
Anthropic released Claude Fable 5 calling it its most capable model ever, and made a specific claim about vision:
Fable 5 is the new state-of-the-art model for tasks involving vision. It can extract precise numbers from detailed scientific figures and can perform complex vision-based tasks like rebuilding a web app's source code from screenshots alone.
We ran it through the Roboflow Vision Evals: 67 visual tasks built from real-world imagery across object understanding, spatial understanding, document understanding, defect detection, and object counting. We used the Anthropic API with adaptive thinking at maximum effort, so this is the model at its strongest configuration.
The claim doesn't hold up on real-world imagery. Claude Fable 5 lands 10th at 74.63% (50/67), behind Google's Gemini 3.5 Flash and Gemini 3.1 Pro and OpenAI's GPT-5.4 and GPT-5.5. At $10 per million input tokens and $50 per million output, it is also the most expensive model near the top of the leaderboard.
Claude Fable 5 on Vision Leaderboard
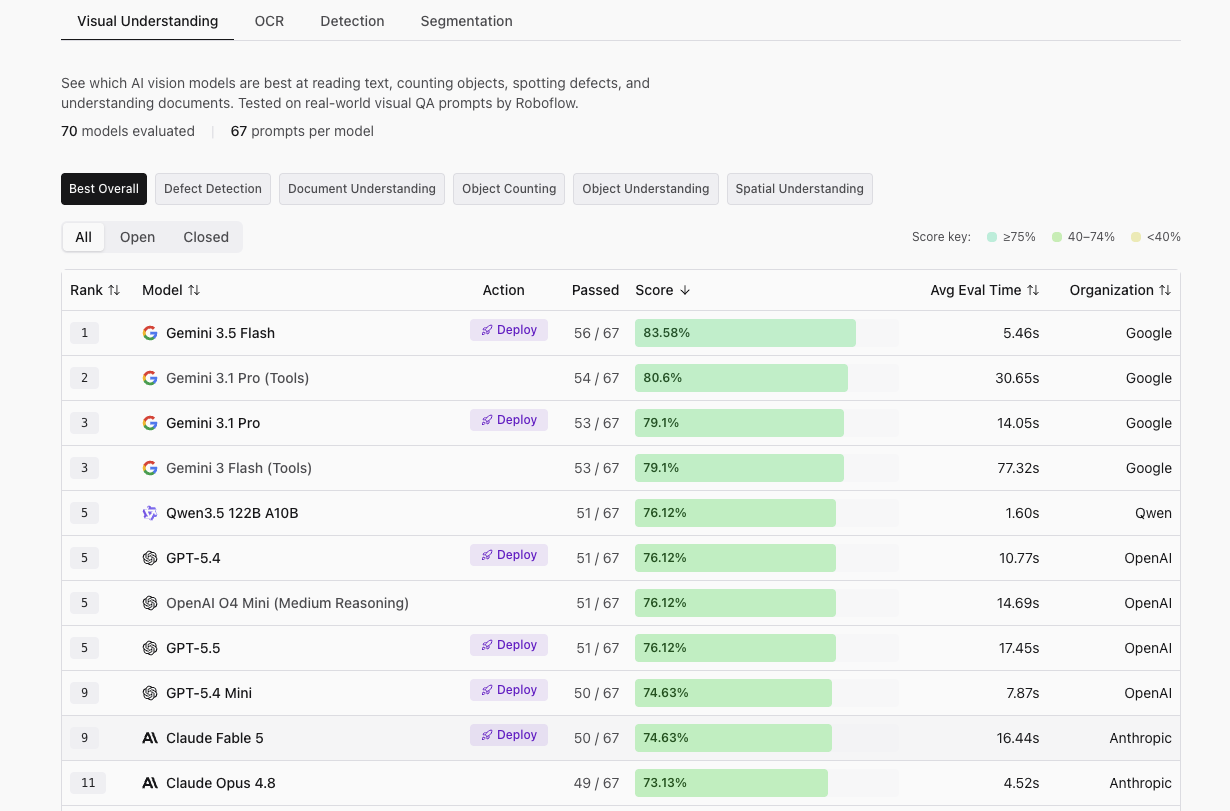
Fable 5 edges out Claude Opus 4.8 by one task and runs nearly four times slower. Gemini 3.5 Flash passes six more tasks while responding three times faster, at a fraction of the cost.
The category breakdown shows where performance varies:
- object understanding 14/14
- spatial understanding 15/19
- defect detection 11/15
- document understanding 7/9
- object counting 3/10
The perfect object understanding score matches Anthropic's framing: this is a model built for reasoning about images, and for visual question answering or document extraction it is among the best we have tested.
