
Thank you to Prof. Luigi Laura and Mirko Cangiano for sharing their research process and results to be adapted into this post for others to learn from and implement.
Comedy is a highly valued human skill, as it shows a sign of intelligence and creativity, and it is this creativity that to date is one of the greatest challenges for artificial intelligence. Comedy requires linguistic skill and knowledge of the world.
With the power of modern computer vision technology, we can now identify the contents of comic strips, one of the many forms of comedic media. We can find the presence of certain characters in a comic and we can use that data to analyze how often characters appear.
In this tutorial, we’re going to talk through:
- A history of analyzing comedy with computers.
- Defining our problem to identify and classify characters in the Peanut comic strip.
- Using Roboflow to identify the presence of characters in Peanuts.
By the end of this post, you'll understand how to create an object detection model for digital media assets, which can generate a result like this:

The same principles we discuss can be applied to a myriad of other use cases in multimedia object identification, from finding the representation of characters in an archive to inspire new ideas all the way to improving the searchability of media.
Let’s begin discussing object identification with computer vision.
A history of analyzing comedy with computers
In 2016, L.B.Chilton, J. Landay, D.S.Weld, through their publication "A microtask workflow for writing news satire," presented work on automatic comedy generation by analyzing a dataset of satirical jokes from The Onion. The result obtained was the ability to break down the creation of humor into seven types of microtasks ranging from identifying entities and aspects in an input title, to articulating associations and beliefs.
In fact, the developed project decomposed the problems into a workflow for improvement to provide the following inputs:
- A survey of humor research and writing processes
- Seven new microtasks
- Example-based tutorials that teach humor
- An innovative workflow
- HumorTool implementation
Beyond comedy, in the scientific community of artificial intelligence, the idea arose to study techniques and methods that could also be applied to the branch of creativity in comic book making.
In 2017, a study was conducted to analyze digitized comics. This was to help their creation in digital form and/or to improve the user experience. The analysis involved integrating within it the phase of component extraction, style analysis, and finally content analysis.
In the authors' proposed work, the goal was to identify characters, considered one of the most difficult parts, because the balloons (area that delimits the text), panels or texts are semi-structured components. This feature is due to the fact that comic book authors are free to draw the characters in the shapes they see fit, although they follow conventions that are adopted to help the reader.
Hand-drawn comic strips have greater deformation and are more variable. For this reason, very little work exists on the detection of characters belonging to the world of comic books.
Analysis of this problem and prior research indicates that two fields of artificial intelligence should be used:
- Natural language processing for texts and;
- Computer vision for understanding drawings, characters, places etc.
The high variety of drawings with the added lack of labeled data make it difficult to work on comic strips compared to natural images. This complicates the research, which contains three main steps:
- Content analysis: obtaining information of raw images and extracting descriptions of structures.
- Content generation and adaptation: comics used as input or output for content creation or modification.
- User interaction: analysis of human behavior based on content.
Comic book genres show non-human characters. This makes segmentation and recognition work even more complex, in addition to the presence of some inserted lines to express possible emotions of the characters.
Solving comic book recognition with computer vision
The project, developed during a master's thesis work for Uninettuno University, and with co-author Professor Luigi Laura, involved testing the best subject recognition and classification solution within Peanuts, one of the world's most famous comics.
To arrive at a solution, the project tried three different approaches:
- Using Haar Cascade Classification
- Using a custom-built Convolutional Neural Network
- Using YOLO trained on Roboflow
Out of these three solutions, the YOLO model trained on Roboflow was the most effective. In the section below, each solution is discussed weighing their merits and drawbacks.

The first solution: Using Haar Cascade Classification
In a first solution, it was decided to try applying the Haar Cascade Classification, for which the project authors performed dataset creation, annotation and character recognition training from scratch.
Two separate sets of examples must be created for the application of the Haar Cascade. One set contains a set of positive images, which will be needed in training as positive samples. The other set contains negative images containing all examples that a discriminator should have learned not to recognize.
Having divided the set of examples we made use of OpenCV's annotation framework, which created a text file containing the image directory, the number of annotated samples, and the pixel position of the region of interest. From this point on we generated a vector file to be given impasto the train phase where we set a set of parameters to tell the Haar Cascade Train how it should train. The result obtained was not entirely satisfactory for object recognition as false positives are produced, but also several false negatives.
The image below illustrates how some characters were identified correctly, but there were many items which were incorrectly annotated. In some cases, bounding boxes were significantly larger than the item they represented, which reduces their utility:


Next: Using a custom-built CNN
With this approach in mind, the project authors went on to create a CNN network that used the following components:
- Two convolutional layers;
- Two MaxPooling layers;
- One Flatten layer and;
- Two Dense layers.
The classifier was implemented as a binary classification network, and a generator to implement the number of positive examples. Image augmentation was applied to increase sample size and the variety of data in the dataset.
Although with excellent results for the classification phase, the recognition phase did not fully satisfy the requirements. With that said, the project authors think that with more images and different parameters, object detection could be improved.
In this example, Snoopy was identified:


But in this example of a car, Snoopy was also identified:


The final solution: Using YOLO with Roboflow
Following the first experimentation the authors went in search of a new solution that is much closer to the latest innovations in the field of computer vision. The solution is YOLOv5, which is composed of several models that allows us to recognize and classify by processing the input entered into it once.
To train their YOLO model, the project authors decided to use Roboflow. The authors said “Roboflow provided us with an easy to use platform that supported us in all the tasks we had to face. Unlike the first solution we experimented with in which we had to first create the dataset and then use it for training, with the platform provided by Roboflow we have everything at our fingertips.”
In order to label images, various tools could have been used. But, Roboflow provides an end-to-end experience with many advantages that sped up the time to train the YOLO model. The reasons cited by the project authors were:
- Online tool, of which no installation is required, easy to use, zero computational cost to the local machine
- Data can be private, public and shared with other people in the working group. In the case of choosing private data, Roboflow has no access to it without permission
- Super efficient support
- Various tools to support the work with the possibility of implementing the source dataset with various options
The tools that proved most useful for the purpose of the project included:
- Assisted labeling (to speed up the annotation process)
- Bounding box tool (to easily annotate images)
- Augmentation (to create a larger sample size)
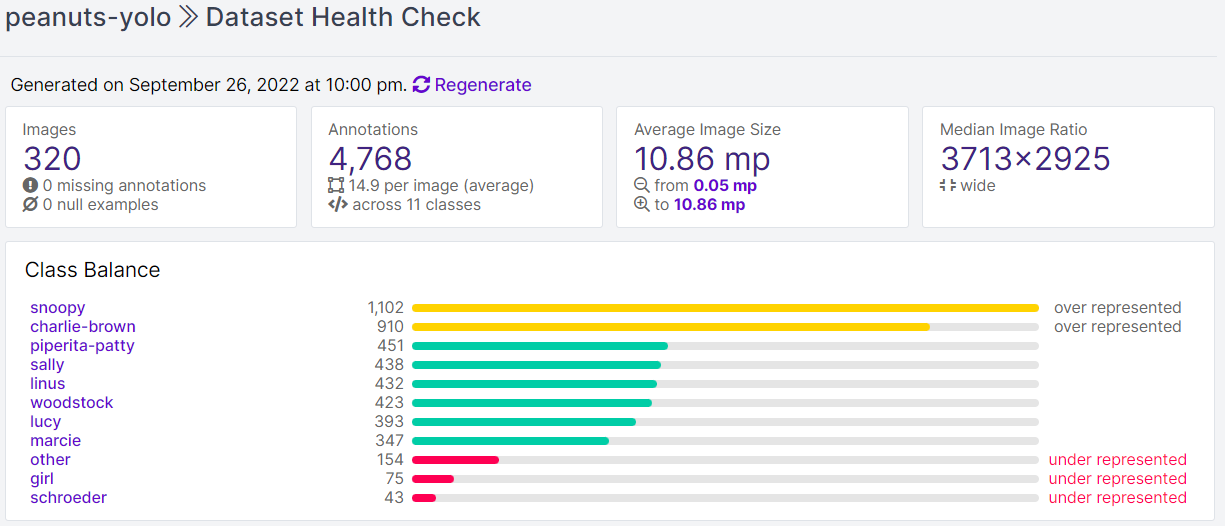
Once the team annotated their images and applied augmentations, they had a dataset of 320 images and 4,768 annotations with which to work. Snoopy and Charlie Brown were most represented in their dataset. The image below shows the Roboflow Dataset Health Check, which illustrated the class balance between different objects in their dataset.
Using the Roboflow Train tool, they could test their model with various available options:
- Via webcam
- Via source code
- Via your own framework
- Via the web interface
The Results
Here is an example of an image uploaded into Roboflow Train via the web interface. This image shows predictions for almost all of the characters in the comic strip, alongside confidence levels for each prediction and labels of the name of each character.
With this model, the team had tight bounding boxes around characters, in comparison to the CNN where bounding boxes were not exact. Here is an image displaying the results of an image upon which inference was performed in the Roboflow web interface:

For their project, the team exported data in the YOLOv5 format and trained their YOLOv5 network using the YOLOv5s model. This is because they needed to have an exportable model to use with any future developments. The team can now deploy their model anywhere with their data ready knowing that the YOLOv5 family of models is right for their needs.
To conclude, let’s go back to the image from the beginning of the article that demonstrates inference on a Peanuts comic:
Above, every character in the comic is named, including characters at different angles and obscured by lines that are in the comic. For instance, in the seventh box of the comic strip, Charlie Brown is correctly identified even though there are lines above his character indicating that he was running at speed.
With the results above, we can see that the YOLOv5 model trained with Roboflow performed well. The results allowed the team make accurate predictions as to the characters in an image and the position of those characters.
Conclusion
In this article, we demonstrated how the problem of identifying cartoon characters can be solved with computer vision.
The same principles we discussed in the YOLO example – training a model with well annotated images – can be applied to other multimedia classification tasks. For instance, one could use computer vision to classify the contents of image archives to make the media more searchable. The variety of possibilities is great.
Using Roboflow, you can quickly annotate, train, and refine a model for identifying objects in multimedia databases, such as in the Peanuts comic example above. You can get started today.
Cite this Post
Use the following entry to cite this post in your research:
James Gallagher. (Nov 4, 2022). Identifying Objects in Multimedia Databases with Computer Vision. Roboflow Blog: https://blog.roboflow.com/identifying-objects-in-multimedia-databases-with-computer-vision/