
This project aims to develop a document table and figure understanding system with computer vision. This project could be used in commercial settings to automatically retrieve information from and process documents.
We will use Table and Figure Identification API built with Roboflow to detect and extract tables and figures from a captured image of a document page.
Once these elements are identified, they are processed and analyzed using a Vision-Language Model (VLM) to generate detailed explanations about it.
In this project we will also use Roboflow Workflows, a low-code, web-based computer vision application builder for building our application. We will then use the Gradio framework to design the user interface for our application.
The following figure shows how the project works:
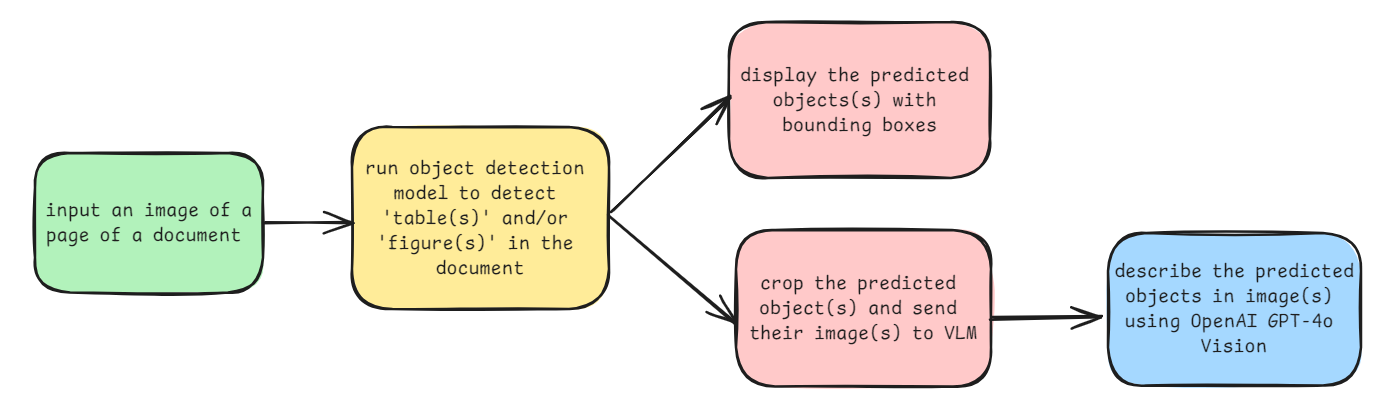
Sending only the region of tables and figures to a VLM like GPT-4o allows the multimodal model to focus on the information in the table, rather than the text.
Here is an example of the system in use, returing a detailed explanation of the two charts identified in the document:

Let’s talk through the steps to build this project.
Steps to build the project
Following are the steps building the project:
- Collect dataset and train computer vision model
- Create a workflow for the project
- Build the Gradio application
Step #1: Collect dataset and train computer vision model
For this project, we will use the TF-ID Computer Vision dataset from the huyifei workspace on Roboflow Universe. This dataset includes over 4,000 images of document pages. You can download the dataset and upload it to your own workspace.
