
I love the feeling of falling into the "zone" when I'm working. An hour zips by like a minute while I destroy my digital checklist. But then I notice that chalky taste in my mouth. My stomach churns. I've forgotten to drink water again.
The funny thing is, my computer has been watching me this whole time through its webcam. What if it could actually do something useful with that information? What if it could tell when I'm drinking and remind me when I'm not?
So I built Hydrovisor, a web app that watches for actual drinking behavior and reminds you to hydrate based on what it sees, not just on a timer.
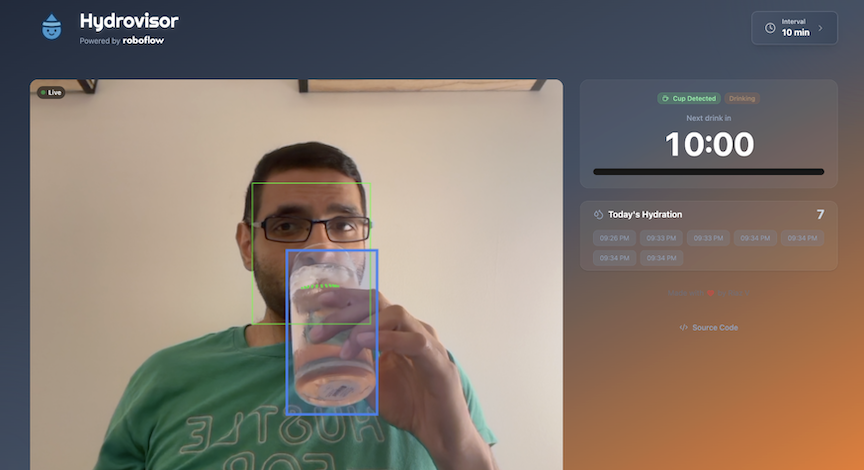
Automated Drink Detection: The Computer Vision Challenge
Detecting whether someone is drinking is trickier than you'd think. You need to figure out:
- Object detection - Is there a cup, glass, or bottle in the frame? What if there are several?
- Face tracking - Where's the person's mouth exactly?
- Spatial relationships - Is that cup actually near the mouth or just sitting on the desk?
- Temporal patterns - Are they drinking or just moving the cup past their face?
You could try training one model to do everything, but I went with something simpler: use the best tool for each job. Roboflow for finding cups and bottles, MediaPipe for tracking faces. Let each model do what it's good at.
How to Build the Drinking Detection System
For face tracking, Google's FaceMesh was the obvious choice. They've spent millions developing it, and it can track 468 facial landmarks with incredible precision. Why reinvent that wheel?
Detecting drinks was a different story. I needed to train my own model, which meant finding training data. Roboflow Universe was a goldmine here, with millions of community-uploaded images to get started.
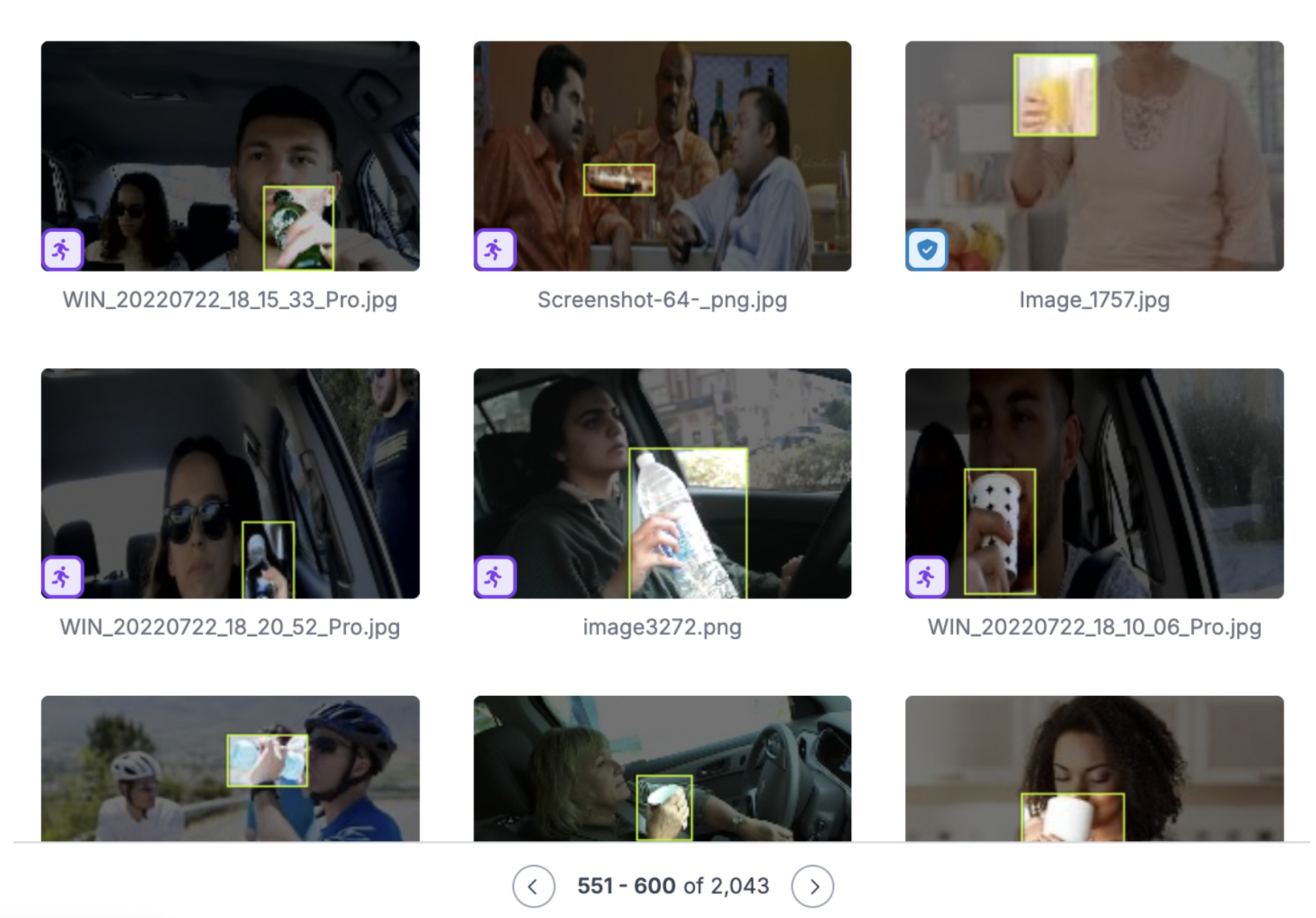
My coworkers were amazing and sent videos of themselves actually drinking water at their desks. This real-world data made all the difference.
The dataset evolution was interesting. Started with stock photos of people drinking from glasses. Total failure in the real world. Added coworker videos with their actual coffee mugs and water bottles. Better. Threw in static shots of various cups and bottles for good measure. After several iterations, I landed on 2,043 images that finally gave me a model that worked across different environments.
The model's publicly available if you want to play with it. But having a model is only half the battle. Now I needed to build an app that could run all day without killing someone's laptop or racking up cloud bills.
Why Roboflow Inference.js?
I had some specific requirements. The app needed to run continuously without being annoying, expensive, or complicated to set up. Roboflow's Inference.js checked all the boxes.
1. Runs on Your Machine, Not Mine
Inference.js uses your browser and your computer's processing power. No cloud servers, no monthly bills. I can offer Hydrovisor free forever because I'm not paying for GPUs in some data center.
// Roboflow Inference.js runs entirely in the browser
const inferenceEngine = new InferenceEngine();
const workerId = await inferenceEngine.startWorker(
