
On August 7th, 2025, OpenAI released GPT-5, the newest model in their GPT series. GPT-5 has advanced reasoning capabilities and, like many recent models by OpenAI, multimodal support. This means that you can both prompt GPT-5 with one or more images and ask for an answer, but also prompt the model to spend more time reasoning before answering.
This combination – of reasoning and visual capabilities – has been present in several “o” models by OpenAI. Reasoning models consistently score high on Vision Checkup, the open source qualitative vision model evaluation tool. Indeed, the top four models on the leaderboard are all reasoning models.
On our tests, GPT-5 tied for first on Vision Checkup with GPT o4 Mini:

In this guide, we are going to walk through our qualitative preliminary tests of GPT-5 for visual understanding, as well as our benchmarks from RF100-VL.
You can try GPT-5 short captioning in the widget below.
GPT-5 for Document Understanding and OCR
We evaluated GPT-5 on 10 document understanding / OCR tests, covering everything from retrieving information from a dense table to reading a torn receipt.
Here are a few examples showing where the model did well and struggled:
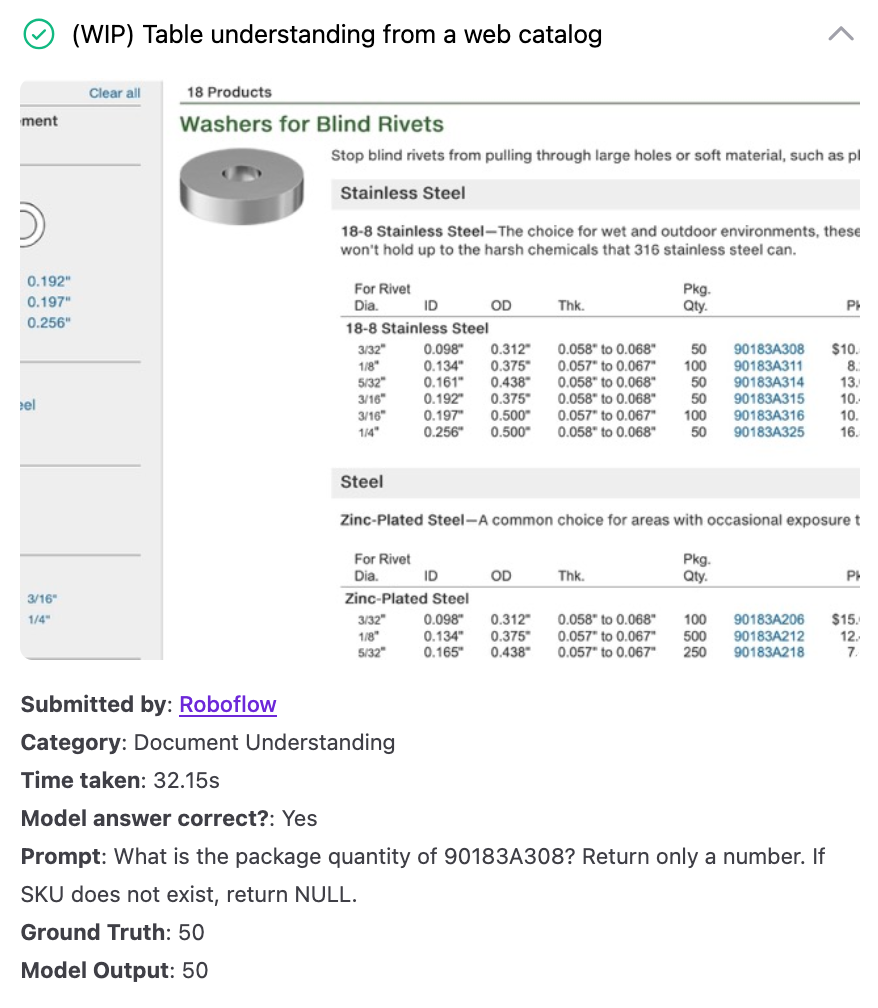
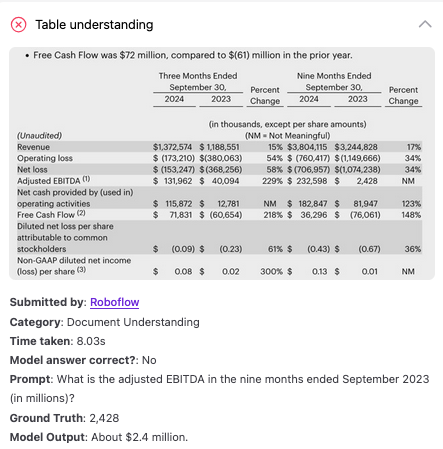