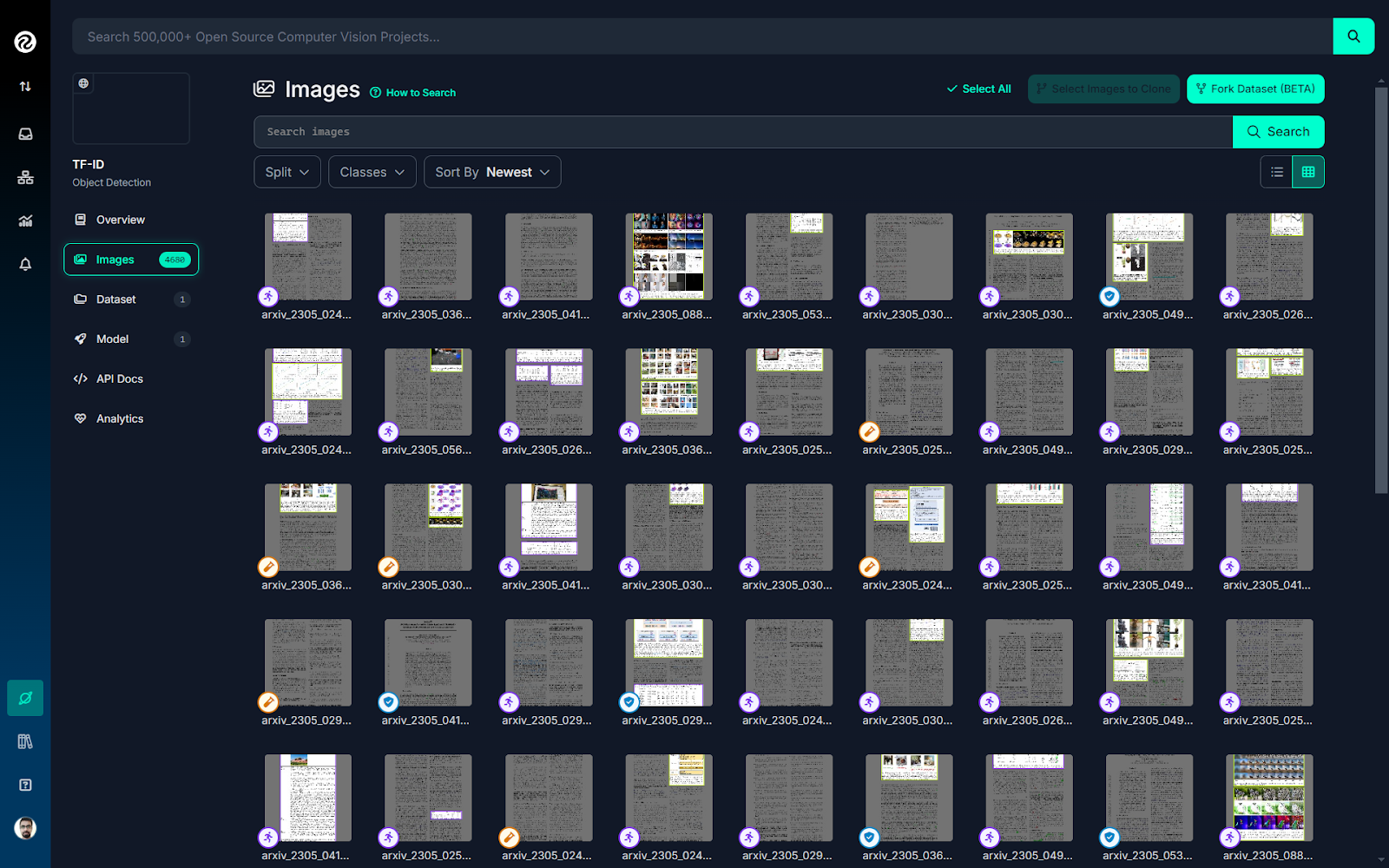
The dataset contains images labeled with two classes, 'figure' and 'table,' to identify all tables and figures in the document, as shown in the figure below.
