
Getting a computer vision model from a dev into a production environment is where a lot of projects struggle. It requires the power of GPUs, an API endpoint(s), and the potential to feed production data back into a training pipeline.
That's a huge infrastructure task that Roboflow’s Inference as a Service (IaaS) solves, and it's easy to get started.

What Is Inference as a Service?
Inference as a Service (IaaS) is a cloud-hosted model that lets you run predictions through simple API calls. It handles all of the heavy lifting and hardware allocation to fulfill your task. The infrastructure that makes that happen lives entirely on the provider's side.
For computer vision specifically, this matters a lot. Vision models are large, latency-sensitive, and hardware-intensive. Running them reliably at scale requires careful orchestration. Inference as a Service abstracts all of that away so product teams can move fast.
Roboflow’s Inference Approach
Most inference platforms focus on just running a model. However, Roboflow treats every inference as part of a larger loop: from raw data to trained model to production deployment to smarter data collection and back again. Here are some advantages of a workflow involving Roboflow:
- One-Click Deployment: Upload a trained weights file and Roboflow turns it into a hosted API endpoint in seconds.
- Active Learning Built In: Unlike generic IaaS, Roboflow treats every inference as a learning opportunity, using inference data to improve your next training run. We have RFHH (reinforcement learning from human feedback) where the human just needs to review the generated labels.
- Abstraction: Roboflow automatically chooses the best runtime for the specific hardware configuration (utilizing CUDA/Tensor RT on NVIDIA GPUS or optimized ONNX on CPUs), which is one less thing for developers to figure out. Additionally, there is a separation between the API and the model runtime, which makes the system modular and easier to debug.
- Model Breadth: Roboflow's inference service isn't limited to custom-trained models. You can run object detection, instance segmentation, classification, and keypoint estimation models you've trained yourself, but also a growing library of foundation models out of the box. That includes SAM 3 for zero-shot segmentation, depth estimation models, OCR, and more.
- Model Chaining: Real-world vision problems are rarely solved by a single model. Roboflow lets you chain models together into a single logic flow. A common pattern might look like: Detect →Crop images → Classify the cropped Images. This dramatically reduces compute costs compared to running a single large model over the full image, and it keeps your pipeline modular so you can swap individual stages independently. You can also add conditional logic directly in a workflow. For example, "if a person is detected, trigger pose estimation; otherwise, skip"- without writing complex infrastructure code.
- Future Proof Infrastructure: With Roboflow, you also have a future-proof guarantee that your deployments continuously improve with your annual subscription, gaining access to the latest technologies.
Key Components of Roboflow's Production-Grade Inference API
Additionally, Roboflow’s API provides quality-of-life features and optimizations:
Auto-Scaling Infrastructure: Traffic can be unpredictable at certain times, and may sometimes spike your inference load without warning. In generic IaaS, this can hinder your product, requiring you to manage GPU orchestration yourself. But with Roboflow, whether you're processing one image a day or ten thousand a minute, the API scales elastically to handle the load without dropping frames.
Built-in Preprocessing & Tiling: High-resolution images are a common pain point. A 4K frame fed directly into most models will either error out or produce terrible results. Roboflow automatically handles resizing, orientation correction, and advanced tiling, breaking large images into digestible chunks, running inference on each tile, and stitching the results back together into a single coherent output.
High-Performance Model Runtimes: Roboflow optimizes deployed models using high-performance runtimes like TensorRT and ONNX Runtime, extracting the lowest possible latency from the underlying hardware.
Versioned Model Endpoints: With Roboflow, you can ship with confidence using instant versioning. You can call specific versions of your model (e.g., project/1 vs project/2) via the API, allowing for easy A/B testing and zero-downtime rollouts.
Dynamic Batching and Multi-Threading: Roboflow handles concurrent requests effectively by optimizing CPU and GPU usage during high throughput (multiple video streams from various cameras). Also, it includes cold-start logic that reduces the time it takes to swap or load new models into memory.
Unified Output Formats: No more parsing raw tensors. Every response from Roboflow's inference API returns clean, standardized JSON: bounding box coordinates, class labels, confidence scores, and segmentation masks where applicable. The output is immediately consumable by your application logic without any custom parsing layer.
Integrated Active Learning: A big advantage of Roboflow is that it can be configured to sample a percentage of production inferences, particularly low-confidence or novel predictions, back into your dataset automatically. Combined with RFHH review, this means your annotation queue is populated with the most valuable examples from the real world, not synthetic data or carefully staged test sets. Models trained on this feedback loop outperform models trained in isolation.
Cloud vs. Edge: Choosing Your Architecture
With Roboflow, you also have options for the underlying architecture of your product. For most teams exploring inference as a service, the cloud is the right default. You get started immediately, scale effortlessly, and avoid all hardware management overhead.
But Roboflow also supports edge deployment when your use case demands it. Key advantages of this are low latency, offline operation, data sovereignty concerns, or processing video locally before sending only relevant events to the cloud. The key advantage is that Roboflow uses the same API structure for both cloud and edge, so you're not learning two different systems.
You can train entirely in the cloud using Roboflow's platform, then export and deploy to edge hardware - NVIDIA Jetson devices, OAK-D cameras, or a local Docker container running the Roboflow Inference Server on commodity hardware. When bandwidth or latency requirements shift, your deployment target can shift with them without rewriting your application logic.
Security, Versioning, and Deployment Management
Additionally, Roboflow provides helpful security and deployment features. For starters, Roboflow uses token-based authentication with enterprise-grade access controls. Every API call is authenticated, every endpoint is secured, and you can manage access at the project and organization level.
