
Transformers, introduced in the 2017 paper "Attention Is All You Need" by Vaswani et al., replace recurrent and convolutional layers with a self-attention mechanism that models relationships across entire input sequences in parallel. This post explains the encoder-decoder architecture, how self-supervised pre-training works, and how the Vision Transformer (ViT) adapts the design for image classification by splitting images into patches. It also compares ViTs to CNNs on inductive biases and covers widely used transformer-based models including GPT and BERT.
When the term "Transformers" is mentioned, it may evoke nostalgic memories for those of us who grew up in the 80s playing with Cybertronian robots that could transform into various forms, such as trucks, planes, microcasette recorders, or dinosaurs.
While it's tempting to delve into that type of transformers, this blog post focuses on a different kind: the transformers introduced by Vaswani and his team in their seminal 2017 paper “Attention Is All You Need”. This paper changed the fields of natural language processing (NLP) and computer vision, helping to bring about new state-of-the-art models for solving a range of problems.
In this post, we'll delve into:
- What transformers are;
- How transformers work and;
- How transformers are used in computer vision.
What Is a Transformer?
Transformers, first outlined in a 2017 paper published by Google called “Attention Is All You Need”, utilize a self-attention mechanism to solve various sequence-to-sequence tasks like language translation and text generation. In the abstract for the paper, researchers note that the transformer, simpler in structure to its antecedent, can dispense “with recurrence and convolutions entirely”.
Transformers are used in tasks such as:
- Summarizing text;
- Translating text from one language to another;
- Retrieving relevant information from a corpus of text given a query and;
- Classifying images.
Recent advancements in deep learning have successfully adapted the transformer architecture for computer vision tasks like image classification, which are referred to as vision transformers.
Compared to convolutional neural networks (CNNs), vision transformers do not have inductive biases, such as translation invariance and locality. Despite this, vision transformers have shown impressive results in image classification compared to well-established CNN models. Recent improvements in efficiency, both in terms of data and computation requirements, have made vision transformers a practical and effective tool for deep learning practitioners to consider in their work.
The Transformer Architecture: A Deep Dive
The architecture of vision transformers is heavily influenced by the original transformer architecture. Having a solid grasp of the transformer architecture, especially the encoder component, is crucial for comprehending vision transformers.
This section provides an overview of the key elements of a transformer, as illustrated in the accompanying diagram. While this explanation focuses on using textual data, other forms of input, such as flattened image patches in vision transformers, can also be utilized.
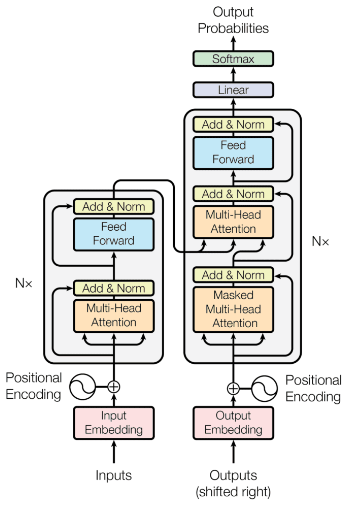
Constructing the Input
Transformers operate on a sequence of tokens that are generated from the input data. To create the tokens, the input data, typically text, is passed through a tokenizer. The job of the tokenizer is to apply rules to break text down into individual tokens. Each of these tokens is then assigned a unique integer identifier.
The token identifiers are used to index a learnable embedding matrix. This process creates a matrix of input data with dimensions (N x d), where N is the number of tokens and d is the dimensionality of the embedding vectors. The embedding vectors serve as a numeric representation of the tokens, which are then fed into the transformer model through which predictions can be made.
The transformer typically processes an entire batch of sequence data at once, with each batch containing multiple sequences of tokens. To ensure consistent processing, all sequences within a batch are padded to the same length (N) with additional tokens (e.g., zeros or random values). This enables the transformer to effectively process the batch as a single (B x N x d) matrix, where B is the batch size and d is the dimension of each token's embedding vector. The padded tokens are ignored during the self-attention mechanism, a key component in transformer architecture.
