’t a silver bullet. Unsupervised learning often returns less accurate results. Furthermore, unsupervised learning is useful for a subset of machine learning problems; you cannot apply unsupervised learning to every type of problem.
Semi-Supervised Learning: A Deep Dive
Semi-supervised learning bridges supervised learning and unsupervised learning techniques to solve their key challenges. With semi-supervised learning, you train an initial model on a few labeled samples and then iteratively apply the model to a larger dataset.
Unlike unsupervised learning, which is useful only in a limited set of situations, SSL works for a variety of problems from classification and regression to clustering and association.
A semi-supervised learning approach uses small amounts of labeled data and also large amounts of unlabeled data. This reduces expenses on manual annotation and cuts data preparation time.
Since unlabeled data is abundant, easy to get, and inexpensive, semi-supervised learning finds many applications, while the accuracy of results doesn’t suffer.
How does Semi-Supervised Learning work?
To work with an unlabeled dataset, there must be a relationship between the objects in the dataset. To understand this, semi-supervised learning uses any of the following assumptions:
- Continuity Assumption: As per the continuity assumption, the objects near each other tend to share the same group or label. This assumption is also used in supervised learning, and the datasets are separated by the decision boundaries. In semi-supervised learning, the decision boundaries are added with the smoothness assumption in low-density boundaries.
- Cluster assumptions: In this assumption, data are divided into different discrete clusters. Further, the points in the same cluster share the output label.
- Manifold assumptions: This assumption helps to use distances and densities, and this data lie on a manifold of fewer dimensions than input space.
- The dimensional data are created by a process that has a lesser degree of freedom and may be hard to model directly. This assumption becomes practical if high.
Let's talk through some of the techniques used in semi-supervised learning.
Techniques Used in Semi-Supervised Learning
There are several techniques for doing SSL, which are described below.
Pseudo-labeling
Instead of manually labeling the unlabelled data, we give our model approximate labels on the basis of the labelled data. Let’s explain pseudo-labeling by breaking the concept into steps as shown in the image below.

The image above describes a process where:
- We train a model with labelled data.
- We use the trained model to predict labels for the unlabeled data, which creates pseudo-labeled data.
- We retrain the model with the pseudo-labeled and labeled data together.
This process happens iteratively as the model improves and is able to perform with a greater degree of accuracy.
Self-Training
Self-training is a variation of pseudo labeling. The difference with self-training is that we accept only the predictions that have a high confidence and we iterate through this process several times. In pseudo-labeling, however, there is no boundary of confidence that must be met for a prediction to be used in a model. The standard workflow is as follows.
First, you pick a small amount of labeled data, e.g., images showing cats and dogs with their respective tags, and you use this dataset to train a base model with the help of ordinary supervised methods.
Then you apply the process of pseudo-labeling — when you take the partially trained model and use it to make predictions for the rest of the database which is yet unlabeled. The labels generated thereafter are called pseudo as they are produced based on the originally labeled data that has limitations (say, there may be an uneven representation of classes in the set resulting in bias — more dogs than cats).
From this point, you take the most confident predictions made with your model (for example, you want the confidence of over 80 per cent that a certain image shows a cat, not a dog). If any of the pseudo-labels exceed this confidence level, you add them to the labeled dataset and create a new, combined input to train an improved model.
The process can go through several iterations (10 is a standard amount) with more and more pseudo-labels being added every time. Provided the data is suitable for the process, the performance of the model will keep increasing at each iteration.
Label Propagation
This technique is a graph-based transductive method to infer pseudo-labels for unlabeled data. Unlabeled data points iteratively adopt the label of the majority of their neighbours based on the labelled data points.
Label propagation (LP) makes a few assumptions:
- All classes for the dataset are present in the labeled data;
- Data points that are close have similar labels and;
- Data points in the same cluster will likely have the same label.
Label propagation creates a fully connected graph where the nodes are all the labeled and unlabeled data points. The edges between the two nodes are weighted. The shorter the euclidean distance between two nodes, the larger the weight will be. A larger edge weight allows the label to "travel" easily in the model.
A simple explanation of the working of the label propagation algorithm is shown below:
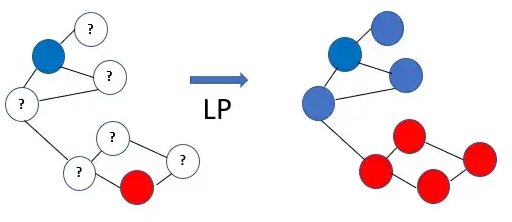
A representation of what Labeling propagation tries to achieve.
The standard workflow is as follows:
- All nodes have soft labels assigned based on the distribution of labels;
- Labels of a node are propagated to all nodes through edges;
- Each node will update its label iteratively based on the maximum number of nodes in its neighbourhood. The label of a node is persisted from the labeled data, making it possible to infer a broad range of traits that are assortative along the edges of a graph.
The label propagation algorithm stops when every node for the unlabeled data point has the majority label of its neighbor or the number of iterations defined is reached.
Key Takeaways On Semi-Supervised Learning
With a minimal amount of labeled data and plenty of unlabeled data, semi-supervised learning shows promising results in classification tasks while leaving the doors open for other machine learning tasks.
The SSL approach can make use of pretty much any supervised algorithm with some modifications needed. SSL fits well for clustering and anomaly detection purposes, assuming the data is suitable based on the requirements of the SSL approach used. While a relatively new field, semi-supervised learning has already proved to be effective in many areas.
But, semi-supervised learning doesn’t apply well to all tasks. If the portion of labeled data isn’t representative of the entire distribution, the approach may fall short. For example, let’s say you need to classify images of colored objects that have different looks from different angles. Unless you have a large amount of representative labeled data, SSL will not help. Many real-life applications still need lots of labeled data, so supervised learning won't go anywhere in the near future.
Cite this Post
Use the following entry to cite this post in your research:
Petru P.. (Dec 16, 2022). What is Semi-Supervised Learning? A Guide for Beginners.. Roboflow Blog: https://blog.roboflow.com/what-is-semi-supervised-learning/