
Overfitting happens when a model memorizes training data instead of learning general patterns, a problem visible when training accuracy is high but test accuracy drops sharply. Detecting it requires monitoring the gap between training and validation performance across epochs, and preventing it draws on techniques including data augmentation, regularization, cross-validation, early stopping, and ensembling. The post also notes a practical exception: deliberately overfitting a small, controlled dataset is a useful first check to confirm a task is learnable before investing in a full training pipeline.
Overfitting is when a model fits exactly against its training data. The quality of a model worsens when the machine learning model you trained overfits to training data rather than understanding new and unseen data.
There are several reasons why overfitting can occur and responding to these causes by applying various state-of-the-art techniques can help.
Today's article will highlight overfitting, common reasons for overfitting, detecting overfitting in machine learning models, and some best practices to prevent overfitting in machine learning model training.
In this article, we are going to discuss:
- What is overfitting?
- How overfitting occurs
- How to detect overfitting
- How to prevent overfitting
Let's begin!
What is Overfitting?
Overfitting is a problem where a machine learning model fits precisely against its training data. Overfitting occurs when the statistical model tries to cover all the data points or more than the required data points present in the seen data. When ovefitting occurs, a model performs very poorly against the unseen data.
When a model has been overfit, the model starts learning too much noise and inaccurate values present in the training data and fails to predict future observations reducing the precision and accuracy of the model.
Consider this scenario. You have 100 images, where 50 are cats, and 50 are dogs. When you train an image classifier model, the model shows a 99% accuracy on the training dataset but only 45% accuracy on the test set which indicates that your model has overfitted.
It means that when you give a picture of a dog from the training set sample, the model accurately predicts its class, whereas when given a random image of a dog from the internet, the model fails to give the correct output.
Our machine learning classifier model is overfit. The classifier has learned how to identify certain features of cats and dogs, but the model has not learned enough general features to be performant on unseen images. This model is thus not ready for any real-world use, as results would be unreliable.
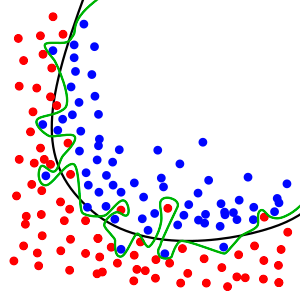
How does overfitting happen?
There are several reasons you could see overfitting in your machine-learning models. Lets discuss some of the most common causes of overfitting:
- If a model has a high variance and low bias, your training accuracy increases, but validation accuracy decreases with the number of epochs.
- If the dataset has noisy data or inaccurate points (garbage values), it may decrease the validation accuracy and increase the variance.
- If the model is too complex, the variance will rise, and the bias will be low. It can learn too much noise or random fluctuations using the training data, which hinders the performance of data the model has never seen before.
- If the size of the training dataset is inadequate, then the model will get to explore only some of the scenarios or possibilities. When introduced to unseen data, the accuracy of the prediction will be less.
Detect overfitting in machine learning models
Detecting overfitting is a complex task before you test the data. The best thing you can do is to start testing your data as soon as you can to figure out whether the model is able to perform well on the datasets with which it will work.
The key question to ask is: does my model perform well on unseen data? If your model performs poorly on unseen data, and those data are representative of the sort of data you will feed your model, overfitting may have occured.
However, some things indicate that your model will learn too much from the training dataset and overfit. These are:
When splitting your dataset into train, validation, and test, you should make sure your datasets are in a random order. This is key. If your datasets are ordered by a particular attribute (i.e. house size in square meters), your training dataset might not learn about the extreme cases (massive house sizes) as those will only appear in validation and test sets.
In addition, the learning curve can give you more information than you might think. Learning curves are plots of model learning performance over time where the y-axis is some metric of learning (classification accuracy or classification loss), and the x-axis is experience (time). If the training error decreases as the number of iterations increases, the validation error does not change or increase. It indicates that the model is overfitting, and you can stop the training.
