
On June 10th, 2025, OpenAI released o3-pro, a new multimodal reasoning model. o3-pro has a June 1st, 2024 knowledge cut-off date and a 200,000 token context window. The model offers the best reasoning of all models to date, and has support for both image and text inputs.
In this guide, we are going to talk about our findings from analyzing OpenAI’s o3-pro model on dozens of hand-crafted prompts related to real-world problems.
We ran our tests using Vision AI Checkup, a site that runs prompts on SOTA models including all of OpenAI’s latest models, the newest Gemini and Claude models, and more.
As of writing this blog post, o3-pro is joint third on the Vision AI Checkup leaderboard. The regular OpenAI O3 model is also third.
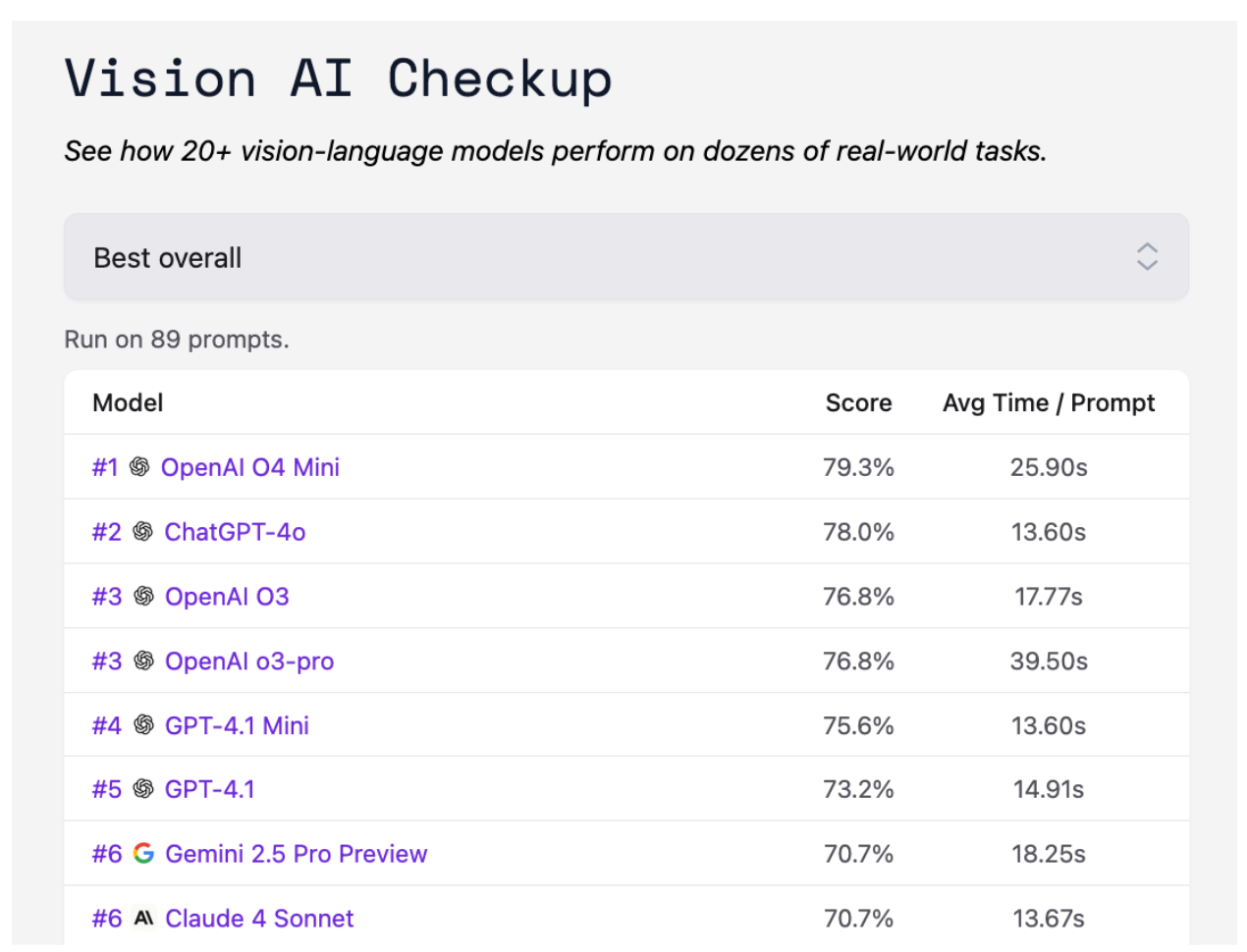
Without further ado, let’s talk about the highlights from our analysis.
Where OpenAI o3-pro Does Well
On our tests, OpenAI o3-pro did especially well on:
- OCR (i.e. read a serial number, read a barcode ID on a circuit board)
- Asking questions about how objects relate to each other (i.e. what is in the background of an image, whether a truck is in a designated bay)
- Visual question answering (i.e. are there missing boxes on a pallet, is a conveyor belt empty)
Let’s walk through a few example prompts from Vision AI Checkup in these categories.
OCR
We asked “What is the ID on the barcode? Return only the ID text.” with the following image as context:

