
In a given year, approximately 65,000 workers wearing hard hats incur head injuries in the workplace, of which over one thousand ultimately die. Workplace safety regulations exist to protect and promote wellbeing in the workplace, yet ensuring awareness and compliance can be a challenge. Even in cases of accidental negligence, an employee may find him or herself in a position where they were unaware that hard hats were required to be in a specific zone.
Computer vision more broadly has found a natural fit in helping capital intensive industries as monitoring equipment and conducting regular inspections can be quite costly. Extending these capabilities to look after individuals as much as equipment is a reasonable step to consider.
Download the Hard Hat Object Detection Dataset Here
Introducing the Hard Hat Dataset
Originally collected and open sourced by researchers at Northeastern University in China (Xie, Liangbin, 2019), the hard hat dataset contains 7,035 images of workers in a wide array of situations that require protective hard hats to complete their day-to-day work. The dataset includes 27,039 annotations (approximately 3.8 per image) across three classes: those in a helmet (19,747), head (6,677), and person (615). The researchers released the dataset such that 5,269 of the images and their labels are in the training set, and the remaining 1,766 are in a validation set.




Various examples available in the hard hat dataset.
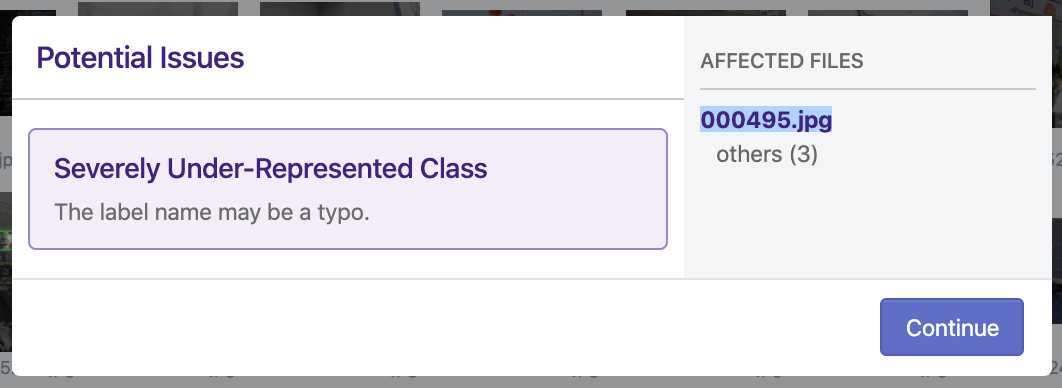
Notably, the Roboflow team did identify potential errors that were corrected before re-release. In image 000495.jpg, there is a single occurrence of an annotation called “others” and three individuals (that appear to be learning over) are labeled as such. The Roboflow team removed this annotation (but not the image as other labels were present) in our release of the dataset, as it appears to be a mistake resulting in a dramatically underrepresented class, decreasing training quality of the overall data.

In addition to practical applications where this dataset may be intriguing, the dataset provides prime territory to assess and compare model performance. The images are of various shapes and sizes, there is significant class imbalance, and many of the annotations are particularly small (heads in broader scenery). These characteristics may make for worthwhile test of various model strengths and weaknesses, e.g. how poorly YOLOv3 performs on small bounding boxes.
You can see the Advanced Dataset Health Check that led us to find all of these problems here.
We’re excited to make this research more open. Check out the full dataset on Roboflow Public Datasets.
Cite this Post
Use the following entry to cite this post in your research:
Joseph Nelson. (Apr 10, 2020). Introducing an Improved Hard Hat Dataset for Computer Vision in Workplace Safety. Roboflow Blog: https://blog.roboflow.com/introducing-an-improved-hard-hat-dataset-for-computer-vision-in-workplace-safety/