
Recognizing handwritten or typeset math equations is harder than general OCR because fractions, roots, exponents, and specialized symbols break standard text-recognition pipelines. This post walks through a two-step computer vision approach: object detection to isolate math-specific structures, followed by image classification to identify individual characters. Using Roboflow's tools for dataset management, annotation, and training, the team built a 100,000-image synthetic dataset from just two base images per equation, ultimately achieving 99.4% mAP, 98.1% precision, and 98.5% recall after an active learning cycle.
Math optical character recognition, or math OCR, is a specialized area of OCR, but highly beneficial in academic fields where input or transcription of math equations is tedious and time consuming. Math OCR solutions do exist, but many are stroke detection based, inaccessible or paid closed-source. With Roboflow, mathematical equation recognition can be done by anyone..
In this guide, we will cover how to build mathematical equation recognition capabilities with Roboflow.
The Problem
Although math OCR solutions do exist, unlike traditional text recognition, they’re far from plentiful, accessible and open source. Math OCR in particular can be a difficult problem to approach.
Consider an equation like the following:
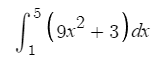
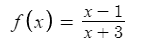
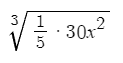
Structures like fractions, roots and exponents confuse most existing OCR solutions and math equations contain many unique characters, formattings and syntax that can be difficult to learn itself and even more difficult to recognize.
Why Computer Vision
Many existing traditional OCR solutions already use forms of computer vision. Traditional OCR solutions are not all made the same, but most follow a similar process.
Object detection is used to isolate blocks of text, then individual lines of text within blocks, then words within lines of text, then letters within words.

Then, image classification is used to identify each letter. The letters, words, lines and blocks of text are reassembled into human readable text.
How to Use Computer Vision for Math OCR
For recognizing math equations, we can use similar concepts to break down math equations into separate parts. Instead of blocks, lines and words of text, we can use object detection to recognize math-specific syntax and structures like fractions, roots and superscripts.
Just like many design processes, this one was full of trial and error.
Our initial attempt to design a math recognition system labeled all the characters, structures, etc as separate classes.
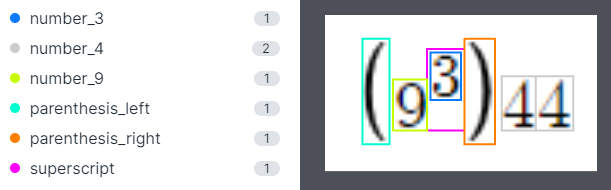
This approach resulted in a severe imbalance of classes. The nature of math syntax meant classes such as zeros, “x”, “y” and other common characters would outnumber classes such as fractions or less common classes, in the most extreme instance: 60,000 to 1. Although it is naturally occurring, when training machine learning models, having an imbalance will make it difficult for the model to find the less occurring class, since it has less examples to learn from.
