
Imagine a young girl named Emma who is fascinated by birds. Every weekend, she visits a nearby park to watch birds with her grandfather. Over time, Emma learns to recognize different bird species by their color, size, shape, and even their chirps. One afternoon, while flipping through a book, she effortlessly points to a picture and says, "Look, Grandpa! It’s a robin!" She doesn't measure wingspans or analyze feather types; her brain instantly connects the image to her experiences and memories of robins at the park.
This natural human ability (to look, understand, and identify) let’s human to see things and recognize it. But what if we want computers to do the same? This is exactly what image recognition aims to achieve.
Image recognition is a computer vision task that enables machines to interpret and identify objects, people, places, and actions in images. It mimics the human ability to understand visual data by analyzing patterns, shapes, and features in digital images.
At its core, image recognition works by analyzing the pixels of an image and identifying patterns. This is achieved through complex algorithms, most notably a type of computational model called neural network. These neural networks are inspired by the human brain's visual cortex and are trained on massive datasets of labeled images. By processing these images, the neural networks learns to recognize the features and characteristics of different objects.
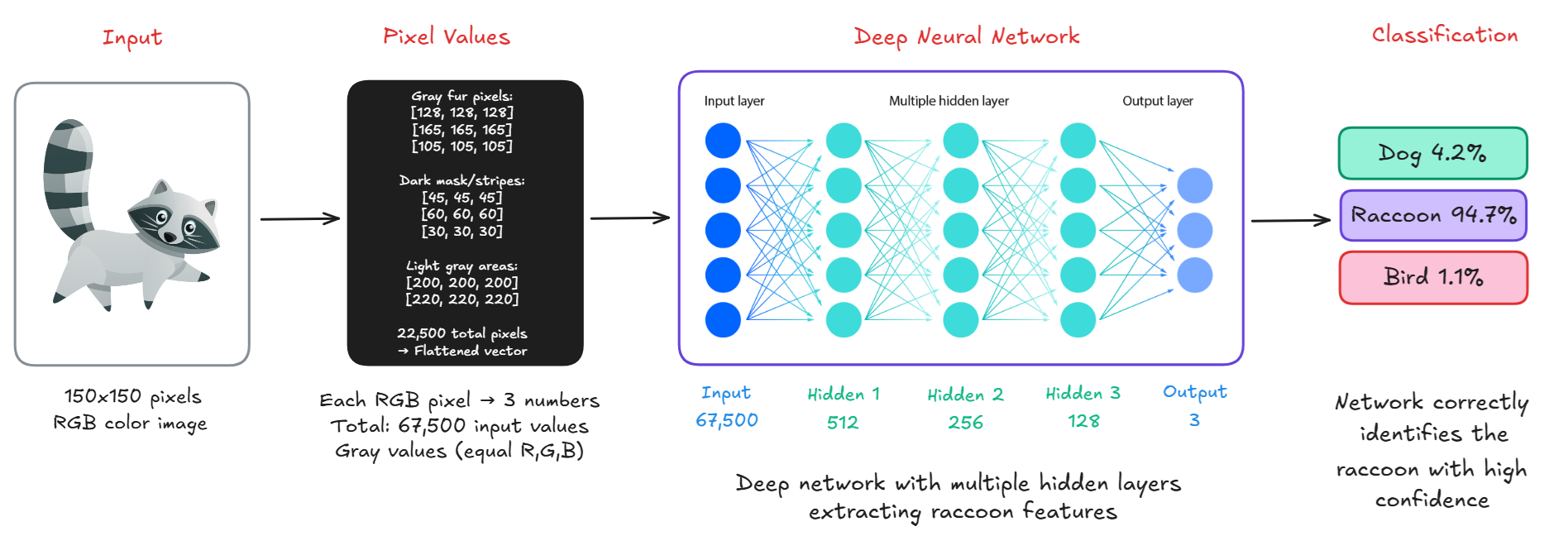
How Does Image Recognition AI Work?
To humans, seeing an image means instantly recognizing familiar shapes, colors, or people. But for a computer, seeing is completely different, images are just numbers. Here’s a step-by-step explanation of how a computer sees an image
Step #1: Pixels (The Computer's Vision Language)
Every image is made up of tiny dots called pixels. Each pixel holds a numerical value that represents a color or shade. For example, a grayscale image is a 2D grid of numbers (as shown below), where each number ranges from 0 (black) to 255 (white). A colored image has three channels Red, Green, and Blue (RGB), making it a 3D array.
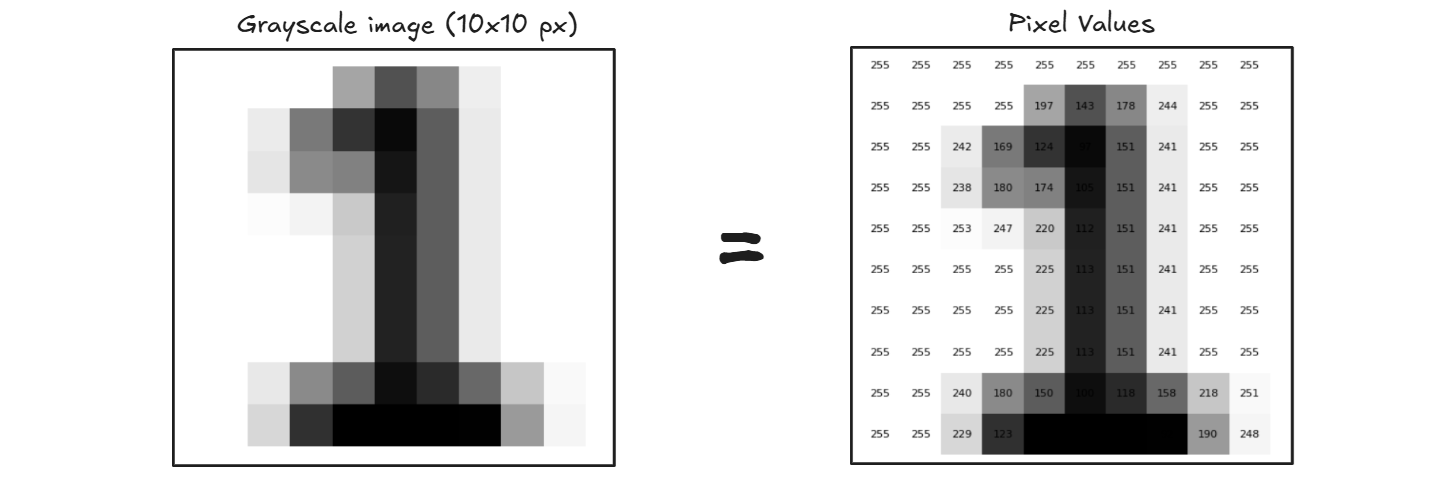
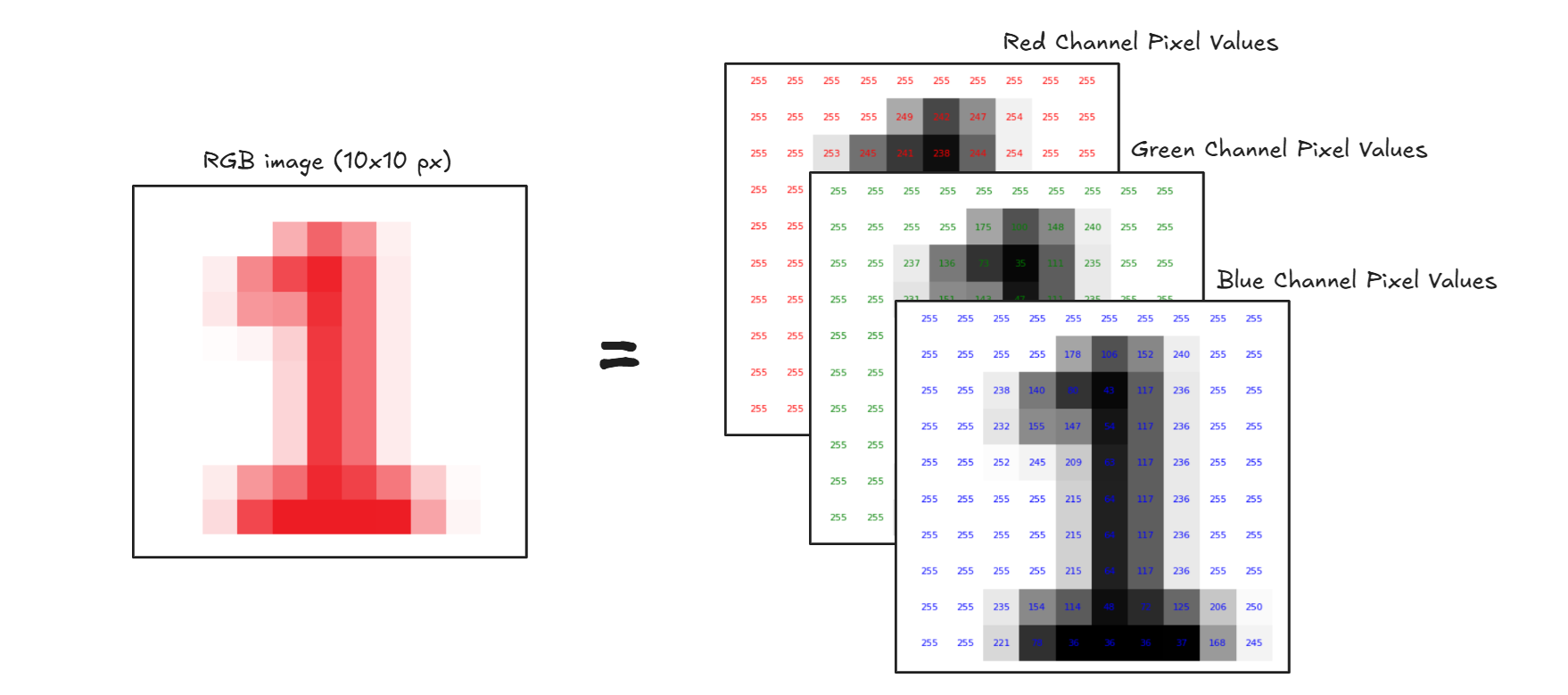
Step #2: Feature Detection (Finding Patterns)
Once the image is converted into numbers, the computer looks for patterns like Edges, Corners & Junctions, Lines and Curves, Shapes, Textures etc. It uses filters or mathematical operations (like convolution etc.) to detect these features automatically.
