
Autodistill brings a fresh approach to automated data labeling for computer vision models by leveraging large foundational models. Designed to work seamlessly with images that are organized in folders or even nested folder structures, the platform utilizes these existing arrangements to create dynamic labeling ontologies.
The names of the folders serve as prompts that Autodistill employs to auto-label the images contained within. This method allows you to take advantage of your pre-existing folder-based organization for prompts, thereby streamlining the process of data labeling for efficient model training.
The Power of Folder-Based Structured Data
By adopting a folder-based data storage approach, where each folder's name signifies a class and contains images pertaining to that class, we can:
- Simplify data management: Organizing data by class in separate folders makes it easier to manage, add, or remove data.
- Ensure data integrity: By confining images of a specific class to a designated folder, we reduce the chance of mislabeling.
- Facilitate automated labeling: Autodistill can automatically infer labels from folder names, obviating manual labeling.
This structured approach not only streamlines the data preparation process but also ensures the integrity and consistency of the data fed into the model.
How to Automatically Label Images Organized by Class
To download the starter script and follow along, use the download button below.
Initial Setup and Dependencies
First, we need to install the necessary libraries. For this project, we'll be using both Autodistill and directory tools to navigate the structured dataset.
pip install opencv-python PyYAML roboflow autodistill glob ultralyticsHarnessing the Structured Data to Define an Ontology
First, create a new file for the script we will be writing. Once you have a new file open, the first step is to establish an ontology using CaptionOntology. Our code will infer the class name directly from the folder name. This ontology maps the caption (derived from the folder name) to a specific class name, enabling the base model to generate accurate labels automatically.
Imagine you're a logging company and your team has been taking photos of trees for years and years. Someone on your team was even nice enough to sort all these tree photos by species. In the past this is where we would start the annotation process. In contrast, with Autodistill our work is almost done.
Since the person on your team is a 'subject expert' we can assume that they properly placed the photos into the proper class. In doing so, we can leverage the folder names in our CaptionOntology and programmatically annotate the photos with their appropriate class names.

Inside of "auto_dataset" we are going to store all of our folders which include the respective trees we are training the model on.
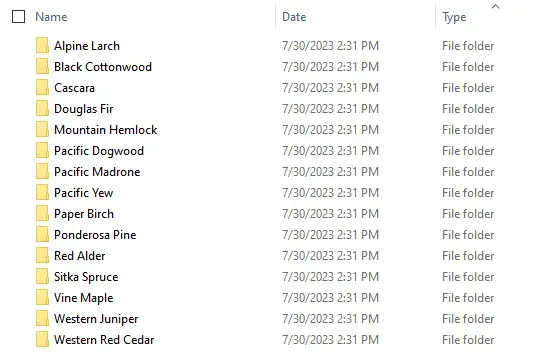
Automated Labeling Process
