
Meta Research's Segment Anything Model (SAM) is a foundational instance segmentation model trained on 11 million images and 1.1 billion masks, released in April 2023. Its core capability is zero-shot inference: given a point, box, or text prompt, SAM produces segmentation masks for objects it has never explicitly been trained to detect. A successor, SAM 2, arrived in July 2024 with 6x higher accuracy on image segmentation benchmarks, and SAM 3 followed in late 2025 with concept-prompt-driven detection, segmentation, and tracking across images and video.
On July 29th, 2024, Meta AI released Segment Anything 2 (SAM 2), a new image and video segmentation foundation model. According to Meta, SAM 2 is 6x more accurate than the original SAM model at image segmentation tasks. This article covers the original Segment Anything model release.
Facebook released the Segment Anything Model showcasing impressive zero-shot inference capabilities and comes with the promise of becoming a new foundational model for computer vision applications.
In this blog post, we will dive into the research of how the Segment Anything model was trained and speculate on the impact it is going to have.
If you're looking for information and a tutorial on how to use SAM, explore the How to Use SAM post showing you steps to create segmentation masks for use in computer vision projects.
On July 29th, 2024, Meta AI released Segment Anything 2 (SAM 2), a new image and video segmentation foundation model. According to Meta, SAM 2 is 6x more accurate than the original SAM model at image segmentation tasks.
You might also be interested in using the newer Segment Anything 3, released on November 19th, 2025 - a zero-shot image segmentation model that detects, segments, and tracks objects in images and videos based on concept prompts.
Background on Foundation Models
Foundation models have been making major strides in natural language processing starting with the release of BERT in 2018 and up until the recent release of GPT-4.
Computer vision has struggled to find a task that provides semantically rich unsupervised pre-training, akin to next token masking in text. Masked pixels have not packed the same punch. The most effective pre-training routines in computer vision have been multi-model, like CLIP, where text and images are used in a pre-training routine.
The Segment Anything research team set out to create a task, model, and dataset that would form a foundation model for computer vision.
Let's dive in to how they did it.
What is Segment Anything?
The Segment Anything Model (SAM) is an instance segmentation model developed by Meta Research and released in April, 2023. Segment Anything was trained on 11 million images and 1.1 billion segmentation masks.
Using Segment Anything, you can upload an image and:
- Generate segmentation masks for all objects SAM can identify;
- Provide points to guide SAM in generating a mask for a specific object in an image, or;
- Provide a text prompt to retrieve masks that match the prompt (although this feature was not released at the time of writing).
SAM has a wide range of use cases. For instance, you can use SAM:
- As a zero-shot detection model, paired with an object detection model to assign labels to specific objects;
- As an annotation assistant, a feature made available in the Roboflow Annotate platform, and;
- Standalone to extract features from an image, too. For example, you could use SAM to remove backgrounds from images.
Segment Anything Task
The Segment Anything authors set up a training task for their model that involves predicting a set of "valid masks" for a given prompt to the model. The prompt could be in the form of points (presumably from a live annotator) and target masks or a word using semantic features from CLIP.

Having a prompt-able prediction like this means that training can very easily modulate the prompts in conjunction with the ground truth to show the model many examples along the way. Other work in interactive segmentation has used similar techniques in the past.
The other large benefit of having this task structure is that the model works well on zero-shot transfer at inference time when the model is being used to label masks in an image.
The Segment Anything Model
The Segment Anything model is broken down into two sections. The first is a featurization transformer block that takes and image and compresses it to a 256x64x64 feature matrix. These features are then passed into a decoder head that also accepts the model's prompts, whether that be a rough mask, labeled points, or text prompt (note text prompting is not released with the rest of the model).