Step #3: Learning From Examples (Training)
The computer is shown thousands of labeled images (like cats, cars, or birds). During training. It learns which features are common for each object type. It stores this information in a neural network, a model that acts like a simplified brain.
Step #4: Classification (Prediction Time!)
When a new image is shown, the computer analyzes the pixels, detects features, compares them with what it has learned and outputs a label (e.g., “raccoon”) with a confidence score (e.g., 94.7%).
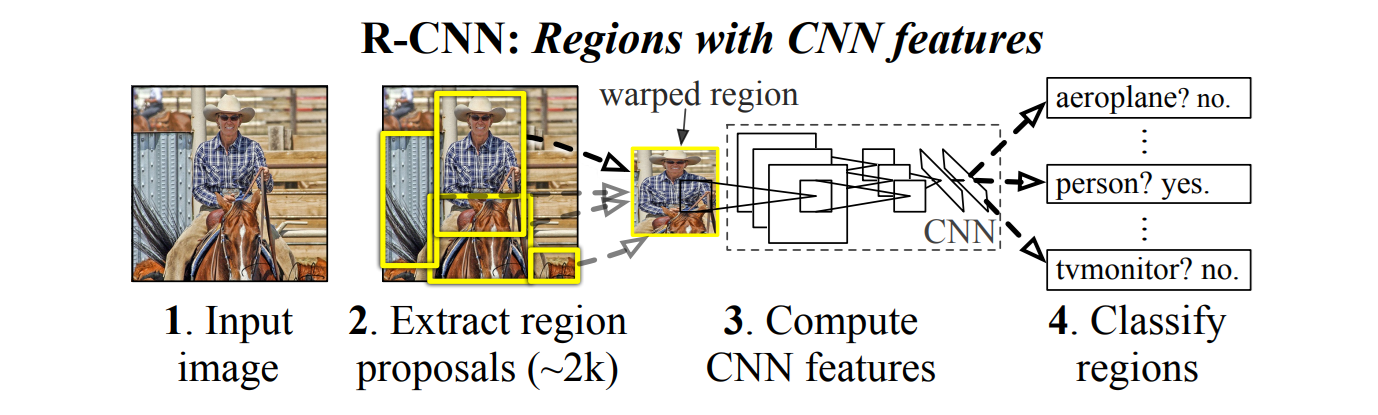
Let’s understand this whole process through R-CNN architecture. The R-CNN architecture diagram below illustrates how a computer sees and recognizes objects in an image using the R-CNN (Region-based Convolutional Neural Network) method. In step 1, the computer receives the input image, which is internally represented as a grid of pixel values. In step 2, rather than analyzing the whole image at once, R-CNN generates about 2,000 region proposals, smaller parts of the image that might contain an object. These regions are then warped to a fixed size and passed through a CNN in step 3, which applies a series of mathematical operations like convolution, pooling, and non-linear activation to extract distinctive features (such as edges, textures, or patterns). Finally, in step 4, each region’s extracted features are classified using a classifier (like SVM), answering questions like "Is this a person?" or "Is this a tv monitor?" The process shows how a computer doesn't understand the whole image at once, instead, it breaks it into parts, looks for meaningful patterns, and uses learned data to recognize what's inside, mimicking the way humans visually scan scenes to identify familiar objects.
A computer does not see images as pictures, it sees grids of numbers. With machine learning, especially deep learning, it learns to recognize patterns in those numbers and match them to known objects. Just like a child learns to recognize a dog after seeing many dogs, the computer learns from data to "see" the world.
Types of Image Recognition Models in AI
Image recognition has wide application with different types of models, each designed for specific tasks such as classification, detection, segmentation, face recognition, or keypoint estimation.
Image Classification Models
Image classification assigns a single label to an entire image. The model looks at the image and predicts what object (or class) it contains, like “cat,” “car,” or “banana.”. These models assigns a single label to the entire image and are used for recognizing the dominant object or scene in an image (e.g., “cat,” “airplane,” “fractured bone”).
Examples:
- ResNet 32/ ResNet-50: Uses residual connections to solve deep network degradation.
- Vision Transformers (ViT): The Vision Transformer uses powerful natural language processing embeddings (BERT) and applies them to images.
Object Detection Models
Object detection models locate and classify multiple objects in an image by drawing bounding boxes and assigning labels (e.g., “person,” “dog”). These models locates and classifies multiple objects in an image by drawing bounding boxes around them and are used for identifying and tracking multiple objects such as people, vehicles, animals, or products within an image or video.
Examples:
- YOLOv12: Fast real-time object detection model.
- DETR: End-to-end transformer based object detection model.
- RF-DETR: Transformer-based real time object detection model.
- Grounding DINO: State-of-the-art zero-shot object detection model.
Instance & Semantic Segmentation Models
These models perform pixel-level classification using:
- Semantic segmentation labels each pixel (e.g., sky, road, person)
- Instance segmentation also distinguishes between individual objects (e.g., person 1 vs. person 2)
These models are used for understanding the shape and exact boundaries of objects, for example, isolating road lanes, tumors, or leaves from the background.
Examples:
- Mask R-CNN: Combines Faster R-CNN with pixel masks.
- YOLOv8 Instance Segmentation: State-of-the-art YOLOv8 model comes with support for instance segmentation tasks.
- Segment Anything 2: Open-world, prompt-based segmentation from Meta.
- SegFormer: Transformer based model for semantic segmentation tasks.
Keypoint Detection & Pose Estimation Models
Keypoint detection models identifies specific landmarks on objects, commonly human joints (elbow, wrist, knee, etc.). Pose estimation uses these points to determine the posture or orientation of a body or object. These models are used for estimating human posture, gesture recognition, fitness analysis, and motion capture. These models typically returns coordinates of 17–33 body joints per person:
[
{ "x": 100, "y": 200, "label": "left_elbow" },
...
]
Examples:
- YOLO-NAS Pose: a keypoint detection model developed by Deci AI.
Face Detection & Recognition
Face Detection models finds and localizes faces in an image and Face Recognition models identifies or verifies individuals based on facial features. These models are used for biometric authentication, security surveillance, face tagging in photos, and access control systems.
Examples:
- RetinaFace: Highly accurate face detectors with landmark extraction.
- FaceNet / ArcFace / InsightFace: Convert faces to embeddings for matching.
- DeepFace: High-level wrapper supporting multiple backends like VGGFace, Dlib, etc.
Vision-Language Models (VLMs)
VLMs combine image understanding with natural language. You can ask them:
"What is happening in this image?" or "Where is the dog?"
They understand both visual patterns and language to give smart, text-based answers. These models interpret images using natural language and can answer questions about them, generate captions, or find objects by name. These models are used for image captioning, visual question answering, object grounding (“where is the dog?”), and multimodal AI applications.
Examples:
- MetaCLIP: Matches images to text (zero-shot).
- Florence-2 / Kosmos-2: Used for grounding, captioning, and segmentation with language.
- GPT-4o: Chat about images, generate captions, interpret documents.
How to Use Image Recognition AI using Roboflow
Roboflow allow you to train, test, and deploy computer vision models that can recognize images. You can build powerful image recognition systems with just a few steps. Following are the steps to build image recognition AI with Roboflow
Step #1: Create a Project
Choose the type of task for which you want to build image recognition model. Roboflow supports following project types.
- Image Classification (Assign label to entire image.)
- Object Detection (Identify objects and their positions with bounding boxes.)
- Instance Segmentation (Detect multiple objects and their shapes.)
- Semantic Segmentation (Assign every pixel to a label.)
- Keypoint Detection (Identify keypoints/skeletons on subject)
- Multimodal (Describe images using text pair)
Step #2: Upload Your Dataset
Once the project is created, upload/drag and drop your images into Roboflow. You can also import data from Roboflow universe, YouTube URL, Cloud Providers, and Upload API.
Step #3: Annotate Images
Label your images using Roboflow's built-in annotation tool. You may use following annotation techniques:
- Manual Annotation: Use Roboflow’s web-based annotation tool to label objects (e.g., bounding boxes, polygons etc.).
