
When training any machine learning model, you must trade off inference speed for accuracy. Larger models with more parameters are almost always more accurate, and smaller models with fewer parameters uniformly infer faster.
Roboflow now offers two model sizes for training custom object detection, Fast and Accurate.
In this post, we will dive into what you should be considering when choosing between fast and accurate.
We provide some benchmarks so you can directly quantify the tradeoff for your use case.
Accuracy Tradeoff
Smaller models will almost always make less accurate predictions. The metric we use to evaluate object detection accuracy is called mean average precision, a measure of how well the predicted bounding boxes overlap with ground truth bound boxes.
In order to provide benchmarks of accuracy for the Roboflow models (02/21/2021), we ran tests across the following Roboflow Universe datasets:
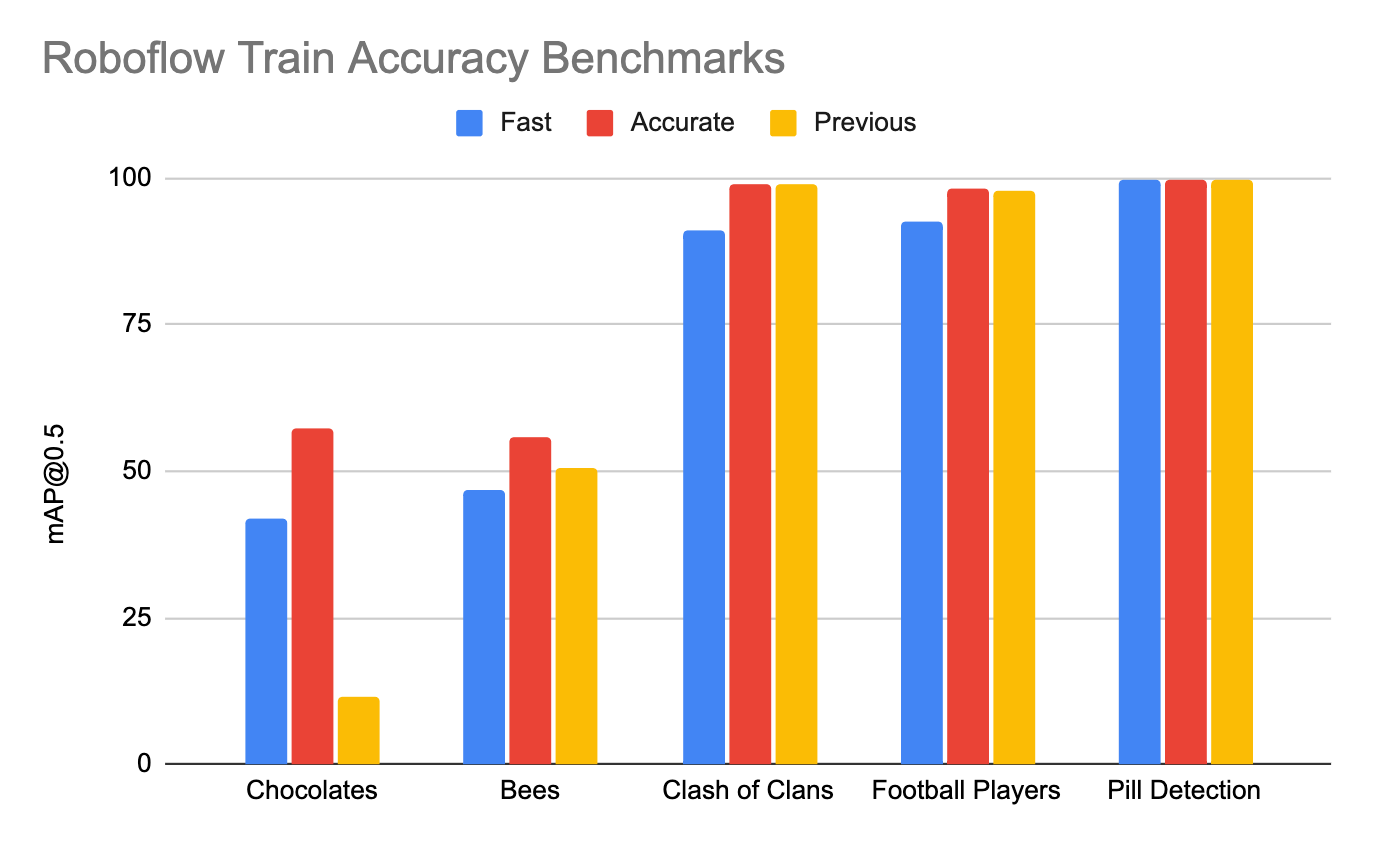
The main takeaway of these results is that if your models performance is saturated (greater than 95% mAP) you will not see much of an accuracy tradeoff. However, if your model still has some accuracy to gain (40-80% mAP), you should see accuracy improvements using the Accurate Roboflow Train model.
To know for certain how the model types will impact your custom model, you should run similar experiments on your custom data.
Inference Speed Tradeoffs
Inference speed is the time it takes for your model to make a prediction given an image as input. In academic papers, inference speed means the time it takes input tensors to pass through a neural network and yield outputs. In practice, inference speed includes all of the time from posting an image from an application to an inference routine and receiving well formatted predictions as a response - inclusive of any network latencies along the way. In this section, we benchmark practical inference speeds across a variety of Roboflow's deployment destinations with an open source utility repository - roboflow inference server benchmark.
- Roboflow Hosted Inference API - Roboflow hosts your model in the cloud.
- Web Browser - iPhone XR - Roboflow runs in web browsers, here on an iPhone XR.
- Enterprise CPU - Intel Xeon E - You can run Roboflow on your own CPUs. Here we benchmark on an Intel(R) Xeon(R) CPU E5-2686 v4 @ 2.30GHz.
