
Paint.wtf is an online drawing game built by Roboflow and Booste that uses OpenAI's CLIP model to score user submissions against absurdist text prompts, ranking drawings by how closely their image embeddings match the prompt's text embedding. GPT-2 generated the bulk of the prompts from a small human-written seed set, while CLIP also handled content moderation by comparing submissions against NSFW topic embeddings. The game drew over 150,000 submissions in its first week, reaching nearly 3 per second at peak, and offers a practical demonstration of what CLIP can and cannot understand about illustrations.
Paint.wtf is an online game that uses AI to score user-submitted digital drawings to zany prompts like, "Draw a giraffe in the arctic" or "Draw a bumblebee loves capitalism." It's Cards Against Humanity meets Microsoft Paint.

Paint.wtf became an internet sensation. In the week of its launch, players submitted over 100,000 drawings – peaking at nearly 3 per submissions per second. It made it to the front page of Hackers News and r/InternetIsBeautiful.


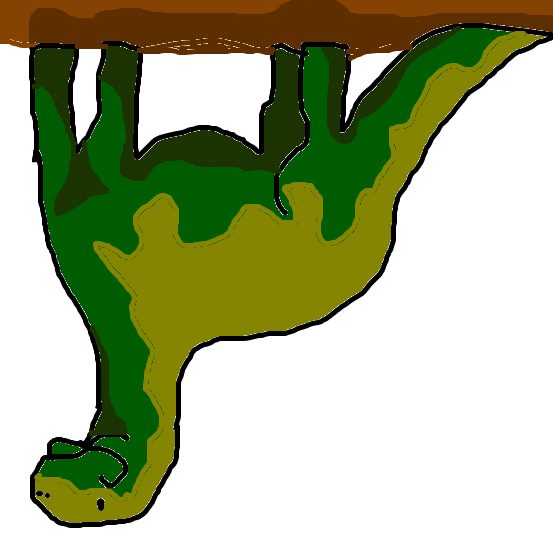
A few of our favorites among the 150k+ submissions: The World's Most Fabulous Monster, A Giraffe in the Arctic, An Upside Down Dinosaur.
We (Roboflow) built Paint with our friends at Booste to play with using OpenAI's CLIP model. We challenged ourselves to build something in a weekend shortly after OpenAI open sourced CLIP.
This post walks through how we used AI to build a popular internet game.
Paint.wtf at a Glance: An AI Sandwich with Humans in the Middle
At a high level, Paint flows the following way:
- A user sees a silly prompt to draw
- The user draws that prompt
- Paint scores that user's drawing and assigns a ranking
The prompts are deliberately silly. Users are prompted to draw "a shark in a barrel," "the world's fastest frog," "a superhero who rides a bike," and so much more.
How'd we come up with so many creative prompts? We didn't. We came up with an initial set and used AI to generate the rest. We wrote the first ten prompts and passed them to GPT-2, a generative text model, to receive thousands more. GPT-2 came up with prompts we certainly wouldn't have considered. The GPT generated prompts did require a human once-over to ensure the game encouraged fun.
The user is then prompted to draw the prompt. To handle drawing in the browser, we made use of Literally Canvas, which gives Microsoft Paint-like functionality.

