
Andrew Ng's core argument at the Scale Transform conference is that deploying a model to production is the midpoint, not the finish line: real-world performance requires a continuous feedback loop where data collected from deployment improves the next model version. He makes the case for a data-centric approach over a model-centric one, noting that data cleaning accounts for more than 80% of a machine learning engineer's work, and that freezing the codebase and focusing on data quality often delivers faster gains than tuning model architecture.
Andrew Ng, the co-founder of Google Brain and Coursera and former Chief Scientist at Baidu, spoke at this week's Scale Transform conference on the transition from "big data" to "good data." He relayed several insights learned from his efforts to deploy AI for real-world applications.
On Iteration in Machine Learning
One of the biggest mistakes Andrew has seen enterprise teams make when working on AI projects is thinking of a project as a straight line from start to finish. In reality, getting a first version of your model to production is the starting point rather than the finish line.
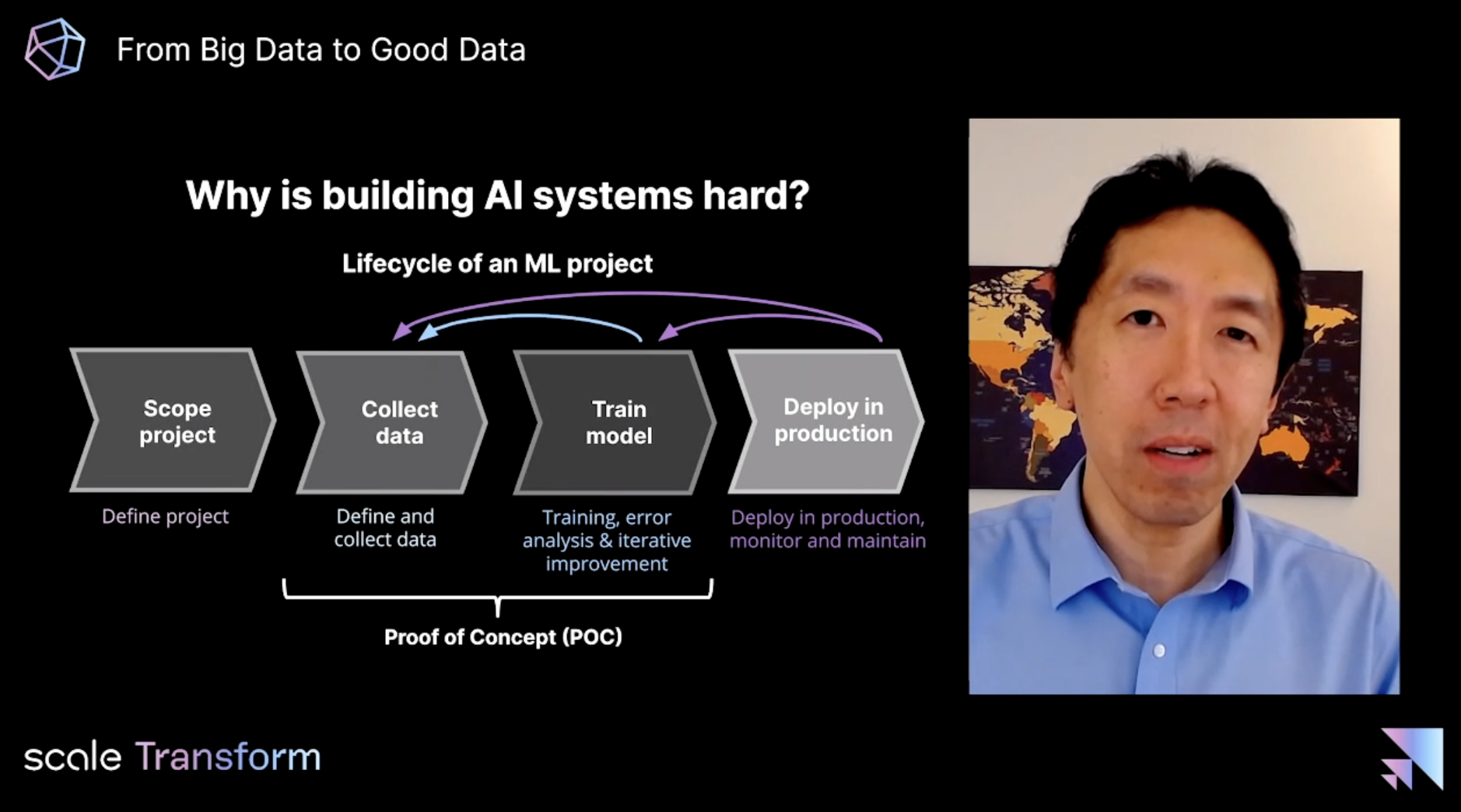
AI needs to be treated as a continuous feedback loop where data your model collects from the real world is used to improve the next version of the model. Most enterprise AI projects currently fail because of a failure to understand and implement this paradigm.
He used the example of chest x-rays and pathology scans; there have been many research papers showing that AI models can outperform even the best doctors and radiologists in the world at identifying disease but almost none of these have made it into real-world use yet. In the real world, models need to handle all sorts of edge cases that you won't be able to predict and simulate in the proof of concept stage.

On the Importance of Good Data
Andrew describes data as the "food for your AI model." Just like with real food, the goal isn't to feed your model the most calories you can possibly cram in; it's to give it a well balanced diet.
Data cleaning makes up over 80% of a machine learning engineer's work. But there is a huge gap in the amount of time research scientists spend on data improvements like better augmentation compared to improvement in model architecture.

