
Foundation models have become a growing part of fundamental research in computer vision and natural language processing. These models (i.e. CLIP by OpenAI and Segment Anything by Meta AI) are trained on massive amounts of data. Through this process, foundation models learn about a vast array of concepts in the domain of the data on which they are trained, whether it is audio, visual, text, and more.
Foundation models are almost like a cheat code: someone else paid for the computing resources to learn knowledge that you can use in a vision project.
Foundation models are large because they have learned about a lot of different concepts. As a result, foundation models often require a large amount of memory to use. Running inference is slower when compared to a smaller, task-specific model.
This makes them unwieldy to use for most real-time or batch processing tasks (i.e. when processing videos, streams, or large amounts of images). With that said, they play a significant role in building computer vision powered applications, by being used alongside custom models, useful for helping to speed up the human annotation process, automatically labeling data to use for training smaller models, and more.
In this guide, we are going to discuss what foundation models are and a few of the many use cases for foundation vision models. We will make reference to specific tools you can use to leverage foundation models for the use cases we outline, allowing you to not only learn about, but experiment with large models for use in your projects.
Without further ado, let's get started!
What is a Foundation Model?
A foundation model is a large machine learning model trained to have vast knowledge about a range of concepts. To build this knowledge, foundation models usually need to be trained with a significant amount of data from different domains. Foundation models are becoming increasingly common in natural language processing and computer vision.
In computer vision, foundation models like Segment Anything (SAM), used to identify objects at the pixel-level, are great for a range of use cases. Given a prompt like "screw" or "robot arm", Segment Anything, combined with a model like Grounding DINO or CLIP, will be able to help you find what you are looking for. But there is a cost: running SAM and another model l slower than using a model trained to identify a particular object.
For most use cases, you don't need to know "a lot about a lot". In other words, you don't need a model that can identify a vast range of objects. Rather, you need a model that can identify for what you are looking, to a high degree of accuracy, and quickly. That's where task-specific models come in.
We can leverage foundation models to help create a computer vision model or use them alongside custom models in applications. Let's take a look at some of the ways you can use foundation models in computer vision.
What Foundation Models Are Used in Computer Vision?
Over the last few years, various organizations have trained and published foundation models for public use. The most common ones include:
- Grounding DINO, used for object detection;
- SAM, used for segmentation, and;
- CLIP, used for classification and image comparison;
We will make reference to these models as we discuss specific use cases.
Use Foundation Models Directly in Vision Applications
Foundation models can be used directly for tasks or as part of a multi-stage vision workflow. For example, you can use CLIP for image classification (is an image X, Y, or Z), identifying distinct scenes in a video, identifying similar or dissimilar images in a dataset, and clustering images.
Consider a scenario where you want to know when there is a scene change in a video. You could use CLIP to measure the similarity between frames. When a frame is sufficiently dissimilar from the last frames, you can note that there was a scene change. This could be used for measuring the length of scenes in sports broadcasts (i.e. commentator time, ad time, game time), for example.
You can also use foundation models as part of a multi-step workflow. Consider an application that, given an image of an item, tells you the make, model, price, and other meta information about the item. You could use CLIP to classify the type of power tool in an image (drill, saw, etc.), then use the output to decide which of multiple tool-specific models should evaluate the tool. These models could then determine the make and model of a tool.

This system would:
- Accept an image from a user
- Use CLIP to classify what type of power tool is in the image
- Use a model to identify the power tool manufacturer
- Use another model to identify the make of the power tool
This setup is ideal because it is easier to train small models that identify a limited number of classes than it is to train a large model that can identify hundreds or thousands of classes.
Collect Relevant Data for Training Models
CLIP is a foundation model that you can use to classify images (e.g. is a photo of a person or a forklift) and compare the similarity between text and an image or two images. You can use the CLIP similarity comparison features to build a system for collecting relevant data for use in training computer vision models.
With a camera and CLIP, you can compare the similarity of frames. If a frame is sufficiently different from the last frames – or sufficiently similar – you can save it for use in model training. With this approach, you can collect relevant data without having to save lots of data that is too similar or dissimilar that will be less useful in your model.
Consider a scenario where you want to build a model to identify trains on tracks. You could use CLIP with a camera positioned at a train station to intelligently collect data. If a frame is dissimilar from the previous few frames, it will indicate a change in the environment (i.e. a new train has arrived, a cargo train is passing through).
