
You can use Claude, Gemini, and GPT-4o to ask open-ended questions about the contents of an image. For example, you could use Claude, Gemini, or GPT-4o to generate a caption for an image, or to extract structured data from an image.
In this guide, we will walk through how to use Claude or Gemini to extract structured data from a product label.
You can now use Anthropic’s Claude and Google’s Gemini multimodal models in Roboflow Workflows. Roboflow Workflows is a web-based computer vision application builder.
With Workflows, you can build complex, multi-step applications in a few minutes. This adds to the list of multimodal models available in Workflows, which includes OpenAI’s GPT-4o, Microsoft’s Florence-2, YOLO-World, Grounding DINO, and more.
The below Workflow, which we will build in this guide, could be used for consumer packaged goods inventory systems, or adapted for any multimodal data extraction use case.
Try the Workflow:
Without further ado, let’s get started!
Step #1: Create a Workflow
To get started, we need to create a Workflow.
Create a free Roboflow account. Then, click on “Workflows” in the left sidebar. This will take you to your Workflows home page, from which you will be able to see all Workflows you have created in your workspace.
Click “Create a Workflow” to create a Workflow.
You will be taken into the Roboflow Workflows editor from which you can build your application:
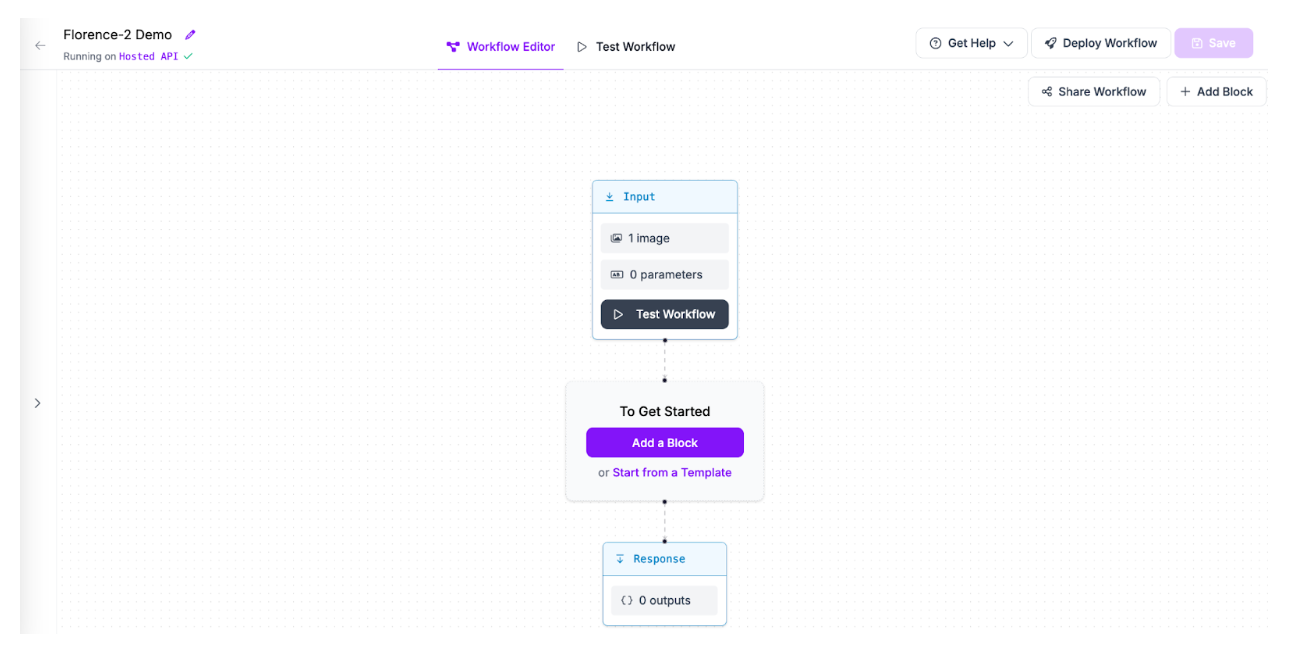
We now have an empty Workflow from which we can build an application.
Step #2: Add a Multimodal Model Block
To use Claude, Gemini, or GPT-4o in Workflows, you need to add the block that corresponds with the model that you want to use.
For this guide, let’s walk through an example that uses Claude.
