
Design never stays still; that is what is so magnetic about it. It evolves with new patterns, new paradigms, new creations, and new innovation. Computer vision is transforming our world at that same pace, quickly becoming one of the most revolutionary technologies and, in turn, introducing a new way of interacting with the world. Our job is to match that pace, embracing constant change and channeling it into tools empower and meet users where the future is headed.
We’re building the bridge between people and machines, turning the messy, visual world around us into things models can actually learn from. That's what makes design at Roboflow so compelling. In just the past month, our open source tools have been downloaded over 2.5 million times, and users have trained models on more than 94 million images — a scale that reflects how quickly this space is growing. Our mission is to make the world programmable, and our challenge (and opportunity) is to make that process feel intuitive, flexible, and fun.

A New Translation Layer
Designing for computer vision is particularly novel because it sits at the intersection of intuition and modeling. We’re not just building tools or a platform to democratize computer vision, we’re building a new translation layer that is about teaching with imagery rather than speech. The opportunity we have in front of us is an untapped frontier for pioneering new design patterns and interaction paradigms.
Cars that drive themselves. At-home, expert-level health and cancer diagnostics. Walking out of a store and instantly paying for your items. Dangers like fires identified and mitigated before any catastrophe. Innovations that have seemed unattainable are within our reach, all powered by vision, but there’s still work to be done to get us there.
Right now, we’re in the middle of a vision revolution. Models are learning to interpret more types of input, but the way they understand and learn from that input is fundamentally different from how humans do. We’re inherently visual creatures. When we look at a bushel of apples, we instantly process what matters, like which are different species, which are misshapen, and which might be starting to rot. When a model sees that same image, its understanding is completely different and much more general at baseline. But, it can learn to detect incredibly subtle patterns, like early signs of rot we wouldn’t catch with the naked eye; we just have to teach it what to look for.
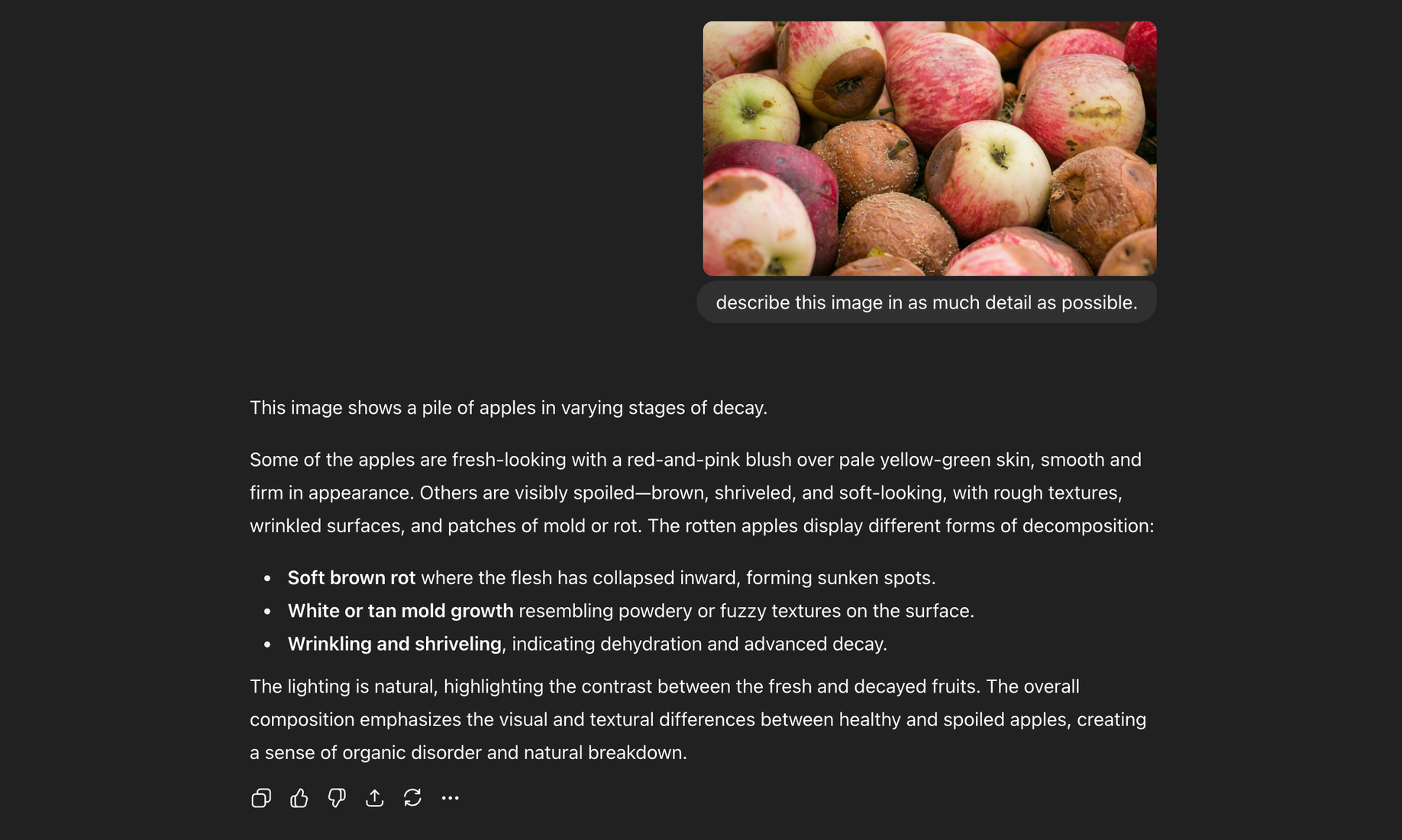
This is what makes designing for computer vision both a challenge and incredibly rewarding. Roboflow is effectively acting as the vehicle, as the translation, for users to teach models anything visual from calibrating cameras tracking the current play in a sports game, or inspecting solar panel efficiency via thermal imagery The entire world is visual and anything we can see, we can teach. The question is: how do we teach it to solve the problems we want it to? How can we craft an experience where users have a visual conversation with their model that is natural, even fun?
