
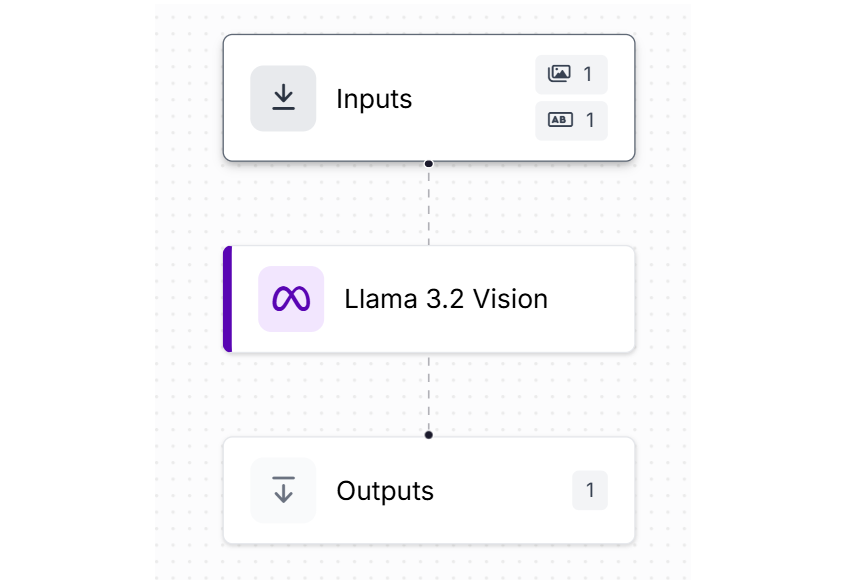
The Llama 3.2 Vision Block in Roboflow Workflow lets you use Meta’s multimodal Llama 3.2 model in your computer vision pipelines.
In this guide, we are going to walk through how to use Llama 3.2 Vision for optical character recognition in Roboflow Workflows. By the end of this guide, we will have a Workflow that can do tasks like read barcode numbers, read the text from a screenshot of a document, and more.
Let's get started!
Using Llama 3.2 Vision for OCR
For extracting text from images using the Llama 3.2 Vision Block in Roboflow Workflows, the following task types can be used:
Task Type: Text Recognition (OCR)
This task type is specifically designed for extracting text from images. It uses the model's OCR capabilities to recognize and extract text from visual data. This task type can be used to extract all text from scanned documents, receipts, or images containing text. The extracted text is returned as a plain string.
We will see how to build a Workflow for this task type. We will use following input image.

Create a new workflow and add “Llama 3.2 Vision” block to it.
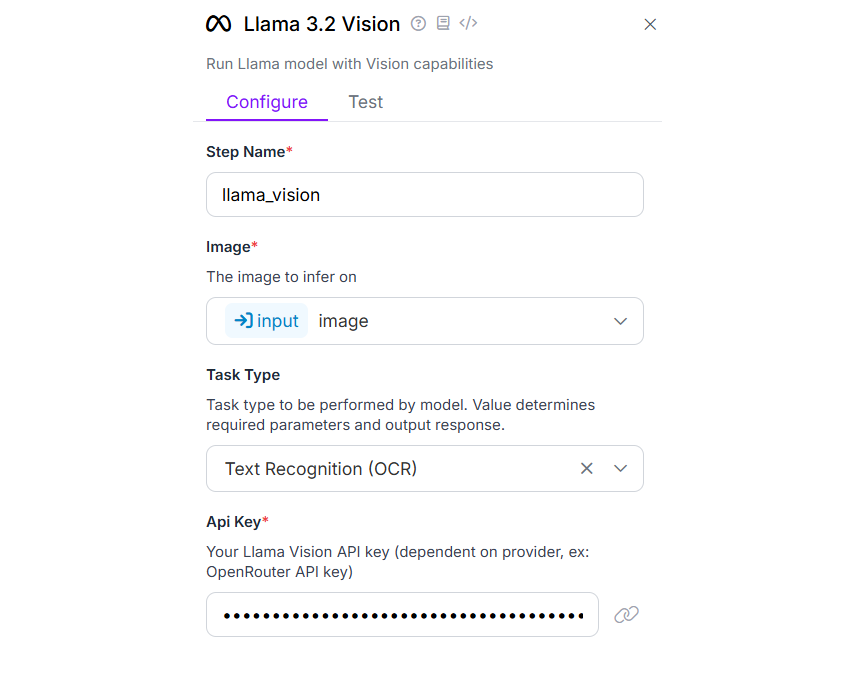
In the Llama 3.2 Vision block, configure the task type as “Text Recognition (OCR)”.
When you run the workflow, you will all text from image is extracted.