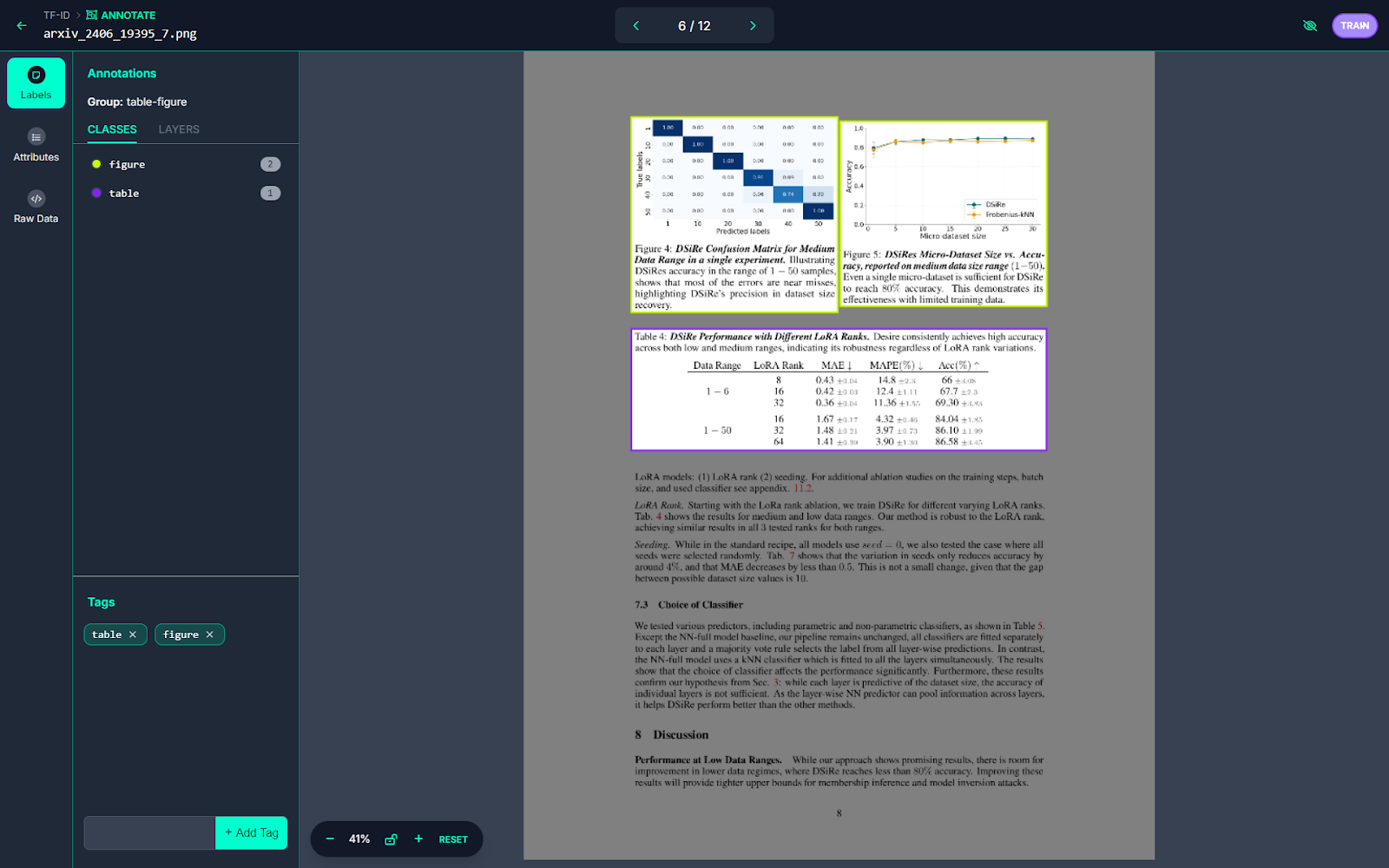
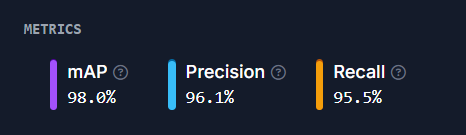
The model for this dataset is trained in Roboflow using the Roboflow 3.0 Object Detection (Fast) model type with the COCOn checkpoint. The following figure displays the model's metrics.
Now that we have a model ready, we can build the Roboflow workspace application.
