
Florence-2, developed by Microsoft Research, is a multimodal vision model with capabilities across several foundational vision tasks. You can use Florence-2 for zero-shot object detection, optical character recognition (OCR), and more.
You can deploy Florence-2 on Intel Emerald Rapids CPU systems. Emerald Rapids is the latest CPU released by Intel, offering cost improvements when compared to running models on a GPU. While Florence-2 was optimized for GPU, the model can run on CPUs with Roboflow Inference, an on-device computer vision inference server.
Here is an example showing Florence-2 detecting objects in an image, running on Intel Emerald Rapids:
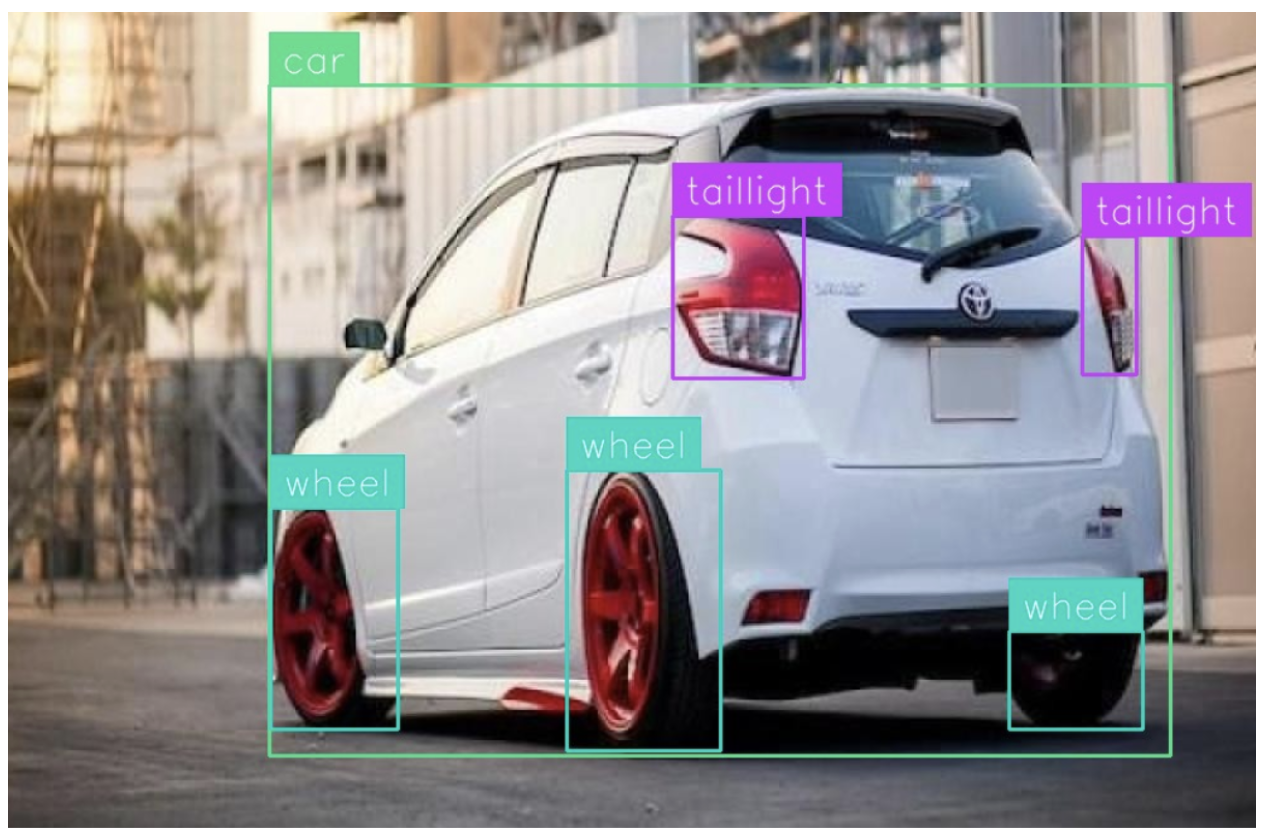
In this guide, we are going to walk through how to deploy Florence-2 with Intel Emerald Rapids on an Intel Emerald Rapids CPU system deployed on Google Cloud Platform.