- Auto-Labeling: Use Roboflow’s AI-assisted labeling (i.e. Label Assist, Smart Polygon, Box Prompting, Auto Label) to speed up the process.
Step #4: Preprocess & Augment Your Data
Roboflow provides preprocessing and augmentation options to improve model robustness:
Preprocessing: Preprocessing involves modifying raw images to standardize them for model training. Common techniques include Auto-Orient, Isolate Objects, Static Crop, Dynamic Crop, Resize, Grayscale, Auto-Adjust Contrast, Tile etc.
Augmentation: Augmentation artificially expands the dataset by applying random transformations to images. This helps prevent overfitting (when a model memorizes training data instead of learning general patterns). Common techniques include
- Image Level Augmentations such as Flip, 90° Rotate, Crop, Rotation, Shear, Grayscale, Hue, Saturation, Brightness, Exposure, Blur, Noise, Cutout, Mosaic.
- Bounding Box Level Augmentations such as Flip, 90° Rotate, Crop, Rotation, Shear, Brightness, Exposure, Blur, Noise.
Step #5: Generate Dataset
Click "Create" to create a dataset version with your chosen settings.
Step #6: Train a Model
You can now train the model with Roboflow. You can choose Roboflow’s built-in auto training option via "Custom Train" button for a hosted model. Or you can export the dataset to train in YOLO, TensorFlow, or PyTorch locally. The following is the example to export dataset in YOLOv8 format for training.
from roboflow import Roboflow
rf = Roboflow(api_key="YOUR_API_KEY")
project = rf.workspace().project("your-project")
dataset = project.version(1).download("yolov8")
Step #7: Deploy Your Model
Roboflow offers flexible deployment options that allow you to run your vision models on the cloud, locally, or on various edge devices. Once trained, Roboflow provides:
- Workflows deployment to quickly configure, integrate, and deploy models into applications.
- Hosted image and video inference endpoints deployments, which are internet-dependent and easy to set up for non-real-time and batch processing needs.
- Edge deployment for embedded devices like TPUs or Android phones using custom code, or to edge devices such as NVIDIA Jetson through Docker containers for scalable, real-time inference.
- Additional deployment options include dedicated remote servers managed by Roboflow, mobile deployment on iOS, Snap AR Lens Studio integration, and more, enabling wide compatibility across platforms and use cases.
How Roboflow Workflows Can Be Used for Image Recognition
Roboflow Workflows is a feature that allows you to combine multiple computer vision models into a single pipeline. Instead of running one model at a time, a workflow lets you automatically chain tasks like object detection, classification, and OCR (text recognition) together, and get the final result with just one API call. Within Roboflow Workflows, you can build an image recognition pipeline using different model types and functional blocks, each responsible for a specific task. These blocks can be combined in sequence to form a complete visual processing pipeline.
Roboflow Workflows is powerful tool because it supports:
- Pre-trained models
- Custom-trained/fine tuned models
Using pre-trained models in Roboflow
Roboflow offers several ready-to-use models (such as YOLOv8, YOLOv11, YOLO-NAS, RF-DETR-Base, VLMs/Multimodal Models) that you can try on your own images without training anything. You can use these models directly in your Roboflow Workflows with the help of different blocks. For example you can use RF-DETR-Base or YOLOv8 model using Object Detection Model block, YOLOv8n-Seg segmentation model using Instance Segmentation Model block, YOLOv8n-Pose pose estimation model using Keypoint Detection Model block GPT-4o model using OpenAI block, gemini-2.0-flash model using Google Gemini block and many more.
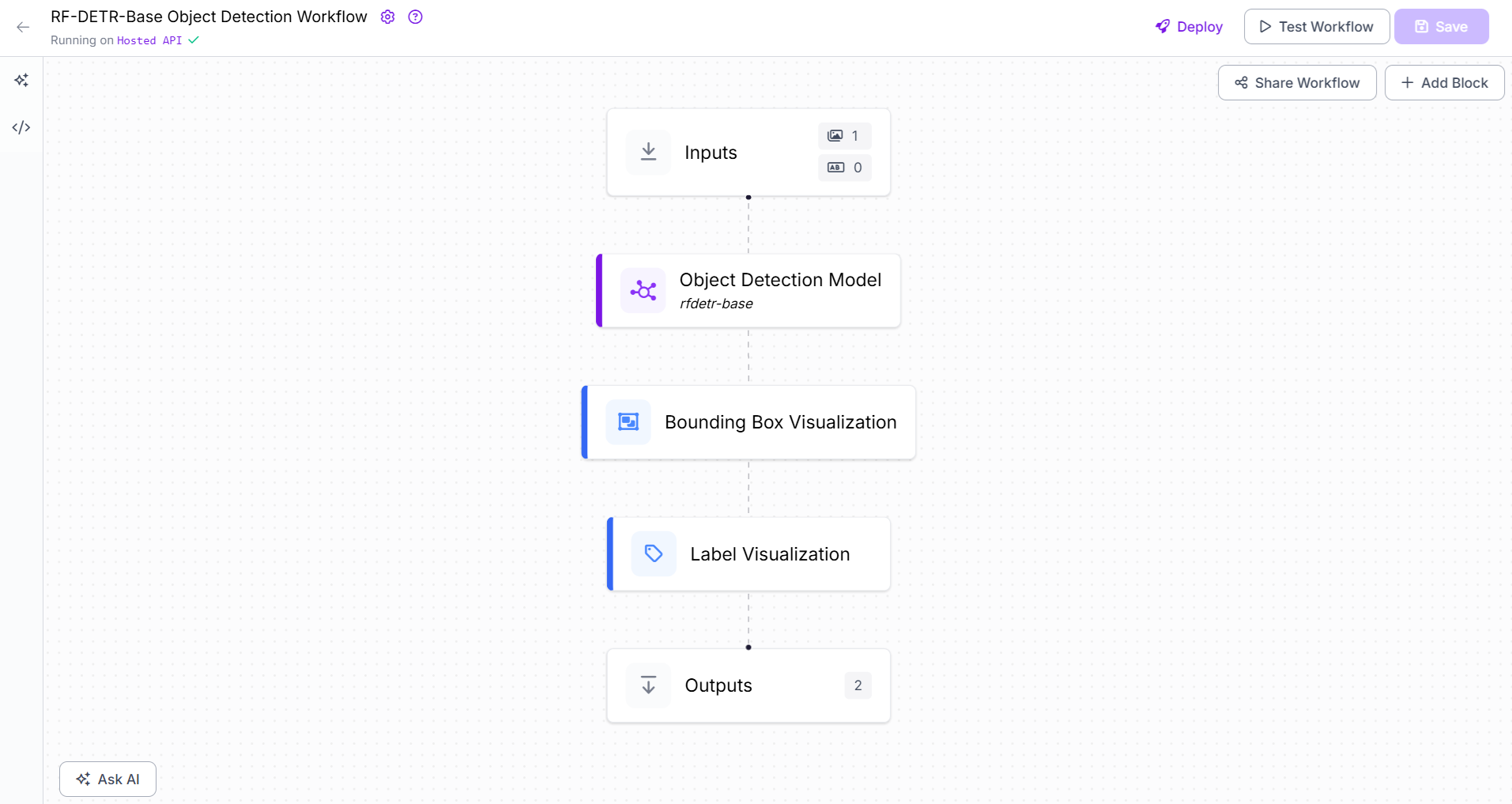
Using trained or fine-tuned custom models with your data
Roboflow is an end-to-end platform for computer vision development. It supports the entire lifecycle of building computer vision models from data collection and labeling to dataset generation, training, fine-tuning, inferencing, deployment, and integration with APIs. Once you train a custom computer vision model using Roboflow, it is hosted and readily available to be integrated in your application via APIs. You can also integrate these models in your Roboflow Workflow via your workspace or publicly available models within other users Workspace in the Roboflow platform.
Building Image Recognition AI with Roboflow
Now let’s see some example of how to build image recognition AI application with Roboflow. In this section we will use custom trained models (Wood/Log Detection, Hand Gesture Recognition) as well as pre-trained model (Florence-2) with Roboflow Workflows to build our application.
Example #1: Detecting and counting wood/log
In this example we will build a Roboflow Workflow application that will recognize and detect Wood/Log and count it. For create the object detection project, upload and label dataset and train the model using Roboflow Autotraining option. The trained model is available at Roboflow hosted inference server that we can use.