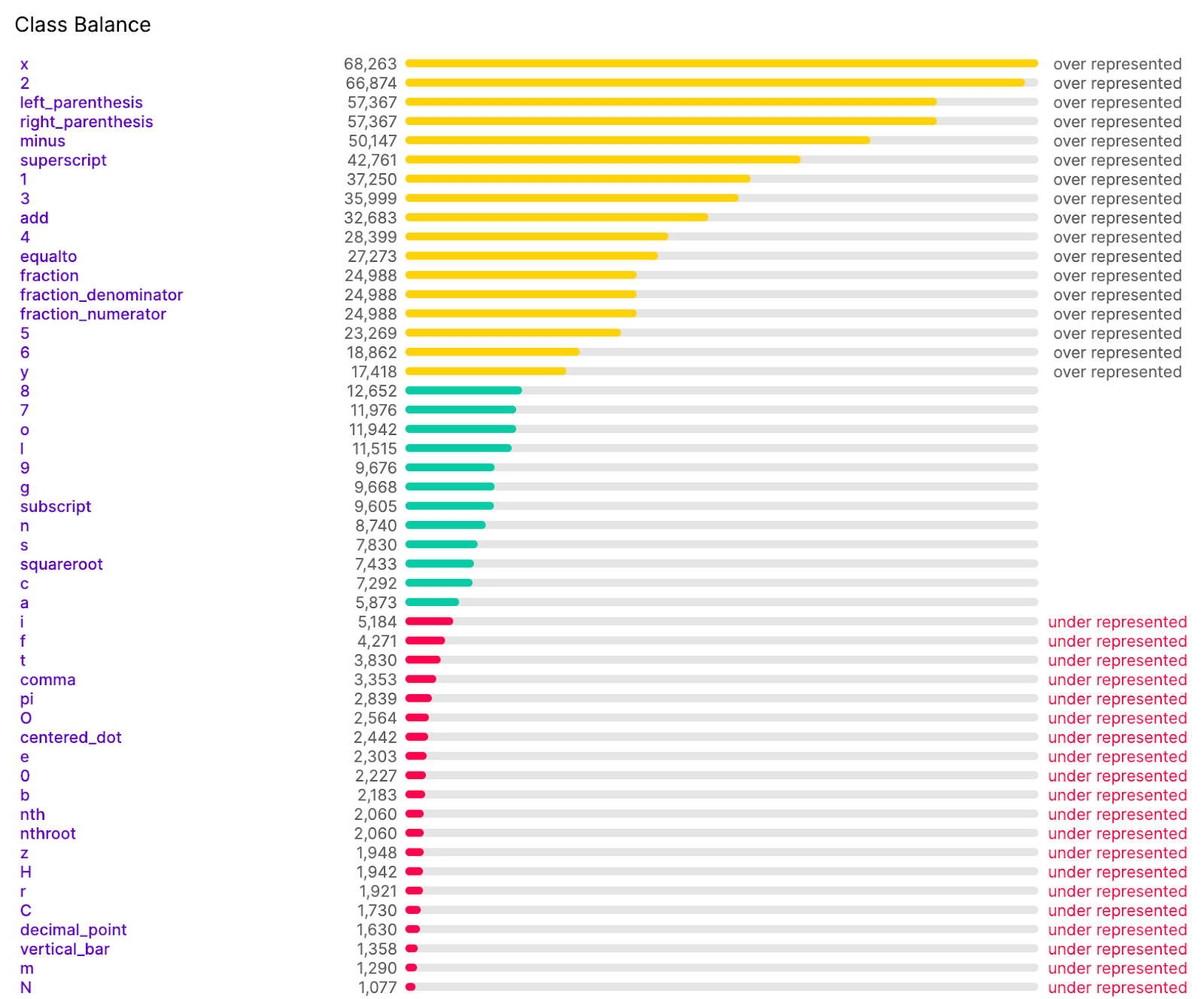
Looking at Roboflow’s Health Check, it was clear that the lowest occuring classes were the characters. In order to make a more balanced dataset, taking inspiration from traditional OCR design, we devised a two step design for recognition.
Isolation Step
In this step, an object detection model would isolate and identify all characters collectively under one class named `character` and separate, uniquely identifiable structures with their respective names.

To accomplish this, since all the data was already created, we organized all the characters under one class by using the remap pre-processing step on Roboflow. This resulted in remapping 103 classes to one.