Once a user submits their drawing, Paint scores it. This is where we utilize CLIP. CLIP's magic is it is the largest model (to date) trained on image-text pairs. That means CLIP does a really good job of mapping text to images. In our case, we want to map: (1) the text prompt to what image CLIP thinks that prompt should look like and (2) the user submitted drawing to what image representations CLIP knows. The closer (2) is to (1), the higher the user's score.
Before proceeding, let's break CLIP down a bit further. OpenAI trained CLIP on 400 million image and text pairs. In doing so, OpenAI taught a model the embeddings for what image features and text features "go together." Those embeddings are feature vectors (arrays) that are fairly meaningless to humans but enable numeric representation of images and text – and numeric representation means we can perform mathematical operations like cosine similarity. One can provide an arbitrary snippet of text to CLIP and receive back an array for the image embeddings that are best aligned to that text. Similarly, one can provide an image to CLIP and learn how CLIP would embed that image in its feature space. Knowing the embeddings and features for a broad range of images enables one to, for example, identify most visually similar images.
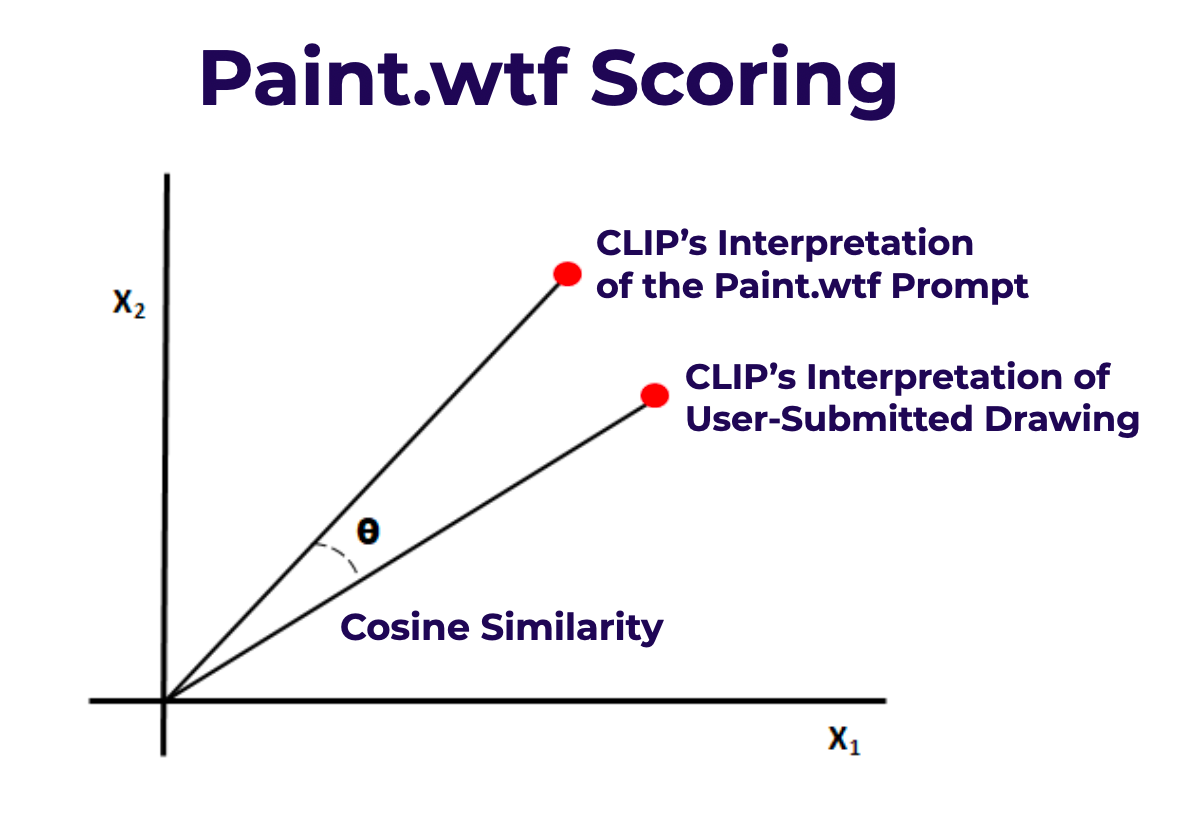
Again, in our use case, we ask CLIP, "What image embedding matches most closely to X arbitrary text?" where X is the prompt. We then ask CLIP, "What embeddings would you assign to Y arbitrary image" where Y is the user submitted drawing. The cosine similarity among the two embeddings is the score, where the lowest distance is ranked highest.
Paint.wtf is an AI sandwich: AI generates the prompt, a human draws that prompt, and then AI scores the result.