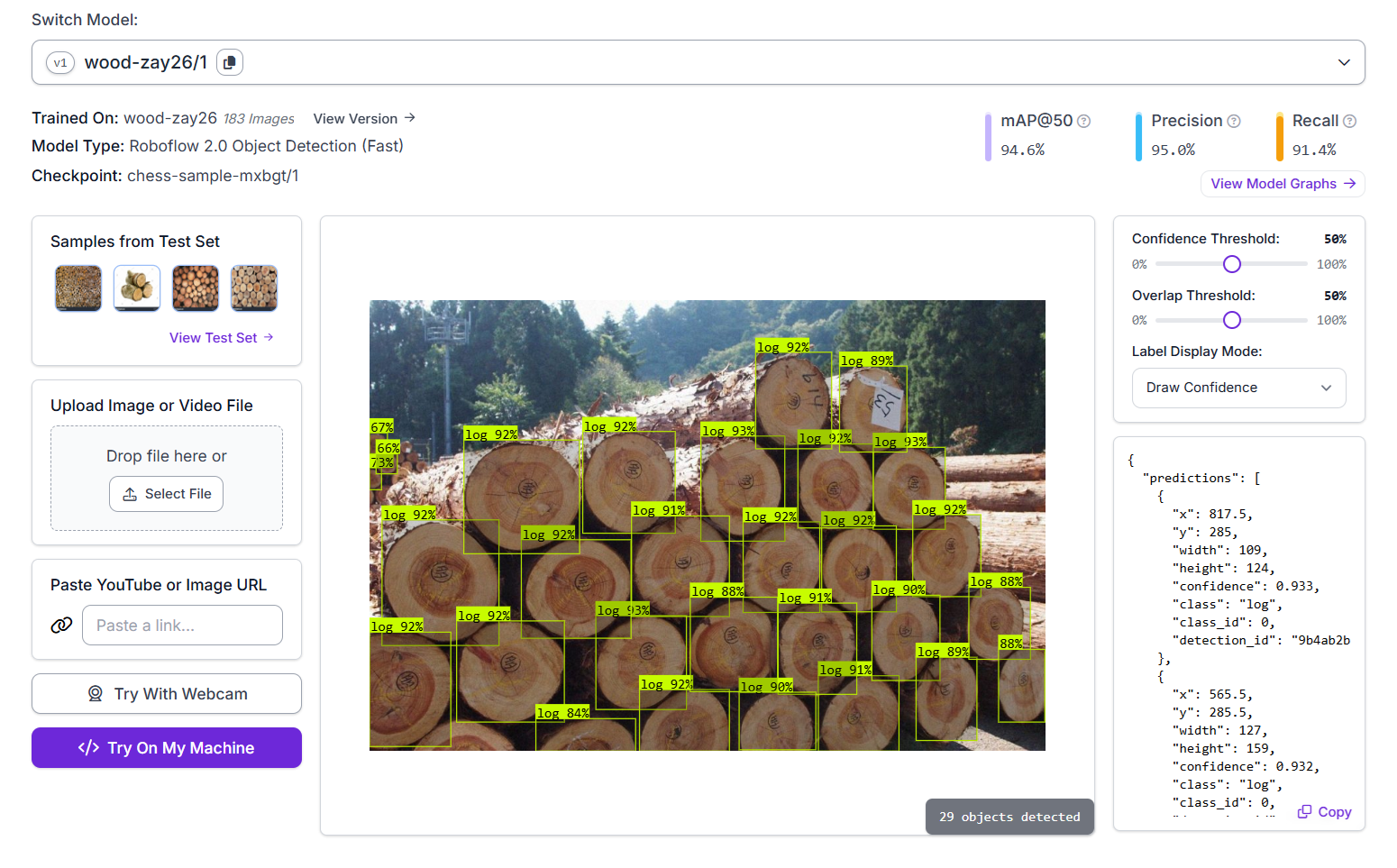
In this example, we build a Roboflow Workflow application designed to detect and count logs (wood pieces) in an image. The project follows an object detection approach using the Roboflow 2.0 Object Detection (Fast) model. To create this application, a custom dataset of 183 labeled images containing wood logs was uploaded to Roboflow. Each log in the image was annotated with the class label "log". The model was trained using Roboflow’s AutoML training pipeline. The model was trained and achieved an mAP@50 of 94.6%, with a precision of 95.0% and a recall of 91.4%. The trained model, identified as wood-zay26/1, is hosted on Roboflow’s inference server and can be integrated into a workflow or called via API.
We will integrate this model into our Roboflow Workflow by creating a new workflow and adding an Object Detection Model block. This block is responsible for running inference using the trained model. In the block’s configuration, set the Model property to wood-zay26/1, which points to the deployed custom object detection model hosted on Roboflow. This enables the workflow to automatically detect and label logs in input images using the trained model.
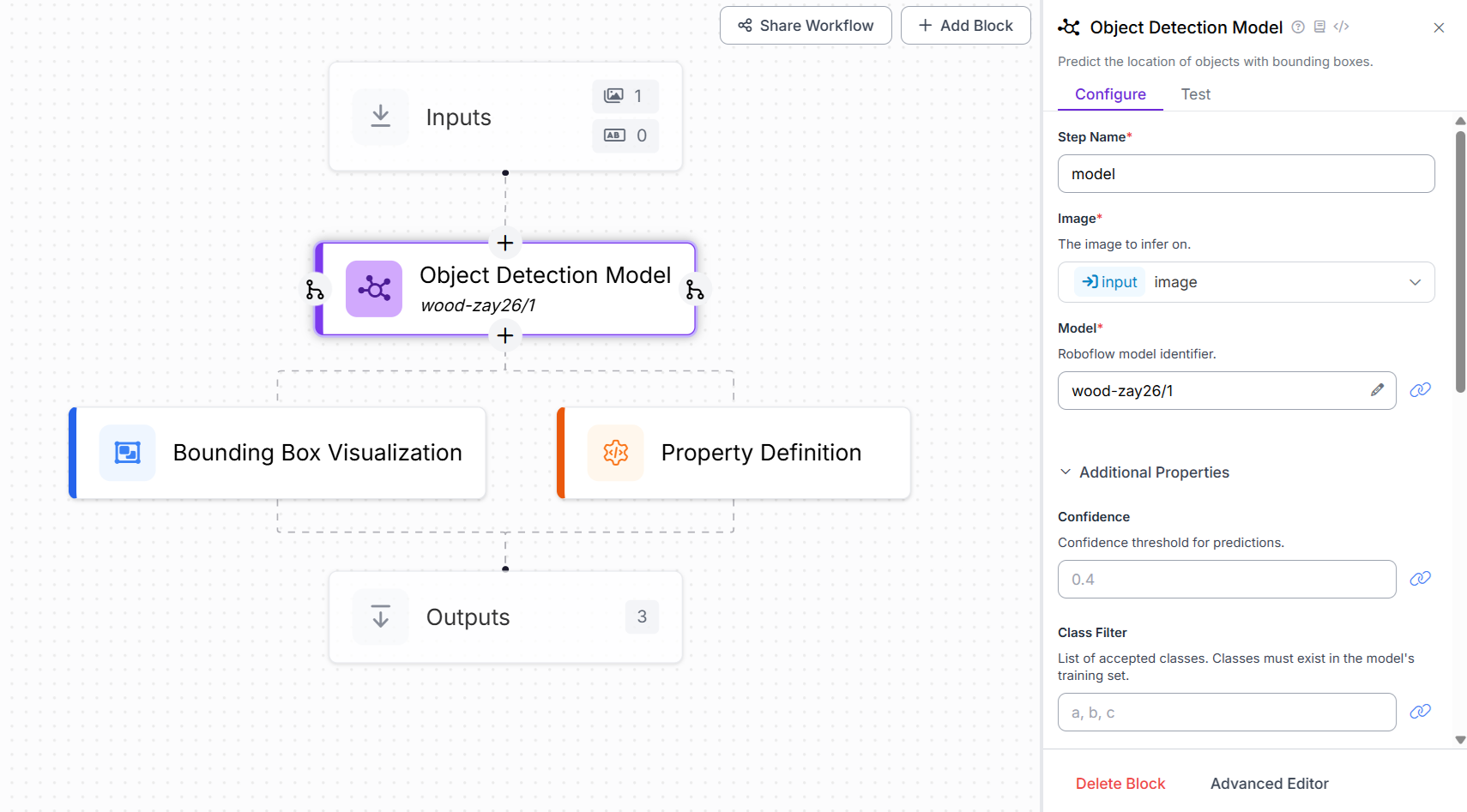
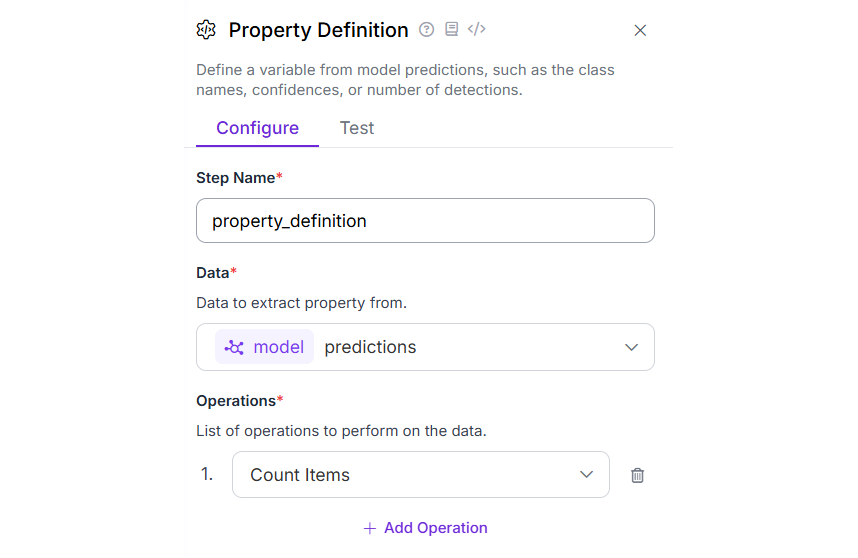
Now add the Property definition block. This block is used to count the number of detections that helps to count the number of Wood/Logs in the image. Set the Operations property of this block to “Count Items” as shown below.