Step #2: Create a Workflow for the project
Next, we will create a Workflow in Roboflow to build an application that identifies tables and figures in a document and then provides descriptions of them. Roboflow Workflows is a powerful open-source tool for building computer vision applications in no time. You can learn more about workflows on how to get started and explore the other blogs. For our project in this blog post, we will create the following workflow.
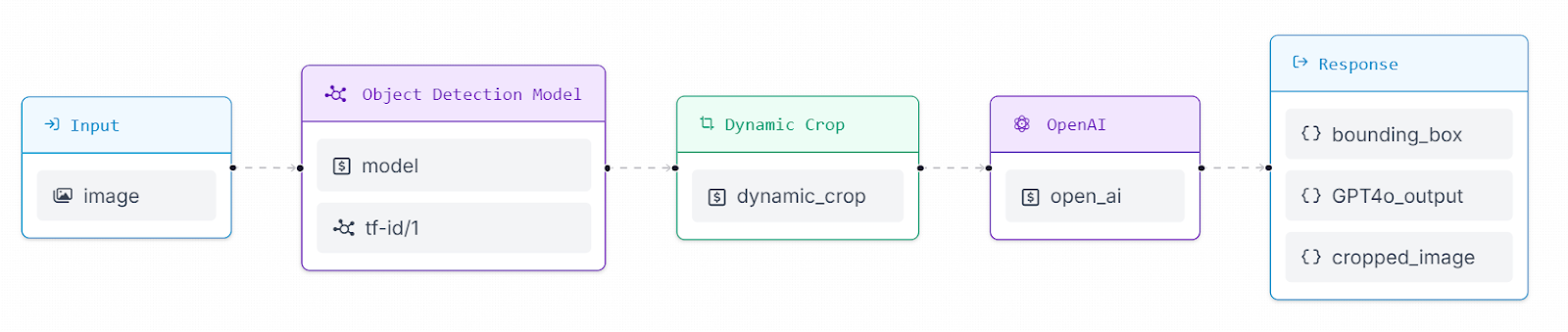
Our workflow contains following blocks:
- Input
- Object Detection Model
- Dynamic Crop
- OpenAI
- Responses
We will understand each of these blocks one by one.
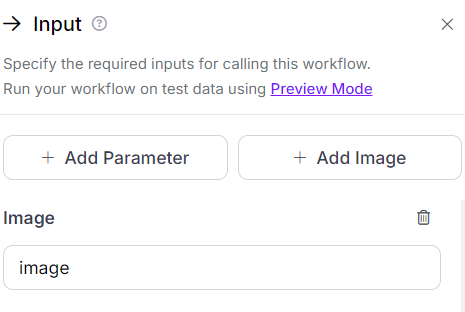
Input Block
This block allows us to specify the necessary input for our workflow. In this workflow, it enables us to input an image.
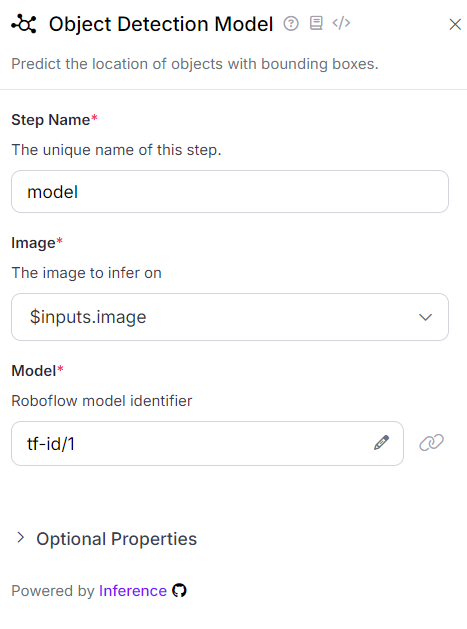
Object Detection Model Block
This block enables the use of a pretrained object detection model to predict the locations of objects with bounding boxes. In this workflow, it is configured with our custom-trained Table and Figure Identification model for document understanding from step #1. The following figure shows the configuration required for this block in our application.