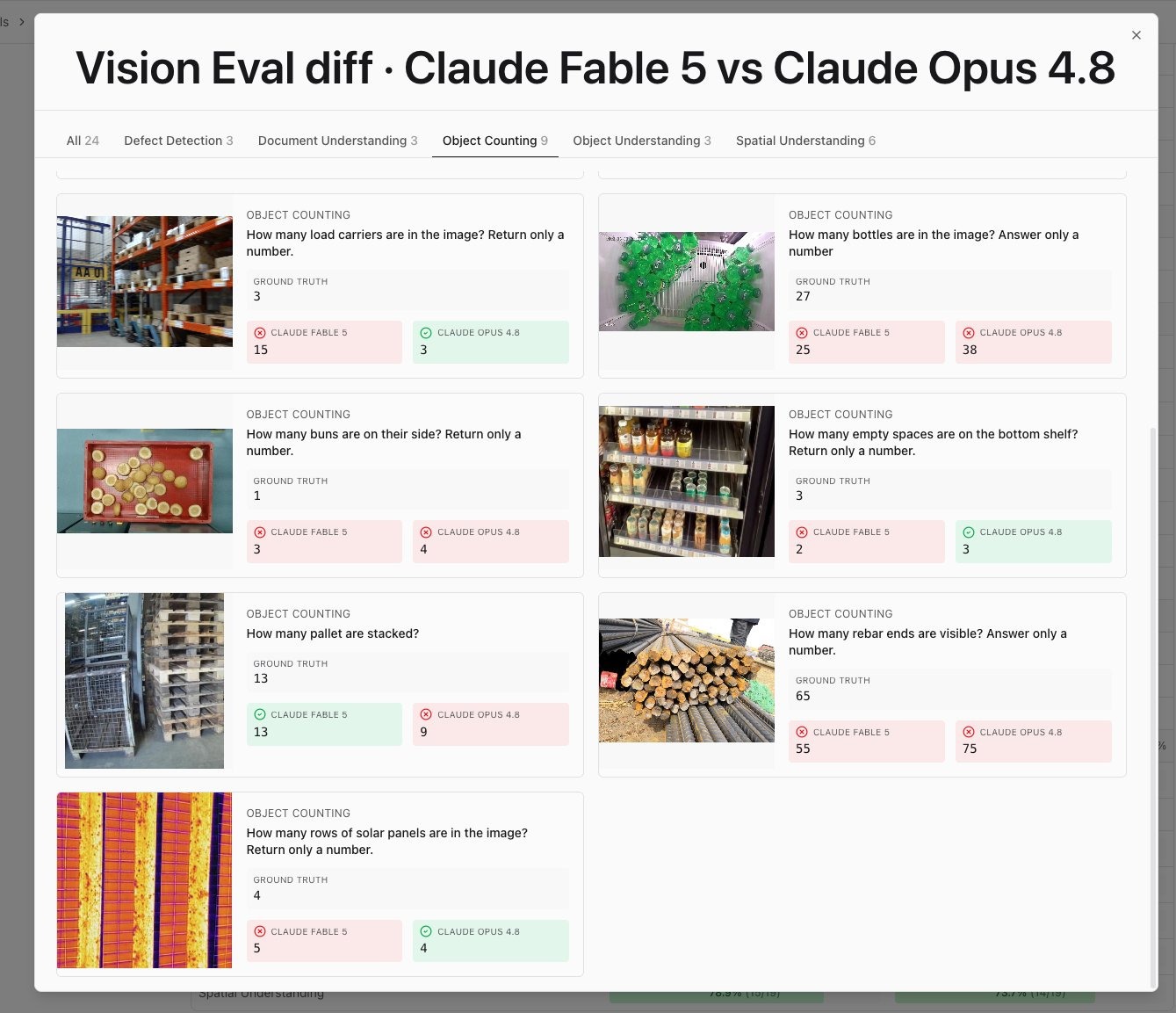
The failures follow the pattern we see in every VLM: counts hold up when objects are few and separated, and fall apart with clutter and occlusion.
Gemini 3.5 Flash passed 7 of the same 10 counting tasks, so Google currently leads here, and no general-purpose VLM is production-grade at counting yet.
The fix for improving counting results is not a bigger VLM. In Roboflow Workflows, run a fine-tuned RF-DETR model trained on your own imagery to detect and count every instance, then use Fable 5 for what it is actually good at: reasoning about the scene and turning results into structured output.
A detector trained on a few hundred labeled images will beat any frontier VLM on counting, at a fraction of the inference cost.
Conclusion
Claude Fable 5 is a strong reasoning model for visual understand but not a state-of-the-art vision model. Use it for visual question answering (VQA) and document extraction; pair it with a specialized detector for localization, measurement, and counting.
Compare Fable 5 against every model we have benchmarked on the Vision Evals leaderboard, or test it on your own images in the Roboflow Playground.
Cite this Post
Use the following entry to cite this post in your research:
Erik Kokalj. (Jun 11, 2026). Claude Fable 5 for Vision: Evaluation and Benchmarks. Roboflow Blog: https://blog.roboflow.com/claude-fable-5-for-vision/