Finally, add a Bounding Box Visualization block to display the detection results with bounding boxes over the identified objects. Once the workflow is executed, it will generate an output image highlighting each detected wood log, allowing you to visually confirm the model’s recognition of logs within the image.
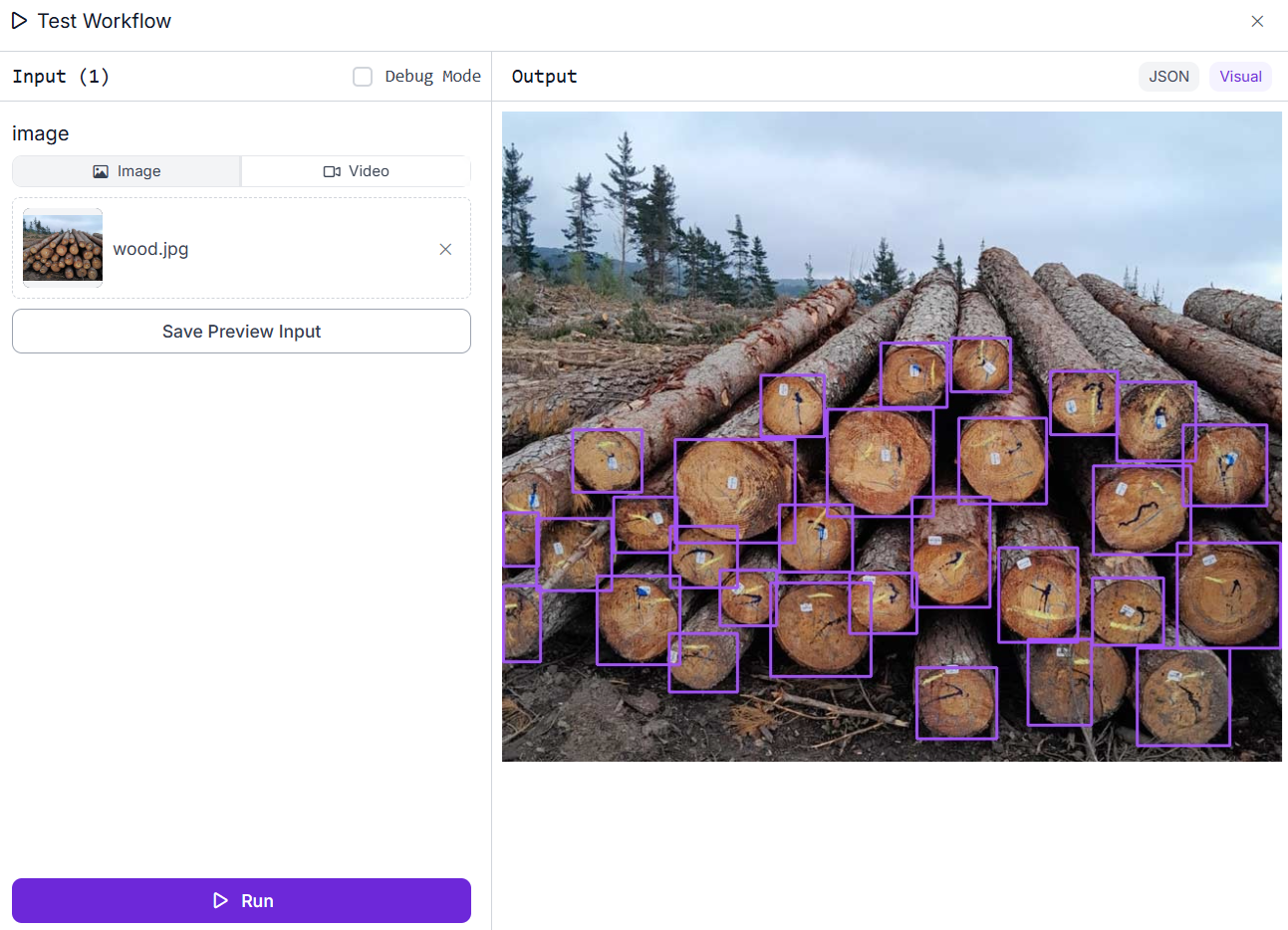
The JSON output displays the result from the Property Block, which provides the total count of detected wood logs identified in the image.
"property_definition": 29
This type of workflow is especially useful in forestry management, inventory tracking, and automated material handling, where counting and recognizing logs in stacked images is required.
You can also run this workflow locally or in real-time using webcam input or edge devices, and even customize it further by adjusting confidence thresholds and overlap settings.
Example #2: Recognizing Hand Gestures
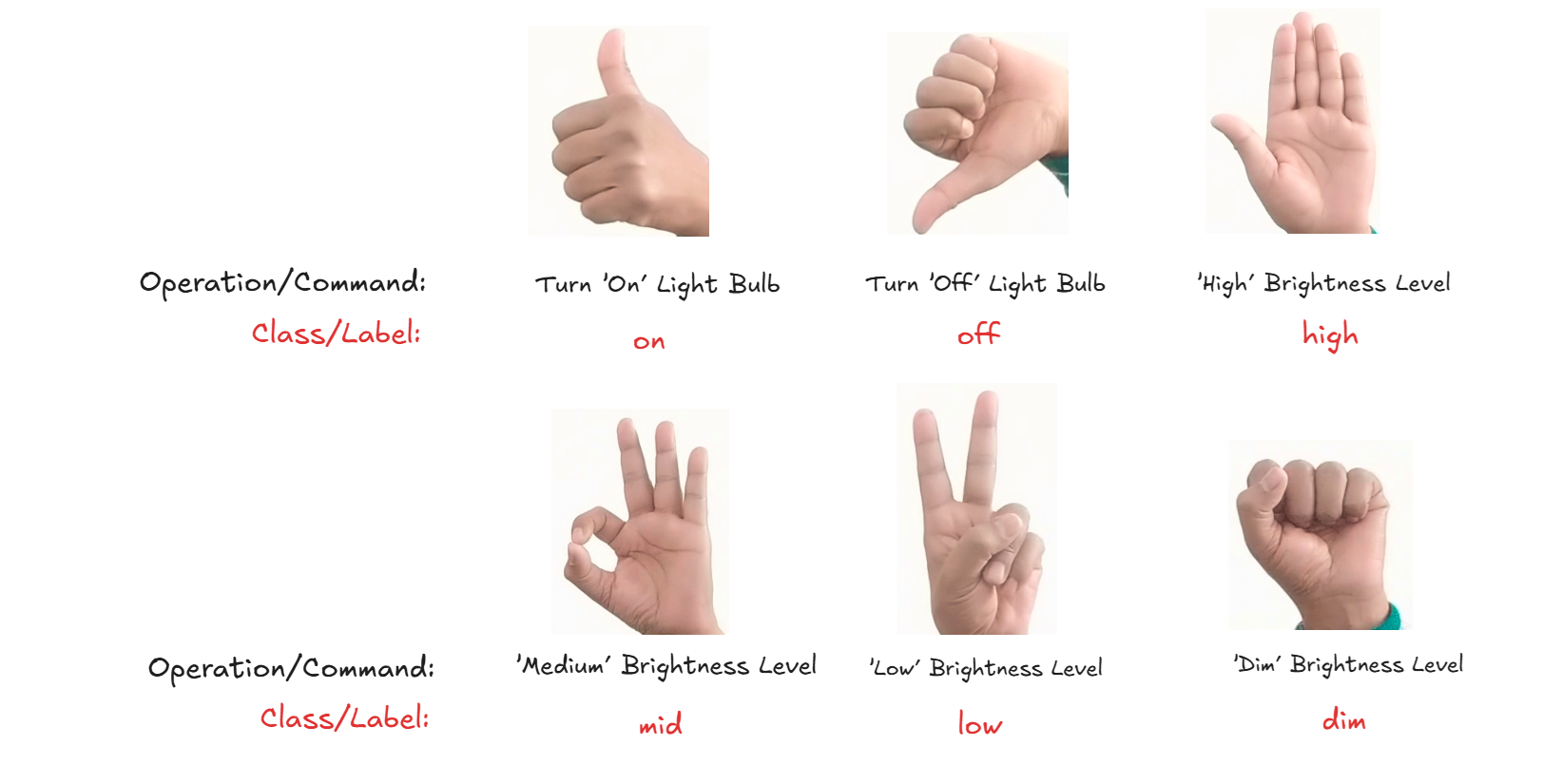
In this example, we build a Hand Gesture Recognition application using a custom-trained object detection model from Roboflow. The model is designed to detect and identify different hand gestures, as shown in the following image, based on the shape of the hand in an image. These hand gestures are used for controlling the AC light bulb.
The model, trained using Roboflow’s AutoML pipeline, is based on the Roboflow 3.0 Object Detection (Accurate) architecture with the COCOs checkpoint as its foundation. The training dataset consists of annotated images representing various hand gestures, each labeled with the corresponding gesture name as the class.