When Andrew is brought on as a consultant on an enterprise AI project, he often tells the team to freeze their codebase and focus exclusively on improving the data. In most cases, iterating on the data gets them the performance they need far faster than tweaking the models.

For most projects, Andrew says, the code is a solved problem; you can just download something from Github. But the data is not solved. Most domains do not have access to "big data" like consumer web companies do. And even for ones that do, you can break down "big data" machine learning problems into a collection of "small data" problems (for example, even though there is lots of driving data available, a self driving car model needs to perform well in edge cases like unicycles crossing the road).

All teams working on machine learning projects need to think about collecting and curating accurate, balanced, and comprehensive datasets.
On Building AI Systems
It's equally important to utilize repeatable, systematic processes for working with data. "Hacking around in a Jupyter notebook" is not a repeatable process.
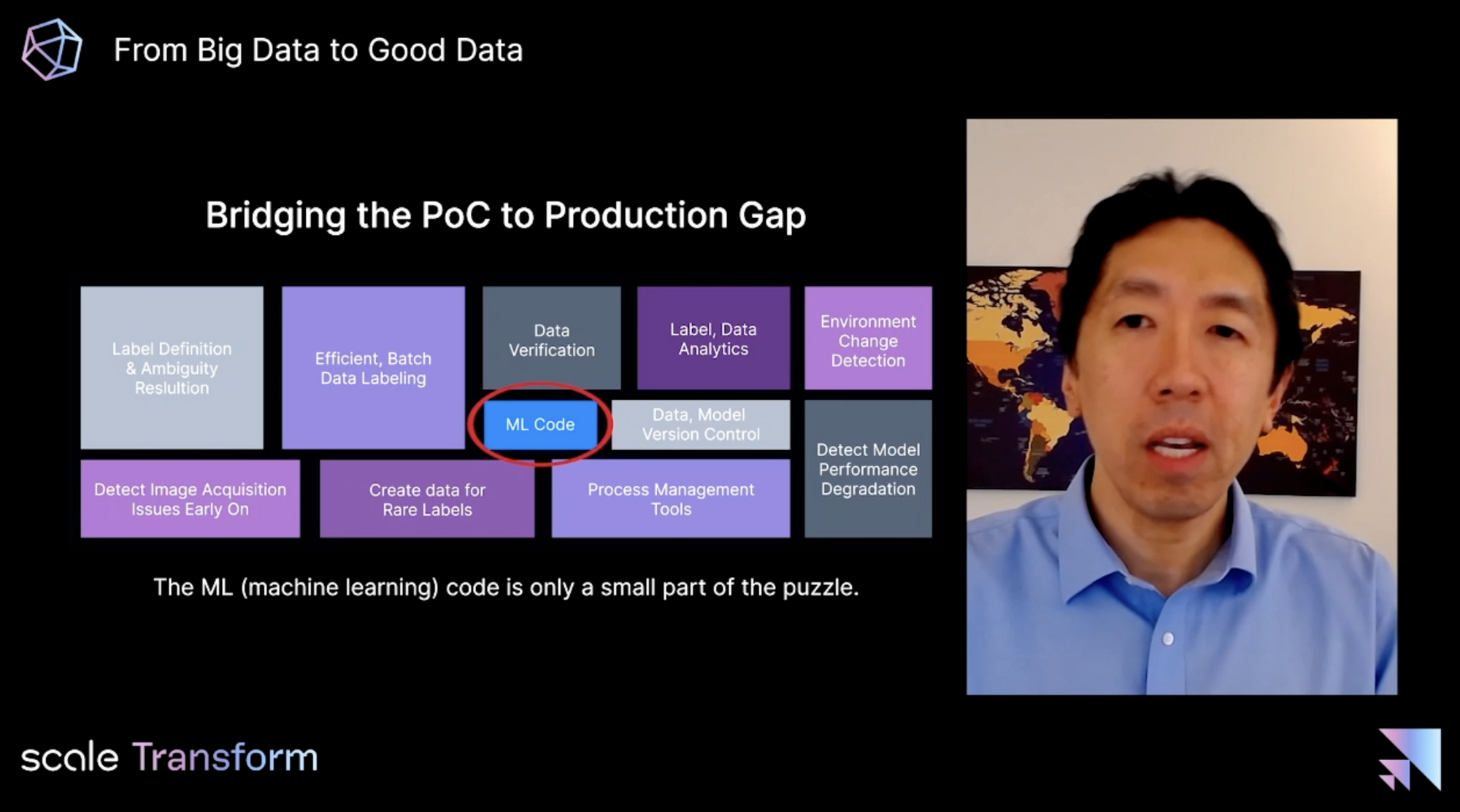
Because the machine learning code is only a small piece of the puzzle, we need to build and use production-grade tooling to ensure success or we end up with unreliable, unpredictable, unmaintainable systems. "The way to solve all these problems is with an AI platform that lets you customize these models for each individual [customer]."
Conclusion
Machine learning is an iterative process; thinking about how to define your problem in a way where you can get value from an imperfect proof of concept and then improve on it over time is essential.
Platforms like Roboflow are build with exactly this in mind. We've helped dozens of organizations rapidly build a proof of concept, instill production ready and repeatable data practices, ensure their projects successfully make it to production, and continue to improve over time with active learning.
We'd love to help you too! If you're working on a computer vision project at your company, please reach out.
Cite this Post
Use the following entry to cite this post in your research:
Brad Dwyer. (Mar 27, 2021). Andrew Ng: "Deploying to production means you're halfway there.". Roboflow Blog: https://blog.roboflow.com/andrew-ng-scale-transform-conference/