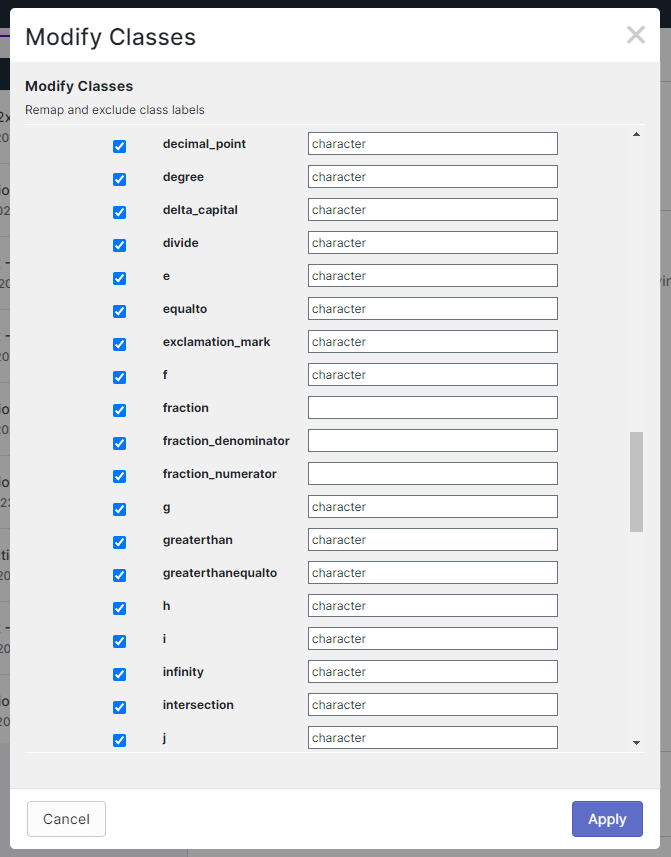
Remapped 103 character classes into one using the Modify Classes preprocessing tool
Classification Step
In this step, an image classification model would identify each character and return the relevant symbol, akin to traditional OCR.
Creating the Dataset
A high quality, large dataset is helpful for any project, but especially important and extremely difficult for this project.
The first attempt for a dataset entailed taking screenshots from a math textbook and using Roboflow Annotate to manually label pictures. Despite best efforts, this resulted in labeling 50 images across the span of a week, which yielded disappointing results of a 27.6% mAP.
Synthetic Data and Annotation Generation
Based on learnings from the first attempt, the second approach was much more successful. It centered around the goal to produce as much data as possible, as accurately as possible, as quickly as possible.
Generating the Equations
The initial attempt revealed some biases and inefficiencies in generating not only the images and annotations, but also the underlying equations themselves. Taking screenshots from a math textbook didn't produce enough quantity, quality nor variety of equations that would be helpful for training a math OCR model.
To get a larger quantity and wider variety of equations, we looked to Mathway, an online math problem solver frequented by students. Their website features a “Popular Problems” section with thousands of equations that are submitted by students across the world to be solved by Mathway.
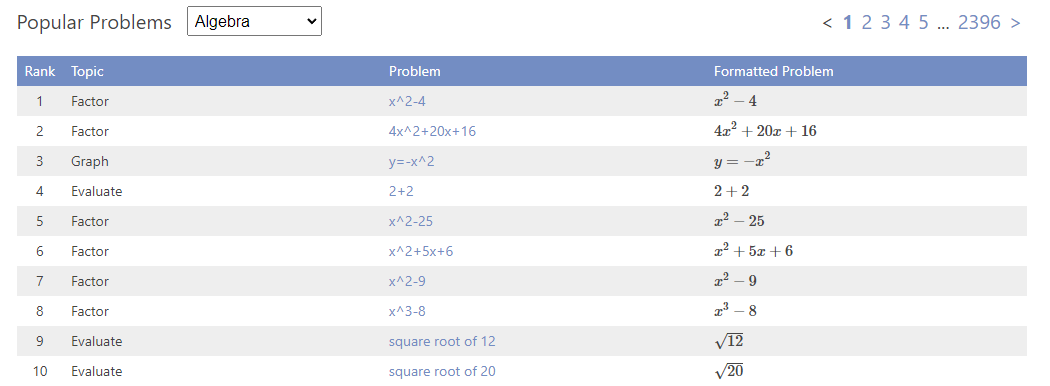
Creating the images
Another problem that needed to be solved was the generation of the images. Up to this point, the data was screenshots of textbooks or manually typing out equations in rendering websites. But, for thousands of equations, a streamlined process had to be designed. The new workflow used elements of a math equation rendering engine for the web, used to display math equations on a whole host of math/education related websites, called MathQuill.