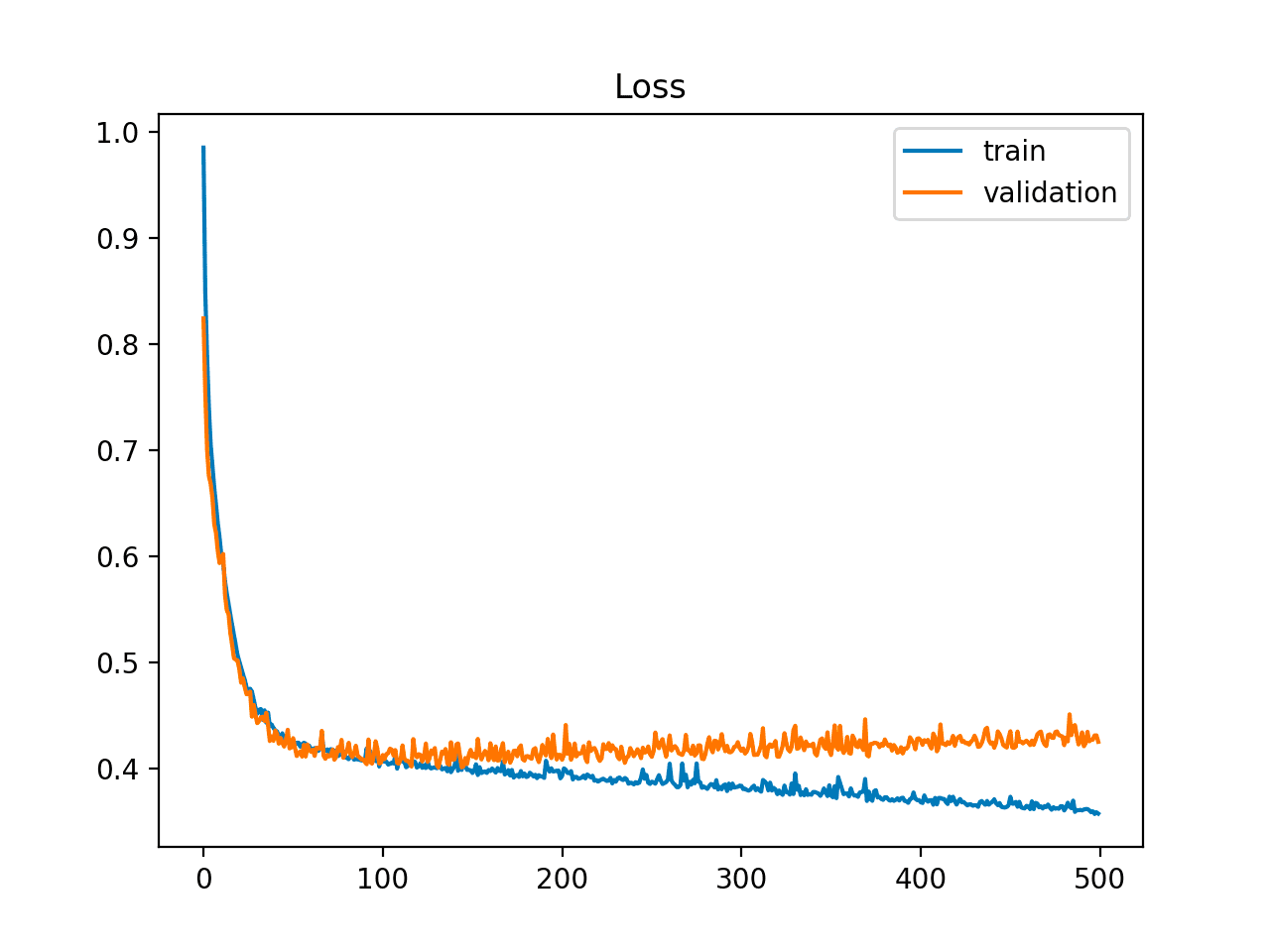
How to Prevent Overfitting
Machine learning models are prone to overfitting because of the complexity of the number of parameters involved. It is essential to understand the methods used to prevent overfitting.