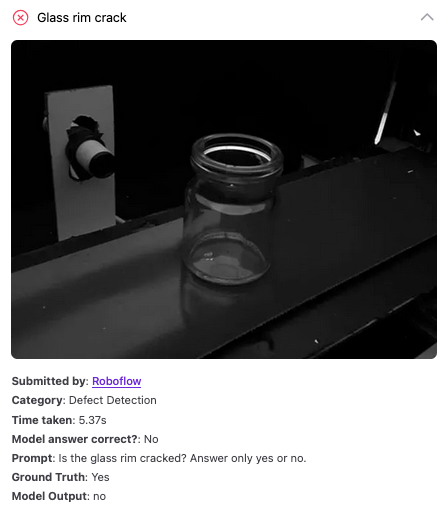
GPT-5 for Defect Detection
Out of 15 defect detection prompts, GPT-5 got 12 of 15 assessments correct. For example, the model was able to find the general location of a defect in a piece of metal and identify cracks in a piece of wood. The model struggled with some tasks, like finding a small crack on the edge of glass.
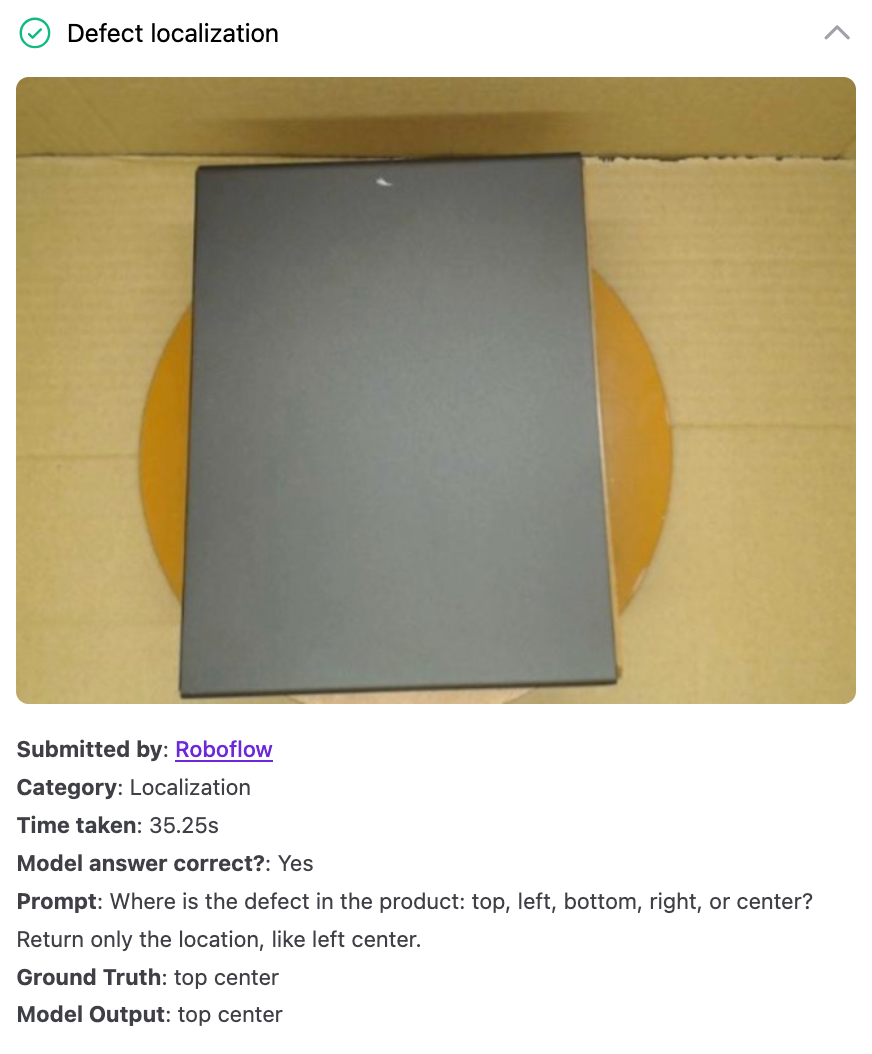
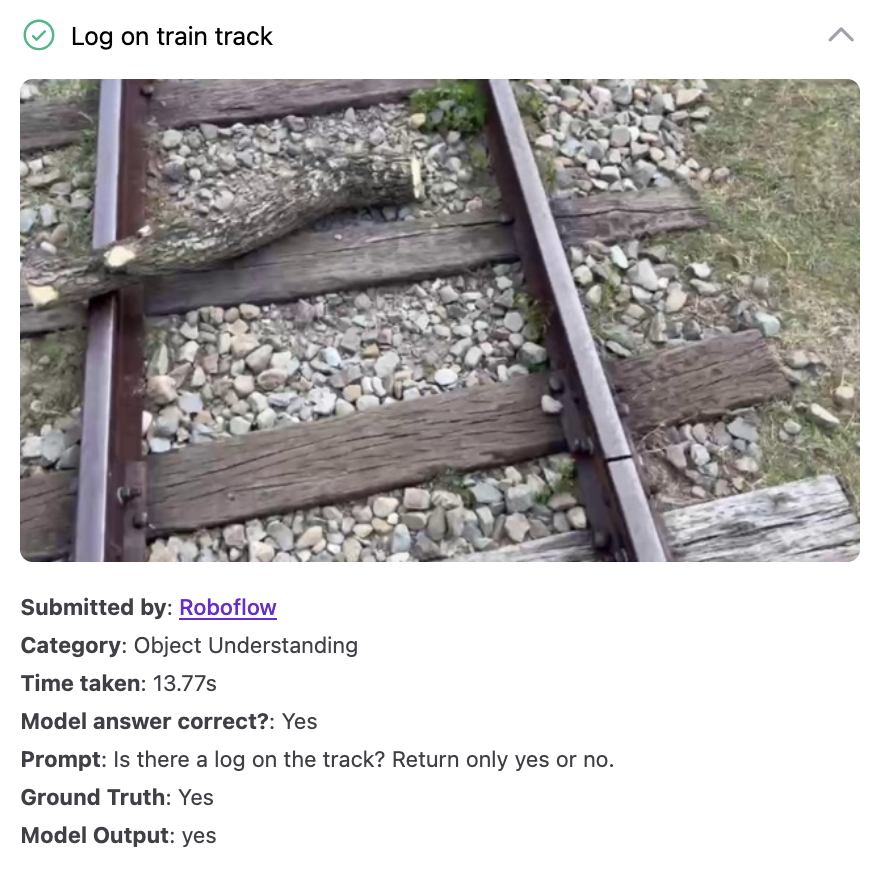