Click “Add Block” to add a block. Then, search for Claude:
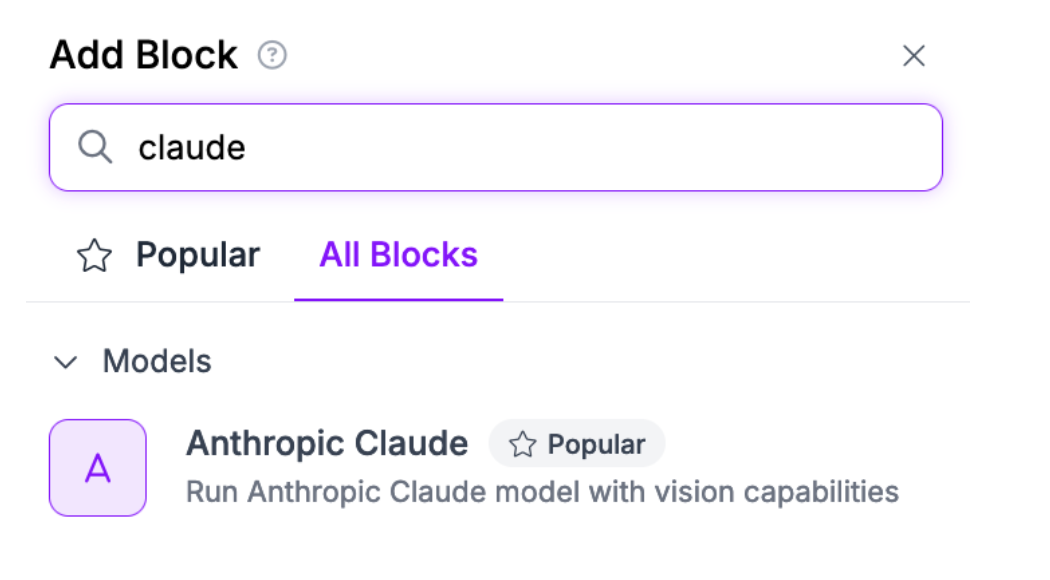
A configuration panel will appear in which you can configure the Claude block.
You can use Claude (and Gemini and GPT-4o) for several tasks, including:
- Open prompt: Directly passes your prompt to the multimodal model.
- Text recognition (OCR): Reads characters in an image.
- Structured output generation: Returns data in a specified format.
- Single-label and multi-label classification: Returns one or more labels that represent the contents of an image.
- Visual question answering: Answer a specific question about the contents of an image.
- Captioning: Returns an image caption.
- Unprompted object detection: Returns bounding boxes that correspond with the location of objects in an image.
For this guide, we are going to use Claude for structured data extraction. For this task, we will use the “Structured output generation” task.
In the Task Type dropdown, select “Structured output generation”.
We can then define a JSON representation of identifiers that map to descriptions.
Let’s search for three items on a coffee bag:
{
"name": "coffee name",
"roast date": "roast date",