Before the input sequence is fed into the self-attention mechanism, positional information is included in the embedded tokens. The self-attention mechanism in a transformer does not inherently capture the position of each token in the sequence. Adding learnable position embeddings to each token serves the purpose of incorporating positional information into the model. This helps the transformer understand the relative order of the tokens in the sequence and more effectively process the input data.
The Encoder
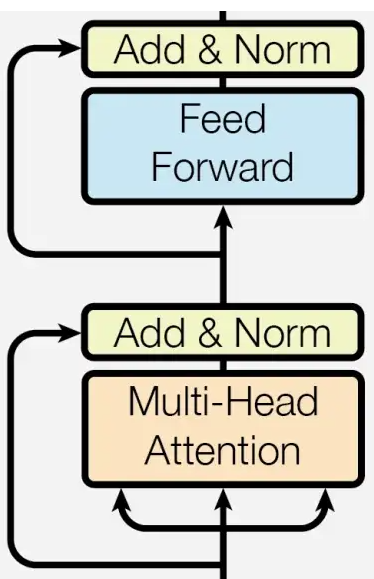
The encoder component of the transformer consists of multiple layers with a consistent structure. These layers include the following components:
- Multi-Headed Self-Attention
- Feed-Forward Neural Network
Each of these modules is followed by layer normalization and a residual connection. By passing the input sequence through these layers, the representation for each token is transformed using:
- The representations of other, relevant tokens in the sequence and;
- A learned, multi-layer neural network that implements a non-linear transformation of each individual token.
When the input sequence is processed through several consecutive layers of the identical structure, the resulting output sequence will have a similar length and contains context-aware representations for each token. This is achieved by the combined effect of normalization, residual connection, and the various modules involved in the transformation process.
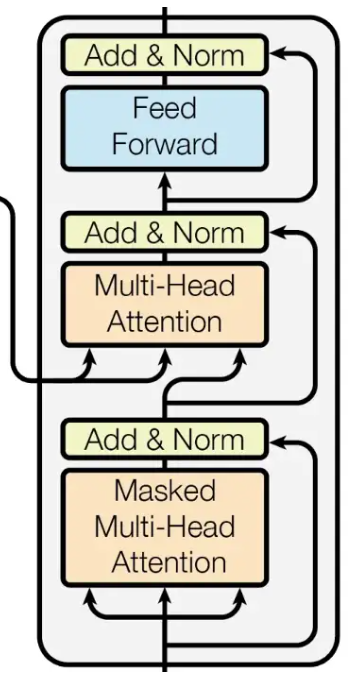
The Decoder
The decoder is composed of multiple identical layers. Each layer includes the following components:
- Masked Multi-Head Attention
- Multi-Head Attention
- Feed-Forward Neural Network
Masked self-attention helps in performing sequence-to-sequence tasks like language translation by ensuring a model doesn’t "look ahead" in the input sequence. This means that each token in the decoder is only adapted based on tokens that come before it in the input sequence.
Multi-head self-attention performs multiple independent self-attention computations in parallel, each with its own parameters. This allows for improved representation of the input and helps to capture multiple, different relationships between tokens in the sequence.
The feed-forward neural network (FFN) applies a linear transformation to the output from the multi-head self-attention component, followed by activation functions such as ReLU or GELU.
The FFN further transforms the representations and passes the final result through layer normalization.
Finally, a residual connection is added to the output from the layer normalization component. This connection helps in solving the vanishing gradient problem during training, which can have a significant and negative impact on training results. The residual connection helps to maintain the original information and helps to prevent overfitting.
The combination of these modules forms a decoder laye. The final output from the decoder is the context-aware representations of each token in the sequence.
Self-Supervised Pre-Training
The original purpose of transformers was for sequence-to-sequence tasks. However, their wide application and popularity has been boosted due to their success in other problems such as text generation and sentence classification. Success in these problems can largely be attributed to the adoption of self-supervised pre-training techniques with transformers.