Add More Training Data
Adding more training data is the simplest way to address variance if you can access more data and compute resources to process that data. More data helps your machine learning model understand more general features instead of features specific to images in the dataset. The more general features a model can identify, the less likely your model will only perform well on seen images.
Use Data Augmentation
If you do not have access to more data, consider augmenting your data. With data augmentation, you can apply various transformations to the existing dataset to increase the dataset size artificially. Augmentation is a common technique to increase the sample size of data for a model, particularly in computer vision.

Standardization
Standardize features so each feature has a 0 mean and unit variance. This change for speeding up the learning algorithm. Without normalized inputs, weights can vary dramatically, causing overfitting and high variance.
Feature Selection
A common mistake made is to include most or all of the features one has irrespective of how many points are available for each feature. This presents an issue because low sample sizes on features makes it difficult for a model to understand how a feature applies more generally to the data in a dataset.
Ask yourself: does your dataset have lots of features but few data points for each feature? If this is the case, consider selecting only the essential features required for training.
Cross-Validation
Using cross-validation, you use all the data for training by splitting the dataset into k-groups and letting each group be the testing set. Repeat the process k times for each group as a testing set.

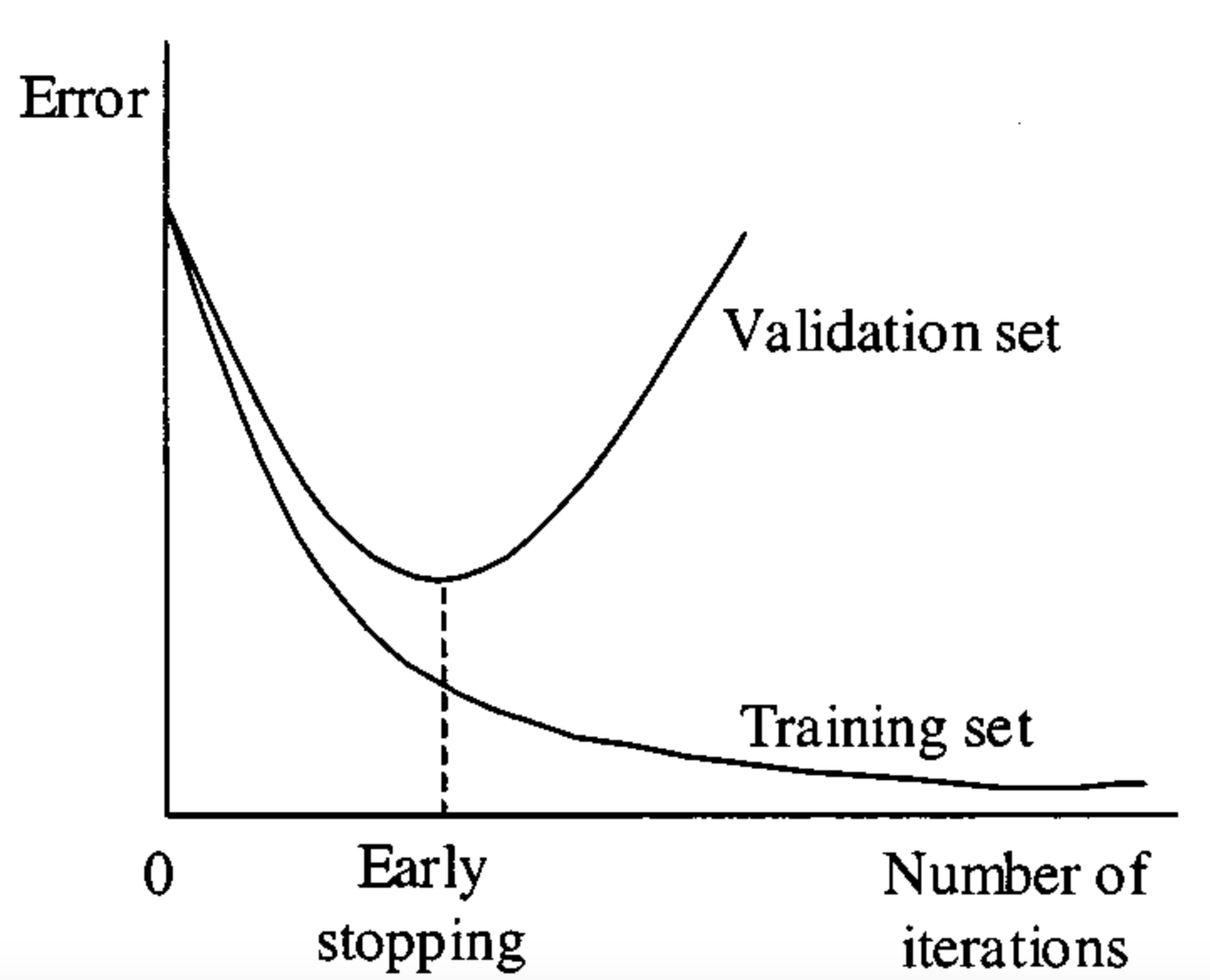
Early Stopping
The point at which you should stop the training process is when your validation loss starts to rise. We can implement this by monitoring learning curves or setting an early stopping trigger.