The model returned “T074802630B2”. This is the correct answer.
Screenshot VQA
We asked “Prompt: What is the package quantity of 90183A308? Return only a number. If SKU does not exist, return NULL.” with the following screenshot:
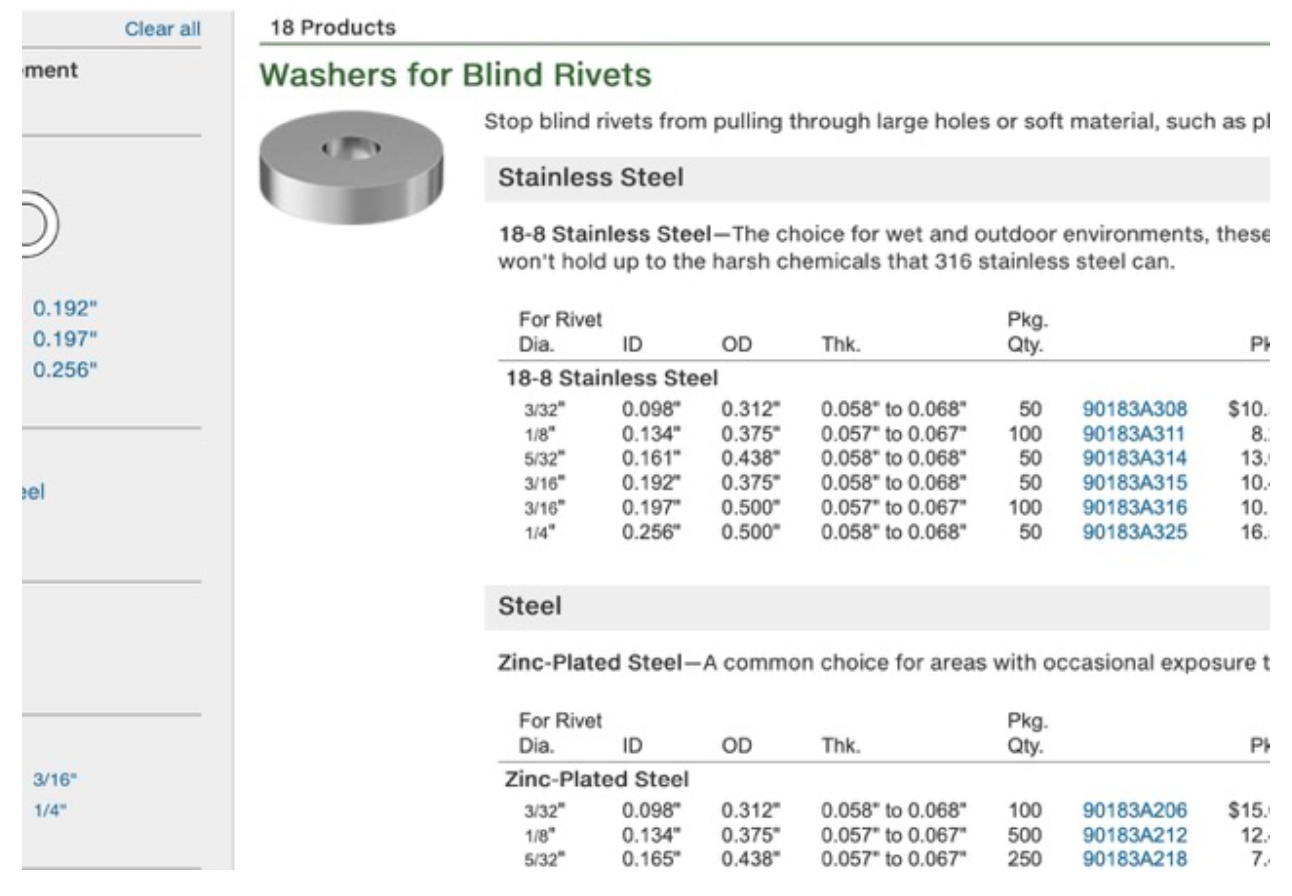
OpenAI o3-pro successfully returned the answer “50”.
Defect Identification
o3-pro passed 12/15 of our defect detection tests. For example, we asked “Is there a scratch on the metal? Return only yes or no.” with the following image as context:

The model said “Yes”, indicating it knows the image contains a defect.
We also ran a label quality test on an image of a juice box, asking “Does the juice box package show an orange eat well label? Return only yes or no.” with the following image:

The model said “yes”, indicating it successfully identified the “eat well” section of the label.
VQA (Missing Object)
We asked o3-pro “How many parts are missing? Return only a number.” with the following image:

The model correctly answered “1”.
Where OpenAI o3-pro Struggles
Like most models, o3-pro struggled with object counting, getting only four of 10 of our object counting related tests correct. This is an area in which there has not been much progress for a while: the best model for object counting, Claude 3.5 Haiku, only gets 6/10 of the counting tests correct.
Object Counting
For example, we uploaded the following image and asked “How many bottles are in the image? Answer only a number”. The model returned 26 but the correct answer is 27.

Object Measurement
o3-pro also struggles with object measurement. We provided the following image and asked “How wide is the sticker in inches? Return only a real number.”:

The model returned 2.7 even though the correct answer is 3.5.
Measuring the dimensions of an object placed next to a ruler is a challenge with which most models struggle. Only 5 of 31 models in the Vision AI Checkup pass this test.
How to Use o3-pro
o3-pro is available both in the OpenAI ChatGPT web interface, the online OpenAI playground, and via API. The API is implemented with the v1/responses API. If you are using the model with the OpenAI Python package, you will need to use the client.responses.create API.
To learn more about the o3-pro model and its features, refer to the OpenAI model card.
Conclusion
o3-pro is a new multimodal reasoning model developed by OpenAI. The model takes time to think about an answer to a question, like other models in the “o” reasoning series by OpenAI.
o3-pro scores joint third on the Vision AI Checkup leaderboard and thrives on a range of tasks, from OCR to VQA. The model struggles with object counting and measurement, and failed a few of our defect detection tests.
To learn more about how the model performs on our tests, refer to the OpenAI o3-pro Vision AI Checkup model page.
Cite this Post
Use the following entry to cite this post in your research:
James Gallagher. (Jun 11, 2025). OpenAI o3-pro: Multimodal and Vision Analysis. Roboflow Blog: https://blog.roboflow.com/openai-o3-pro-review/