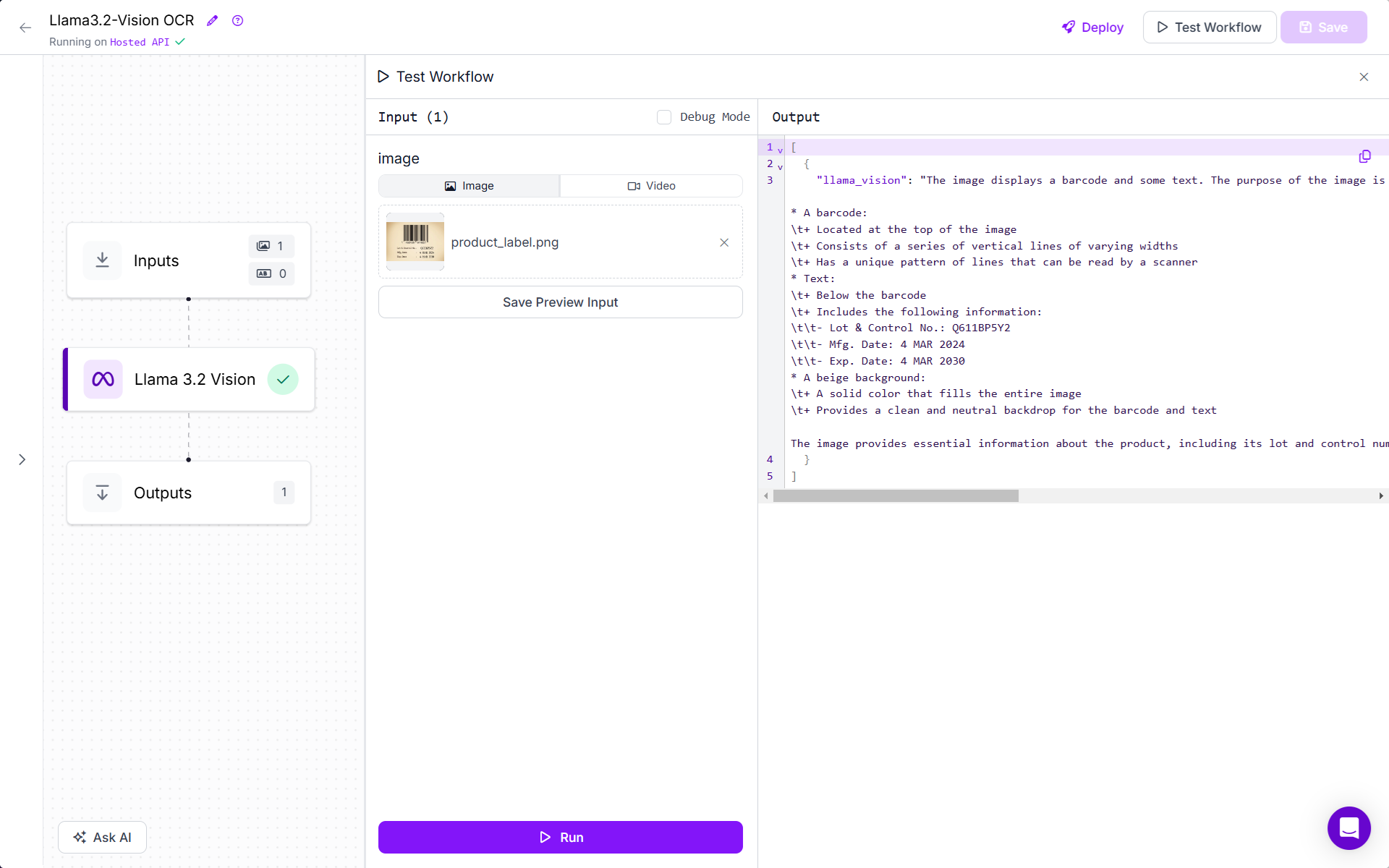
The returned text is in string form. You can further use other blocks like Custom Python block or build your personal application to further process this data.
Task Type: Open Prompt (Unconstrained)
While not specifically designed for OCR, the open prompt task type can be used to extract text by providing custom prompt like:
"Extract product number and expiry date from image in CSV format."
This task type can be used for flexible or custom text extraction when you need to extract information in your own specified format. The model will generate a response containing the extracted text. The output may be structured or plain text depending on your prompt. For this example, we will use following input image.

Create a workflow as following.
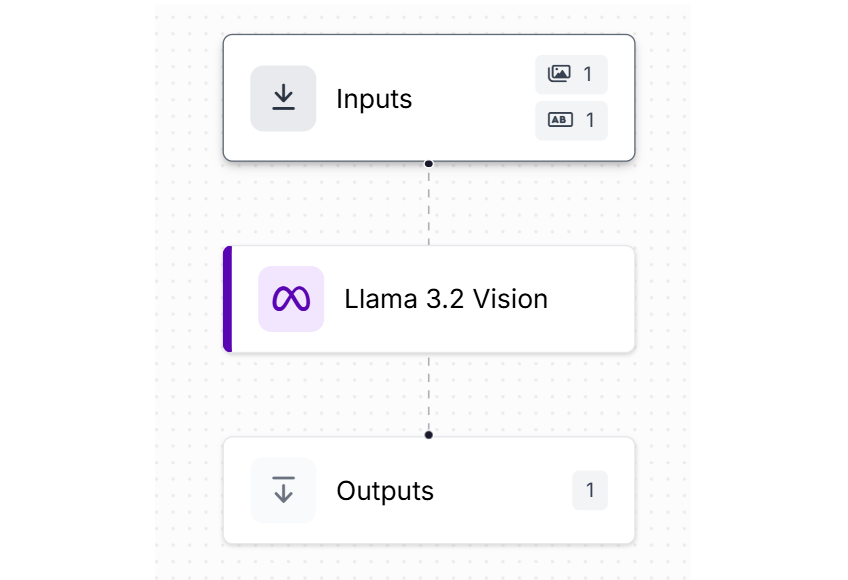
In the input block, add a parameter “prompt”. This will be used to specify prompt at run time.