Without further ado, let’s get started!
What is Florence-2?
Florence-2 is a multimodal model developed by Microsoft. The model is licensed under an MIT license. You can use Florence-2 for many tasks, including:
- Zero-shot object detection
- Zero-shot segmentation
- Optical Character Recognition (OCR)
- Region proposal
- Image captioning
- And more
Because all of these capabilities are available in a single model, Florence-2 is attractive for a wide range of computer vision applications.
For example, you could provision a server with Florence-2 to both identify the number of shipping containers in an image and read all text in the image.
To learn more about Florence-2, how the model works, and what it can do, refer to the Florence-2 guide.
Step #1: Provision an Intel Emerald Rapids CPU Instance
To start using Florence-2, we first need a device on which we can run the model. For that, we are going to deploy an Intel Emerald Rapids CPU instance. We will provision the CPU instance on Google Cloud Platform, on which the CPU type is generally available.
Open Google Cloud Platform and navigate to Compute Engine. Then, click “Create Instance”.
You can configure your new server with the hardware you need. Select the C4 Series, which uses Intel Emerald Rapids. Then, set up your system with the vCPUs, memory, and disk space you need.
We will create a c4-standard-4 instance with 4 vCPUs, 2 cores, and 15 GB of memory.
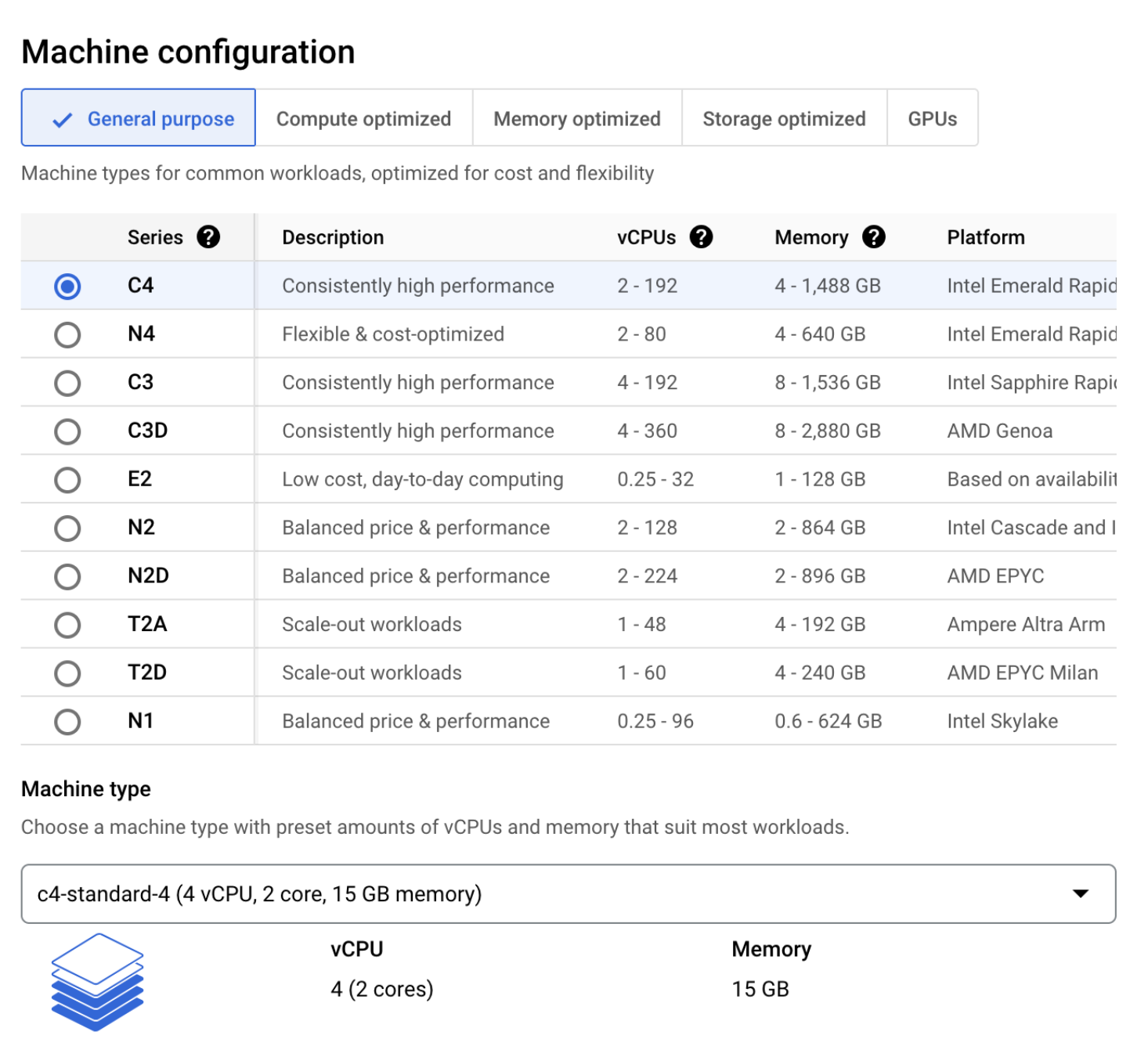
Once you have configured your server, provision the system. When your system is ready, SSH into the system.
Step #2: Install Roboflow Inference
With a system set up, you are ready to install Roboflow Inference. Inference is a computer vision inference server. You can run Inference both in Docker as a microservice, or run models directly through the Inference Python package.
For this guide, we will run models through the Inference Python package.
First, you will need to set up your system with Python 3.11, Inference, and relevant dependencies. You can install the required dependencies with the following commands:
sudo apt install python3.11-venv -y
python3 -m venv venv