You can use Roboflow Collect for this purpose. Collect is an image collection solution with which you can gather images for use in training vision models.
Label Data Automatically for Model Training
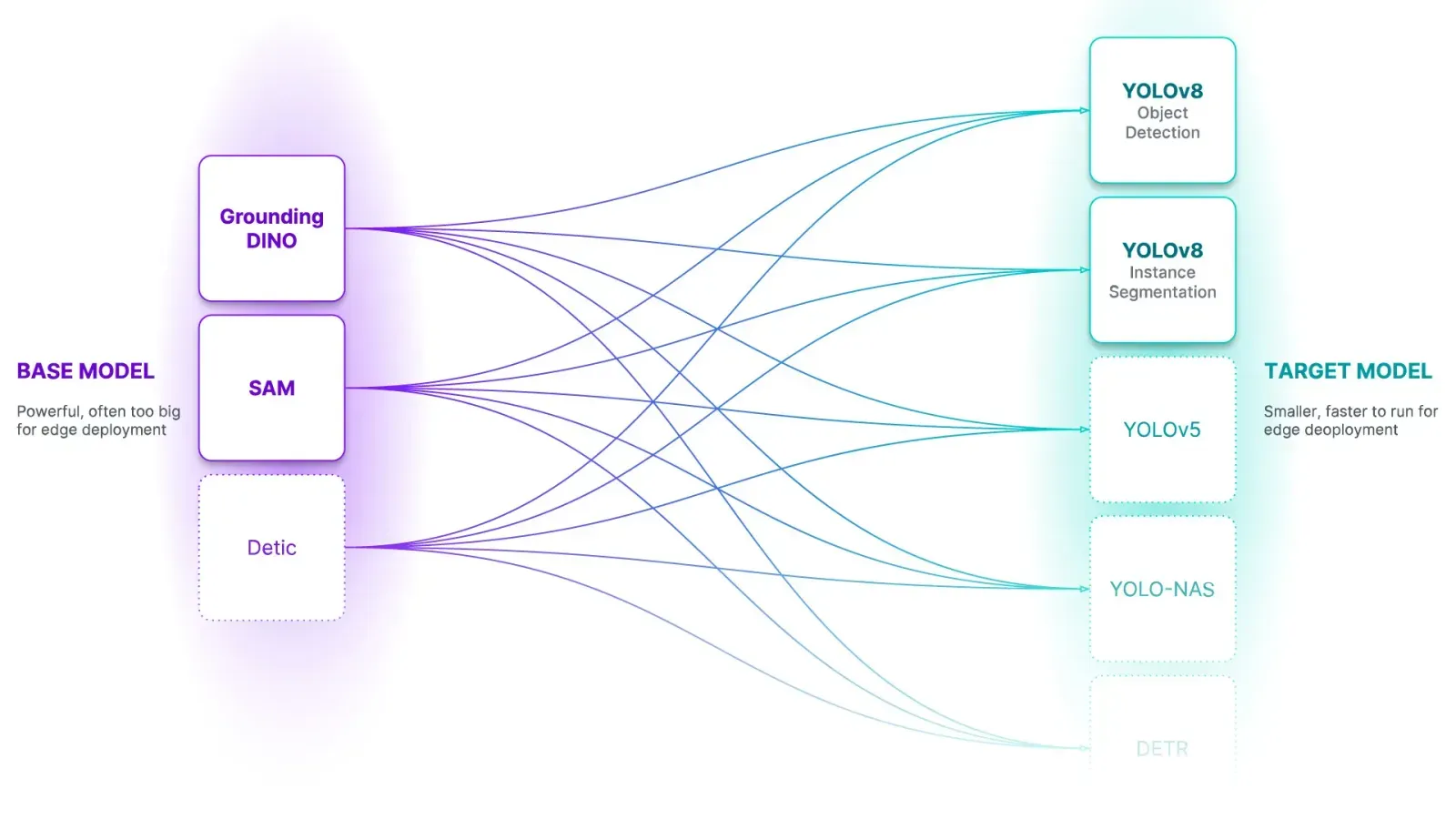
Foundation models can be used to label data automatically for training vision models. For example, you can use Grounding DINO for object detection, Segment Anything for segmentation, and CLIP for classification.