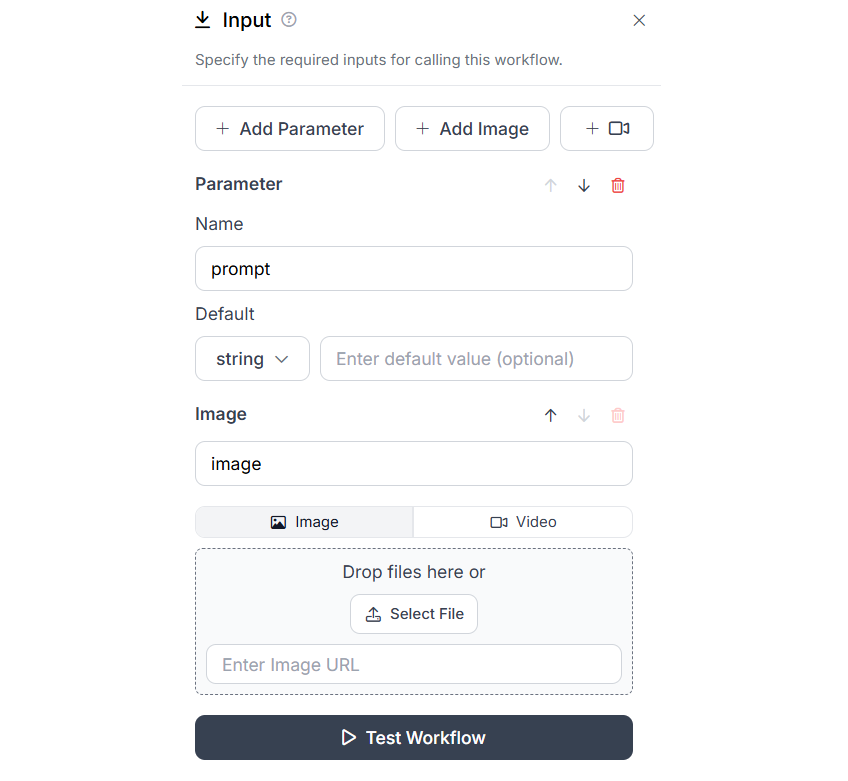
In the Llama 3.2 Vision block, configure task type as “Open Prompt” and bind the Prompt property with the “prompt” parameter defined in input block.
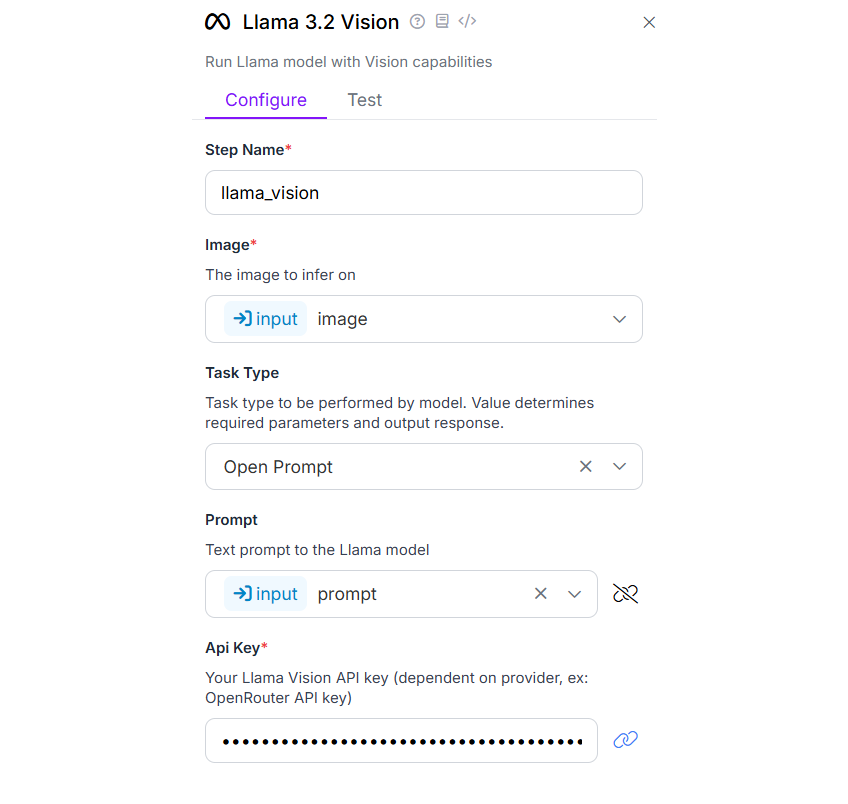
Now run the workflow by uploading image and specifying following prompt:
Extract date, time and total cost from image in JSON format { "Date:" : "", "Time:" : "", "Total Cost:" : ""}
You will see output as below.