"origin": "coffee origin"
}
The keys are the identifiers for each description. Descriptions are passed to the model, then the results are mapped back to the key.
Once you have set up your task and output, add your Claude API key:
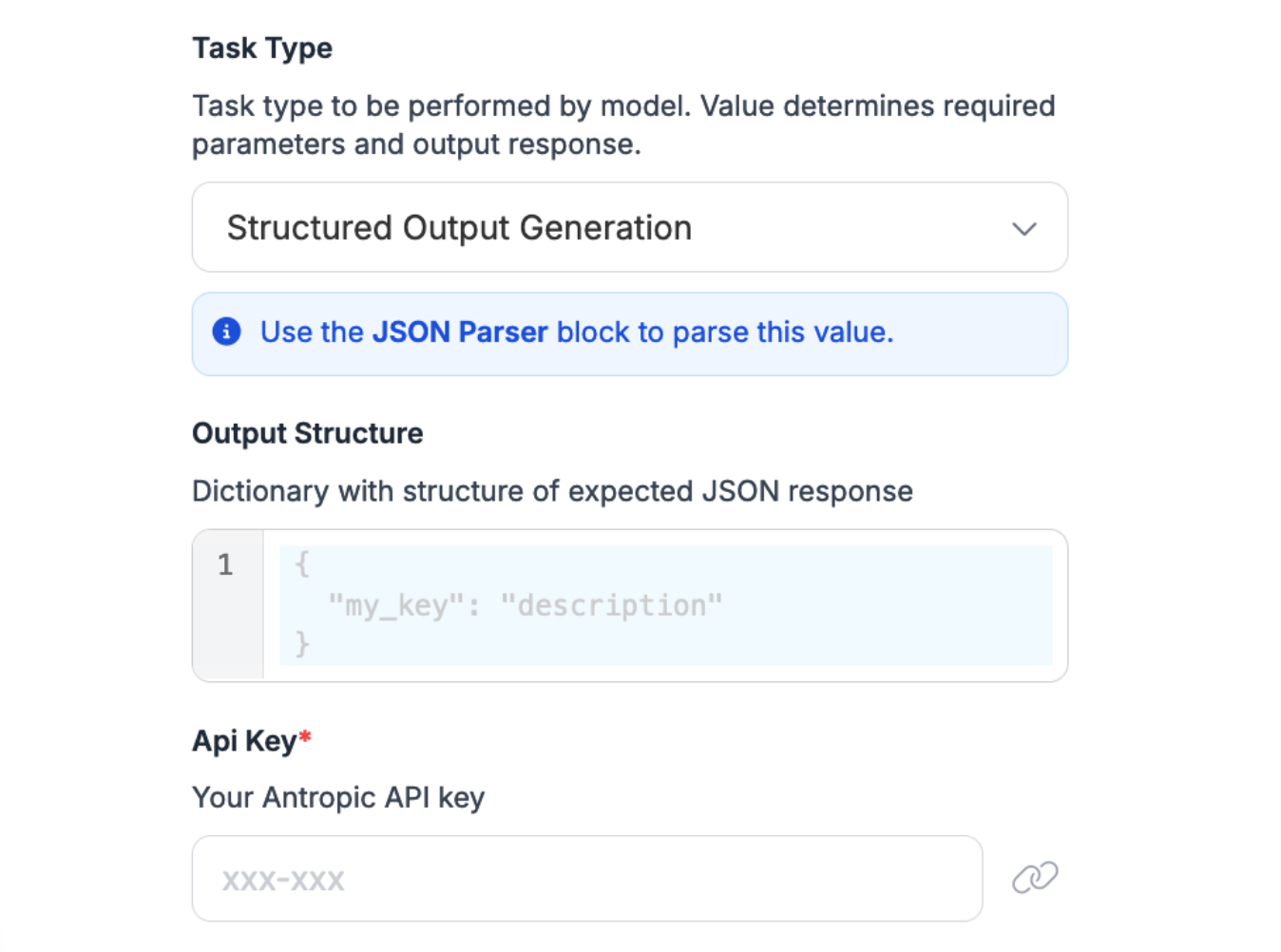
Once you have configured the block, you can run your Workflow.
Your Workflow should look like this:
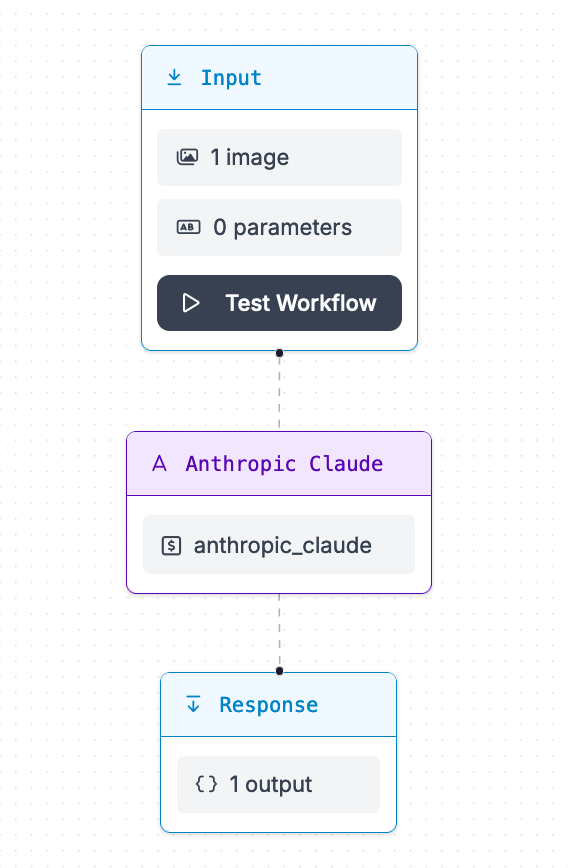
Our Workflow accepts an input image, sends the image to Claude, then returns the results.
This Workflow can be customized to add more logic. For example, you could run an object detection model, crop predictions, then send each individual prediction to Claude. Or you could run a person detection model to blur any instances of people in an image before sending it to Claude.
We encourage you to explore the Workflows interface and try out the various blocks available.
Step #3: Test the Workflow
To test the Workflow, click “Run Preview” at the top of the page.
To run a preview, first drag and drop an image into the image input field.
Click “Run Preview” to run your Workflow.
The Workflow will run and provide a JSON view with all of the data we configured our Workflow to return, and.
