
Using multimodal computer vision models, you can build complex systems to understand product inventory in an image. For example, you can build a system that identifies products in an image, then retrieves attributes and returns them as structured data.
Consider a scenario where you are building a consumer packaged goods inventory cataloging system. The system should let someone take a photo of a product and register structured data about the product in a system (i.e. name of the product, ID, SKU). With computer vision, you can build such a system.
In this guide, we are going to build a CPG inventory system. We will walk through an example that lets you take a photo of a bag of coffee and retrieve structured data about the coffee.
We do not need to write any code to develop the logic in our application. You can customize the application to identify different types of packaging (i.e. bags, boxes).
Here is an example of our inventory system in action:
Without further ado, let’s get started!
Build a CPG Inventory Cataloging System with Computer Vision
To build our system, we will:
- Configure the system to accept an image;
- Use a zero-shot model to identify products;
- Visualize the location of bounding boxes on our image;
- Crop all individual packages in an image;
- Run each product through GPT-4 to extract structured data;
- Return the results.
Our system will return a JSON result that can be processed with code.
Let’s discuss how this Workflow works in detail.
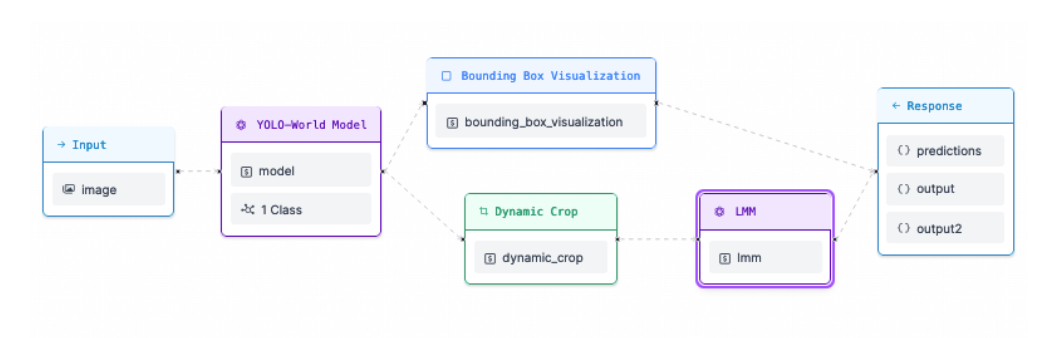
What is Roboflow Workflows?
Workflows is a low-code computer vision application builder. With Workflows, you can build complex computer vision applications in a web interface and then deploy Workflows with the Roboflow cloud, on an edge device such as an NVIDIA Jetson, or on any cloud provider like GCP or AWS.
Workflows has a wide range of pre-built functions available for use in your projects and you can test your pipeline in the Workflows web editor, allowing you to iteratively develop logic without writing any code.
Detect CPG Products with Computer Vision
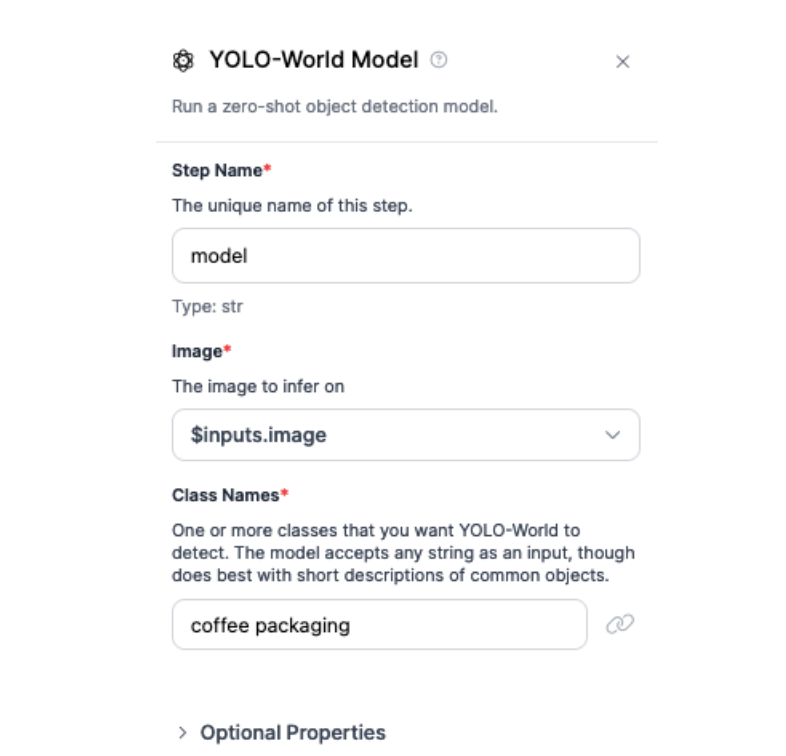
First, we need to be able to detect products. For this task, we will use YOLO-World, a zero-shot object recognition model. You can use YOLO-World to detect common objects (i.e. boxes, product packaging) without training a fine-tuned model.