A few of our favorites among the 150k+ submissions: A Raccoon Driving a Tractor, a Ninja Riding a Bicycle, an Exploding Pig.
Building an MVP Version of paint.wtf in 50 Lines of Code that Works with Your Webcam
You can build and run a local version of paint.wtf in 50 lines of Python code. (For a live walkthrough, checkout our talk at AI Engineer on YouTube.)
We'll make use of open source libraries like OpenCV (for interacting with our webcam), CLIP (for embedding user images and paint prompts), andinference (for serving our model).
To get started, ensure you have a free Roboflow API key set in your .env directory. This allows us to authenticate and pull down any of the 50,000 open source models compatible with inference, including CLIP. Your .env should look like this:
API_KEY=your_api_key_hereLet's now provide the full script and then break down each part. Here's the final script for running paint.wtf locally on your webcam.
import cv2
import inference
from inference.models import Clip # add
from inference.core.utils.postprocess import cosine_similarity
clip = Clip()
prompt = "a gorilla gardening with grapes"
text_embedding = clip.embed_text(prompt)
def render(result, image):
# get the cosine similarity between the prompt & the image
similarity = cosine_similarity(result["embeddings"][0], text_embedding[0])
# scale the result to 0-100 based on heuristic (~the best & worst values I've observed)
range = (0.15, 0.40)
similarity = (similarity-range[0])/(range[1]-range[0])
similarity = max(min(similarity, 1), 0)*100
# print the similarity
text = f"{similarity:.1f}%"
cv2.putText(image, text, (10, 310), cv2.FONT_HERSHEY_SIMPLEX,
12, (255, 255, 255), 30)
cv2.putText(image, text, (10, 310),
cv2.FONT_HERSHEY_SIMPLEX, 12, (206, 6, 103), 16)
# print the prompt
cv2.putText(image, prompt, (20, 1050),
cv2.FONT_HERSHEY_SIMPLEX, 2, (255, 255, 255), 10)
cv2.putText(image, prompt, (20, 1050),
cv2.FONT_HERSHEY_SIMPLEX, 2, (206, 6, 103), 5)
# display the image
cv2.imshow("CLIP", image)
cv2.waitKey(1)
inference.Stream(
source = 2,
model = clip,
use_main_thread = True,
output_channel_order = "BGR",
on_prediction = render
)Running this enables us to produce an output like the below:

Let's break down the 46 lines of code.
The first lines import the open source libraries we're using: OpenCV for interacting with our webcam and inference for serving over 50,000 open source models like CLIP.
We then instantiate the Clip() class. This will enable us to make use of CLIP for embedding text (the prompt from the game) and the image a user holds up to their webcam. We define an example prompt the user will draw. (In this case, a gorilla gardening with grapes.)
The render() function appears lengthy, though it is deceivingly simple. It does three things: (1) compares the cosine similarity of the image embedding to the text embedding (2) scales CLIP similarity scores from 0 to 100 (3) displays the similarity score and the prompt in purple text with a white shadow. For (2), scaling the similarity is not a requisite step for the game to work. Because CLIP's similarity scores are often between ~0.15 to ~0.40 overall, we will scale 0.15 to 0 and 0.40 to 100. This helps exaggerate the displayed difference in the user's webcam image.
The last portion of code makes use of inference to stream input from a camera. Here, it is key to set source to your webcam source with OpenCV. (If you run the script and your webcam isn't found, attempt to change to source=webcam or source=1). We set the model we're using to CLIP (as the open source inference server can support many other foundation models). We tell OpenCV to use the main thread for our process and to flip color channels to BGR (this is an artifact of OpenCV display). Lastly, when the Stream function has predictions, we'll pass render to show them on screen.
In 46 lines of Python, you have paint.wtf running live with your webcam.
CLIP: Discoveries, Issues, and Resolutions
In running what we believe to be the largest game with CLIP (yielding a dataset of 150,000+ images), we encountered a number a fascinating issues and discoveries in our process.
CLIP Understands Illustrations
For Paint to work at all, CLIP would have to generalize not only to any arbitrary image, but to any arbitrary digital image. All user submissions were created via a Microsoft Paint-like interface. We truly didn't know if that meant we could reliably have CLIP understand what the images contained.
Surprisingly, CLIP does remarkably well – even on relatively sparse user-submitted images.