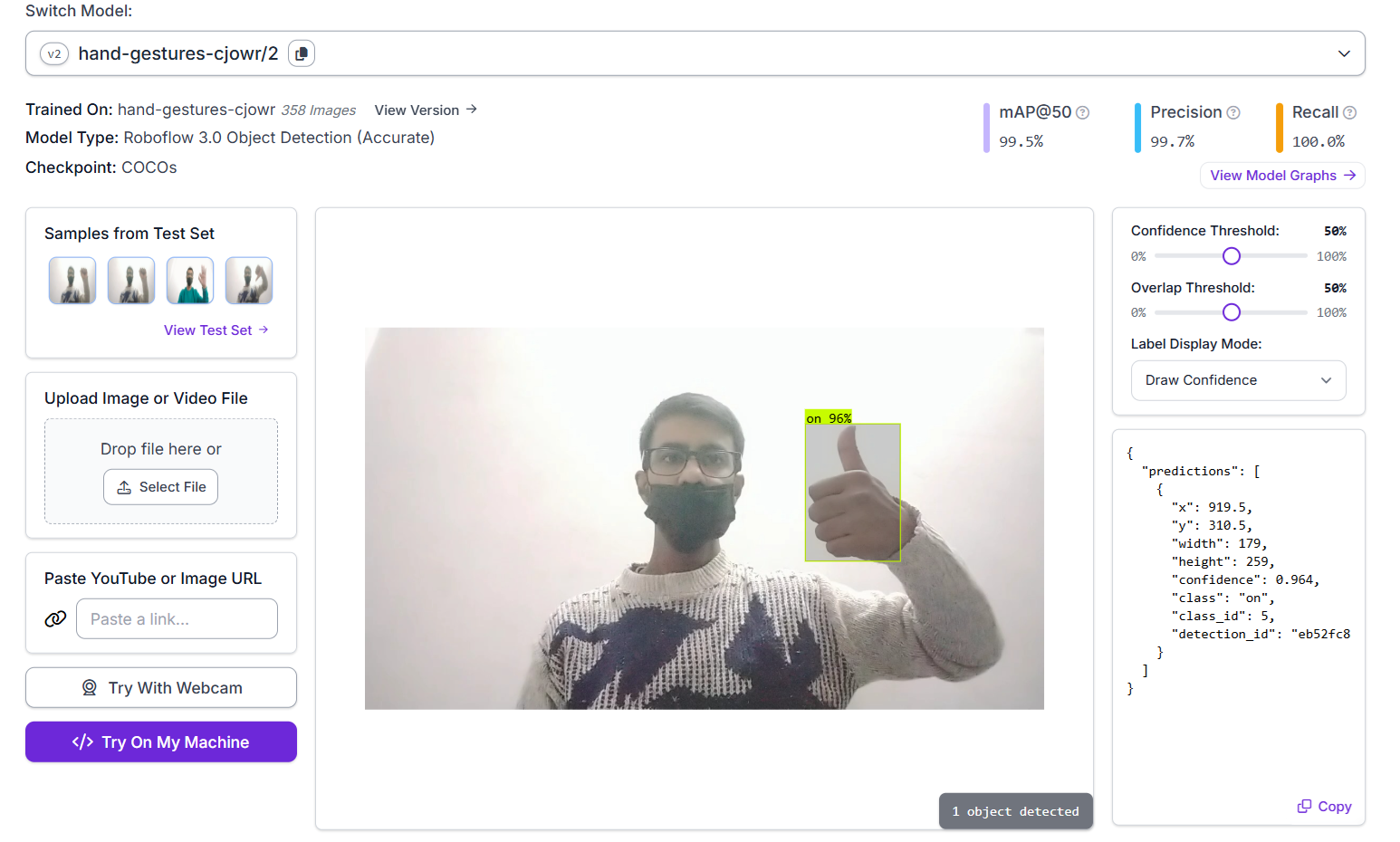
In the inference shown below, the model has successfully detected a hand gesture and labeled it as "on" with 96% confidence. The model was trained and achieved an mAP@50 of 99.5%, with a precision of 99.7% and a recall of 100.0%.
We will use this model in a Roboflow Workflow to build a Hand Gesture Recognition application. To set it up, create a new workflow and add an Object Detection Model block, configuring the Model property to hand-gestures-cjowr/2. Then, include both a Bounding Box Visualization block and a Label Visualization block to display the detected hand gestures along with their corresponding class names.
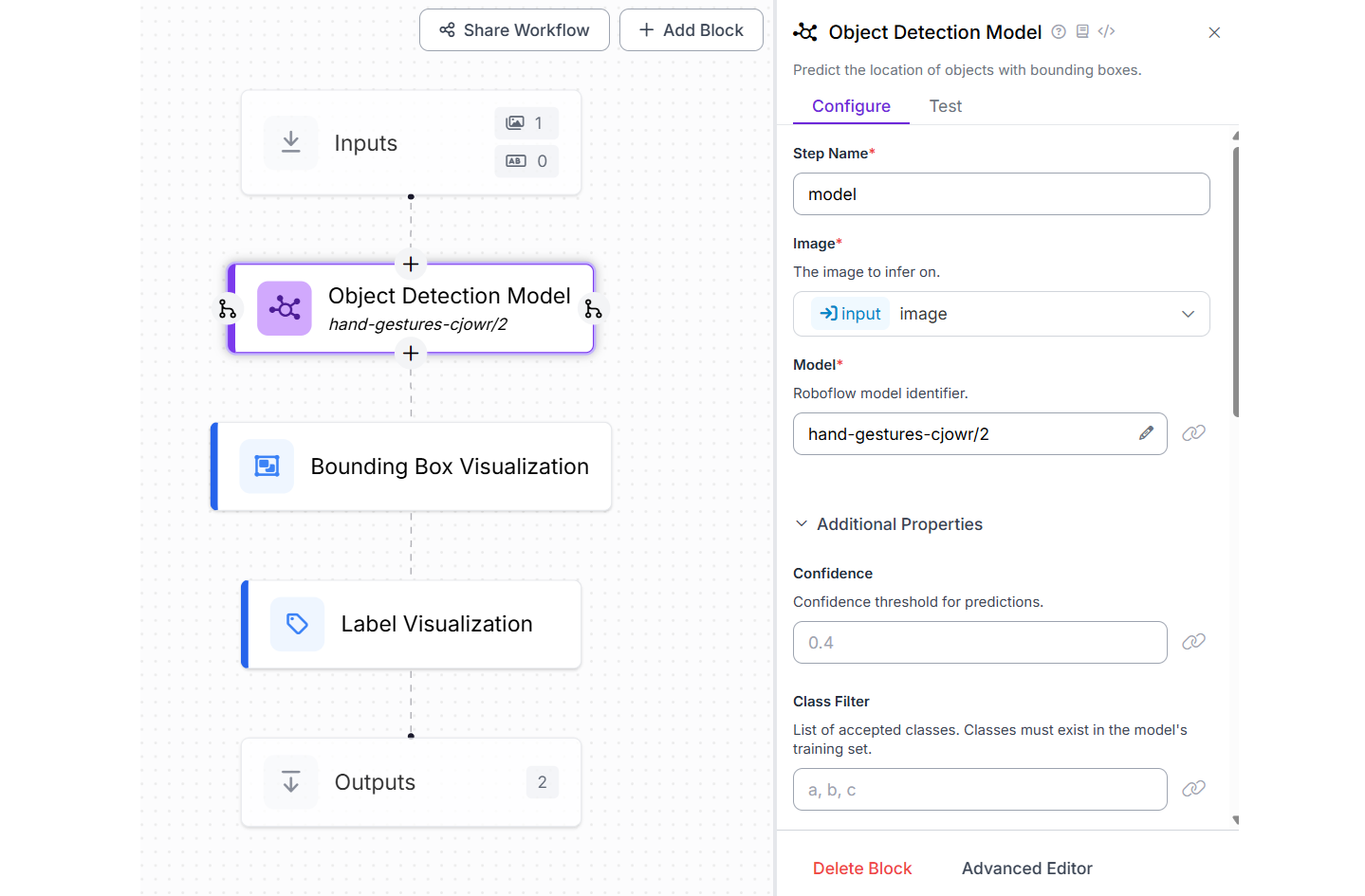
Once the workflow is executed on an input image, it will highlight each recognized gesture with labeled bounding boxes.