Foundation models take in a text prompt (i.e. "box") and will assign a label appropriate for the task type with which you are working. An object detection foundation model will draw a bounding box around an object, segmentation models will draw a mask (which can also be turned into a bounding box if necessary), and classification models will return a label.
Consider a scenario where you want to build a package detection model for use in tracking boxes in a conveyor belt. Grounding DINO could identify all of the packages on the conveyor belt in the images you have collected. You can use the bounding boxes returned from Grounding DINO as labels for use in training a model.
Roboflow is building Autodistill, an open source tool for using large, foundation vision models to train smaller, task-specific models. With Autodistill, you can use common foundation models such as Grounding DINO, SAM, and CLIP and connect them with popular models for use in training like RF-DETR and ViT.
After running Autodistill, you will have a fine-tuned model ready to use. This model will be significantly smaller than the foundation model used to label images and will thus be more practical to run on the edge or at scale.
Use for Human-Assisted Tasks
SAM, used for image segmentation, in particular is useful for human-assisted automated labeling. With SAM-powered labeling, you can hover your cursor over an object of interest in an image and SAM will identify the boundaries of the object. This allows you to create accurate labels for use in training a model, without having to manually draw individual polygon points around each object of interest in an image.
Roboflow has a SAM integration you can use for automated labeling. With this integration, you can point at an object to label an object and click to save the label. You can click inside or outside the object to refine the label: clicking inside lets you remove parts of the label that are less relevant, and clicking outside lets you expand the label.
Learn More About the Contents of a Dataset
CLIP, used for classification and image similarity, generates "embeddings". These embeddings are numeric representations of the semantic content of an image. The closer two embeddings are, the more similar the images they represent are.
With this property comes the potential to uncover many insights about a dataset through clustering. Using an algorithm like t-SNE, you can visualize all of the images in your dataset on a scatter plot. Similar images will be closer together; dissimilar images will be further apart. This visualization will give you an insight into the composition of your dataset.
You can use this plot with a secondary dimension, such as how a model performed on each image, to figure out whether there are particular clusters of images that perform more poorly on your data. If this is the case, you may not have enough images for a given use case, data may not be labeled correctly, among other reasons. CLIP can help you identify dataset issues, and you can spend time working to resolve any issues you have found.
