
Florence-2 is a lightweight vision-language model from Microsoft, released under the MIT license, that handles more than ten vision tasks including captioning, object detection, grounding, and segmentation within a single unified architecture. Its strength comes from the FLD-5B dataset, which contains 126 million images and 5.4 billion annotations built through an automated pipeline. At 0.77 and 3 billion parameters, Florence-2 outperforms Kosmos-2 on zero-shot benchmarks while being small enough to run on mobile devices or a GPU like an NVIDIA T4.
Florence-2 is a lightweight vision-language model open-sourced by Microsoft under the MIT license. The model demonstrates strong zero-shot and fine-tuning capabilities across tasks such as captioning, object detection, grounding, and segmentation.
Despite its small size, it achieves results on par with models many times larger, like Kosmos-2. The model's strength lies not in a complex architecture but in the large-scale FLD-5B dataset, consisting of 126 million images and 5.4 billion comprehensive visual annotations.
You can try out the model via HF Space or Google Colab.
In addition, we have made an interactive playground that you can use to test Florence-2. In the below widget, upload an image, then run the playground.
The playground will aim to identify bounding boxes for every object in the image using Florence-2's open ended object detection task type.
It may take several seconds to see the result for your image.
Unified Representation
Vision tasks are diverse and vary in terms of spatial hierarchy and semantic granularity. Instance segmentation provides detailed information about object locations within an image but lacks semantic information. On the other hand, image captioning allows for a deeper understanding of the relationships between objects, but without reference to their actual locations.
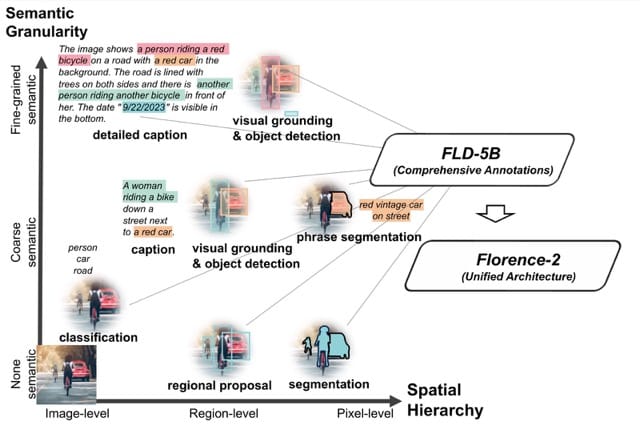
The authors of Florence-2 decided that instead of training a series of separate models capable of executing individual tasks, they would unify their representation and train a single model capable of executing over 10 tasks. However, this requires a new dataset.
Building Comprehensive Dataset
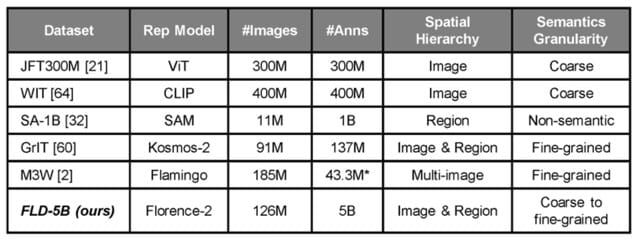
Unfortunately, there are currently no large, unified datasets available. Existing large-scale datasets cover limited tasks for single images. SA-1B, the dataset used to train Segment Anything (SAM), only contains masks. COCO, while supporting a wider range of tasks, is relatively small.

Manual labeling is expensive, so to build a unified dataset, the authors decided to automate the process using existing specialized models. This led to the creation of FLD-5B, a dataset containing 126 million images and 5 billion annotations, including boxes, masks, and a variety of captions at different levels of granularity. Notably, the dataset doesn't contain any new images; all images originally belong to other computer vision datasets.
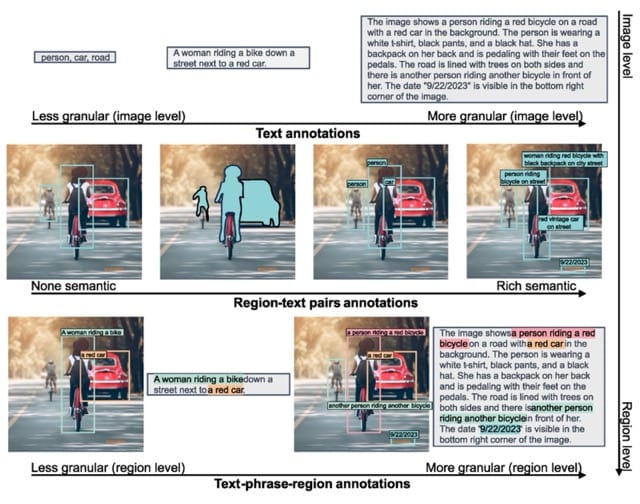
FLD-5B is not yet publicly available, but the authors announced its upcoming release during CVPR 2024.
Model Architecture
The model takes images and task prompts as input, generating the desired results in text format. It uses a DaViT vision encoder to convert images into visual token embeddings. These are then concatenated with BERT-generated text embeddings and processed by a transformer-based multi-modal encoder-decoder to generate the response.
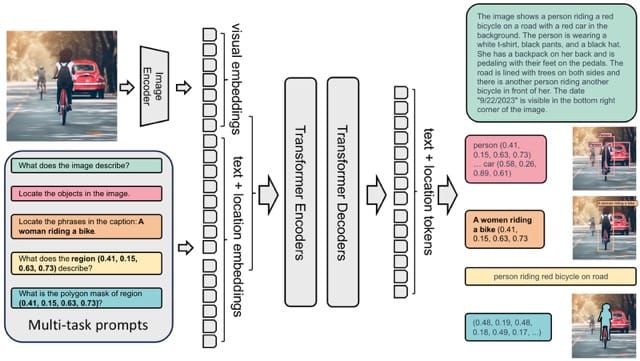
For region-specific tasks, location tokens representing quantized coordinates are added to the tokenizer's vocabulary.
- Box Representation (x0, y0, x1, y1): Location tokens correspond to the box coordinates, specifically the top-left and bottom-right corners.
- Polygon Representation (x0, y0, ..., xn, yn): Location tokens represent the polygon's vertices in clockwise order.
Capabilities
Florence-2 is smaller and more accurate than its predecessors. The Florence-2 series consists of two models: Florence-2-base and Florence-2-large, with 0.23 billion and 0.77 billion parameters, respectively. This size allows for deployment on even mobile devices.
Despite its small size, Florence-2 achieves better zero-shot results than Kosmos-2 across all benchmarks, even though Kosmos-2 has 1.6 billion parameters.




Florence-2 on CPU and GPU
While Florence-2 can technically run on CPU, we recommend running Florence-2 on a GPU. If you run Florence-2 on a CPU device, expect inferences to take several seconds. In contrast, if you run Florence-2 on an NVIDIA T4, you can expect inferences to take ~1 second per image.
Conclusions
Florence-2 represents a significant advancement in vision-language models by combining lightweight architecture with robust capabilities, making it highly accessible and versatile. Its unified representation approach, supported by the extensive FLD-5B dataset, enables it to excel in multiple vision tasks without the need for separate models. This efficiency makes Florence-2 a strong contender for real-world applications, particularly on devices with limited resources.
Curious to learn how to build your own application with Florence-2? Check out our guide where we build a shipping container OCR tool with Florence-2.
Cite this Post
Use the following entry to cite this post in your research:
Piotr Skalski. (Jun 20, 2024). Florence-2: Vision-language Model. Roboflow Blog: https://blog.roboflow.com/florence-2/