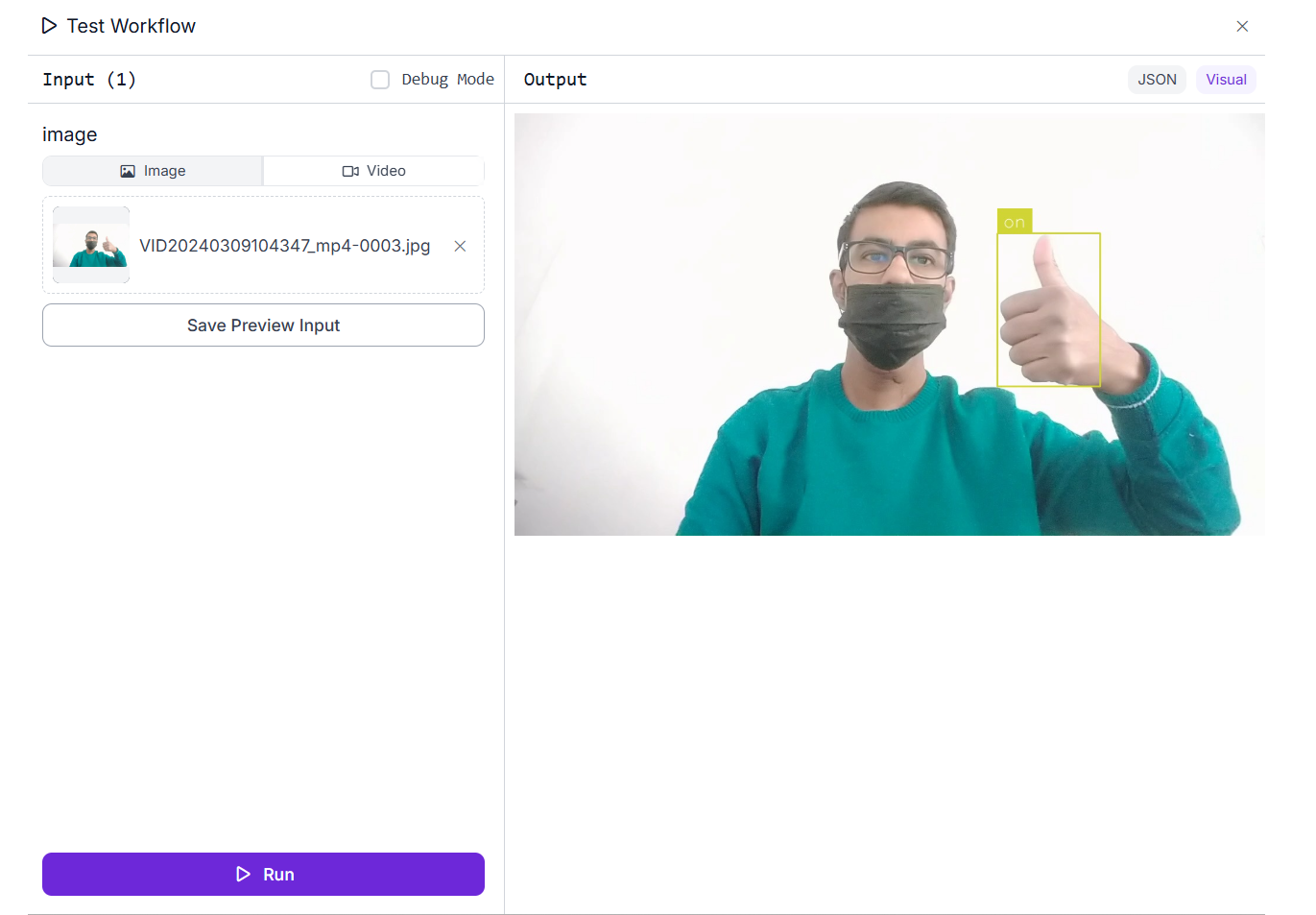
Apart from processing static images, the workflow can also handle video files and live video streams. Using the Inference Pipeline SDK, you can deploy and run workflow locally on an edge device to process video inputs in real time. This makes it suitable for interactive applications such as gesture-based control systems, smart home interfaces, assistive technologies, and sign language detection system.
Example #3: VLM for Image Recognition
In this example, we use the Microsoft Florence-2 Vision-Language Model (VLM) to build an intelligent image recognition application. The application is powered by a Roboflow workflow that integrates a pre-trained Florence-2 model capable of identifying and locating specific objects within an image. By providing a text prompt, such as the name or description of the object, the model is guided to detect and highlight the target object in the image. This approach leverages the power of multimodal AI, combining vision and language understanding to perform flexible, prompt-based object recognition.
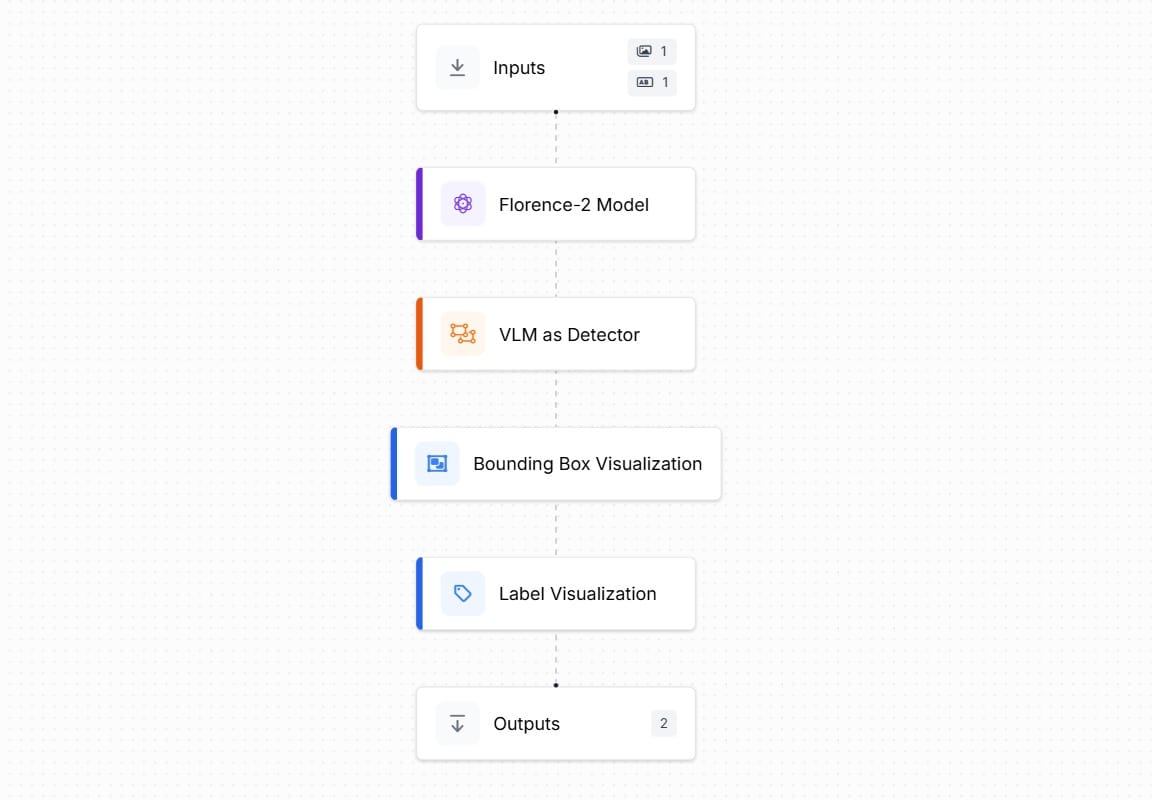
Create a Roboflow Workflows as following. Add the Florence-2 block, VLM as Detector block, Bounding Box Visualization Block and Label Visualization Block.
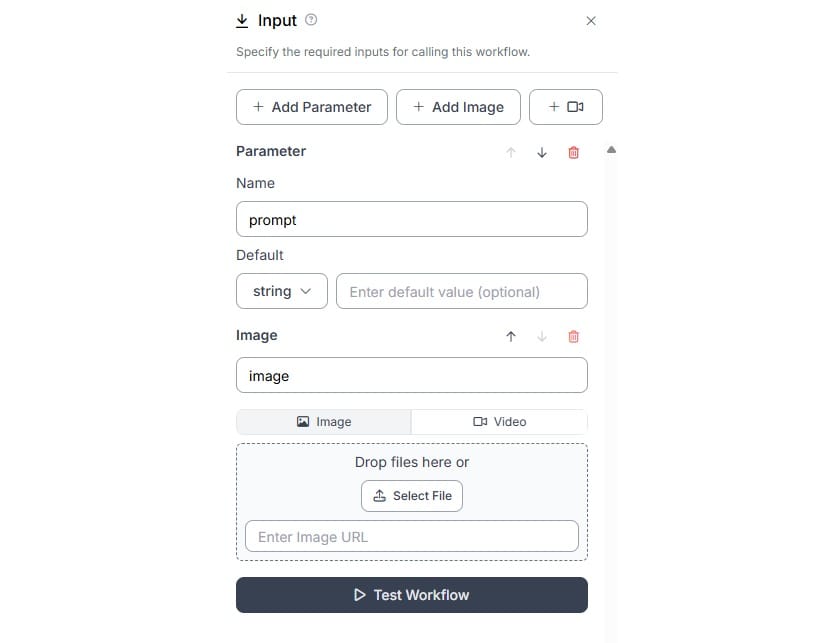
Add a text parameter in input block to specify the text based prompt along with input image.
Configure the Florence-2 block as following. Choose the Task Type as “Prompted Object Detection”. Bind the Prompt property with the “prompt” parameter added in the Input Block.
