
NVIDIA Cosmos 3 is a 32B open foundation model for vision reasoning across text, image, video, and action, and ranks among the top open models on VANTAGE-Bench, a benchmark of real-world fixed-camera footage in warehouses, transportation hubs, and smart spaces. Tested without fine-tuning on three scenes (an airport gate turnaround, a warehouse loading dock, a kitchen assembly line), Cosmos 3 Super reliably segmented activity into structured state sequences when prompting and region framing were set up carefully. It handles slow, coarse events better than fast or small-object actions.
What is Cosmos 3?
Cosmos 3 is an open frontier foundation model for physical AI. It is an omni-model, which means one model handles vision reasoning and multimodal generation across text, image, video, ambient sound, and action. Two open variants shipped on day one, Super (32B) and Nano (8B), under the OpenMDW 1.1 license, available on GitHub.
The part that caught our attention is the reasoning side. Cosmos 3 is currently one of the highest-ranked open model on VANTAGE-Bench, a benchmark built for real-world fixed-camera footage across warehouses, transportation, and smart spaces.
Fixed cameras pointed at operations is most of the visual data the physical world actually produces. So we ran our own tests on exactly that kind of footage, with no fine-tuning, to see how far the base model gets you.
We tested three scenes of increasing difficulty: an airport gate, a warehouse, and a kitchen assembly line. Here is what we found.
Testing Cosmos 3 for vision use cases
All tests used Cosmos 3 Super (32B) in thinking mode. Videos were split into multiple chunks, and afterwards results were combined back together.
No per-frame calls, no fine-tuning, no detection model in the loop. The variables we changed were the region of interest we passed in, the frame rate (ingestion), chunk duration, and the prompt.
Test 1: Airport gate turnaround
A fixed camera on a single airport gate. We cropped the region of interest to the plane and cargo zone and prompted Cosmos 3 to track cargo movement through the turnaround.
Cosmos 3 segmented the whole turnaround into six clean states: no plane, parked with the door closed, door open, unloading, loading, and empty again. We used 1 FPS, 15-second chunks, as cargo movement isn't that fast. The transitions lined up with what was happening on the apron.
Test 2: Warehouse loading dock
A warehouse with two roll-up gates, forklifts and crews moving boxes from truck to the pallets and vice-versa. Harder than the airport: two active zones in one frame, more clutter, and the events we cared about (box movements) are subtler than a plane arriving.
This is where the prompt and setup mattered more than the model. Three things moved the accuracy:
- Splitting the region of interest per gate and running inference on each gate separately beat one combined call across the whole frame.
- Lower frame rates over longer clips read more accurately than dense sampling. 0.2 FPS ingestion, 30 second video chunks worked better than 2 FPS, 5 second chunks.
- Framing the task around the pallet's cargo level (is it increasing or decreasing) beat tracking boxes in motion between the pallet and the van. Watching the slow-changing state was more reliable than watching the fast-moving handoff.
Takeaway: when a scene has multiple zones and subtle state changes, isolate each zone and point the model at the state that changes slowly, not the motion that changes fast.
Test 3: Kitchen assembly line
An overhead camera on a taco line, checking each order's build against the ticket as ingredients went onto the plate. This is the hardest of the three: many small, visually similar items (salsas, cabbage, guacamole, radishes) packed into adjacent bins, fast hands, and an overhead angle.
We used 4 FPS, 3-second chunks, with 1 frame overlap.
Spatial grounding helped. Telling the model where each ingredient lived (cabbage in the top-left bin, the salsas in the center) lifted accuracy noticeably over leaving it to figure out the layout on its own. But this was the toughest case, and the base model still struggled in these settings. It missed some ingredients and the timing of a few transitions was off.
Takeaways using Cosmos 3 for vision
A few patterns held across all three scenes:
- The base model is genuinely capable on fixed-camera footage with zero fine-tuning, which tracks with its VANTAGE-Bench result.
- Models do better tracking slow-changing state (e.g., pallet fill level) than fast-moving actions (e.g., individual box transfers).
- Difficulty scales with the number of small, similar objects and the speed of the action.
- How you frame the scene matters. Cropping to the subject and analyzing each zone separately produced some of the largest accuracy gains.