CLIP Can Read
One of the very first discoveries our users exposed to us is that CLIP has an understanding of handwriting. This means that a user could simply write the prompt as text on the canvas and rank relatively highly on the leaderboard.
This so-called typography attack has now been well-documented on CLIP.
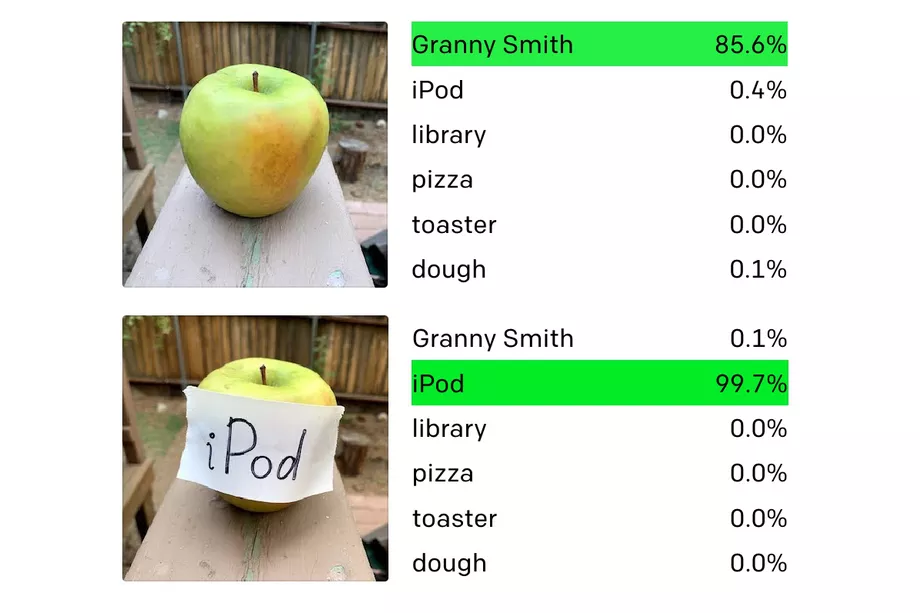
We discovered and built a solution before the now-viral "Apple iPod" went viral. We apply a text penalty to any image that appears to have handwriting in it. How do we know if an image has handwriting? You guessed it – we ask CLIP. Specifically, we calculate the embedding for, "An image that contains handwriting." If the user submitted drawing ranks more closely to the embedding for handwriting than it does for the target prompt, we can penalize the submission by a factor of the submission. (This strategy requires careful tuning: a number of well-drawn submissions also incorporate text, but in a benign way. As an example, check the "World's Most Fabulous Monster" image at the top of this post – the monster is on the cover of Vogue magazine.)
CLIP Can Moderate Content
We built a tool that allows anyone on the internet to make a drawing. As you'd expect, we did not always receive the cleanest of imagery.
To regulate submissions, we can check if a given drawing ranks more closely to a target NSFW topic than the submission does to the actual prompt's embedding. If the user's drawing is more similar to, say, "A drawing of nudity" than "A drawing of an alien that can teleport," we can conclude it likely shouldn't be included in the leaderboard and so we censor it automatically.
Verdict: Play Paint.wtf and Play with CLIP
Our experience playing with CLIP allowed us to scratch the surface on what is possible and exposed blind spots in CLIP's understanding. By trying Paint.wtf, you, too, can get a sense of its power.



A few of our favorites among the 150k+ submissions: The World's Most Fabulous Monster, An Exploding Pig, A Cute Raccoon Using a Computer.
Try playing Paint.wtf as an icebreaker in your next stand up. Good luck!
Cite this Post
Use the following entry to cite this post in your research:
Joseph Nelson. (Mar 14, 2021). How We Built Paint.wtf, an AI Game with 150,000+ Submissions that Judges Your Art. Roboflow Blog: https://blog.roboflow.com/how-we-built-paint-wtf-an-ai-that-judges-your-art-100-000-submissions/