- NVIDIA Jetson NX - You can run Roboflow on an edge Jetson. Here we test on the NVIDIA Jetson Xavier NX, Jetpack 4.5.
- Web Browser - Mac M1 Max - Roboflow runs in web browsers, here on a Mac M1 Max, Version 98.0.4758.102 (Official Build) (arm64).
- Enterprise GPU - NVIDIA K80 - You can run Roboflow on your own GPUs. Here we benchmark on an NVIDIA K80 on an AWS p2.xlarge instance.
- Enterprise GPU - NVIDIA V100 - Here we benchmark on an NVIDIA V100 on an AWS p3.2xlarge instance.
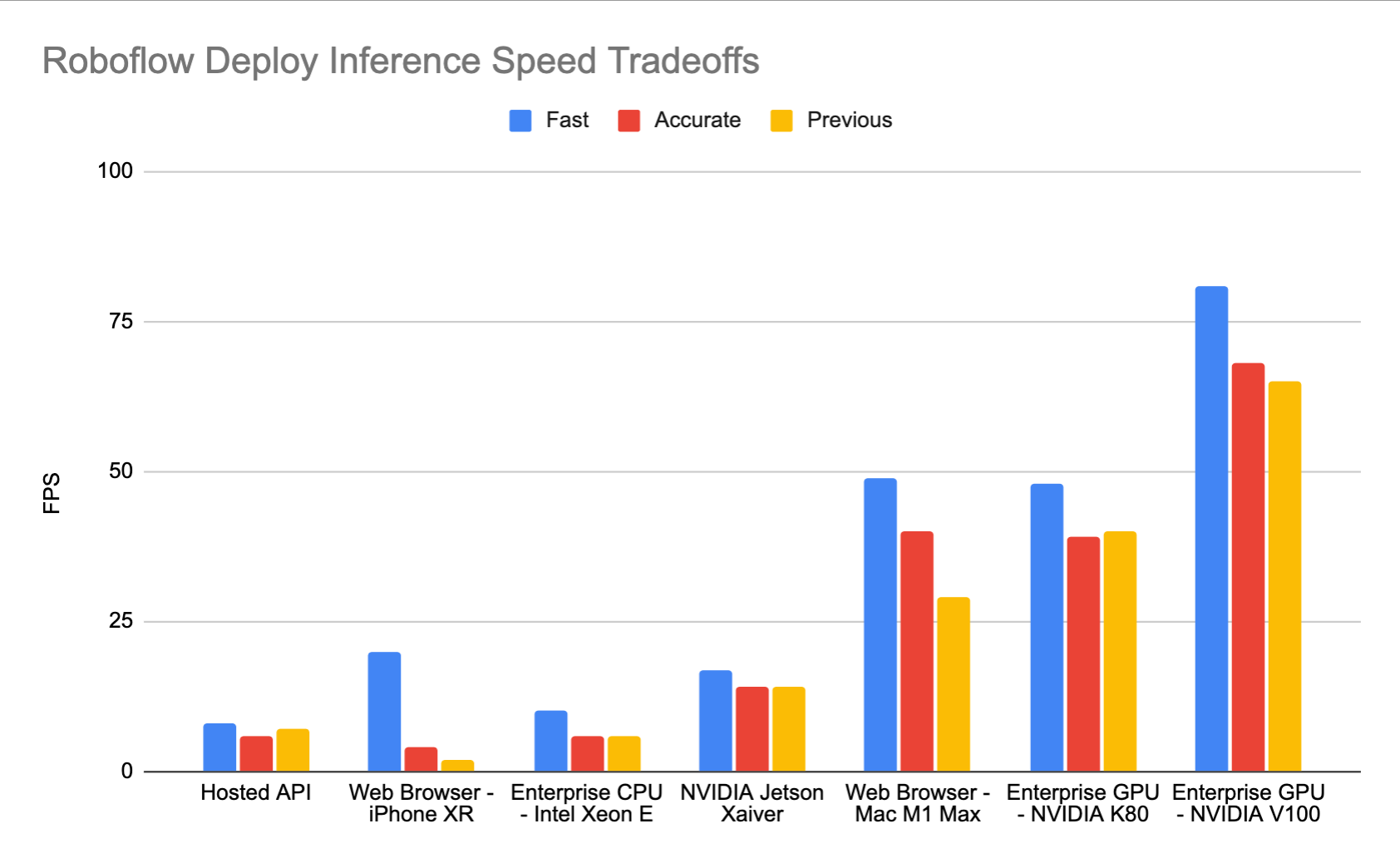
All of the estimates above are measured while processing single image frames, which is is required when you need realtime inference. If you can process frames in parallel, you can achieve much higher inference speeds. For example, with a 100 frame parallelism, we witnessed 300 FPS against the hosted inference API.
Inference speeds may vary with respect to hardware and custom models with different prediction behavior (such as costly NMS operations). To get the most exact estimate for your custom model, you should benchmark your model on your hardware.
You can learn more about the specifics of implementing Roboflow Deploy for your use case at https://docs.roboflow.com/inference.
Training Time Tradeoffs
Depending on your custom dataset, the Fast Roboflow Train model should train roughly twice as fast as the Accurate Roboflow Train model.
Conclusion
While you are prototyping your model, you should use the Roboflow Train Fast model.
If your model requires greater accuracy, you should use the Roboflow Train Accurate model.
If your application requires realtime inference on the edge, you should used the Roboflow Train Fast model.
Happy training! And of course, happy inferencing!
Cite this Post
Use the following entry to cite this post in your research:
Jacob Solawetz, Paul Guerrie. (Mar 8, 2022). What to Think About When Choosing Model Sizes. Roboflow Blog: https://blog.roboflow.com/computer-vision-model-tradeoff/