"beverage-detection-model",
2, // model version
"YOUR_PUBLISHABLE_KEY"
);2. Works Instantly
Visit the website, allow camera access, start tracking hydration. That's it. No app downloads, no Python environments, no CUDA installations. If you can browse Instagram, you can use Hydrovisor.
// Simply import from npm - no CDN scripts or manual downloads needed
import { InferenceEngine, CVImage } from 'inferencejs';
// That's it! The library handles all the heavy lifting
// No WASM files to manually load, no model downloads to manage3. Slow is Actually Fine
Here's something counterintuitive: you don't need blazing fast inference for drinking detection. It takes several seconds to lift a cup to your mouth and drink. Running inference at 5 FPS catches that just fine, and it means the app can run all day without turning your laptop into a space heater.
// Configure frame rates for optimal performance without overloading the system
export const FRAME_RATES = {
faceDetection: 15, // Face tracking needs higher FPS for smooth UX
objectDetection: 5, // Object detection can run at lower FPS to save resources
} as const;
// Use requestAnimationFrame with frame rate limiting
const OBJECT_FRAME_INTERVAL = 1000 / FRAME_RATES.objectDetection;
let lastFrameTime = 0;
const detectObjects = async (currentTime) => {
// Only process if enough time has passed (200ms for 5 FPS)
if (currentTime - lastFrameTime < OBJECT_FRAME_INTERVAL) {
requestAnimationFrame(detectObjects);
return;
}
lastFrameTime = currentTime;
// Run inference here
const detections = await inferenceEngine.infer(workerId, image);
requestAnimationFrame(detectObjects);
};The Tech Stack
With Inference.js as the foundation, I kept everything else simple and mainstream:
- React 19 with TypeScript for a robust, type-safe frontend
- Roboflow Inference.js for real-time object detection
- MediaPipe Face Mesh for facial landmark tracking
- Zustand for efficient state management
- Framer Motion for smooth animations
Making It Work: Object Detection
First up, finding the drinks. Roboflow's Inference.js handles this part:
const detectObjects = async (currentTime: number) => {
// Frame rate limiting at 5 FPS
if (currentTime - lastFrameTime < OBJECT_FRAME_INTERVAL) {
requestAnimationFrame(detectObjects);
return;
}
const image = new CVImage(videoElement);
const detections = await inferenceEngine.infer(workerId, image);
// Filter for cups, glasses, bottles
const drinkingObjects = detections.filter((d: Detection) =>
DETECTION_CLASSES.includes(d.class.toLowerCase())
);
if (drinkingObjects.length > 0) {
// Keep only the largest cup (by area) for tracking
const largestCup = drinkingObjects.reduce((prev, current) => {
const prevArea = prev.bbox.width * prev.bbox.height;
const currentArea = current.bbox.width * current.bbox.height;
return currentArea > prevArea ? current : prev;
});
setObjectDetected([largestCup]);
}
requestAnimationFrame(detectObjects);
};Finding Faces with MediaPipe
While Roboflow finds the cups, MediaPipe tracks where your mouth is:
// Key MediaPipe landmark indices for lips
const LIP_LANDMARKS = {
upperLipTop: 13,
lowerLipBottom: 16,
leftCorner: 61,
rightCorner: 291,
...