The concept of self-supervised learning has greatly contributed to the success of transformers. Self-supervised tasks, like predicting “masked” (hidden) words in raw, unlabeled text data, can be used to pre-train transformers on vast amounts of data.
This pre-training approach was popularized by BERT and has been adopted in many subsequent transformer models, leading to significant improvements in natural language understanding tasks. For example, the fine-tuning of BERT on supervised tasks resulted in impressive results. This idea was later adapted in the development of GPT-3.
While the application of self-supervised learning has had a tremendous impact in NLP, the same success has not yet been seen in vision transformers as of the time of writing. Despite multiple attempts to implement this approach, it has yet to yield the same results in vision-related applications as seen in NLP.
Transformers in Computer Vision: ViTs
In the field of computer vision, attention mechanisms are widely used in combination with Convolutional Neural Networks, but there are limited cases of applying the transformer architecture solely to solve computer vision tasks. Attention mechanisms can also be utilized to replace some components of CNNs while preserving their overall structure.
Although many traditional computer vision models rely on CNNs, recent developments in the field have shown that pure transformer models applied directly to sequences of image patches can perform exceptionally well on image classification tasks.
The Vision Transformer (ViT) model, which uses a transformer encoder as its base model, has demonstrated highly competitive performance in various computer vision applications including image classification, object detection, and semantic image segmentation. This model is a testament to the extent to which transformers can apply to computer vision.
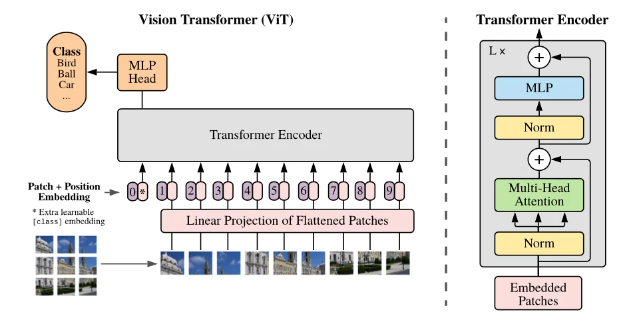
ViT Structure
The ViT model incorporates a self-attention layer which allows for the embedding of information globally across the entire image. Through training, the model learns to encode the relative position of the image patches, effectively reconstructing the image's structure. The transformer encoder in ViT is made up of three components:
- Multi-Head Self-Attention Layer (MSP): This layer concatenates attention outputs linearly and uses multiple attention heads to train both local and global dependencies within an image;
- Multi-Layer Perceptrons (MLP): A two-layer system with a Gaussian Error Linear Unit (GELU) activation function;
- Layer Norm (LN): Added prior to each block to prevent the creation of any new dependencies between training images, which helps to improve training time and overall performance.
Additionally, residual connections are included in the design of the ViT architecture after each block to facilitate the flow of information throughout the network without encountering non-linear activations. During image classification tasks, the MLP layer acts as the classification head and is equipped with one hidden layer for pre-training and a single linear layer for fine-tuning.
ViT Architecture
Here is the process used by Vision Transformers to complete an image classification task:
- Split an image into patches (fixed sizes).
- Flatten the image patches.
- Create lower-dimensional linear embeddings from these flattened image. patches.
- Include positional embeddings.
- Feed the sequence as an input to a state-of-the-art transformer encoder.
- Pre-train the ViT model with image labels, which is then fully supervised on a big dataset.
- Fine-tune the downstream dataset for image classification.
ViT Attention Maps: Visualizing Predictions
In the context of a Vision Transformer, “attention maps” refer to the visual representations of the attention scores computed by the self-attention mechanism within the transformer architecture. These attention scores determine how much information from one token is used to influence the representation of another.
Attention maps are generated by applying the self-attention mechanism to the input tokens and then visualizing the resulting attention scores. These maps show which tokens are influencing each other and provide insight into how the model is processing the image.