Visual Conversation
Our platform is where that translation layer comes to life. We provide an end-to-end toolset that allows users to source data from their own environments or tap into millions of images on Roboflow Universe, curate and annotate that data, train a model, evaluate its performance, and put it into production. They can act on the model’s outputs, monitor its performance, extract meaningful insights, and continue to iterate on the model from there. Making this entire process feel seamless is a challenge we work on every single day
One of the most addicting parts of our product to work on is our annotation interface. This is the most tactile touchpoint users have and where they communicate most directly with the model. At its inception, the tooling was primarily user-driven – manually drawing bounding boxes and polygons, with some AI assistance available after the user trained their first model. Then SAM changed the playing field entirely. We directly integrated the model into our tooling, supercharging and expediting polygon labeling by automatically detecting objects the user hovered over.
Box Prompting — A conversational labeling experience.
Smart Polygon — Our SAM-powered labeling tool.
Soon after, we introduced box prompting, our most conversational take on labeling yet, where the user can label their objects of interest using model-assisted detection. As the user labels more, the model learns and fine-tunes itself in real time, making itself more accurate and the entire experience seamless. This unlocked the huge potential for us to push the capabilities even further, with new experimental products in the works to take this concept and amplify it. After months of constant ideation, iteration, and user testing, we’re now launching Roboflow Rapid, the next major exploration into making labeling and model training as instant and magical as possible.
Roboflow Rapid — Our new model creation experience.
That's just a sliver of the work we're doing at Roboflow. The computer vision landscape presents a foreign, expansive puzzle – one where we have to continuously iterate and challenge our assumptions to ensure we’re bridging the gap between technical and natural in the most effective way possible. For our designers, we're always thinking of how to:
- Improve problem framing and create a more intuitive, natural pipeline
- Help users build better models, faster
- Ensure interfaces are clean and purpose driven
Underpinning all of this is a consistent, ever present part of our design work: thinking about how we present concepts for users to digest and understand by not just stating what they are, but what they mean, and what the user can do with them. Our users span every level of experience, from beginner to expert, so it is a necessity to package concepts that allow opt-in complexity to ensure our platform meets users where they are and grows with them.