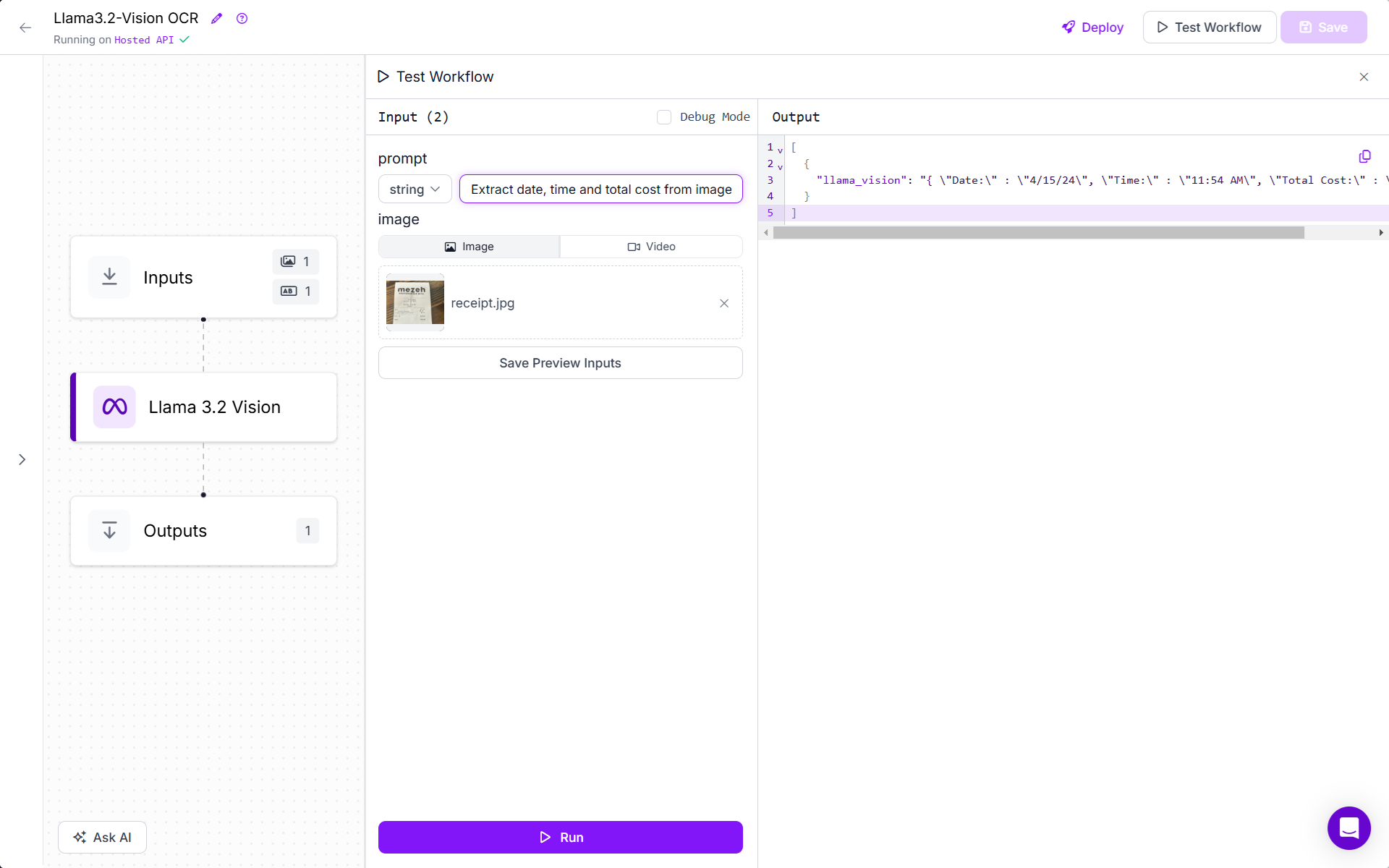
You will see only the desired piece of information in your specified format.
[
{
"llama_vision": "{ \"Date:\" : \"4/15/24\", \"Time:\" : \"11:54 AM\", \"Total Cost:\" : \"$16.98\" }"
}
]
Task Type: Visual Question Answering (VQA)
This task type allows you to ask specific questions about the text in an image. For example:
"What is the expiry date?"
"What is the product number?"
This task type helps extracting specific pieces of text from an image, such as product number, dates etc. This type of information is very useful for applications like inventory management across various industries. The model will return the text relevant to the question asked. For this example, create a Workflow as following.