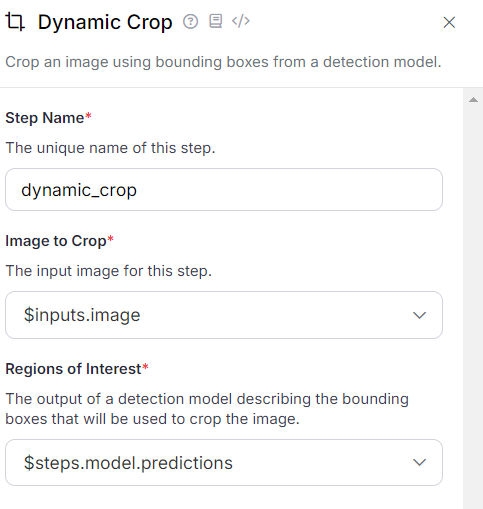
Dynamic Crop Block
This block crops the region of interest based on the bounding box coordinates returned by the object detection model. The following configurations should be applied within this block for this workflow application.
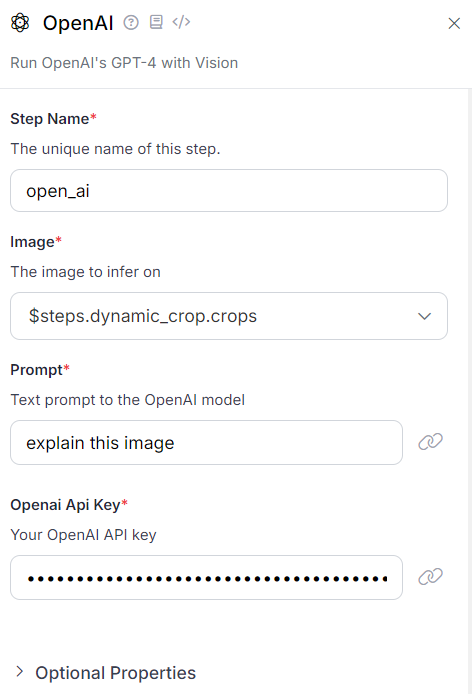
OpenAI Block
This block runs OpenAI's GPT-4 with Vision. In this workflow application, it takes the cropped image as input from the previous dynamic crop block and runs a specified prompt to generate a description of the image. The following figure shows the necessary configurations for this block. Be sure to use your OpenAI API Secret Key when setting up this block.
Response Block
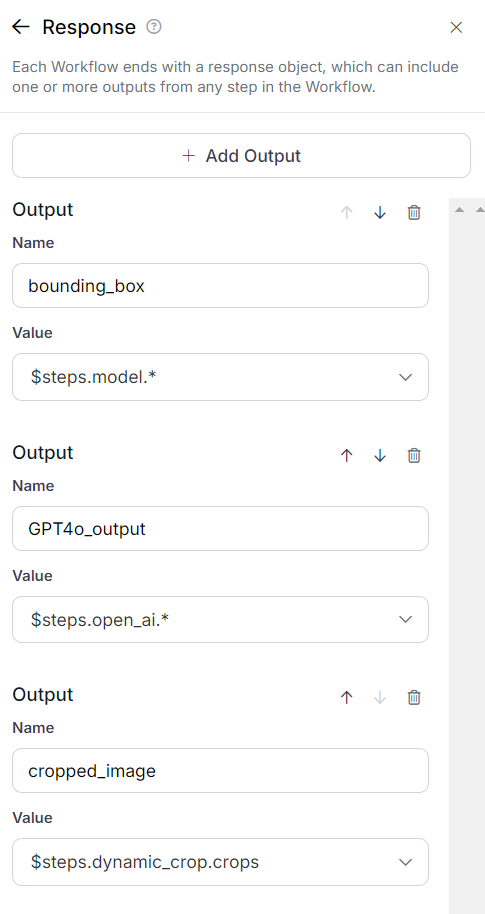
This is the final block of our Workflow application, which can include one or more outputs from any step in the Workflow. It is used to display the output of the Workflow application.