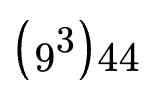
Creating the annotations
Not only did MathQuill, using html2canvas, a JavaScript package that creates images of HTML elements, create high quality training images, it also allowed the process of automatically generating annotations. This was possible due to MathQuill’s HTML format making it somewhat easy to see all the characters and structures used in a math equation.
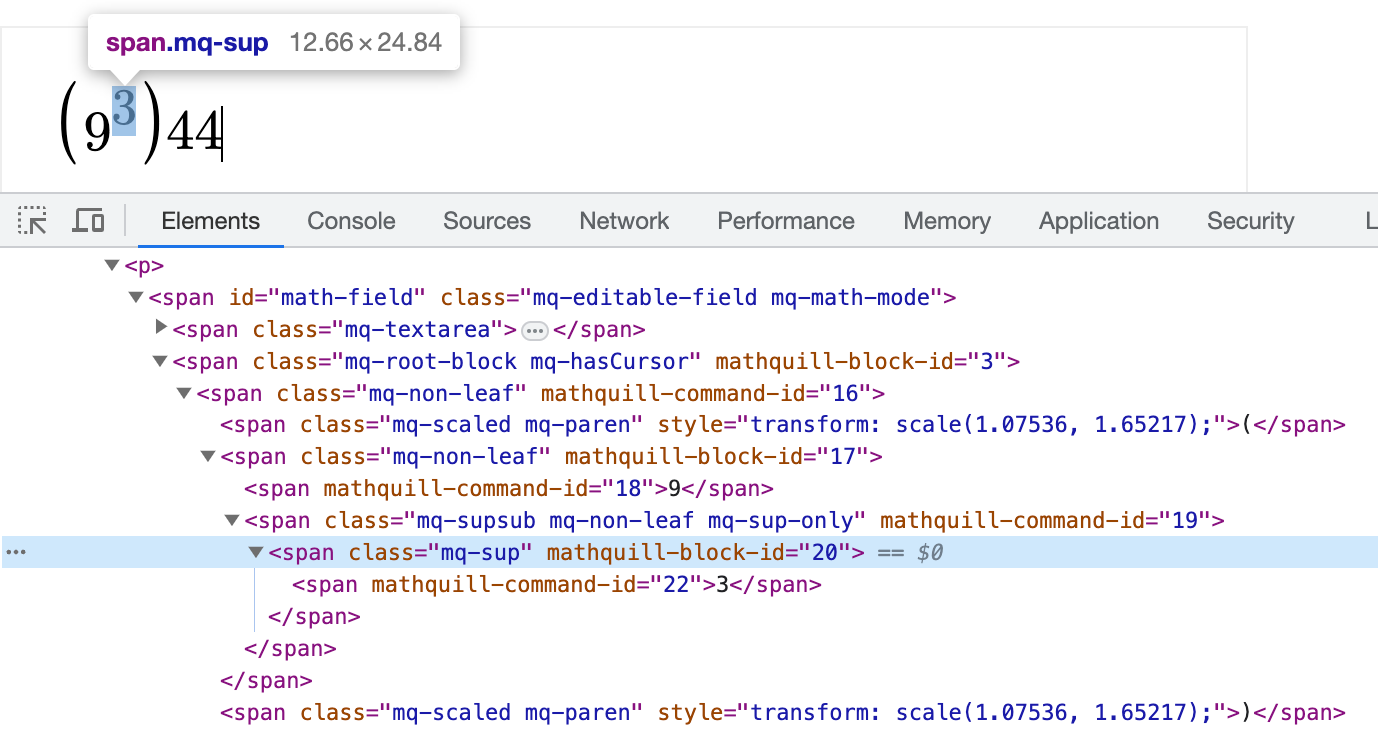
Using JavaScript, it also became possible to get the exact location of each element in the equation. This was attempted first using the `getBoundingClientRect()` function, but due to bounding box discrepancies, shifted to making every other element invisible and mapping out contrast to get bounding box locations.