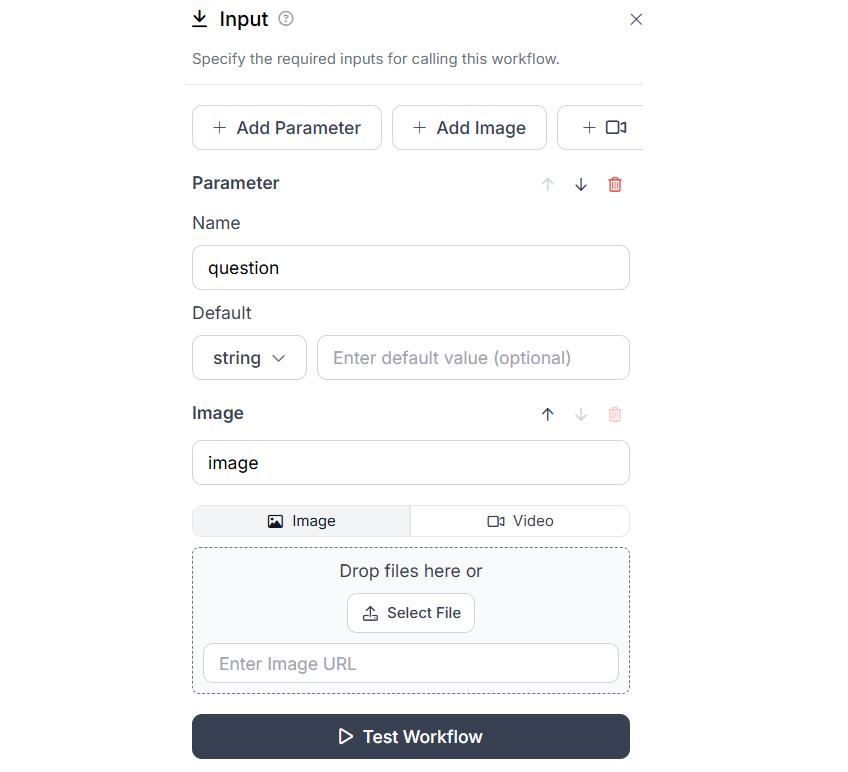
In the input block, add a parameter “question”. This will be used to specify Question at run time.
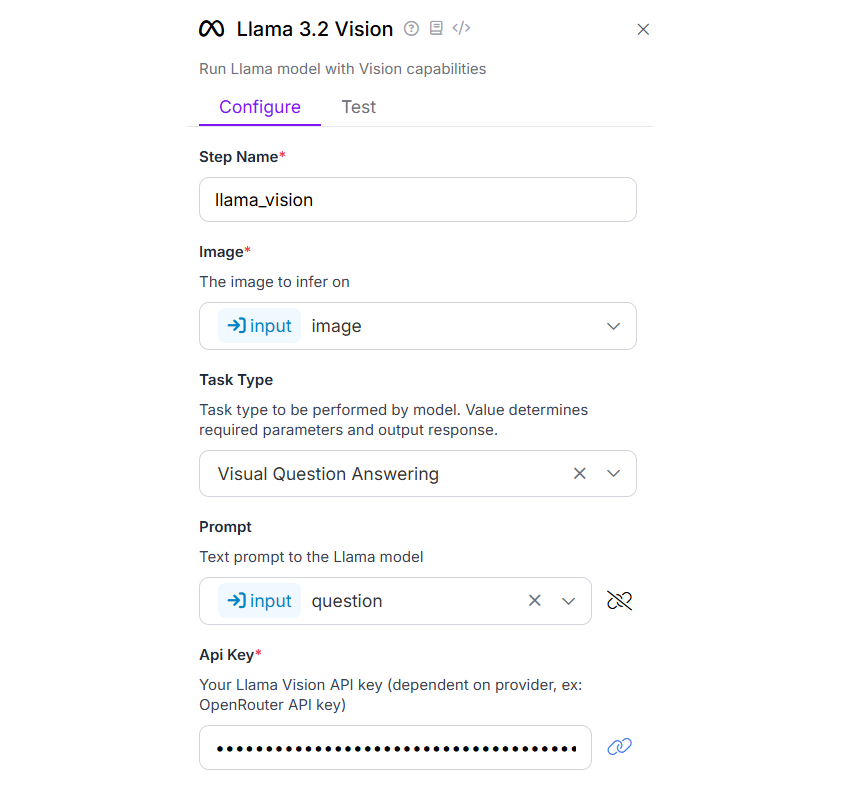
In the Llama 3.2 Vision block, configure task type as “Visual Question Answering” and bind the Prompt property with the “question” parameter defined in input block.
Now run the workflow by uploading image of product label that we used in “Text Recognition (OCR)” section and specifying following prompt:
“What is the expiry date?”
You will see output as below.