Roboflow has an in-app vector analysis tool you can use to understand model performance across images in your test dataset. The vector analysis tool is powered by CLIP, allowing you to see performance grouped into clusters by the semantic similarity of images.
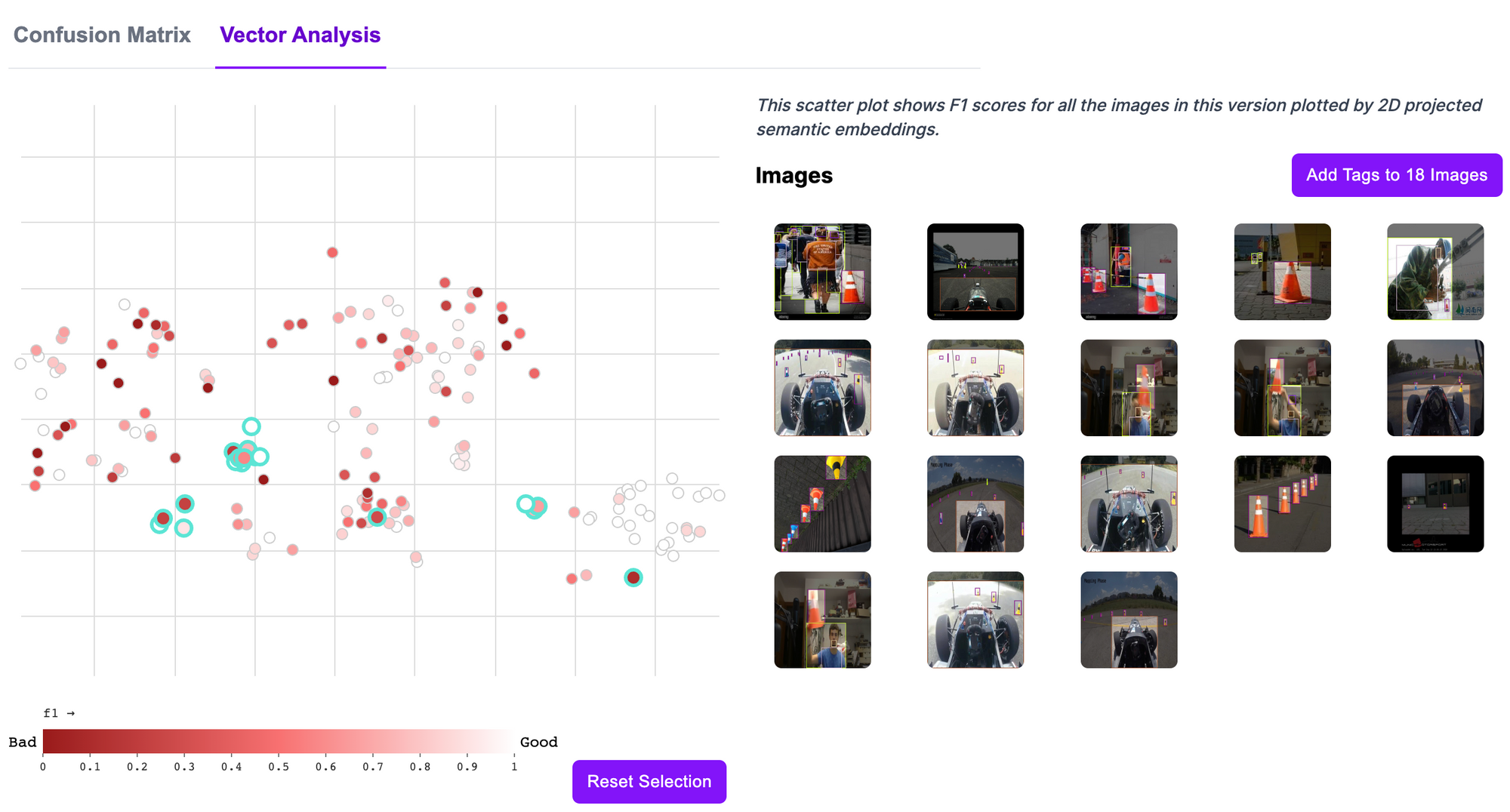
We have also published a blog post and accompanying notebook that you can use to run your own vector analysis on a dataset.
More Use Cases for Foundation Vision Models
There are many more use cases for foundation vision models. The Roboflow team is always thinking about ways to use foundation models to solve business problems. Here are a few other use cases for foundation vision models:
- Classify frames in a video with CLIP. CLIP accepts arbitrary text labels, which is useful for zero-shot (no prior training) classification on video frames.
- Identify scene changes in a video with CLIP.
- Build a semantic image search engine with CLIP.
- Use a model out of the box for inference. This is useful if you have a limited range of images on which you want to run inference, or for experimenting.
How to Use Foundation Models with Roboflow
Roboflow has a range of tools you can use to experiment with foundation models:
- Autodistill: With Autodistill, you can use CLIP, SAM, Grounding DINO, DINOv2, and other foundation models for labeling data automatically in a few lines of code (or a single command).
- Inference: Roboflow Inference has endpoints for using CLIP and SAM. This allows you to run inference with CLIP and SAM through a HTTP endpoint hosted in Docker. With Inference, you can have a single server manage all of your inferences.
- SAM-based Label Assist: You can use SAM for automated labeling in Roboflow Annotate, allowing you to label images faster than ever.
We also have free notebooks that show how to use various foundation models step by step.
Conclusion
Foundation vision models are playing a growing role in modern vision workflows. While foundation models may be unwieldy to use for inference on the edge, there are many practical situations in which they are useful.
There are foundation models covering object detection, classification, and segmentation, such as Grounding DINO, CLIP, and SAM, respectively.
In this guide, we have explored how to use foundation vision models for automated data collection, automated labeling, human-assisted automated labeling, and for learning more about the contents of a dataset. You can use the information we have provided to think through potential use cases for foundation models in your projects, no matter the scale at which you are working.
Cite this Post
Use the following entry to cite this post in your research:
James Gallagher. (Aug 29, 2023). Use Cases for Computer Vision Foundation Models. Roboflow Blog: https://blog.roboflow.com/use-cases-for-computer-vision-foundation-models/