In this Workflow, three outputs are displayed: the bounding box details, cropped images, and the response from GPT-4 Vision. The following configurations are applied in this block.
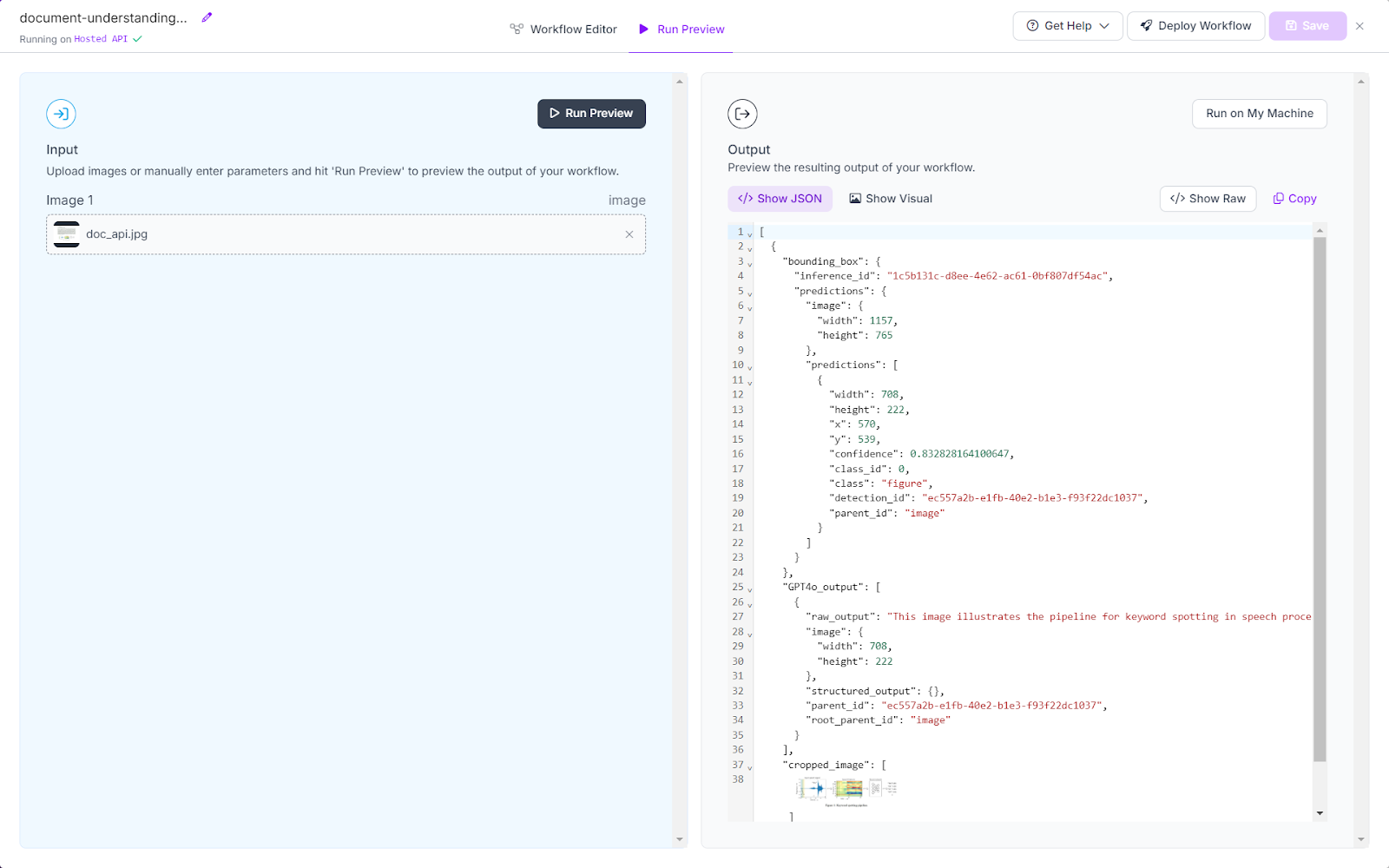
Running the workflow will generate the following output, including the bounding box description, cropped image, and GPT-4 response.