source venv/bin/activate
curl -sSL https://bootstrap.pypa.io/get-pip.py -o get-pip.py
python3 get-pip.py
pip3 install roboflow inference
sudo apt-get install ffmpeg libsm6 libxext6 git-all -y
pip install torch torchvision transformers timm accelerate einops peftIt may take several minutes for all of the above commands to run.
Once the commands have run, you will be ready to start running Florence-2 on your system.
Step #3: Create an Inference Script
Let's try Florence-2 on two tasks: OCR with regions and object detection.
Create a new Python file and add the following code:
from inference import get_model
model = get_model("florence-2-base", api_key="API_KEY")
result = model.infer(
"image.jpeg",
prompt="<OCR_WITH_REGION>",
)
print(result[0].response)Above, replace:
- API_KEY with your Roboflow API key. Learn how to retrieve your Roboflow API key.
- Image.jpeg with the name of the image on which you want to run inference.
- <OCR_WITH_REGION> with the name of the task that you want to use.
You can see a full list of task types available in the Florence-2 Task Types section later in this blog post.
Let’s run our code on the following image of a shipping container:

Our code returns the following:
{'<OCR_WITH_REGION>': {'quad_boxes': [[109.80899810791016, 48.23649978637695, 350.3429870605469, 48.23649978637695, 350.3429870605469, 92.47550201416016, 109.80899810791016, 92.47550201416016], [466.875, 33.84550094604492, 476.8349914550781, 251.3094940185547, 460.89898681640625, 251.84249877929688, 453.4289855957031, 33.84550094604492], [208.91099548339844, 157.50149536132812, 257.7149963378906, 157.50149536132812, 257.7149963378906, 179.3544921875, 208.91099548339844, 179.3544921875], [196.95899963378906, 183.61849975585938, 270.1650085449219, 183.61849975585938, 270.1650085449219, 204.93849182128906, 196.95899963378906, 204.93849182128906], [216.38099670410156, 231.5885009765625, 251.24099731445312, 231.5885009765625, 251.24099731445312, 253.97450256347656, 216.38099670410156, 253.97450256347656]], 'labels': ['</s>J.B.HUNT', 'JHU N336853', 'JBHU', '236853', '53']}}Our system successfully identified text in the image.
