
If you’ve been working with object detection long enough, you’ve undoubtedly encountered the problem of double detection. This is when the same object is detected by the model multiple times.
This is commonly solved with Non-Max Suppression (NMS), which keeps the most confident bounding detection and discards the rest. But what if you want to merge the boxes instead?
This article will explain double detections and present Non-Max Merging (NMM). We will discuss:
- What causes double detections
- The Non-Max Merging algorithm
- Differences between NMS and NMM
We will then explain some example code that shows how to run NMS with computer vision model predictions.
Double Detection Problem
What causes double detections? Two cases are prominent offenders.
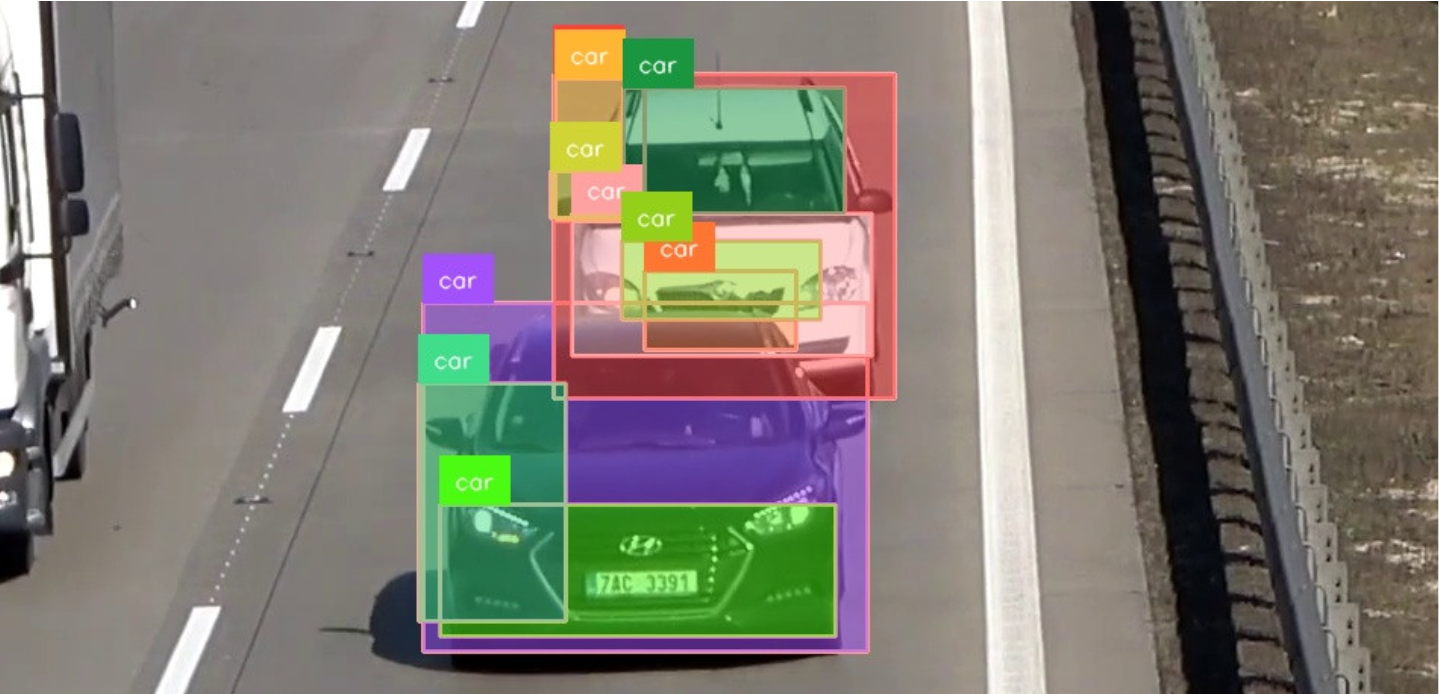
First, overlapping detections may be produced by the model itself.
- Models such as YOLO or Faster R-CNN use anchor boxes or region proposals to predict objects. Multiple anchor boxes might cover the same object with slight position, size, or aspect ratio variations, leading to multiple detections.
- The model might be overconfident about multiple regions of the same object, especially if it has been trained on a dataset with noisy annotations or if the object has distinct features that stand out at different locations or scales.
- If the model is uncertain about which class the object belongs to, it might produce multiple detections with different class labels. For example, it might detect a "car" and also a "vehicle" as separate entities, even though they refer to the same object.
By default, frameworks such as Ultralytics filter away most model predictions. Specifying a lower confidence threshold reveals more model predictions.

Secondly, the overlap might be created on purpose.
- InferenceSlicer (SAHI) divides an image into small slices, applies a model to each one, and then merges the results. To avoid objects being abruptly cut off at the slice edges, the slices are made to overlap slightly. However, this overlap can result in the same object or its parts being identified multiple times.
How would you detect people in this image?