Step #3: Build the Gradio application
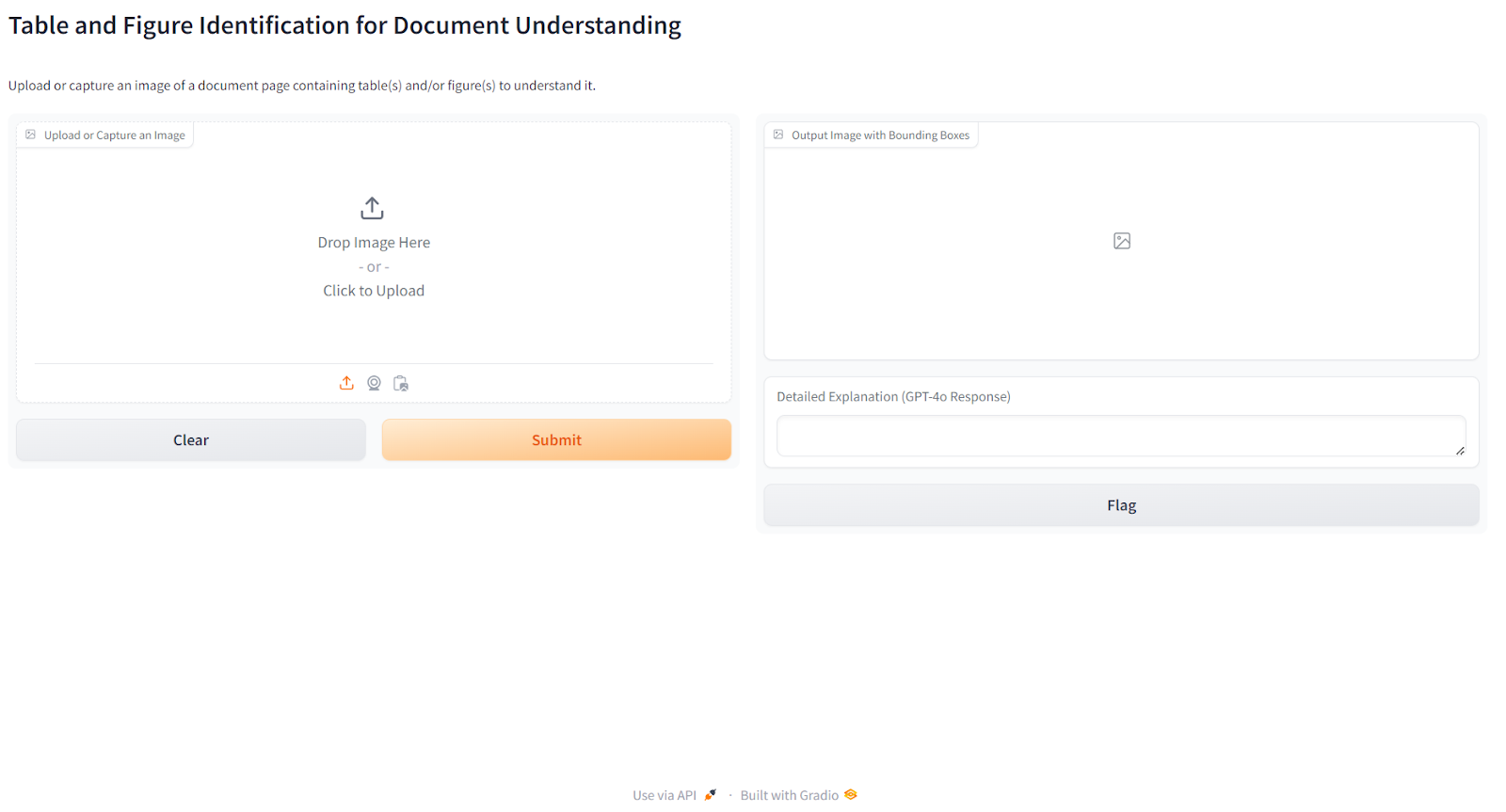
In this final step, we will build a Gradio application that allows users to input an image of a document page to help them understand any figures or tables within the image. The Gradio application utilizes the Roboflow Workflow that we developed in the previous step to perform this operation.