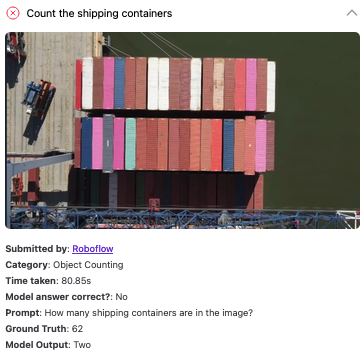
GPT-5 for Object Counting
We tested GPT-5 on 10 object counting tasks. This is a task with which several multimodal models struggle. GPT-5 correctly counted the number of specified objects in 4 of 10 images.
Here are a few of our results:


The model also struggles with object measurement. In our standard test where we ask GPT to measure the dimensions of a sticker positioned next to a rule, the model incorrectly answered the question:

GPT-5 for Object Detection: Benchmarks with RF100-VL
RF100-VL is a benchmark that asks “How well does your VLM understand the real world?”. This question is analyzed from the lens of performance on an object detection task in a multi-modal setting. Indeed, the ability to find the location of an object in an image signals greater understanding of the contents of the input data.
RF100-VL consists of 100 open source datasets containing object detection bounding boxes and multimodal few shot instruction with visual examples and rich textual descriptions across novel image domains.
The current SOTA among all MLLMs is Gemini 2.5 Pro, achieving a zero-shot mAP50:95 of 13.3:

After running GPT5 with this prompt on RF100-VL we got the mAP50:95 of 1.5. This is significantly lower than the current SOTA of Gemini 2.5 Pro of 13.3.
Reasoning and Visual Task Performance with GPT-5
All of the top five models on the Vision Checkup leaderboard are configurations of models with reasoning capabilities. In our tests, GPT-5 consistently scored in the top five. Our leaderboard consists of ~90 prompts so the extent to which the results can be extrapolated to say which model is “best” are limited.
With that said, GPT-5 consistently scoring high – with examples of prompts we ran through the leaderboard available earlier in this post – is consistent with a trend we have observed: reasoning-capable models perform increasingly well at vision tasks.
This marks the continuation of an important development in multi-modal large language models: the ability to reason over both text and vision modalities.
Curiously, when we ran GPT-5 with high reasoning, we observed worse performance on vision tasks. With that said, we observe that scores vary pretty significantly between individual runs of our evals. We attribute this to multiple reasons. The biggest one is the stochasticity of the reasoning mode for OpenAI models; we previously observed that prompting a reasoning model with the same question twice can lead to both correct and incorrect answers.
Our benchmark is also not very large, so instability on a single-question level bears large significance. And lastly, we were testing the model during its very early stages, so any issues on the api side can also be contributing to this result.
We plan to re-run our evaluations over the next few days to verify our results.
Conclusion
GPT-5’s improved reasoning pushes it high on the Vision Checkup leaderboard, showing how multi-step thinking helps models extract more insight from images. Still, RF100-VL highlights a key gap: understanding isn’t the same as locating. Without object detection foundations, the model’s predictions often land wide.
That said, GPT-5’s leap in visual reasoning points to a promising direction — one where models don’t just look harder, but think smarter about what they see.
Cite this Post
Use the following entry to cite this post in your research:
James Gallagher. (Aug 7, 2025). GPT-5 for Vision: Results from 80+ Real-World Tests. Roboflow Blog: https://blog.roboflow.com/gpt-5-vision-multimodal-evaluation/