
In this post, we do a deep dive into the neural magic of EfficientDet for object detection, focusing on the model's motivation, design, and architecture.
Recently, the Google Brain team published their EfficientDet model for object detection with the goal of crystallizing architecture decisions into a scalable framework that can be easily applied to other use cases in object detection.
The paper concludes that EfficientDet outperforms similar sized models on benchmark datasets. At Roboflow, we found that the base EfficientDet model generalizes to custom datasets hosted on our platform. (For an in depth tutorial on implementing EfficientDet, please see this blog post on how to train EfficientDet and this Colab Notebook on how to train EfficientDet.)
In this blog post, we explore the rationale behind the decisions that were made in forming the final EfficientDet model, how EfficientDet works, and how EfficientDet compares to popular object detection models like YOLOv3, Faster R-CNN, and MobileNet.
Challenges in Deep Learning EfficientDet Addresses
Before exploring the model, here are some key areas that have prevented image detection systems from being deployed to real life use cases.
- Data Collection - With model architecture and pretrained checkpoints, EfficientDet cuts down on the amount of data required to generalize to a new domain.
- Model Design and Hyper Parameterization - Once the data has been collected, machine learning engineers need to carefully set up the model design and tune a number of hyper parameters.
- Training Time - the amount of time required to train the model on the gathered dataset. In the EfficientDet paper, this is measured in FLOPS (floating point operation per second).
- Memory Footprint - Once the model is trained, how much memory is required to store the model weights when called upon for inference?
- Inference Time - When the model is invoked, can it perform predictions quick enough to be used in a production setting?
Image Features and CNNs
The first step to training an object detection model is to translate the pixels of an image into features that can be fed through a neural network. Major progress has been made in the field of computer vision by using convolutional neural networks to create learnable features from an image. Convolutional neural networks mix and pool image features at different levels of granularity, allowing the model a choice of possible combinations to focus on when learning the image detection task at hand.
However, the exact manner in which the convolutional neural network (ConvNet) creates features has been a keen area of interest in the research community for sometime. ConvNet releases have included ResNet, NASNet, YoloV3, Inception, DenseNet, … and each has sought to increase image detection performance by scaling ConvNet model size and tweaking the ConvNet design. These ConvNet models are provided in a scaling fashion, so programmers can deploy a larger model to improve performance if their resources allow.
EfficientNet: Motivation and Design
Recently, the Google Brain team released their own ConvNet model called EfficientNet. EfficientNet forms the backbone of the EfficientDet architecture, so we will cover its design before continuing to the contributions of EfficientDet. EfficientNet set out to study the scaling process of ConvNet architectures. There are many ways - it turns out 💭- that you can add more parameters to a ConvNet.

You can make each layer wider, you can make the number of layers deeper, you can input images at a higher resolution, or you can make a combination of these improvements. As you can imagine, the exploration of all these possibilities can be quite tedious for machine learning researchers.
EfficientNet set out to define an automatic procedure for scaling ConvNet model architectures. The paper seeks to optimize downstream performance given free range over depth, width, and resolution while staying within the constraints of target memory and target FLOPs. They find that their scaling methodology improves the optimization of previous ConvNets as well as their EfficientNet architecture.
EfficientNet Network, Scaling and Evaluation
Creating a new model scaling technique is a big step forward, and the authors take their findings a step further by creating a new ConvNet architecture that pushes their state of the art results even higher. The new model architecture is discovered through neural architecture search.
The neural architecture search optimizes for accuracy, given a certain number of FLOPS and results in the creation of a baseline ConvNet called EfficientNet-B0. Using the scaling search, EfficientNet-B0 is scaled up to EfficientNet-B1. The scaling function from EfficientNet-B0 to EfficientNet-B1 is saved and applied to subsequent scalings through EfficientNet-B7 because additional search becomes prohibitively expensive.
The new family of EfficientNet networks is evaluated on the ImageNet leaderboard, which is an image classification task. Note: there have been some improvements since the original release of EfficientNet, including tweaks to optimize from the resolution discrepancy and deploying EfficientNet as a teacher and student.