By using YOLO-World, we can detect products without spending time building a custom model.
To detect coffee packaging, we provide the text prompt “coffee packaging” to our model:
Once YOLO-World has detected the product, we will crop them using the Dynamic Crop block. This will create new images using the detections from YOLO-World. For example, if an image contains three coffee packages, we will create three images: one for each package.
Extract Data from CPG Products with Computer Vision
To extract information from each package, we will use GPT-4o. We will make one call to GPT-4o for each cropped region of the original image.
By cropping images upfront, we can attribute each response to an image. This means we can associate responses with an image, so our inventory system can save both the image of a specific package and the metadata extracted from the image.
To extract data from packaging, we use GPT-4o. This model is accessed through the Large Multimodal Model (LMM) block.
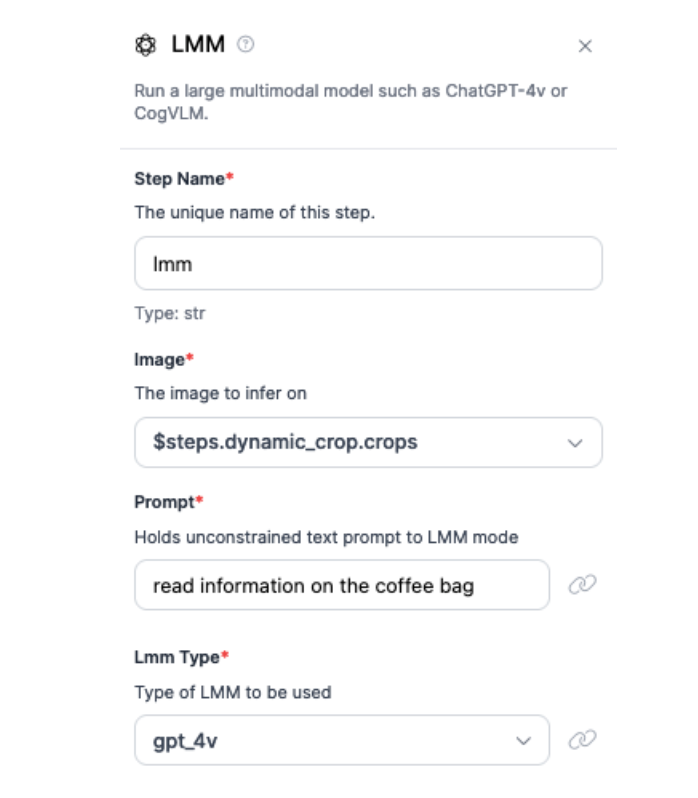
We provide the prompt “read information on the coffee bag”, and then use a custom JSON prompt in the “JSON Output” field to extract specific pieces of information:
{
"roast date": "roast date",
"country": "country",
"flavour notes": "flavour notes"
}The first values are the labels that will be returned by our workflow, and the second are the prompts associated with each value.
Visualize Predictions
Our Workflow contains a Bounding Box Visualization block. This block will show all predictions returned by YOLO-World. This is useful for debugging purposes; we can see exactly what regions were detected by YOLO-World.