The process of my code finding the bounding box of each character/structure by changing the other elements’ visibility
Once the bounding box location was known, it then became possible to construct a COCO JSON annotation file that to then upload through Roboflow’s annotation upload API.
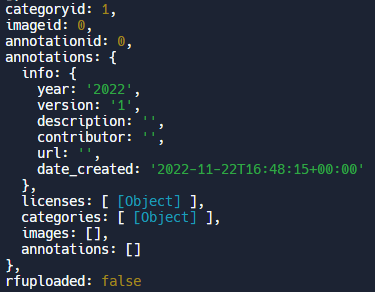
Adding annotations to the project via the upload API
Augmentations
In addition to augmentations made on the dataset generation side, which included usage of different fonts, font sizes and background images, augmentations such as crop, rotation, shear, hue, saturation, brightness, exposure, blur and noise were added.
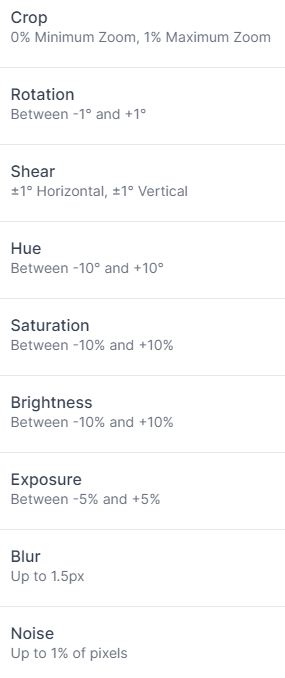
Active Learning
After an initial, lower performing model was trained, roboflow.js was used to create an active learning environment.
Using a known equation, the existing code generated an equation image. Once the equation image was generated, it was inferred on by the model, which would predict what the equation was. If the predicted equation was incorrect, it would submit the image and the annotations back to my project in order to help train the model further.
What resulted was a cyclical active learning process, where low-performing images would be automatically added to the project dataset for use in improving the model’s performance in future trained versions.
Result
The result was a 100,000 image dataset with most, if not all, perfect annotations using only two varied and augmented images for each unique equation.
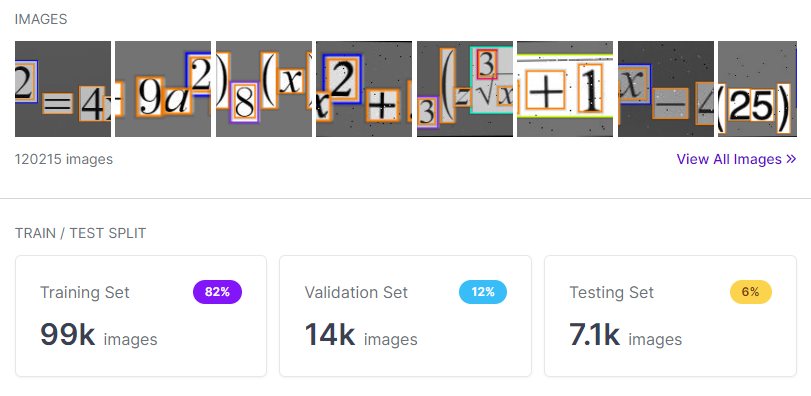
The training results also reflected the improvement, especially over the former 27.6%, with the new dataset reaching 99.4% mAP, 98.1% precision and 98.5% recall.