Opt-In Educational Complexity
Some users enter the platform knowing exactly what their goals: they want to optimize their edge deployments, train with a specific model architecture, or work with a particular export format. However, most are newer to computer vision and are just learning how to label. In order to make computer vision effectively accessible to all, we need to craft an opinionated platform which allows users to choose their desired complexity. This is something we weave into the fabric of Roboflow every single day.
The immense amount of transformation the Roboflow platform has undergone since launch is a strong testament to this. Even in this past quarter, we recently partnered with a variety of users to test and roll-out new tooling for evaluating models’ performance and easily diagnosing potential improvements with a recommendation system. The features also speak to more experienced users, providing powerful classic machine-learning tooling (like a confusion matrix) to navigate their model’s performance in-depth. During user testing, it became obvious how excited participants were about tooling that both allowed them to better understand their models AND met them where they were across all ranges of expertise.
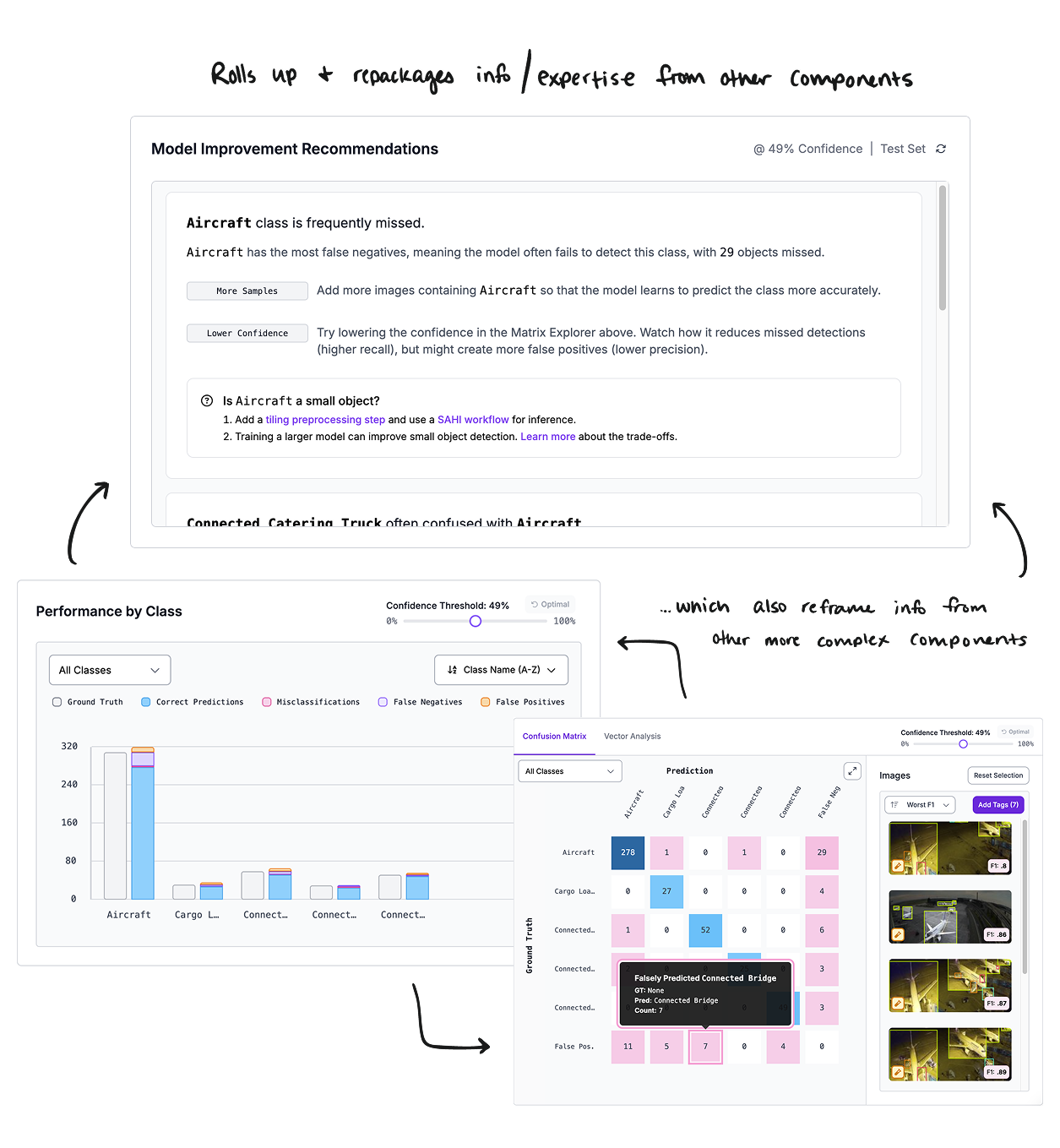