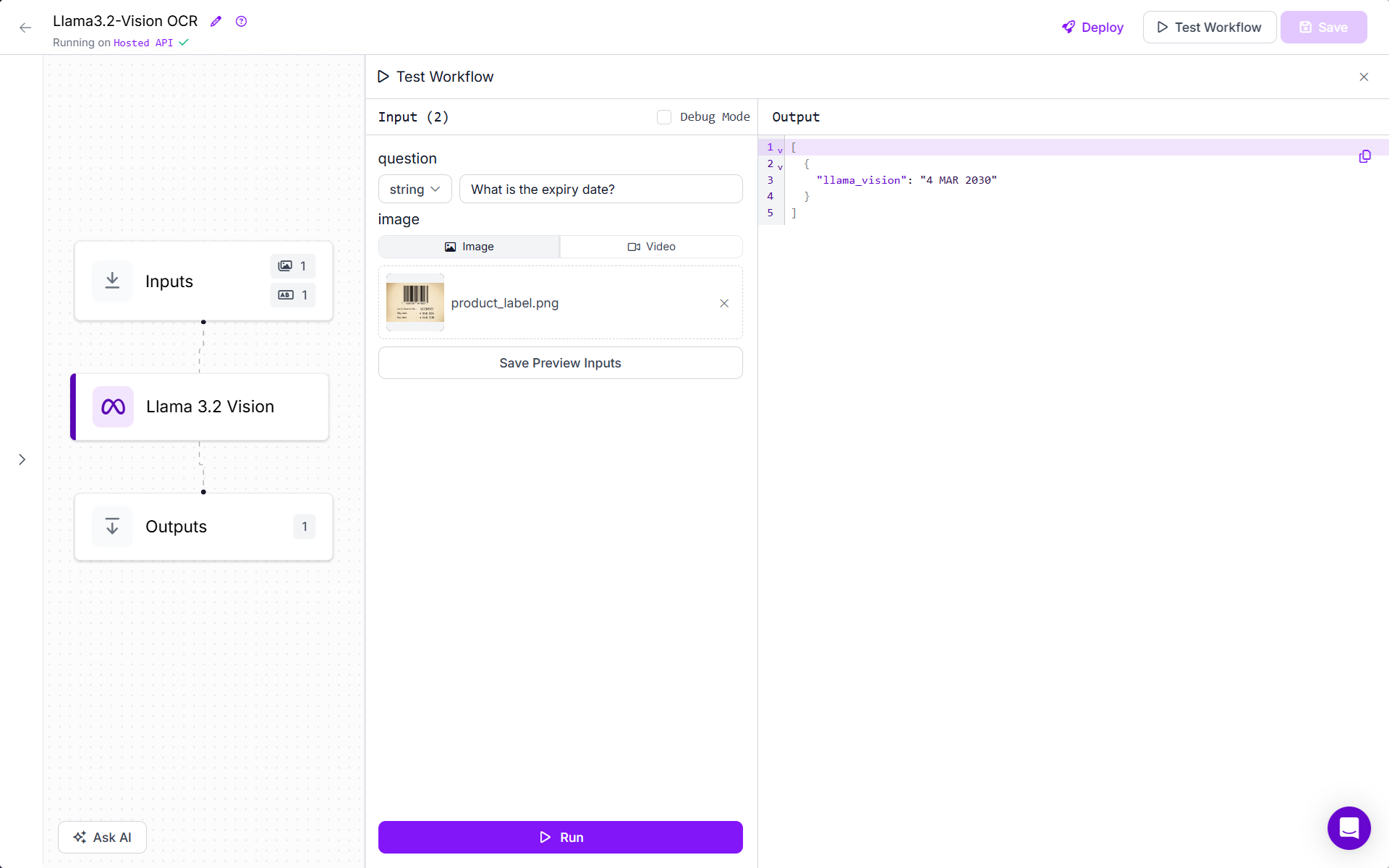
The workflow will only fetch the expiry date. This task type can be used only when you need specific information.
Task Type: Structured Output Generation
If you need the extracted text in a structured JSON format, you can use this task type. This task type can be used when you need to extract text for integration with other systems or workflows that require structured data. The model will attempt to return the extracted text in a structured JSON format. You can extract text in any complex structured format with the help of this task type. For this example, we will use following image.

We will be extracting all Food Type, Item and its Price in the structured from the above breakfast menu image. Create a Workflow as following.
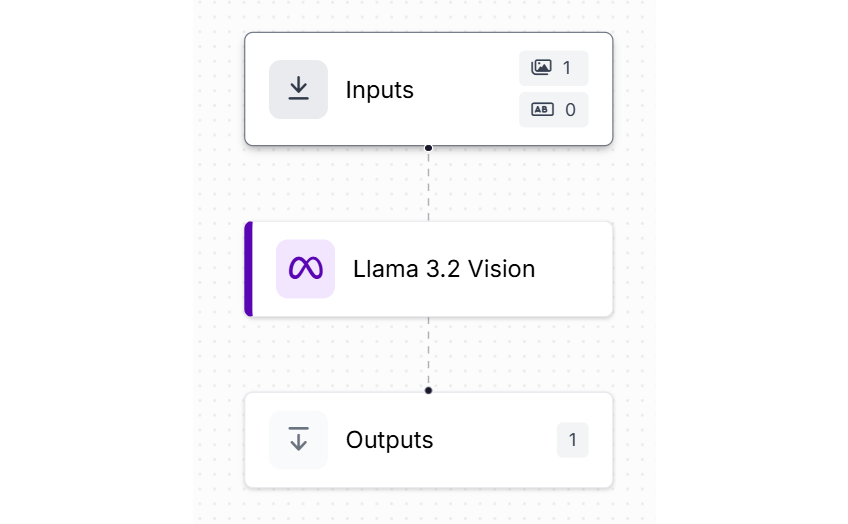
Configure the Llama 3.2 Vision block with task type as “Structured Output Generation” and specify the value to “Output Structure” parameter as following.