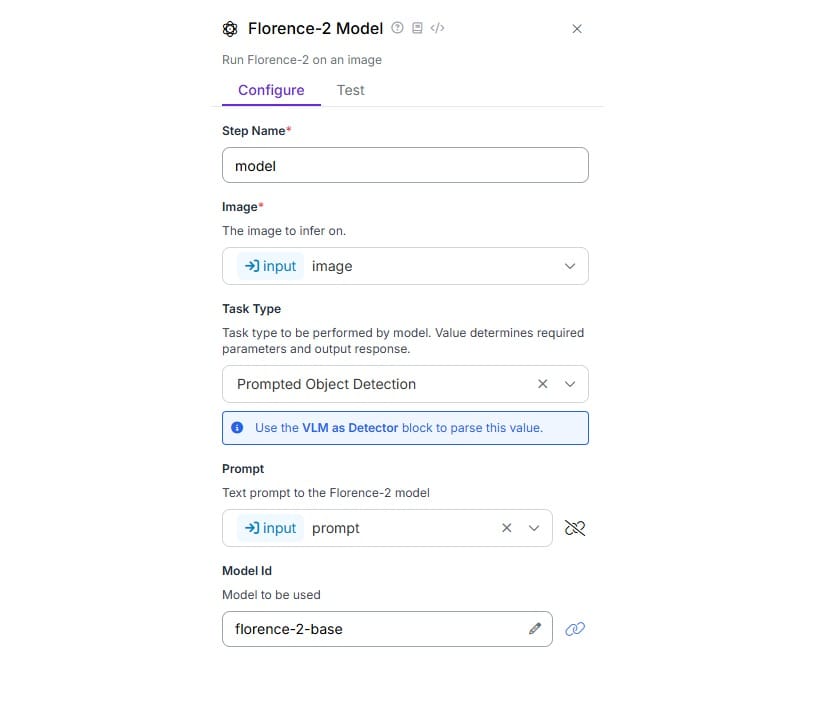
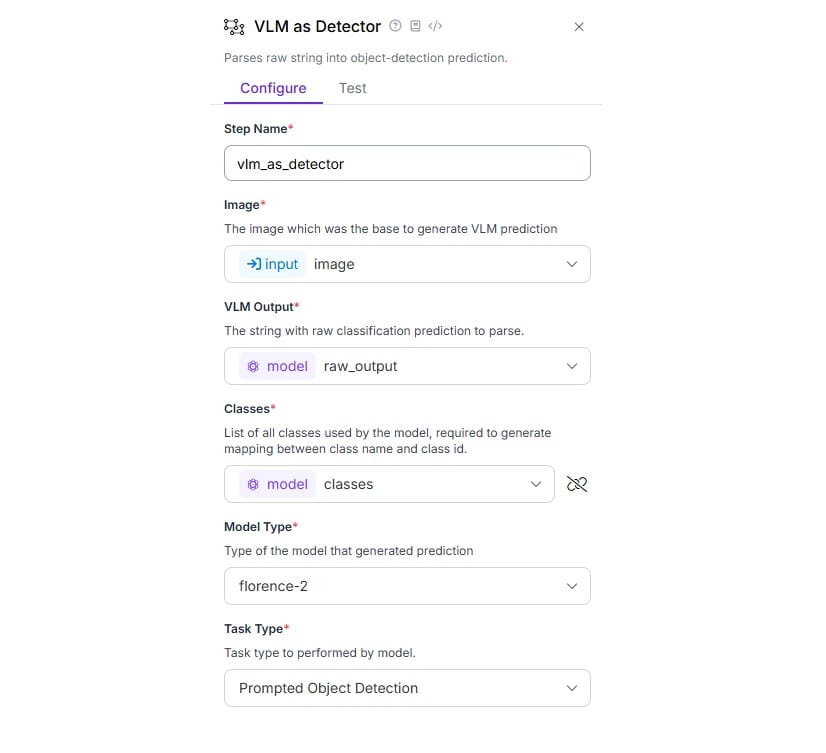
Now, configure the VLM as Detector block as follows. The VLM Output and Classes properties are set with the output from Florence-2 block and Model Type property is set to Florence-2 and Task Type to Prompted Object Detection.
Run the Workflow by specifying prompt and uploading input image. In the case the prompt is “Where is the ball?” and input image is of a baseball player (batter) hitting the ball. We want to identify the ball and it’s position in the image.
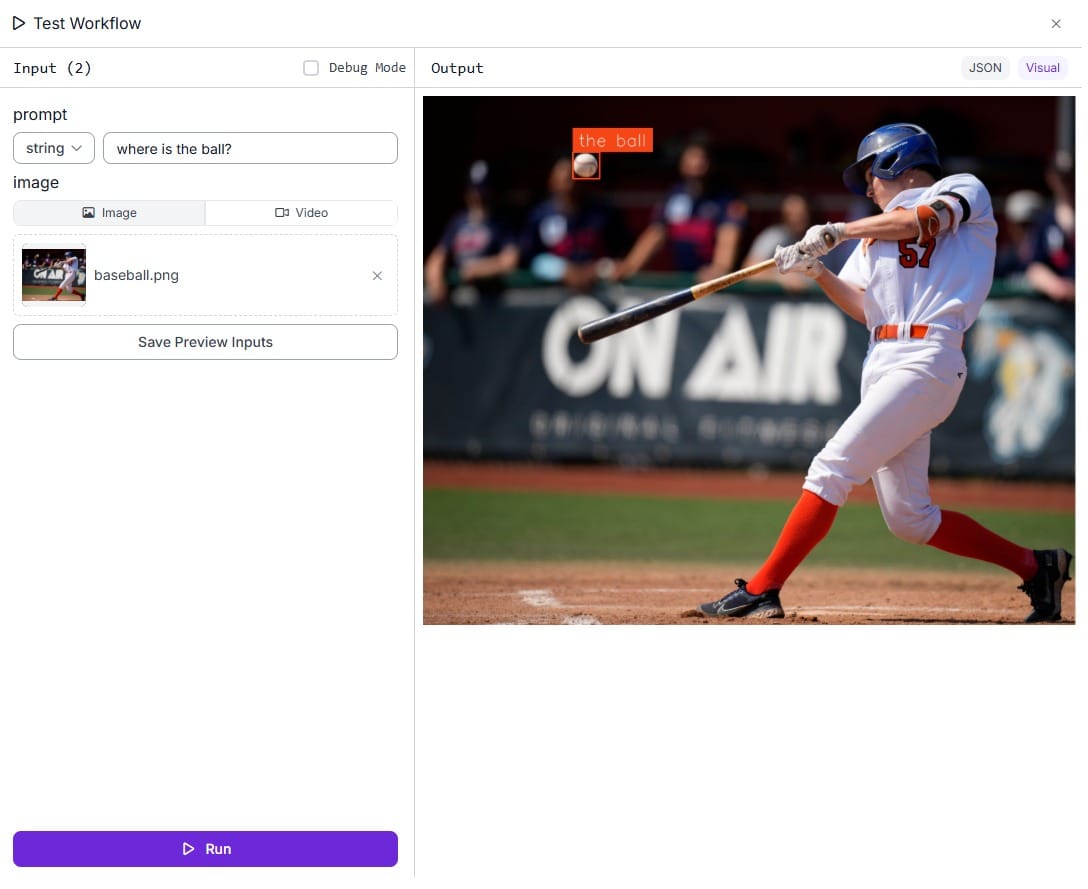
Vision-Language Models (VLMs) offer a powerful and flexible approach to image recognition by combining visual understanding with natural language prompts. Instead of relying solely on predefined classes, VLMs allow users to describe what they want to detect using simple text inputs. This enables prompt-based object detection, where the model can identify and localize objects in an image based on a given description. Whether used for locating specific items, generating image captions, or answering visual questions, VLMs make image recognition more intuitive and adaptable to a wide range of real-world scenarios.
Image Recognition AI Software
Image recognition is a powerful application of computer vision that allows machines to understand and interpret visual data just like humans. With platforms like Roboflow, building and deploying intelligent image recognition systems becomes accessible, even without deep coding expertise. Whether it's detecting logs, recognizing hand gestures, or using vision-language models for prompt-based detection, Roboflow Workflows empower developers to create custom or multimodal AI pipelines with ease. These capabilities open the door to real-world applications in industries like forestry, security, retail, healthcare, and beyond.
The following are the key takeaways from this blog to help you understand and apply image recognition using Roboflow:
- Image Recognition: Computers interpret images as numerical data, and through training, they learn to recognize patterns and objects using neural networks.
- Types of Models: There are different models for various tasks including classification, object detection, segmentation, keypoint detection, hand gesture recognition, and vision-language understanding.
- Roboflow Workflows: A no-code/low-code visual pipeline builder that lets users chain multiple model types and functions to create full image recognition systems.
- Pre-trained vs Custom Models: Roboflow supports both, use ready-to-go models or train your own on custom datasets using AutoML.
- Real-World Applications: From wood log counting to real-time hand gesture recognition and prompt-based object detection with VLMs, image recognition has a broad range of use cases.
- Flexible Deployment: Roboflow supports cloud-based, edge device, and mobile deployment, along with hosted APIs and SDKs for real-time or batch inference.
Cite this Post
Use the following entry to cite this post in your research:
Timothy M. (Jun 10, 2025). What Is Image Recognition AI? Algorithms and Applications. Roboflow Blog: https://blog.roboflow.com/image-recognition/