};
export function getLipBoundingBox(faceKeypoints: Point[]): BoundingBox {
// Extract lip points
const lipPoints = [
faceKeypoints[13], faceKeypoints[16],
faceKeypoints[61], faceKeypoints[291]
];
// Calculate bounding box with 20% padding
const xs = lipPoints.map(p => p.x);
const ys = lipPoints.map(p => p.y);
const width = (Math.max(...xs) - Math.min(...xs)) * 1.4;
const height = (Math.max(...ys) - Math.min(...ys)) * 1.4;
return {
x: (Math.min(...xs) + Math.max(...xs)) / 2,
y: (Math.min(...ys) + Math.max(...ys)) / 2,
width, height
};
}Putting It Together: The Drinking Detection
Now for the fun part. We have cups, we have faces, but are they actually drinking? We use Intersection over Union (IoU) to figure out if the cup is near the mouth:
export function calculateIoU(box1: BoundingBox, box2: BoundingBox): number {
// Convert to rectangles and calculate intersection
const rect1 = boundingBoxToRectangle(box1);
const rect2 = boundingBoxToRectangle(box2);
const xOverlap = Math.max(0,
Math.min(rect1.right, rect2.right) - Math.max(rect1.left, rect2.left));
const yOverlap = Math.max(0,
Math.min(rect1.bottom, rect2.bottom) - Math.max(rect1.top, rect2.top));
const intersectionArea = xOverlap * yOverlap;
const unionArea = box1.width * box1.height + box2.width * box2.height - intersectionArea;
return intersectionArea / unionArea;
}But here's the thing: drinking takes time. You lift the cup, drink, put it down. We need to handle that whole motion without getting confused by brief moments when detection fails:
const OVERLAP_THRESHOLD = 0.02; // 2% IoU threshold
const DEBOUNCE_MS = 500; // Continue for 500ms after last detection
const MIN_DRINKING_FRAMES = 2; // Minimum frames to start drinking
// Track overlap over time with refs
if (isOverlapping) {
lastOverlapTimeRef.current = now;
overlapFrameCountRef.current++;
// Start drinking after minimum frames
if (!isDrinking && overlapFrameCountRef.current >= MIN_DRINKING_FRAMES) {
startDrinking();
}
} else if (isDrinking) {
const timeSinceLastOverlap = now - lastOverlapTimeRef.current;
// Stop only after 500ms without overlap
if (timeSinceLastOverlap > DEBOUNCE_MS) {
stopDrinking();
overlapFrameCountRef.current = 0;
}
}This smoothing is crucial. Without it, the app would constantly flip between "drinking" and "not drinking" as you move the cup around.
The Multiple Cups Problem
What if there are multiple drinks on your desk? Simple solution that actually works: track the biggest one. The cup you're drinking from is usually closer to the camera, so it appears larger:
// Find the largest cup by area
const largestCup = drinkingObjects.reduce((prev, current) => {
const prevArea = prev.bbox.width * prev.bbox.height;
const currentArea = current.bbox.width * current.bbox.height;
return currentArea > prevArea ? current : prev;
});What I Learned: Real-Time Drink Detection with Computer Vision
Building Hydrovisor proved that you don't need massive models or expensive infrastructure to solve real problems with computer vision. Sometimes the best solution is combining tools that already work well.
A few takeaways:
- Let specialized models do what they're good at instead of forcing one model to do everything
- Real-world interactions are messy; temporal smoothing is your friend
- Simple heuristics beat complex logic more often than you'd think
- 5 FPS is plenty when you're detecting actions that take seconds
The whole thing runs in your browser, costs nothing to use, and actually helps people stay hydrated. No data leaves your computer, no monthly bills, just a reminder to drink water when you need it.
Try it yourself at hydrovisor.live and explore the source code at github.com/rvirani1/hydrovisor. Never forget to hydrate again!
Written by Riaz Virani
Cite this Post
Use the following entry to cite this post in your research:
Riaz Virani. (Sep 16, 2025). Real-Time Drinking Detection: Building Hydrovisor. Roboflow Blog: https://blog.roboflow.com/drinking-detection/