This approach also helps our more novice users learn techniques with more complex concepts, growing their knowledge and leveling up their overall confidence with computer vision. We’ve seen users that have been with Roboflow for years who started as beginners and now consider themselves computer vision experts (with some even changing their job titles to reflect that). We’re embracing this full send – from how we name features, to crafting nascent iterative model training tooling to simplify the process, to making our current workflow builder more flexible and approachable.
The Known Unknowns
The fact that the computer vision field is an ever-changing green space can be daunting, but at Roboflow, it’s exhilarating. With the break-neck pace of advancements, computer vision as it is now will not stay as it is for even for an instant. Roboflow is becoming part of that driving force by being first party contributors to model advancements and developing RF-DETR, a state-of-the-art, real-time object detection and segmentation model that outperforms all existing models on real world datasets
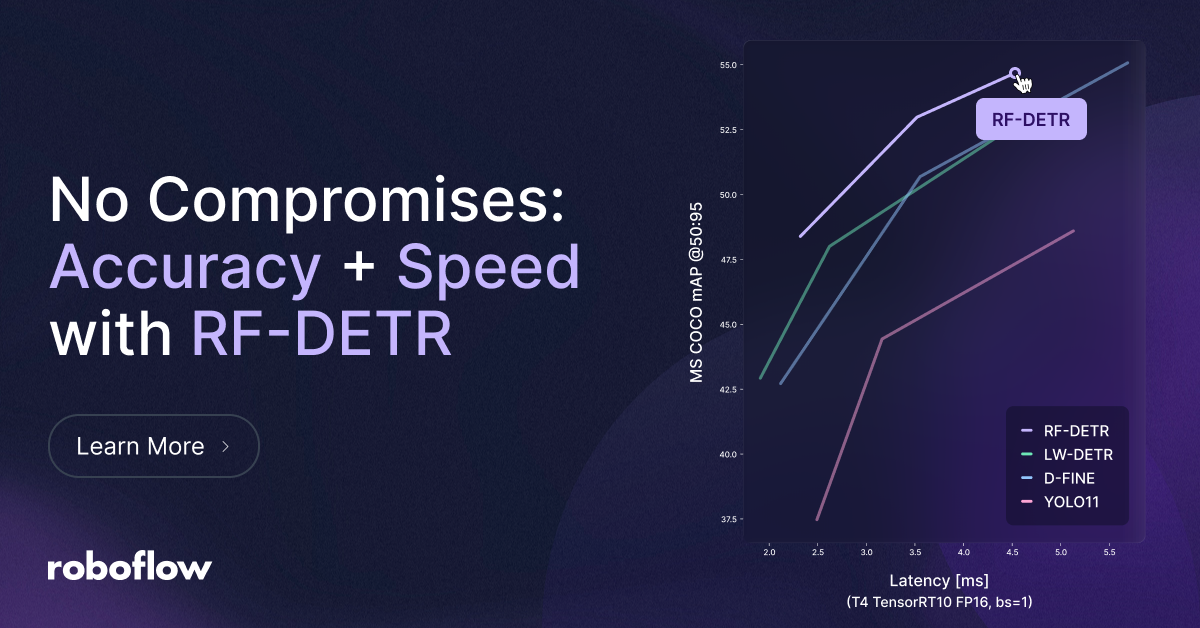
That’s just scratching the surface. The progress and introduction of multimodal models is changing how we can interact with and enhance computer vision models. Vision transformers (a specific kind of neural net architecture) are making way for more generalizable models. Hardware is becoming more accessible and models are becoming more optimized for local devices. There are endless examples of how the space is changing.