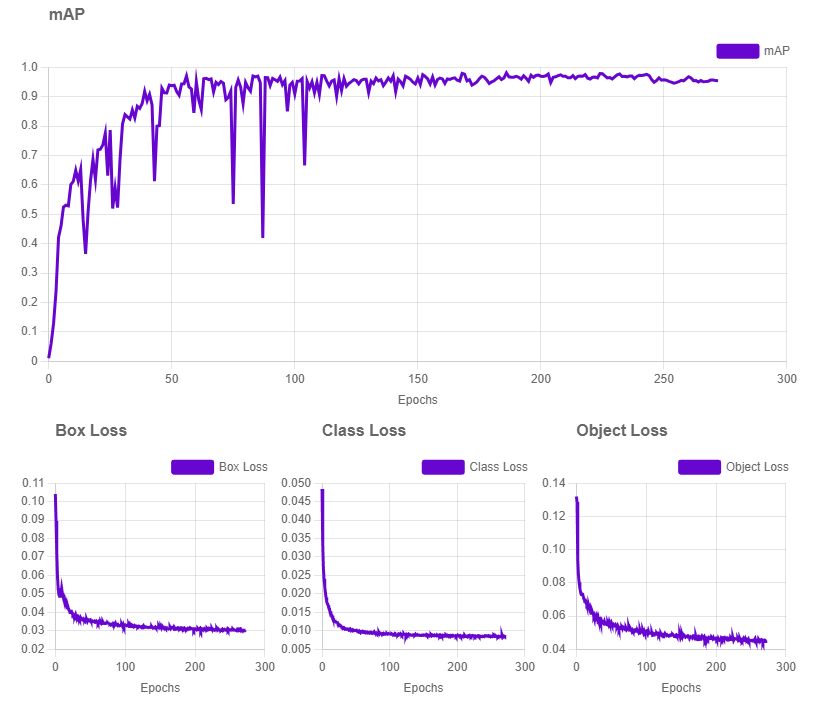
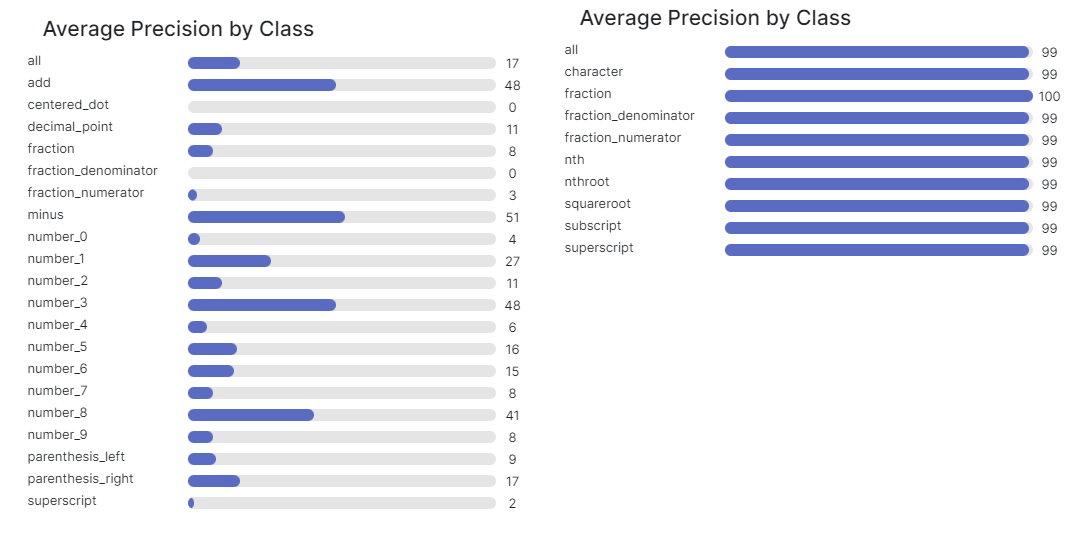
Conclusion
Throughout the process of creating math OCR capability, using Roboflow’s tools to create computer vision datasets and models allowed this project to occur, using most parts of Roboflow’s pipeline:
- Instantly uploading training images as they are made
- Managing massive amounts of data
- Having centralized access to annotations and images
- Monitoring dataset health through Health Check
- Training entire models with a single click
- Deploying models quickly using deployment methods such as roboflow.js
- Quickly iterating through failures with active learning
Using computer vision, navigating and digitizing the complex syntax of math equations becomes a much easier process.
Cite this Post
Use the following entry to cite this post in your research:
Leo Ueno. (Jun 30, 2023). Recognizing Math Equations with Computer Vision. Roboflow Blog: https://blog.roboflow.com/math-equations-computer-vision/