Return a Response
We have configured our Workflow to return three values:
- The predictions from YOLO-World, the model we use for packaging detection;
- The response from our bounding box visualizer, and;
- The structured data response from GPT-4o.
Testing the Workflow
To test a Workflow, click “Run Preview” at the top of the page.
To run a preview, first drag and drop an image into the image input field.
Click “Run Preview” to run your Workflow.
The Workflow will run and provide two outputs:
- A JSON view, with all of the data we configured our Workflow to return, and;
- A visualization of predictions from our model, drawn using the Bounding Box Visualization block that we included in our Workflow.
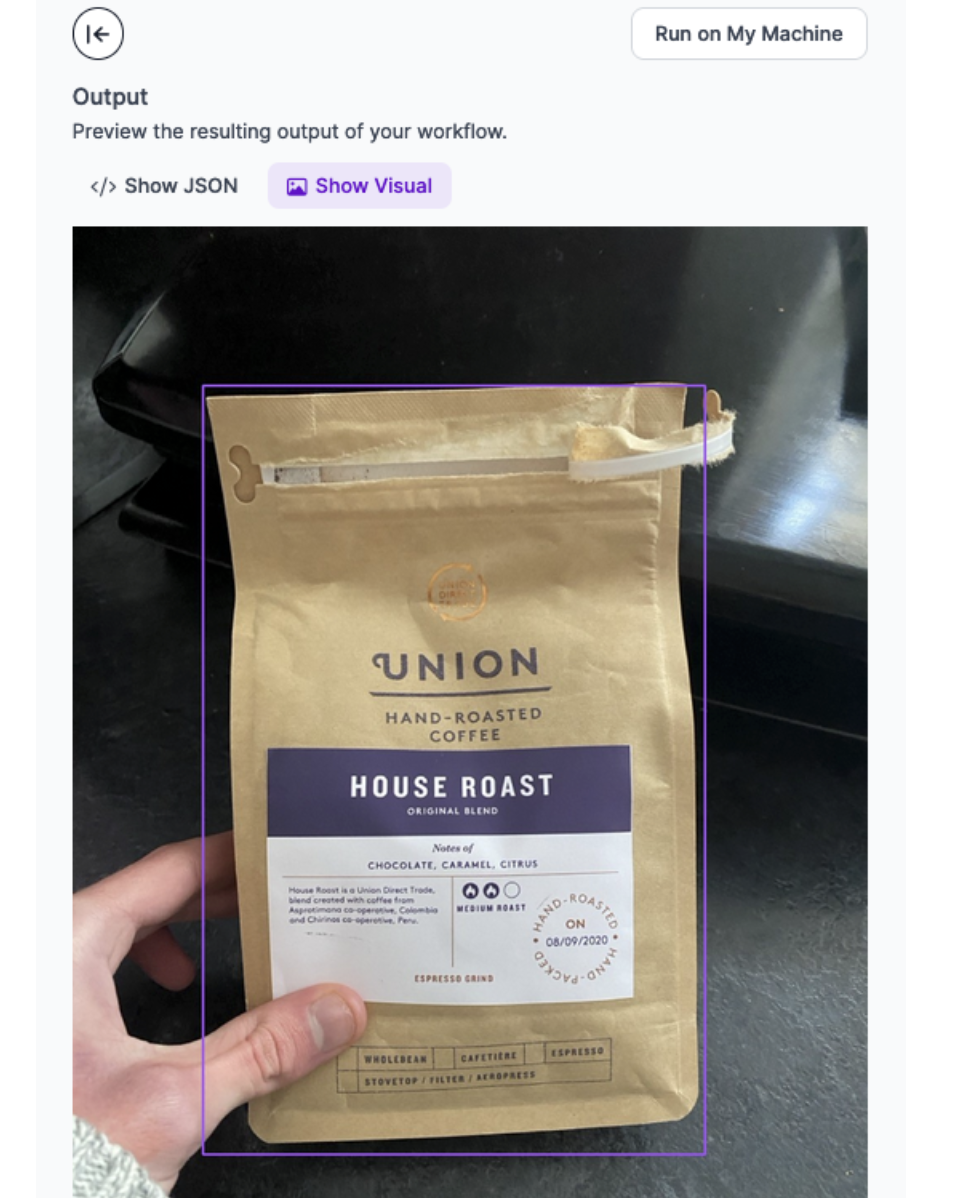
Let’s run the Workflow on this image:

Our Workflow returns a JSON response with data from GPT-4o, as well as a visual response showing the bounding box region from YOLO-World.