By visualizing the attention maps, we can gain a better understanding of how the model is making its predictions and identify areas where the model is struggling to learn important relationships between the tokens. This information can be used to improve the performance of the model by making changes to the architecture or the training process.
In general, attention maps in the context of a ViT are visual representations of the relationships between the tokenized image patches, and they can provide valuable information for improving the performance of the model.

While Vision Transformer architecture shows great potential for visual processing tasks, its performance remains inferior compared to similar-sized Convolutional Neural Networks alternatives such as ResNet when trained from scratch on moderate-sized datasets like ImageNet. Despite this, ViTs have demonstrated exceptional performance when fine-tuned or pre-trained on large datasets and show improved computational efficiency compared to CNNs.
CNN vs. Vision Transformers (ViTs)
The Vision Transformer is a model that utilizes the architecture of a transformer, initially designed for text-based tasks, to handle image classification. Unlike Convolutional Neural Networks, which process images as pixel arrays, ViT breaks down the image into fixed-sized patches, which are treated as visual tokens and embedded. The model then uses positional embeddings to process the patches as sequences and feed them into a Transformer encoder for the prediction of image class labels.
The performance comparison between a Convolutional Neural Network and a Vision Transformer depends on several factors, such as the size of the dataset, the complexity of the task, and the architecture of the models.
ViT exhibits excellent performance when trained on large datasets, surpassing state-of-the-art CNNs in accuracy while requiring 4x less computational resources. The successful application of transformers in NLP tasks has now been extended to images, where ViTs have proven to be highly effective in image recognition.
The Vision Transformer model outperforms Convolutional Neural Networks in terms of computational efficiency during pre-training. However, ViT lacks the inductive bias present in CNNs, which leads to a greater dependence on regularization or data augmentation techniques when working with smaller datasets. To obtain optimal performance, it may be necessary to incorporate additional model regularization or data augmentation strategies when using Vision Transformers.
Generally, CNNs are known for their strong spatial information processing capabilities, which make them well-suited for image classification tasks that require local feature extraction. They achieve this by applying convolutional filters to the input image, which learn local features such as edges, corners, and textures.
On the other hand, ViTs are designed to handle large-scale datasets, and they rely on the transformer architecture, which was originally developed for NLP tasks, to process the tokenized image patches. ViTs can capture long-range dependencies between the tokens, which allows them to capture more global information about the image.
In terms of performance, a ViT can surpass the performance of a CNN when trained on very large datasets, such as those containing over 14 million images. However, if the dataset is smaller, it is often more effective to use established models like ResNet or EfficientNet.
This is because ViTs have a large number of parameters, which can be difficult to optimize on smaller datasets, whereas CNNs are typically more effective in these scenarios. In conclusion, the choice between a CNN and a ViT will depend on the specifics of the task at hand and the available resources, such as the size of the dataset and computational power.
Popular Transformer-Based Models
Let’s talk through some of the most notable models that leverage transformers in NLP, image generation, and computer vision.
GPT
GPT, developed by OpenAI, is a language model that uses generative training and does not require labeled data for its training. It predicts the probability of the sequence of words in a language. There are four versions of GPT as of February 2023: GPT-1, GPT-2, GPT-3, and GPT-3.5
The GPT-1 model goes through a two-phase training process, beginning with unsupervised pre-training using a large corpus of unlabeled data, using the language model objective function. This stage is followed by supervised fine-tuning of the model on a specific task with task-specific data. The GPT-1 model is based on the transformer decoder architecture.
The main focus of GPT-2 is on generating text. To generate text, GPT-2 utilizes an autoregressive approach and trains on input sequences with the objective of predicting the next token at each point in the sequence. The model is built using transformer blocks, with a focus on the attention mechanism. GPT-2 has fewer dimensional parameters as compared to BERT (discussed below). However, GPT-2 contains more transformer blocks (48 blocks) and can process longer sequences.
The architecture of GPT-3 is similar to GPT-2, but it has a higher number of transformer blocks (96 blocks) and it is trained on a larger dataset. Additionally, the sequence length of the input sentences in GPT-3 is double the size of GPT-2.