You should experiment with different stop times to figure out what works best for you. The ideal situation is to stop training just before you expect the model to start learning noise in the dataset. You can do this by training multiple times and figuring out roughly at what point noise starts to impact your training. Your training graphs will help inform the optimal time to stop training.
Remember: if you stop training too early, your model may not be as performant as it would be if left to train for a little bit longer.
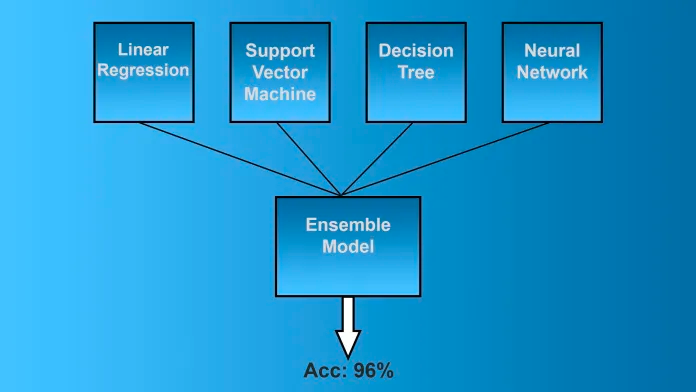
Ensembling
We combine multiple strategically generated models, such as classifiers or experts, in this technique to obtain better predictive performance. It reduces variance, minimizes modeling method bias, and decreases the chances of overfitting.
Regularization
This is a trendy technique in machine learning that aims to decrease the complexity of the model by significantly reducing the variance while only slightly increasing the bias. The most widely used regularization methods are L1(Lasso), L2(Ridge), Elastic Net, Dropout, Batch Normalization, etc.

Can Overfitting in Machine Learning Be A Good Outcome?
While overfitting of machine learning models is typically taboo, it is commonplace today when attempting to de-risk computer vision models to later be deployed in business applications. Before investing time and effort into a computer vision project, your organization may be at a point where they’d rather see if the task is even “learnable” by a model.
This can be accomplished by creating a model that is overfit. After collecting images in which you are focused on identifying a subset of the objects that appear, you are bound to end up loading your model with training and validation images that lack variety in structure. This will result in your model overfitting to that environment, as it is optimized for detection of the labeled objects you identified in the training images.
A project that is fully de-risked as a learnable task means we have a viable computer vision project for implementation in our business. Whether that use case be for worker safety, defect detection, document parsing, object tracking, broadcasting experiences, gaming, augmented reality apps, you name it … sometimes overfitting is the proof we need to confirm vision is a realistic solution to a problem.
Conclusion
Overfitting is an everlasting problem in the field of machine learning. Understanding the common reasons and how to detect overfitting is difficult. The standard practices discussed in today's article will help you understand how to address overfitting in model training.
here
Cite this Post
Use the following entry to cite this post in your research:
Mrinal W.. (Oct 31, 2022). Overfitting in Machine Learning and Computer Vision. Roboflow Blog: https://blog.roboflow.com/overfitting-machine-learning-computer-vision/