Here is the structured response from our Workflow:
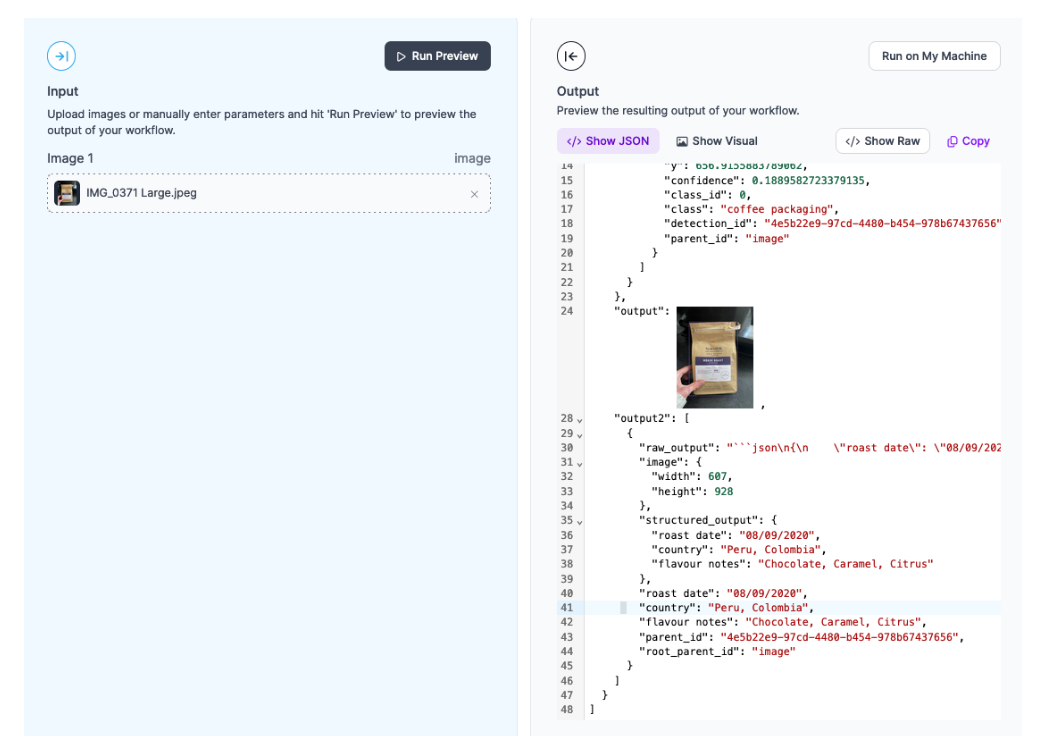
The response contains an accurate representation of the structured data we requested:
"structured_output": {
"roast date": "08/09/2020",
"country": "Peru, Colombia",
"flavour notes": "Chocolate, Caramel, Citrus"
}
Here is the visual response showing the detected coffee bags:
Deploying the Workflow
Workflows can be deployed in the Roboflow cloud, or on an edge device such as an NVIDIA Jetson or a Raspberry Pi.
To deploy a Workflow, click “Deploy Workflow” in the Workflow builder. You can then choose how you want to deploy your Workflow.
Conclusion
You can use computer vision to build complex packaging understanding systems.
In this guide, we used Roboflow Workflows to build a tool that identifies bags of coffee and extracts data from the coffee bags. This data is then returned as JSON, which could be saved in a packaging indexing system.
To learn more about building computer vision applications with Workflows, refer to the Roboflow Workflows documentation.
Cite this Post
Use the following entry to cite this post in your research:
James Gallagher. (Jul 25, 2024). How to Build a CPG Inventory Cataloging System. Roboflow Blog: https://blog.roboflow.com/cpg-inventory/