You can use InferenceSlicer, which handles the task easily.

Notice that if you zoom in, you will see that underneath most detections, there is another double detection.
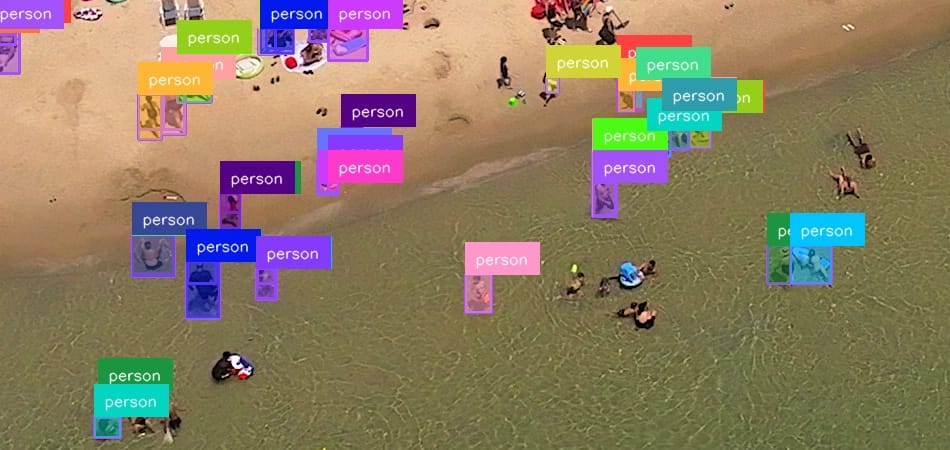
Overlap Filtering
Two similar algorithms are used to solve double detections:
- Non-Max Suppression (NMS), which checks for box overlap and only keeps the best detection
- Non-Max Merging (NMM), which checks for box overlap and merges the detections into one

Let's clarify the prerequisite concepts and then dig deeper into the algorithms.
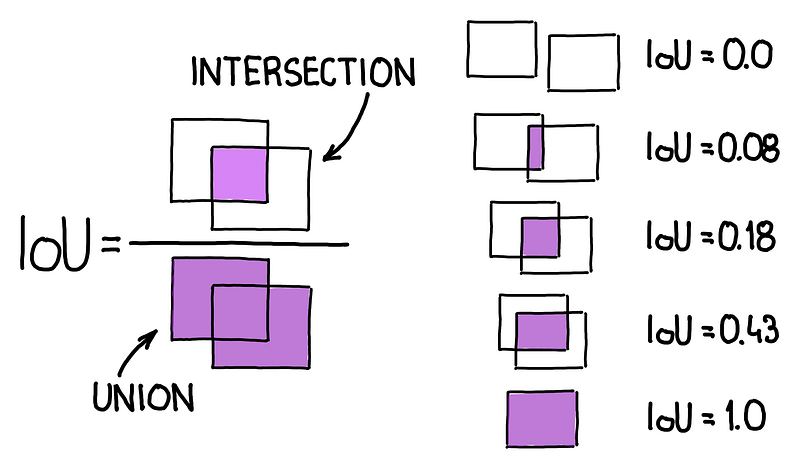
Intersection-Over-Union (IOU)
When we say 'overlap,' we typically mean a high Intersection-Over-Union value. It is computed by dividing the area where two boxes intersect by the merged area of the two boxes. IOU spans from 0 to 1. The higher the value, the greater the overlap!
Non-Max Suppression (NMS)
Suppose you run a model over an image, producing a list of detections. You wish to filter out cases when two detections are placed on the same object.
The most common approach is to use Non-Max Suppression.

- First, it sorts all detections by their confidence score, from highest to lowest.
- It then takes all pairs of detections and computes their IOU, checking how much the pair overlaps.
- For every pair where the overlap is higher than the user-specified
iou_threshold, discard the less confident one. - This is done until all classes and detection pairs are accounted for.
Non-Max Suppression can be performed either on a per-class basis (e.g., car, dog, plant) or in a class-agnostic manner, where overlaps are checked with boxes of any class.
For further reading, Piotr wrote an in-depth analysis of Non-Max Suppression with NumPy.
Non-Max Merging (NMM)
The steps of this algorithm are slightly more involved. Let's again start with the case when a model produces a list of detections, some of them detecting the object twice.