Image VQA Benchmarks
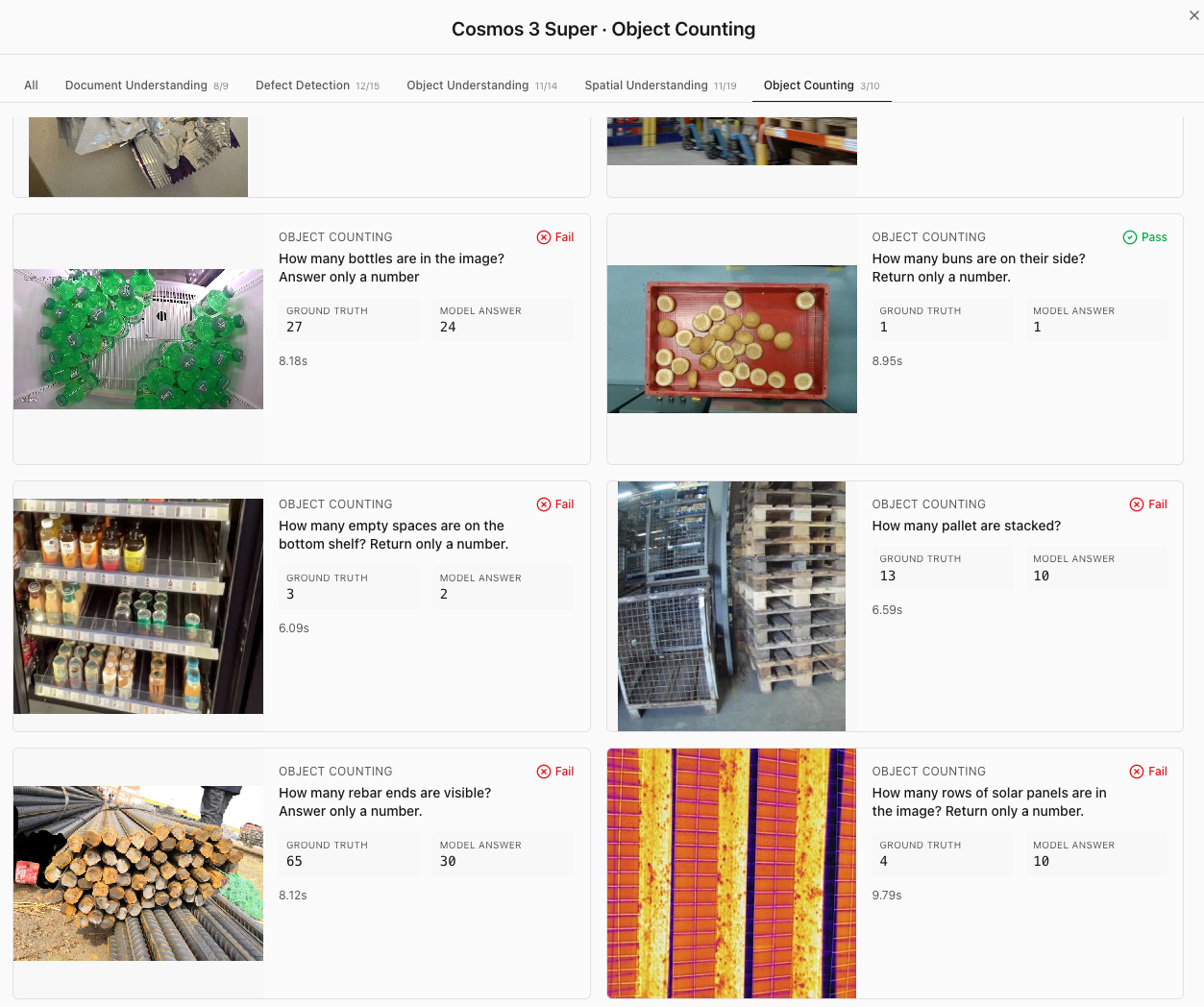
We have also tested the model on our Visual Understanding Evals, where Cosmos 3 Super (with Thinking enabled) did well (passed 45/67 tasks), but still scored below Qwen 3.5 27B. It struggled the most on Spatial Understanding and Object Counting tasks.
When to use Cosmos 3 for vision
Cosmos 3 is a strong base for turning fixed-camera feeds into structured events, and the gap between an impressive demo and a system you can trust in an operation is the same gap it has always been: data, reliability, and deployment.
That loop, label, train, deploy, and retrain on the data your cameras generate, is what we build at Roboflow, and it is where a model like Cosmos 3 goes from a good test to something running on the line.
Sources: NVIDIA newsroom: Cosmos 3 launch, NVIDIA blog: How Cosmos 3 helps Physical AI think before it acts, Hugging Face: Welcome NVIDIA Cosmos 3.
Cite this Post
Use the following entry to cite this post in your research:
Erik Kokalj. (Jun 3, 2026). Cosmos 3: Evaluation for Vision Use Cases. Roboflow Blog: https://blog.roboflow.com/cosmos-3-vision/