{
"Food Type": "",
"Item": "",
"Price": ""
}
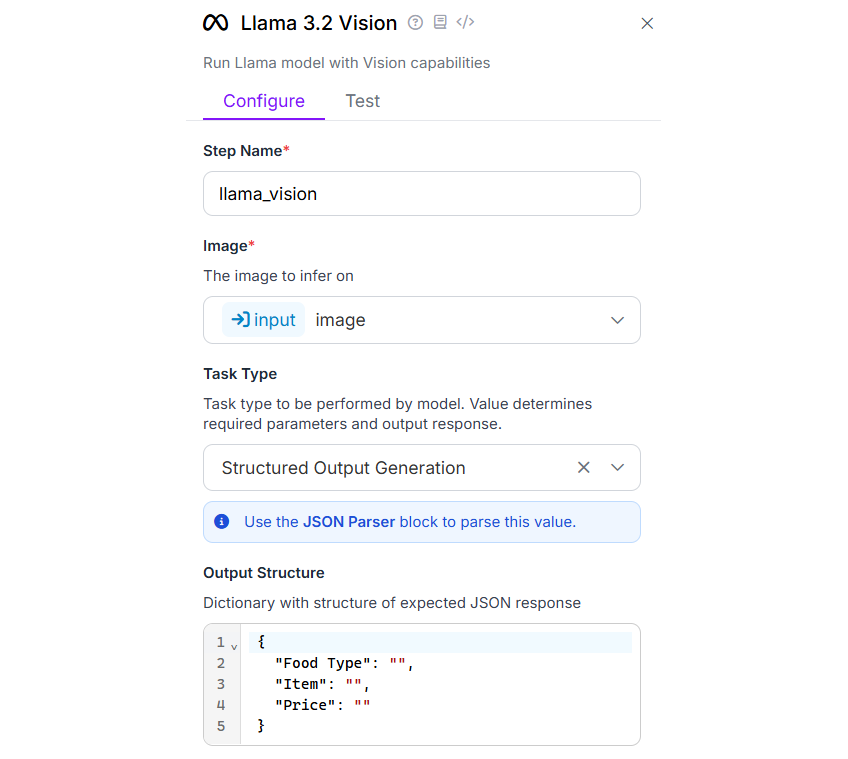
The configuration for Llama 3.2 Vision block for "Structured Output Generation" should look like following.
You will see the following output.
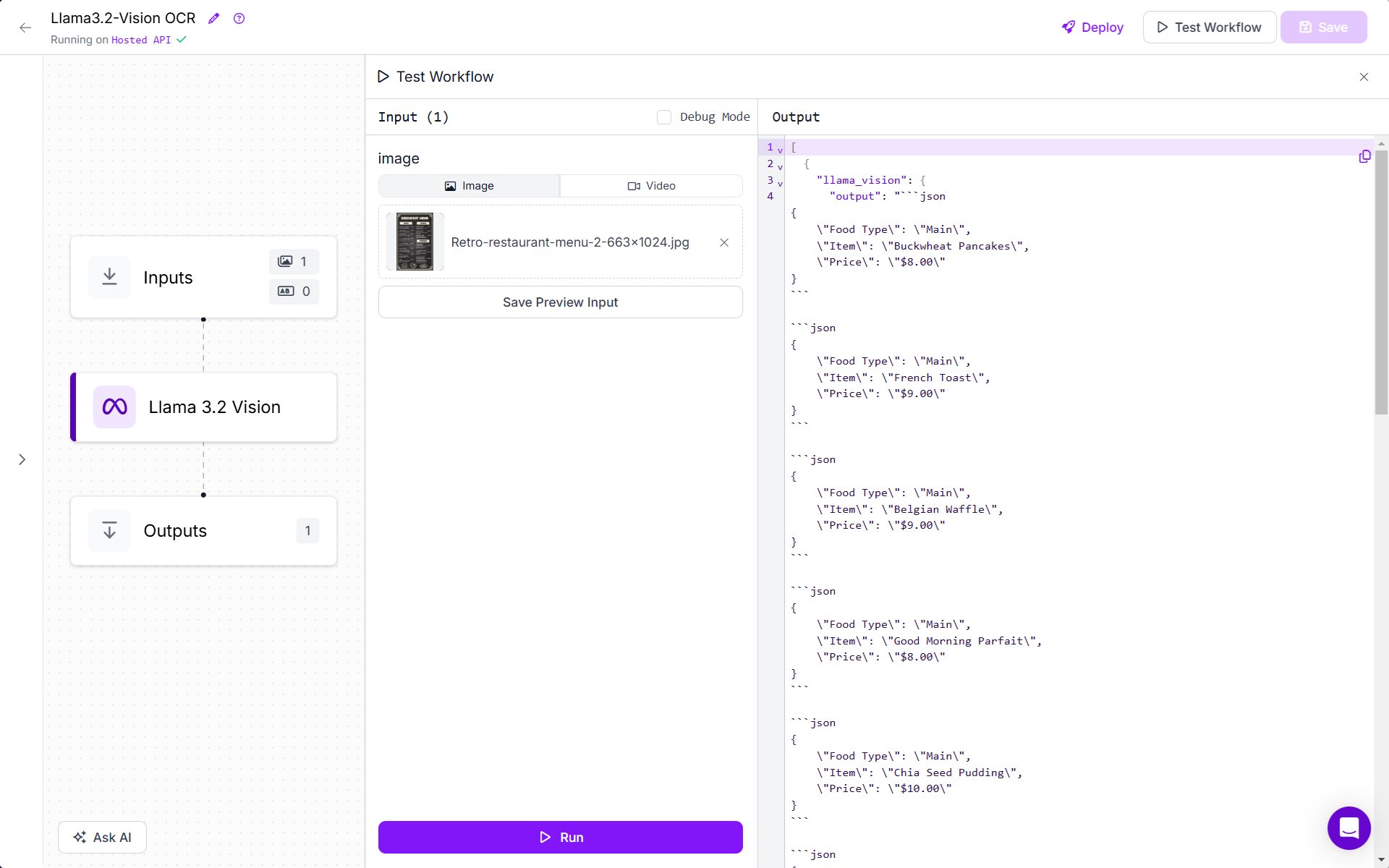
In the output you can see that all the data from image is returned in proper structured format. This data can be used for further processing.