The EfficientNet looks like a good backbone to build upon. It efficiently scales with model size and outperforms other ConvNet backbones.
So far, we have covered the following portion of the EfficientDet network:
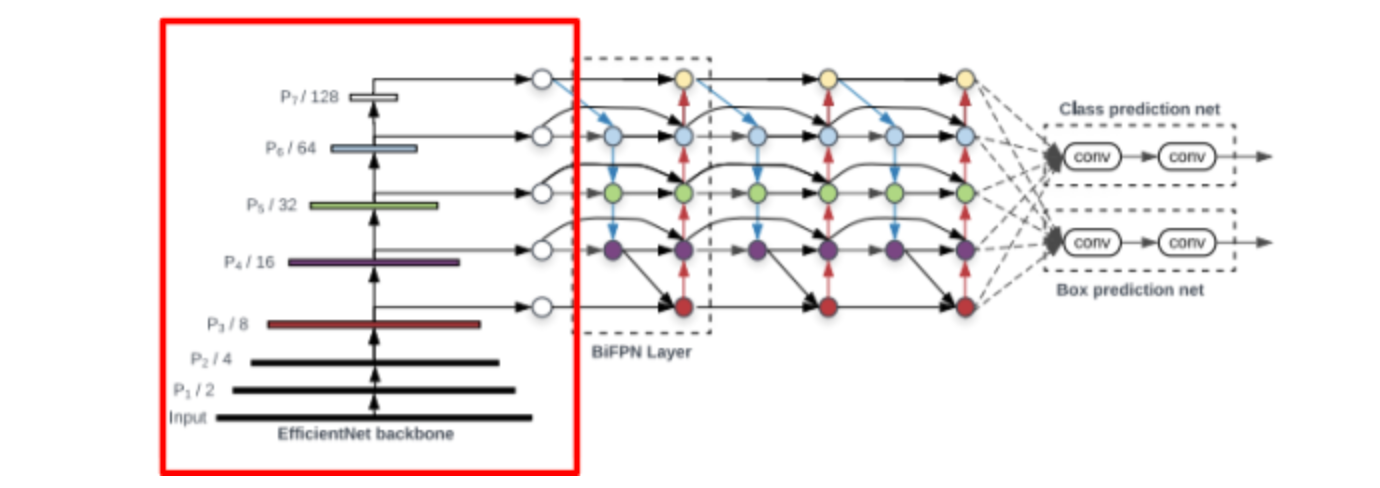
Introducing EfficientDet
Now, we will move onto the contributions of EfficientDet, which seeks to answer the following question: how exactly should we combine the features of ConvNets for object detection? And how should we scale our model’s architecture once we have developed this combination process?
EfficientDet Feature Fusion
Feature fusion seeks to combine representations of a given image at different resolutions. Typically, the fusion uses the last few feature layers from the ConvNet, but the exact neural architecture may vary.

In the above image, FPN is a baseline way to fuse features with a top down flow. PA net allows the feature fusion to flow backwards and forwards from smaller to larger resolution. NAS-FPN is a feature fusion technique that was discovered through neural architecture search, and it certainly does not look like the first design one might think of.
The EfficientDet paper uses “intuition” (and presumably many, many development sets) to edit the structure of NAS-FPN to settle on the BiFPN, a bidirectional feature pyramid network. The EfficientDet model stacks these BiFPN blocks on top of each other. The number of blocks varies in the model scaling procedure. Additionally, the authors hypothesize that certain features and feature channels might vary in the amount that they contribute to the end prediction, so they add a set of weights at the beginning of the channel that are learnable.
EfficientDet Model Scaling
Previous work on model scaling for image detection generally scaled portions of the network independently. For example, ResNet scales only the size of the backbone network. But a joint scaling function had not yet been explored. This approach is very reminiscent of the joint scaling work done to create EfficientNet.
The authors set up a scaling problem to vary the size of the backbone network, the BiFPN network, the class/box network, and the input resolution. The backbone network scales up directly with the pretrained checkpoints of EfficientNet-B0 through EfficientNet-B6. The BiFPN networks width and depth are varied along with the number of BiFPN stacks.
EfficientDet Model Evaluation and Discussion
The EfficientDet Model is evaluated on the COCO (Common Objects in Context) data set, which contains roughly 170 image classes and annotations across 100,000 images. COCO is considered to be the general purpose challenge for object detection. If the model performs well in this general domain, it will likely do very well on more specific tasks. EfficientDet outperforms previous object detection models under a number of constraints. Below, we look at the performance of the model as a function of FLOPS.

Here we can see that the model does quite well relative to other model families under similar constraints. The authors also evaluate the model on semantic segmentation on Pascal VOC. They find that they achieve state of the art there too. Hey, why not?
Simply, Why is EfficientDet Useful?
Taking a step back from the implementation details, it is pretty incredible to think about what the open sourced checkpoints of EfficientDet mean for computer vision engineers. The pretrained checkpoints of EfficientNet crystallize all of the findings and automaticity that the researchers at Google Brain placed into building a ConvNet, along with all of the supervision that image classification on ImageNet can provide.
The EfficientNet checkpoints are further leveraged with feature fusion and all components of the architecture are efficiently scaled. Finally, these model weights are pretrained on COCO, a generalized image detection dataset. As a user, there are few decisions left up to question beyond the type of data to provide the model.
Nice Breakdown - How Do I Use EfficientDet?
At Roboflow, we have provided a tutorial on this blog post on how to train EfficientDet and this Colab Notebook on how to train EfficientDet. Through Roboflow, you can feed in your data set with annotations and simply feed a new data download link into our example and get some results. Then, after training, the notebook exports the trained weights for deployment to an application!
Stay in Touch
If you have results with EfficientDet and want to share, submit your project.
Cite this Post
Use the following entry to cite this post in your research:
Jacob Solawetz. (Apr 22, 2020). EfficientDet for Object Detection. Roboflow Blog: https://blog.roboflow.com/breaking-down-efficientdet/