This constant evolution means our design work can’t just consider and incorporate what exists already, but it also has to anticipate what might exist in the future. The moving target of what comes next means that the models we integrate into our platform, the tools that we can develop and leverage, and the workflows that users want and benefit the most from, can change in a matter of weeks. This isn’t a detriment to us or our process, but an opportunity. We capitalize on this in ways like being the first platform to integrate groundbreaking models such as Segment Anything (and its subsequent releases) less than 24 hours after first release. It’s exhilarating and fulfilling. Our reward is the fact that our users are the first to access state of the art technologies and tooling.
Design as Infrastructure
Designing in this kind of environment requires flexibility in process, and the possibility of change woven into the very foundations of our mindset. Interfaces must be modular enough to support new model types and evolve with features without breaking the mental model for the user. Terminology and visual systems need to expand gracefully and naturally incorporate new items (and retire old) such that they stay concise and approachable. We have to create experiences resilient to change, and designers must know where things should flex to produce the best experience for our users.
We approach this by building with adaptability in mind: developing a componentized system, abstracting our patterns for broad application, and crafting a design language that can sing across modalities. There is a balance we aim to strike between being opinionated without being overtly rigid in favor of patterns that can branch and accommodate, leading users where they want to go. Often, our users are learning alongside the model.
In a field where the frontier moves daily, good design isn’t static, it’s infrastructural. It’s the scaffolding that holds space for what's effective now and anticipating future potentials. We need to recognize that what we build now might be rendered completely obsolete soon; but that‘s where true opportunity lays to create genuinely rewarding and innovative new experiences.
Growing with Change
Being a designer at Roboflow means being at the edge. Learning new technologies and concepts, broadening our own understanding of what’s possible with visual understanding, being curious, asking questions, and pitching new directions. Because of how quickly the status quo changes in computer vision, our designs need to live and breathe with us, and with us, our users who span across industries, expertise, and applications that we haven’t even encountered yet.
We don’t just create experiences, we build them. Designers are embedded within our product teams, pairing closely with engineers and often owning front-end development or even shipping core features themselves. Being integrated and active in the entire development process is essential, allowing us to move faster, make better decisions in context, and design with implementation in mind from the start. We lean into being technical as a strong differentiator because it allows us to gain richer understanding of what we’re working with, sharpens the quality of what we ship, and deepens our empathy for our developer-centric user base.
Design, at the end of the day, is rooted in humanity. Even as we work with cutting-edge models and complex systems, our responsibility is to make that technology accessible, intuitive, and meaningful to real people doing real work. The researchers fine-tuning their models, the hobbyist or student just learning computer vision and crafting their first models, the teams deploying their models in the field. Our job is to help them actualize their ideas and applications with ease—with delight, even—at the realization that what they want to do with computer vision is possible.
For Roboflow, design isn’t an afterthought or the aesthetic icing on top. It is an active, pivotal part of our process and how we think about shaping our product and the future of computer vision: with care, curiosity, humanity, and the users as our grounding force.

Cite this Post
Use the following entry to cite this post in your research:
Korryn Resetar. (Oct 24, 2025). Design @ Roboflow. Roboflow Blog: https://blog.roboflow.com/design-roboflow/