More Llama 3.2 Prompting Modes
Llama 3.2 Prompting Modes
This block can be prompted for different types of tasks by setting the appropriate task type. For example, it can be used to:
- Automatically extract text from images.
- Generate natural language descriptions of what’s in an image.
- Answer questions based on the image’s content.
- Perform both single-label and multi-label image classification by comparing the image against a set of defined classes.
- Return results in structured JSON format, which makes it easy to feed data into subsequent workflow steps.
Let's talk through how to use various task types in Workflows.
The Llama 3.2 task type property of this block can be used to specify that type of task to be performed by the model. The selected task type determines required parameters and output response.
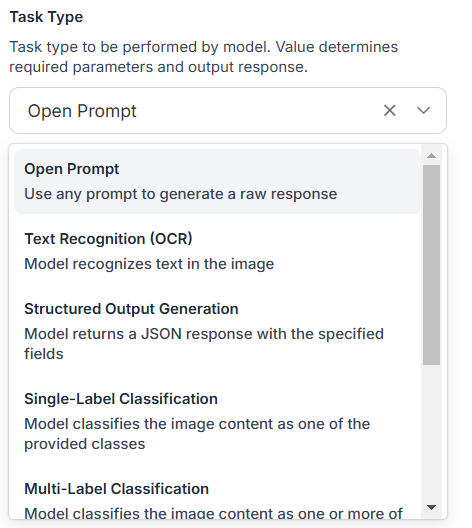
Text Recognition (OCR)
Selecting this task type enables the model to recognize and extract text from images. This task type is suitable for tasks like document processing or extracting information from scanned images.
Open Prompt (Unconstrained)
This task type allows user input any text prompt to generate a raw response from the model. This is useful for open-ended tasks where the output format is not predefined. Selecting this task type require specifying another property “prompt”.
Structured Output Generation
This task type allows model to generate JSON responses with specified fields. This task type is useful to generate structured data, such as extracting specific attributes from an image. Selecting this task type require configuring another parameter Output Structure.

Single-Label Classification
This task type allows model to classify an image into one of the provided classes. This task type is useful for tasks like object recognition or scene classification. Selecting this task type require configuring another parameter, Classes.
Multi-Label Classification
This task type is used for more complex classification tasks. It enables the model to classify an image into multiple classes, allowing for nuanced categorization of visual data. Selecting this task type also require configuring another parameter, Classes, similar to Single-Label classification.
Visual Question Answering (VQA)
This task type enables users to ask questions about the contents of an image and as a result the model will generate a text response based on its understanding of the visual data. Selecting this task type require configuring another parameter, Prompt, in which user can specify the question to be asked.
Captioning (Short)
This task type enables model to generate natural language descriptions of images. It makes the model “look” at an image and creates a short caption that summarizes what’s happening in the image.
Captioning
This task type works similar to Captioning (Short) task but generate longer and more detailed description for the images.
Conclusion
In this blog we have learnt how to use Llama 3.2 Vision block in Roboflow Workflow for OCR. The Llama 3.2 Vision block in Roboflow Workflows uses the Llama 3.2 Vision model and offer a robust, no-code solution for integrating advanced multimodal capabilities into your computer vision pipelines. It empowers users to perform tasks like OCR, image captioning, and classification, all through configurable task types. This block enables users to build OCR applications for the variety of tasks in no time.
Cite this Post
Use the following entry to cite this post in your research:
Timothy M. (Feb 14, 2025). How to use Llama 3.2 Vision for OCR. Roboflow Blog: https://blog.roboflow.com/how-to-use-llama-3-2-vision-for-ocr/