The structured dataset, in the form of class-specific folders within auto_dataset, is processed as follows. First, we define folders and images:
import os
import shutil
import random
import cv2
import glob
import yaml
import tempfile
from collections import defaultdict
from autodistill_grounded_sam import GroundedSAM
from autodistill.detection import CaptionOntology
from autodistill_yolov8 import YOLOv8
if __name__ == '__main__':
main_dir = "auto_dataset"
final_dir = "final_dataset"
current_directory = os.getcwd()
annotation_dir = os.path.join(main_dir, "annotations")
images_dir = os.path.join(main_dir, "images")
train_dir = os.path.join(final_dir, "train")
valid_dir = os.path.join(final_dir, "valid")
data_dict = defaultdict(list)
images = {}
try:
os.makedirs(final_dir, exist_ok=True)
os.makedirs(main_dir, exist_ok=True)
os.makedirs(os.path.join(final_dir, 'images'))
os.makedirs(os.path.join(final_dir, 'labels'))
for dir_path in [train_dir, valid_dir]:
os.makedirs(os.path.join(dir_path, 'images'), exist_ok=True)
os.makedirs(os.path.join(dir_path, 'labels'), exist_ok=True)
except:
passNext, we iterate through each folder representing a class:
# loop over all sub-directories in the top-level directory
for class_dir in glob.glob(os.path.join(top_level_dir, '*')):
# get the class name from the directory name
class_name = os.path.basename(class_dir) Next, we can use GroundedSAM to label the images in the folder based on the inferred class:
base_model = GroundedSAM(ontology=CaptionOntology({"tree": str(class_name)}))
# label all images in a folder called `context_images`
try:
base_model.label(
input_folder=class_dir,
output_folder="auto_dataset/"+str(class_name)
)
except:
pass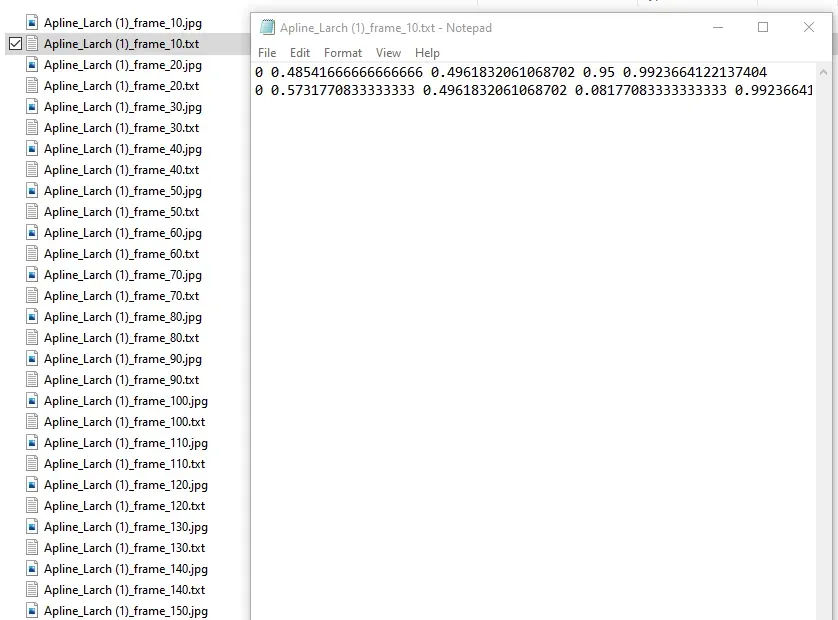
Next, we need to compile image paths and their corresponding class labels:
for img_path in glob.glob(os.path.join(class_dir, '*')):
img = cv2.imread(img_path)
if img is not None:
image_name = os.path.basename(img_path)
images[image_name] = img
data_dict[class_name].append(img_path)We can now create a final data.yaml file which can be used for training:
# Continue with your YAML creation, if necessary
yaml_dict = {
'names': list(data_dict.keys()),
'nc': len(data_dict),
'train': current_directory + "\\" + final_dir + "\\train",
'val': current_directory + "\\" + final_dir + "\\valid"
}
with open(final_dir + '\\data.yaml', 'w') as file:
yaml.dump(yaml_dict, file, default_flow_style=False)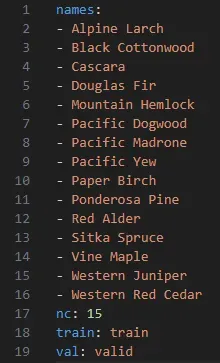
Next, we can assign the class index to class name for data.yaml to function properly:
for count, folder in enumerate(os.listdir(main_dir)):
print("Assigning class index to class name for YOLO: " + folder)
print("Class index: " + str(count))Next, we need to create the train folder and change annotations to class index:
source_folder_path = os.path.join(main_dir, folder, 'train')
if os.path.isdir(source_folder_path):
# Copy the 'images' and 'labels' subfolders to the final_dir
for subfolder in ['images', 'labels']:
source_subfolder_path = os.path.join(source_folder_path, subfolder)
if os.path.exists(source_subfolder_path):
# Loop over each file in the subfolder and copy it to the destination
for file_name in os.listdir(source_subfolder_path):
source_file_path = os.path.join(source_subfolder_path, file_name)
dest_file_path = os.path.join(final_dir, subfolder, file_name)
if os.path.isfile(source_file_path): # Check if it is a file, not a directory
# If this is an annotation file, rewrite the first value in each line
if subfolder == 'labels':
with open(source_file_path, 'r') as annot_file:
lines = annot_file.readlines()
lines = [str(count) + line[line.find(' '):] for line in lines]
with open(dest_file_path, 'w') as annot_file:
annot_file.writelines(lines)
else:
shutil.copy2(source_file_path, dest_file_path) # preserves file metadataCreate the valid folder and change annotations to class index:
source_folder_path = os.path.join(main_dir, folder, 'valid')
if os.path.isdir(source_folder_path):
# Copy the 'images' and 'labels' subfolders to the final_dir
for subfolder in ['images', 'labels']:
source_subfolder_path = os.path.join(source_folder_path, subfolder)
if os.path.exists(source_subfolder_path):
# Loop over each file in the subfolder and copy it to the destination
for file_name in os.listdir(source_subfolder_path):
source_file_path = os.path.join(source_subfolder_path, file_name)
dest_file_path = os.path.join(final_dir, subfolder, file_name)
if os.path.isfile(source_file_path): # Check if it is a file, not a directory
# If this is an annotation file, rewrite the first value in each line
if subfolder == 'labels':
with open(source_file_path, 'r') as annot_file:
lines = annot_file.readlines()
lines = [str(count) + line[line.find(' '):] for line in lines]
with open(dest_file_path, 'w') as annot_file:
annot_file.writelines(lines)
else:
shutil.copy2(source_file_path, dest_file_path) # preserves file metadataNext, we can get a list of all the images and annotations:
# Get a list of all the images and annotations
image_files = [f for f in os.listdir(os.path.join(final_dir, "images")) if os.path.isfile(os.path.join(final_dir, "images", f))]
print("LENGTH OF IMAGES: " + str(len(image_files)))
annot_files = [f for f in os.listdir(os.path.join(final_dir, "labels")) if os.path.isfile(os.path.join(final_dir, "labels", f))]
print("LENGTH OF ANNOTATIONS: " + str(len(annot_files)))We can generate a random shuffle of your dataset for train/valid split using the following code:
# Assume that each image has a corresponding annotation with the same name
# (minus the extension), shuffle the list and split into train and validation sets
random.shuffle(image_files)
valid_count = int(len(image_files) * 0.1)
valid_files = image_files[:valid_count]
train_files = image_files[valid_count:]Finally, we can move data to final_dataset directory and remove empty directories:
# Move the files to the appropriate folders
for filename in valid_files:
shutil.move(os.path.join(final_dir, "images", filename), os.path.join(valid_dir, 'images', filename))
annot_filename = os.path.splitext(filename)[0] + ".txt"
if annot_filename in annot_files:
shutil.move(os.path.join(final_dir, "labels", annot_filename), os.path.join(valid_dir, 'labels', annot_filename))
for filename in train_files:
shutil.move(os.path.join(final_dir, "images", filename), os.path.join(train_dir, 'images', filename))
annot_filename = os.path.splitext(filename)[0] + ".txt"
if annot_filename in annot_files:
shutil.move(os.path.join(final_dir, "labels", annot_filename), os.path.join(train_dir, 'labels', annot_filename))
try:
os.removedirs(final_dir + '/images')
os.removedirs(final_dir + '/labels')
except:
passFinally, we can train a YOLOv8s model on your auto-labeled Autodistill data:
target_model = YOLOv8("yolov8s.pt")
target_model.train(data=final_dir+'\\data.yaml', epochs=200)
# run inference on the new model
pred = target_model.predict("auto_dataset/valid/your-image.jpg", confidence=0.5)
print(pred)
To evaluate our model, we can review the confusion matrix in the "\runs\detect\train" section. This matrix is produced when you train a YOLOv8 model:
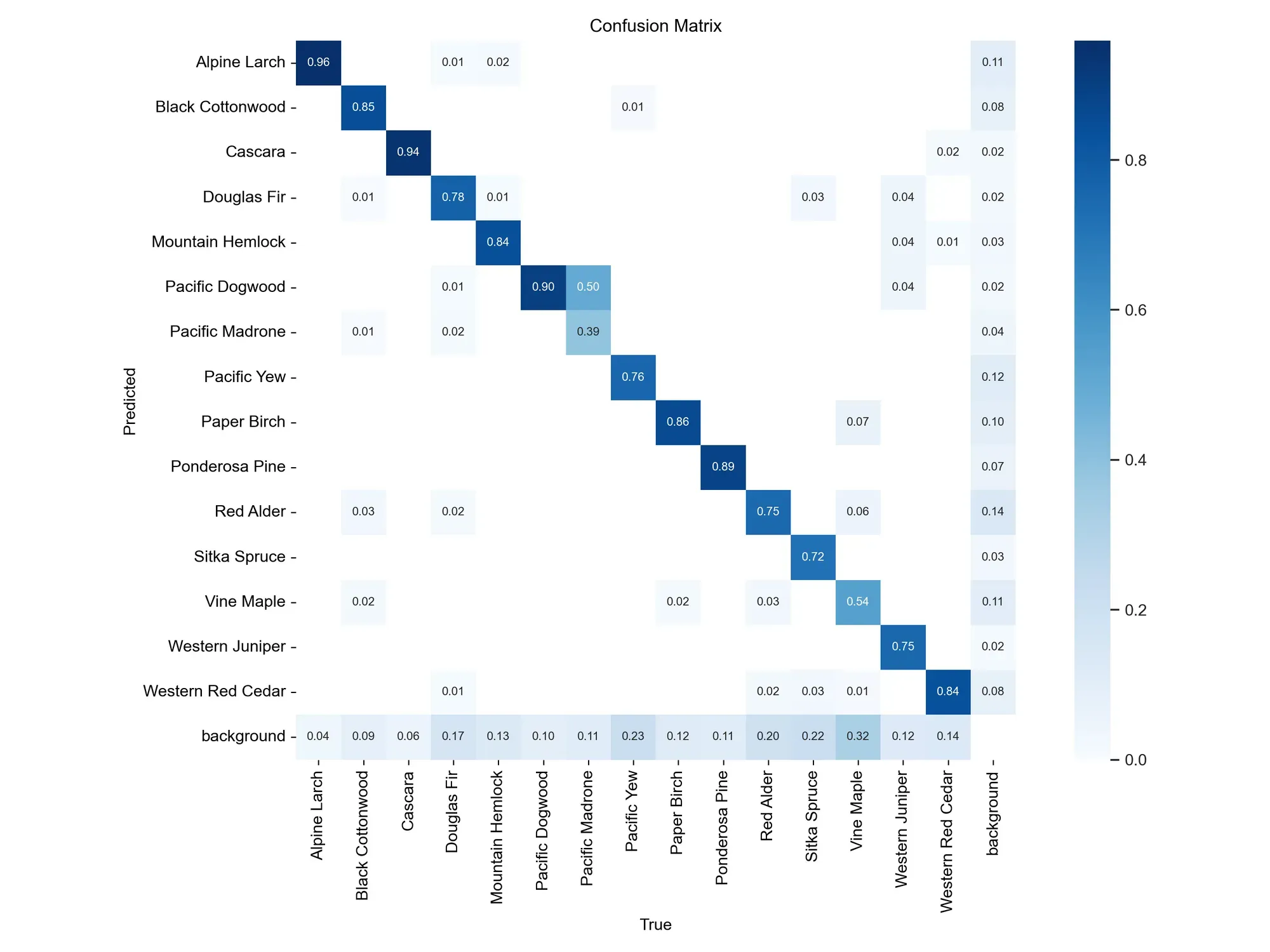
Conclusion
Autodistill revolutionizes the way you train models by eliminating the need for manual data labeling. That's correct, zero annotations are required! The platform accomplishes this feat by utilizing unlabeled images to train a base model. When leveraging structured data as mentioned above you can accelerate the development of large model
By using the folder names as a labeling ontology to automatically label these images, and creating a dataset that serves as the training ground for your specialized model. This innovative method dramatically reduces human involvement in the machine learning process, accelerating the speed at which tailor-made models can be deployed in edge computing scenarios.
In summary, Autodistill, a pioneering innovation from Roboflow, elevates the practice of model distillation within the field of computer vision. By transferring insights from larger models into compact, efficient alternatives, the platform enables you to achieve remarkable performance, particularly with regard to processing speed and computational limitations.
Additionally, its features such as prompt evaluation and automated annotation refine the data labeling process, enhancing both efficiency and accuracy. Importantly, the platform's ability to train models with zero manual annotations paves the way for fully automated machine learning processes and swift edge deployment. Welcome to the era of streamlined efficiency and automation!
Cite this Post
Use the following entry to cite this post in your research:
Tyler Odenthal. (Aug 28, 2023). Automated Labeling for Images Organized in Folders. Roboflow Blog: https://blog.roboflow.com/autodistill-folder-structure/