The labels are:
J.B.HUNT(container logo, correct)JHU N336853(attempted vertical container ID, but incorrect)JBHU(container ID, correct)236853(container ID, correct)
We also have the bounding box regions corresponding with each label, ideal if we wanted to do post-processing (i.e. find bounding boxes in a certain region, exclude vertical bounding boxes, etc.). Of note, Florence-2 struggles with vertical OCR. In a production scenario, we would exclude the vertical bounding box from above given the model is less likely to return an accurate result.
Next, let’s try Florence-2 on object detection.
Create a new file and add the following code:
import supervision as sv
import cv2
from inference import get_model
model = get_model("florence-2-base", api_key="OCR_WITH_REGION")
CLASSES = ["vehicle"]
result = model.infer(
"image.jpeg",
prompt="<OD>",
classes=CLASSES
)
detections = sv.Detections.from_lmm(
sv.LMM.FLORENCE2,
result,
resolution_wh=(result.image.width, result.image.height),
classes=CLASSES
)
image = cv2.imopen("image.jpeg")
detections = sv.Detections(...)
box_annotator = sv.BoxAnnotator()
label_annotator = sv.LabelAnnotator()
annotated_frame = box_annotator.annotate(
scene=image.copy(),
detections=detections
)
annotated_frame = label_annotator.annotate(
scene=image.copy(),
detections=detections
)
annotated_frame.save("output.png")The code will return a list of bounding boxes corresponding to the results from the model.
We can visualize the results with supervision, an open source Python package with utilities for working with computer vision models.
This will save a new version of the input image with bounding boxes and labels.
Replace car in the code above with the class(es) you want to identify.
Let’s run the code on the following image of cars:

Here is the result of the code:
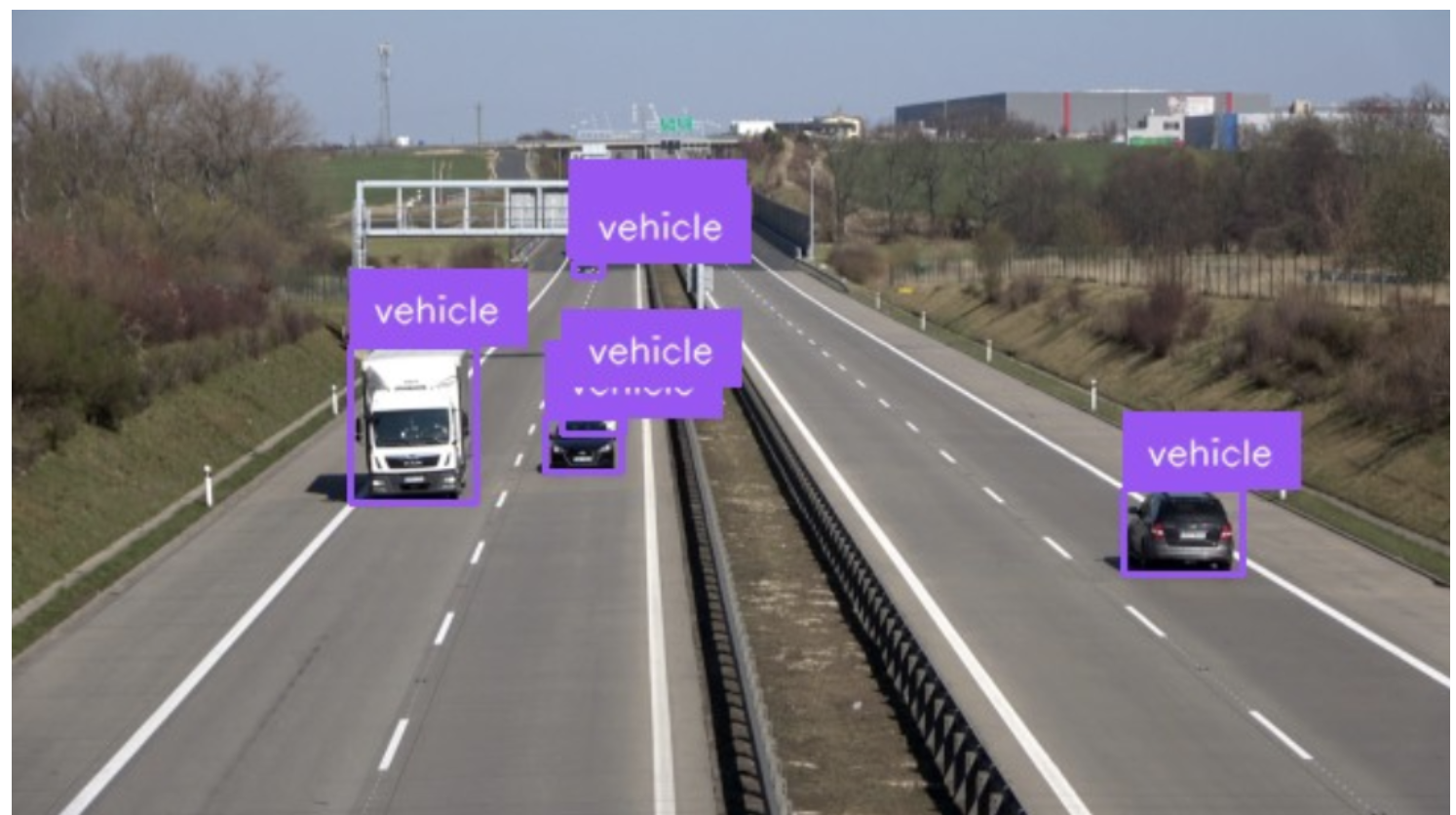