Here is the output of our Gradio Application:
Here is the code for the Gradio application:
import gradio as gr
from inference_sdk import InferenceHTTPClient
from google.colab import userdata
from PIL import Image, ImageDraw
from io import BytesIO
import base64
# Get the API key from Colab secrets
API_KEY = userdata.get('ROBOFLOW_API_KEY')
# Initialize the Roboflow client
client = InferenceHTTPClient(
api_url="https://detect.roboflow.com",
api_key=API_KEY
)
# Function to run inference and draw bounding boxes
def process_image(image):
# Save the image locally
image_path = "uploaded_image.jpg"
image.save(image_path)
# Run the inference workflow
result = client.run_workflow(
workspace_name="tim-4ijf0",
workflow_id="document-understanding-api",
images={
"image": image_path
}
)
# Initialize a draw object to modify the image
draw = ImageDraw.Draw(image)
# Extract bounding box information and draw it on the image
bounding_boxes = result[0]['bounding_box']['predictions']['predictions']
for box in bounding_boxes:
x = box['x']
y = box['y']
width = box['width']
height = box['height']
left = x - width / 2
top = y - height / 2
right = x + width / 2
bottom = y + height / 2
# Draw the bounding box
draw.rectangle([left, top, right, bottom], outline="red", width=3)
# Concatenate all GPT-4 outputs into a single string
gpt4o_outputs = result[0]['GPT4o_output']
raw_output = "\n\n".join([output['raw_output'] for output in gpt4o_outputs])
return image, raw_output
# Create the Gradio interface
interface = gr.Interface(
fn=process_image,
inputs=gr.Image(type="pil", label="Upload or Capture an Image", mirror_webcam=False), # Label for input
outputs=[
gr.Image(type="pil", format="png", label="Output Image with Bounding Boxes"), # Label for output image
gr.Textbox(label="Detailed Explanation (GPT-4o Response)") # Label for output text
],
title="Table and Figure Identification for Document Understanding",
description="Upload or capture an image of a document page containing table(s) and/or figure(s) to understand it."
)
# Launch the Gradio app
interface.launch(share=True)Set your Roboflow API key in an environment variable called ROBOFLOW_API_KEY.
To test the application, the following image is used containing the figure and the table both.

The following is the output generated by the application. The application utilizes bounding box coordinates and the GPT-4o response from the workflow to display the final output image, showing the identified objects with bounding boxes and their descriptions. In the output, you can see that the application successfully detects both the figure and the table and provides a detailed explanation for each.

Conclusion
This project demonstrates the power of combining computer vision and AI to enhance document understanding.
By using an object detection model built with Roboflow and OpenAI's GPT-4o API, the application can automatically identify and explain complex figures and tables in documents.
Through this process, we have also gained valuable insights into building and configuring Workflows in Roboflow, learning how to integrate multiple steps, from data input to model inference and output visualization, into a cohesive application.
Cite this Post
Use the following entry to cite this post in your research:
Timothy M. (Sep 3, 2024). Table and Figure Understanding with Computer Vision. Roboflow Blog: https://blog.roboflow.com/table-and-figure-understanding/