Here are the steps Non-Max Merge takes:
- First, it sorts all detections by their confidence score, from highest to lowest.
- It then takes all pairs of detections and computes their IOU, checking how much the pair overlaps.
- From most confident to least, it will build groups of overlapping detections.
- It starts by creating a new group with the most confident non-grouped detection D1.
- Then, each non-grouped detection that overlaps with D1 by at least
iou_threshold(specified by the user) is placed in the same group. - By repeating these two steps, we end up with mutually exclusive groups, such as [[D1, D2, D4], [D3], [D5, D6]].
- Then merging begins. This is done with detection pairs (D1, D2) and is implementation-specific. In supervision we:
- Make a new bounding box
xyxyto fit both D1 and D2. - Make a new
maskcontaining pixels where the masks of D1 or D2 were. - Create a new
confidencevalue, adding together theconfidenceof D1 and D2, normalized by theirxyxyareas.New Conf = (Conf 1 * Area 1 + Conf 2 * Area 2) / (Area 1 + Area 2) - Copy
class_id,tracker_id,anddatafrom the Detection with the higher confidence.
- Make a new bounding box
- The prior step is done on detection pairs. How do we merge the whole group?
- Create an empty list for results.
- If there's only one detection in a group, add it to the results list.
- Otherwise, pick the first two detections, compute the IOU again, and if it's above the user-specified
iou_threshold, pairwise merge it as outlined in the prior step.
The resulting merged detection stays in the group as the new first element, and the group is shortened by 1. Continue pairwise merging while there are at least two elements in a group.
Note that the IOU calculation makes the algorithm more costly but is required to prevent the merged detection from growing boundlessly.
In the end, you get a shorter list of detections, with all the original detections either kept or merged into the likely accurate results.
When to use each method
As you can see, the methods often produce similar results. Which should you pick for your use case? The quick answer is to opt for non-max suppression as the default but do a few tests for non-max merge for your use case.
Notice that in the following image, Non-Max Merge performed better:

Since the side of the truck was detected with very high confidence, non-max suppression discards other overlapping detections. If your tests show that a part of your object is detected with high confidence and you need to expand the detection area, or the detections underestimate the object size, you should first tinker with the nms_threshold parameter and then test Non-Max Merge.
Performance Considerations
In our implementation, we noticed that Non-Max Suppression (NMS) is about 2x faster than Non-Max Merge (NMM).
When run on 35 detections, the results were (in milliseconds):
- NMS: 1.25 ms
- NMM: 4.23 ms
When run on 750 detections:
- NMS: 41.15 ms
- NMM: 75.71 ms
Verdict
I advise starting with Non-Max Suppression, running a few experiments to see how it performs, and checking multiple values for nms_threshold. Then, try Non-Max Merging, but carefully evaluate the performance cost.
Non-Max Merge in supervision

Non-Max Suppression and Non-Max Merge are built into the most commonly used objects of Supervision. The library offers two ways of accessing NMS and NMM:
Inside Detections
The first is the convenience methods of with_nms and with_nmm in the Detections class. Here's some ready-to-use code you can apply to your images:
import cv2
import supervision as sv
from inference import get_model
image = cv2.imread(<SOURCE_IMAGE_PATH>)
model = get_model(model_id="yolov8m-640")
result = model.infer(image)[0]
detections = sv.Detections.from_inference(result)
detections = detections.with_nmm(
threshold=0.5
)You may also visualize the result:
annotated_frame = sv.BoundingBoxAnnotator().annotate(
scene=image.copy(),
detections=detections
)
sv.plot_image(annotated_frame)Inside InferenceSlicer
InferenceSlicer (SAHI) divides an image into small slices, applies a model to each one, and then merges the results. To avoid objects being abruptly cut off at the slice edges, the slices are made to overlap slightly. However, this overlap can result in the same object or its parts being identified multiple times.
Since InferenceSlicer may intentionally cause double detections, we also added a solution. By setting the overlap_filter_strategy parameter, together with iou_threshold, you may apply NMS and NMM to the resulting detections.
Here's how that looks:
import numpy as np
import cv2
import supervision as sv
from inference import get_model
image = cv2.imread("beach.jpg")
model = get_model("yolov8s-640")
def slicer_callback(slice: np.ndarray) -> sv.Detections:
result = model.infer(slice)[0]
detections = sv.Detections.from_inference(result)
return detections
slicer = sv.InferenceSlicer(
callback=slicer_callback,
slice_wh=(512, 512),
overlap_ratio_wh=(0.4, 0.4),
overlap_filter_strategy=sv.OverlapFilter.NON_MAX_MERGE
)
detections = slicer(image)
You can read more in How to Detect Small Objects with Inference Slicer.
Conclusion
Non-Max Suppression (NMS) and Non-Max Merging (NMM) address double detections in object detection. NMS is efficient, keeping the most confident detections, while NMM merges overlaps for a more consolidated result. Start with NMS for speed, adjust thresholds as needed, and use NMM for precise overlap handling. Both methods are available through our Open Source supervision library and are ready to be used whenever double detection issues arise.

Cite this Post
Use the following entry to cite this post in your research:
Linas Kondrackis. (Jun 25, 2024). What is Non-Max Merging?. Roboflow Blog: https://blog.roboflow.com/non-max-merging/