BERT
BERT (Bidirectional Encoder Representations from Transformers) is a deep-learning model developed by Google for NLP tasks like text classification and natural language inference. The architecture consists of an encoder-only transformer that learns contextual representations of words in a given text corpus.
BERT uses self-supervised pre-training techniques, where the model learns to predict masked tokens in the input text using bidirectional representations of the words surrounding the masked tokens. This allows BERT to learn contextual relationships between words in a given text, capturing both their left and right context.
Once pre-trained, BERT can be fine-tuned on specific NLP tasks, such as sentiment analysis or question answering, using a task-specific output layer on top of the pre-trained representation layer. The fine-tuning process allows the model to adapt pre-trained weights to the target task, learning from task-specific labeled data.
BERT's ability to learn and retain contextual relationships between words in a given text has led to significant improvements over traditional models in NLP, and it is widely used in many NLP tasks today.
DALLE-2
DALL-E 2 is a transformer-based generative model developed by OpenAI. It is capable of generating diverse and high-resolution images from textual descriptions. The architecture of DALL-E 2 consists of a 12-layer transformer, where each layer has multi-head self-attention and feed-forward modules.
The model takes in a textual description as input and passes it through an embedding layer to convert the text into a dense vector representation. This vector is then passed through the transformer layers to generate a representation that captures the context of the textual description.
The output of the last transformer layer is reshaped and passed through several dense layers to generate an image. In DALL-E 2, a combination of ImageNet features and an L2 loss function is used to train the model. The L2 loss is used to compare the generated image with the target image, while ImageNet features are used to enforce semantic consistency.
In summary, DALL-E 2 works by generating a dense representation of the textual description through the transformer layers and then transforming this representation into an image through several dense layers. The model is trained to generate images that are both semantically consistent and similar to the target image.
Detectron2
Detectron2 is an open-source software framework for computer vision and object detection tasks. It is a new iteration of the original Detectron framework developed by Meta AI (formerly Facebook AI).
Detectron2 is built on a modular design that enables users to easily plug in various backbones networks, heads, and losses. The framework's backbone networks are typically convolutional neural networks that extract features from an image. These features are then fed into heads, which are responsible for making predictions about the objects present in the image. The heads can include classification heads for determining the class of the objects and regression heads for determining the position of objects in the image.
The losses in Detectron2 are used to train the network to minimize the difference between the predictions and the ground-truth annotations. The losses are defined based on the task being performed (e.g., object detection, instance segmentation, etc.). During the training phase, the framework takes as input a batch of images along with their corresponding annotations and optimizes the parameters of the network to minimize the loss. After training, the network can be used to make predictions on new images. Overall, Detectron2's modular design and its support for multiple backbones, heads, and losses make it a highly flexible and scalable framework for computer vision and object detection tasks.
Transformer Architecture
Transformers are a type of neural network architecture that has been widely adopted for Natural Language Processing tasks. They are based on self-attention mechanisms, which allow the network to consider the relationships between all elements in the input sequence.
The most popular transformer architecture is the Encoder-Decoder architecture, but there are also encoder-only and decoder-only variations used for solving specific problems. Self-supervised pre-training of transformers on large amounts of textual data has led to significant performance improvements in NLP tasks.
In computer vision, transformers have shown potential for tasks such as object detection and semantic segmentation, although the application of self-supervised pre-training has not been as successful as in NLP. Despite this, the architecture is still being actively researched and explored in the computer vision community, with several works such as DALLE-2 and ViT proposing modifications to the original transformer architecture to better suit computer vision tasks.
Ready to use the power of transformers for your own computer vision projects? Try training and deploying a state-of-the-art vision transformer model with Roboflow - no infrastructure setup required. Get started for free.
Cite this Post
Use the following entry to cite this post in your research:
Petru P.. (Feb 9, 2023). Transformer Architecture: What Is a Transformer?. Roboflow Blog: https://blog.roboflow.com/what-is-a-transformer/