Florence-2 successfully identified bounding boxes corresponding to cars.
If you use Florence-2 for segmentation, you will need to use the MaskAnnotator() class to visualize masks. This class is designed for plotting segmentation masks on images.
Florence-2 Task Types
Florence-2 supports many multimodal tasks. Inference supports using 11 of the tasks implemented in Florence-2. The supported tasks are:
- Object detection: Identify the location of all objects in an image. (<OD>)
- Dense region captioning: Generate dense captions for all identified regions in an image. (<DENSE_REGION_CAPTION>)
- Image captioning: Generate a caption for a whole image. (<CAPTION> for a short caption, <DETAILED_CAPTION> for a more detailed caption, and <MORE_DETAILED_CAPTION> for an even more detailed caption)
- Region proposal: Identify regions where there are likely to be objects in an image. (<REGION_PROPOSAL>)
- Phrase grounding: Identify the location of objects that match a text description. (<CAPTION_TO_PHRASE_GROUNDING>)
- Referring expression segmentation: Identify a segmentation mask that corresponds with a text input. (<REFERRING_EXPRESSION_SEGMENTATION>)
- Region to segmentation: Calculate a segmentation mask for an object from a bounding box region. (<REGION_TO_SEGMENTATION>)
- Open vocabulary detection: Identify the location of objects that match a text prompt. (<OPEN_VOCABULARY_DETECTION>)
- Region to description: Generate a description for a region in an image. (<REGION_TO_DESCRIPTION>)
- Optical Character Recognition (OCR): Read the text in an image. (<OCR>)
- OCR with region: Read the text in a specific region in an image. (<OCR_WITH_REGION>)
You can use each of these inference methods by setting the prompt argument in your model.infer call to the value corresponding with the task type you want to use.