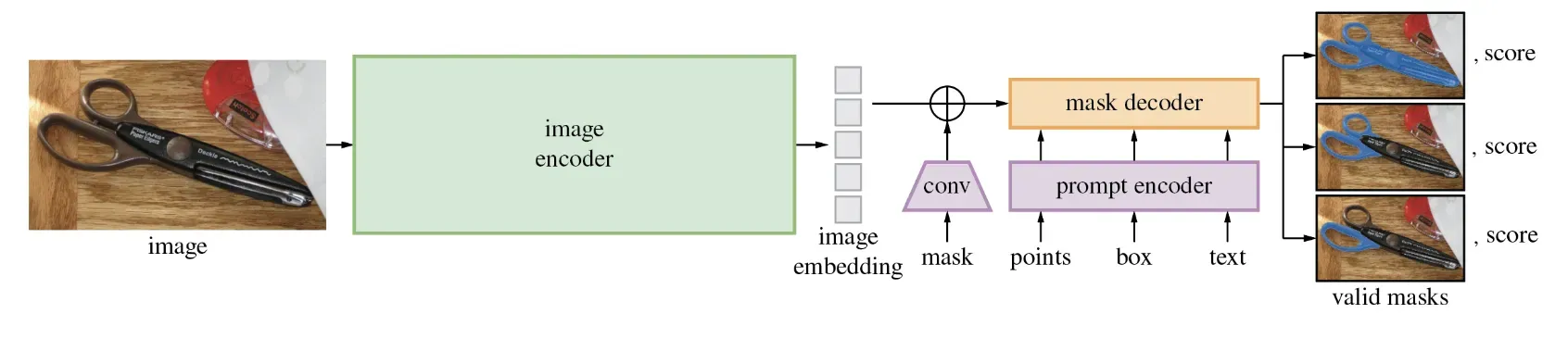
The Segment model architecture is revolutionary because it puts the heavy lifting of image featurization to a transformer model and then trains a lighter model on top. For deploying SAM to production, this makes for a really nice user experience where the featurization can be done via inference on a backend GPU and the smaller model can be run within the web browser.
Segment Anything Dataset
Segment Anything releases an open source dataset of 11MM images and over 1 billion masks, SA-1B Dataset, the largest mask corpus to date. The authors of the Segment Anything dataset product their dataset through three stages:
- Assisted Manual: Annotators annotate alongside SAM to pick all masks in an image.
- Semi-Automatic: Annotators are asked to only annotate masks for which SAM cannot render a confident prediction.
- Full-Auto: SAM is allowed to fully predict masks given it's ability to sort out ambiguous masks via a full sweep.

Segment Anything Impact Predictions and Conclusion
Segment Anything will certainly revolutionize the way that people label images for segmentation on the web and Roboflow uses SAM to power our one-click polygon labeling tool, Smart Polygon, in Roboflow Annotate.
We predict that there will be numerous applications that are built off of the SAM features as they have been demonstrated to be extremely powerful as an engine for zero-shot capabilities. Perhaps they will even be setting a SOTA on the COCO dataset for object detection with some supervision.
Even more impactful than the model itself and its features is the approach that the Segment Anything researchers were able to prove out. That is, you can train an extremely large transformer to featurize images well into a strong semantic space that can be used for downstream tasks. This is why many are calling Segment Anything a GPT-esque moment for computer vision.
We will see how it all plays out!
Until then, happy segmenting!
Frequently Asked Questions
How many images were used to train SAM?
SAM's dataset contains 1.1 billion segmentation masks and 100 million images. The segmentation mask dataset is 400x larger than the next biggest mask dataset. The image dataset is 6x larger than OpenImages V5.
Can you use SAM for zero-shot prediction?
SAM provides zero-shot prediction functionality out of the box.
Is there a Segment Anything Paper?
Meta AI released the Segment Anything paper on April 5, 2023 and it's free to access. The paper shows model performance across various benchmarks and gives insight into the dataset.
Is there a Segment Anything Demo?
There is a free interactive Segment Anything demo available online for you to use without needing a login. The demo provides sample images and you can upload your own images as well.
Is there a Segment Anything API?
Meta AI did not release an official Segment Anything API but the model is open source and available for you to use via Github.
Cite this Post
Use the following entry to cite this post in your research:
Jacob Solawetz. (Apr 7, 2023). What is Segment Anything Model (SAM)? A Breakdown.. Roboflow Blog: https://blog.roboflow.com/segment-anything-breakdown/