Let’s run the Workflow on this image:

Our Workflow returns:
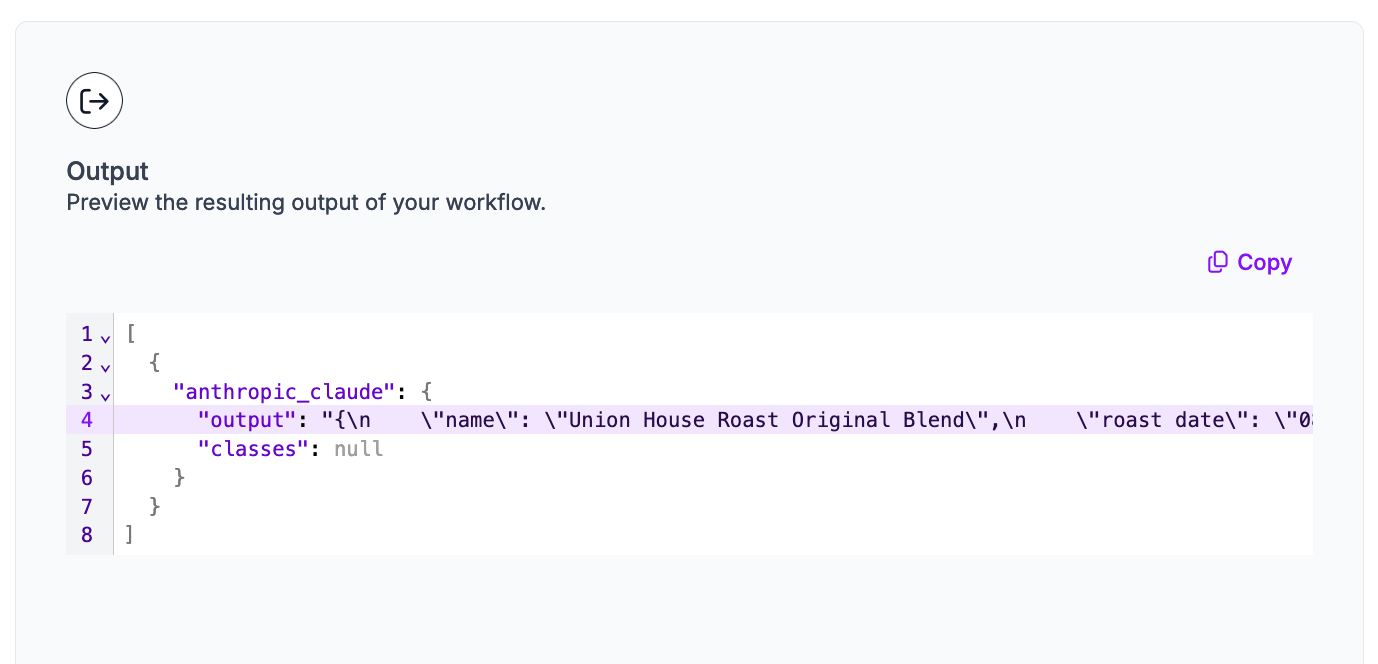
There is an output key with the results from our system. This key contains a string with a JSON representation of the output from our image. The results are:
[
{
"anthropic_claude": {
"output": "{\n \"name\": \"Union House Roast Original Blend\",\n \"roast date\": \"08/09/2020\",\n \"origin\": \"Asoproaaa cooperative, Colombia and Chirinos cooperative, Peru\"\n}",
"classes": null
}
}
]Claude successfully identified the name of the coffee, the roast date, and the cooperatives involved in roasting. With that said, we may want to tweak the output to separate origin and co-operatives, so that Claude only includes the country in the origin key. We can do this by modifying the structured output configuration.
Deploying the Workflow
Workflows can be deployed in the Roboflow cloud, or on an edge device such as an NVIDIA Jetson or a Raspberry Pi.
To deploy a Workflow, click “Deploy Workflow” in the Workflow builder. You can then choose how you want to deploy your Workflow.
To learn more about deploying Workflows, refer to the Roboflow Workflows Deployment documentation.
Conclusion
You can use Claude, Gemini, and GPT-4o in Roboflow Workflows to retrieve information about the contents of images. You can use these models for several tasks, from image captioning to classification to structured data extraction.
In this blog post, we created a Workflow that uses Claude to read coffee labels and extract data in a specific structure. This structure is then available in JSON to be programmatically parsed. For example, the packaging data extracted by the system built in this guide could be connected with a CPG inventory system.
To learn more about building with Roboflow Workflows, check out the Roboflow Workflows introduction guide, as well as our repository of Workflows tutorials.
Cite this Post
Use the following entry to cite this post in your research:
James Gallagher. (Oct 10, 2024). Launch: Use Claude and Gemini in Computer Vision Workflows. Roboflow Blog: https://blog.roboflow.com/claude-gemini-workflows/