Florence-2 Benchmarking
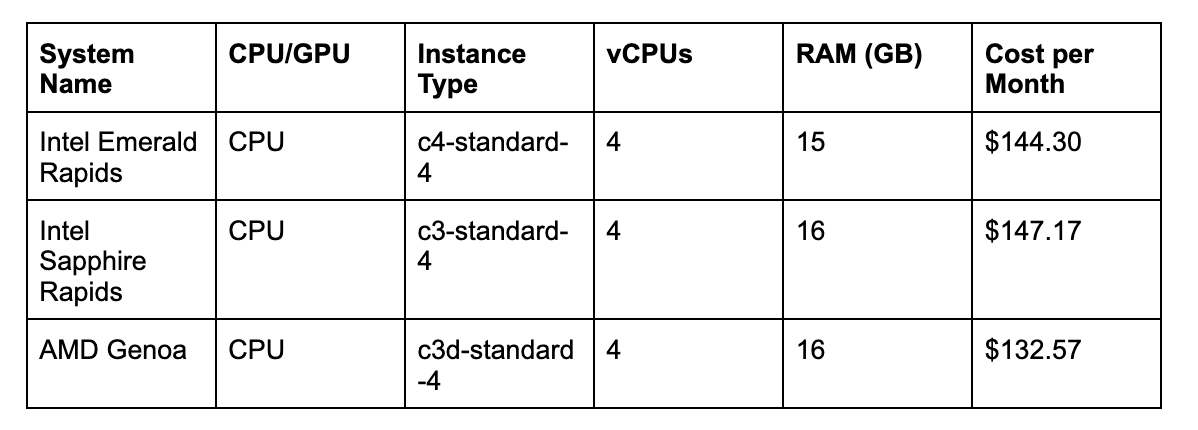
We benchmarked Florence-2 on Intel Emerald Rapids and Intel Sapphire Rapids systems on Google Cloud Platform to analyze performance improvements between the generations of CPUs. We also benchmarked performance on AMD’s Genoa architecture.
We chose the following system types in GCP:
Here are the results from our Inference benchmarks:
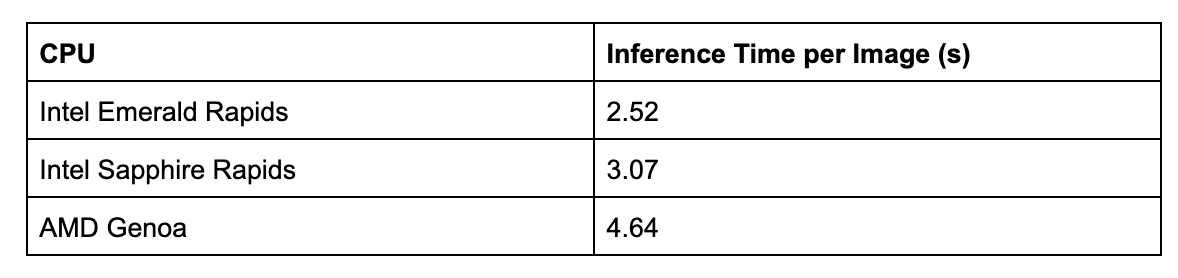
Intel Emerald Rapids achieves the lowest inference time per image out of all CPU architectures we tested, followed by Intel Sapphire Rapids. Intel Emerald Rapids, on average, processes images 0.55s faster than the previous generation Sapphire Rapids CPU system.
The above benchmarks were calculated by taking the average of 10 inferences across all systems.
Conclusion
Florence-2 is a multimodal model developed by Microsoft Research. You can use Florence-2 for a wide range of tasks, including zero-shot object detection, image captioning, and zero-shot segmentation.
In this guide, we walked through how to deploy Florence-2 on an Intel Emerald Rapids system. We provisioned an Intel Emerald Rapids system on Google Cloud Platform, then installed Inference and required dependencies. We then ran inference on both a captioning and object detection task.
To learn more about the capabilities of Florence-2, refer to the Florence-2 guide.
Cite this Post
Use the following entry to cite this post in your research:
James Gallagher. (Nov 19, 2024). How to Deploy Florence-2 with Intel Emerald Rapids. Roboflow Blog: https://blog.roboflow.com/deploy-florence-2-intel-emerald-rapids/