Also, since production systems can't afford breakages from model updates, Roboflow's versioned endpoints let you maintain explicit separation between production and staging environments, calling each via distinct API paths. When you're confident in a new version, promoting it is a configuration change, not a redeployment.
Choosing the Right Service for Your Needs
Lastly, not every workload is the same, and Roboflow's managed compute offerings reflect that.
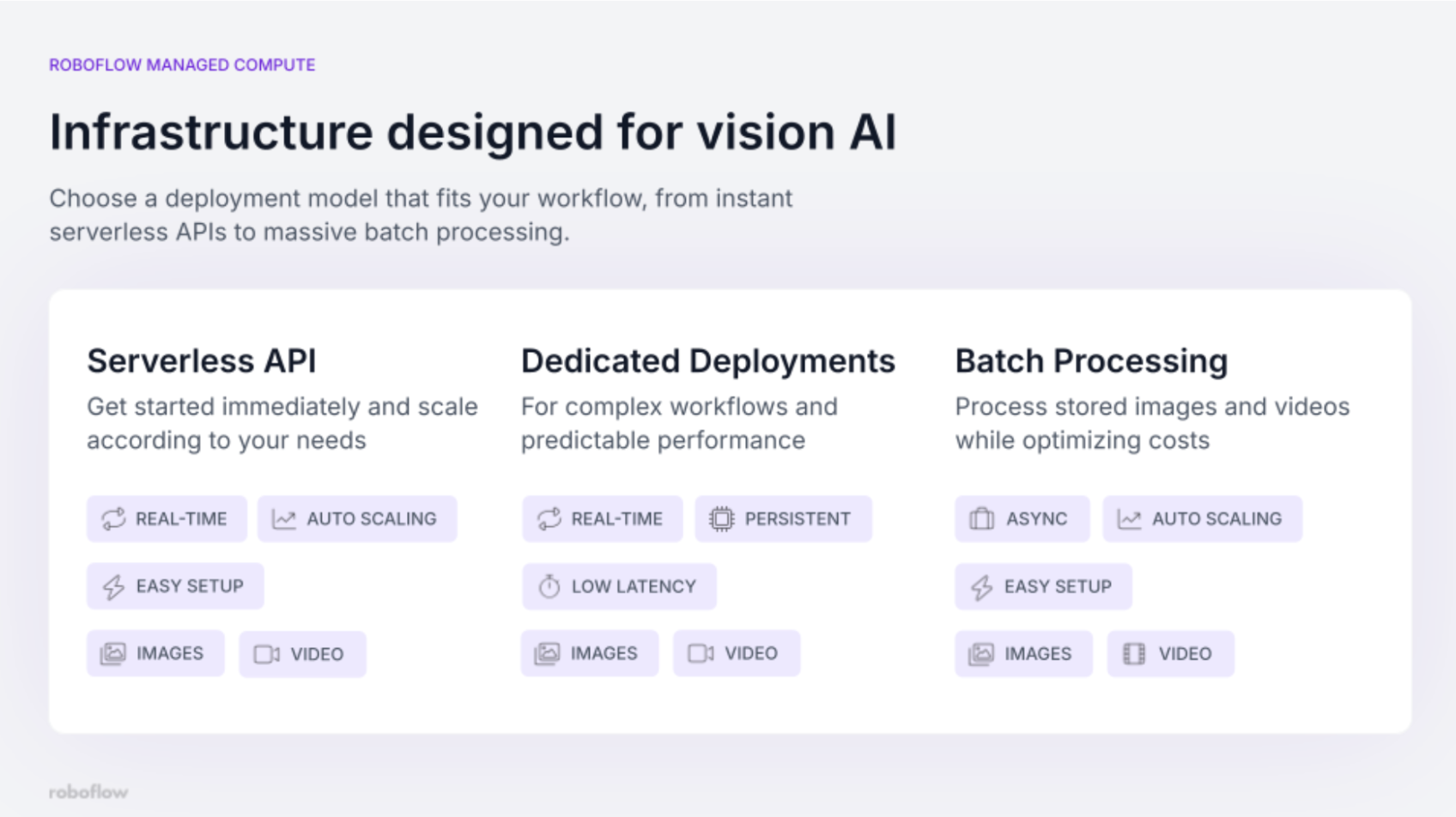
The Serverless API is the easiest entry point. It scales automatically in real-time, requires no setup beyond an API key, and is ideal for variable or unpredictable traffic. If you're prototyping, handling bursty loads, or want to get something live today without thinking about infrastructure at all, this is where to start.
Dedicated Deployments are for teams with predictable, high-volume workloads who need consistent, low-latency performance. A persistent deployment means your model is always running and always available. If you're running a 24/7 production pipeline where latency consistency matters, a dedicated deployment is recommended.
Batch Processing handles the other end of the spectrum: large volumes of stored images or video where the amount of data processed matters more than latency. Batch jobs run asynchronously and are cost-optimized for high-volume workloads. This includes: processing archived footage, running periodic audits, or generating labels at scale.
Inference as a Service with Roboflow
Whether you're running a prototype or scaling to millions of inferences per day, Roboflow's inference platform is built to meet you where you are.
Explore Roboflow's options or reach out to our team to identify a solution that meets your needs.
Learn about increasing inference speed.
Written by Aryan Vasudevan
Cite this Post
Use the following entry to cite this post in your research:
Contributing Writer. (Mar 2, 2026). Inference as a Service: How Roboflow Makes Vision AI Production-Ready. Roboflow Blog: https://blog.roboflow.com/inference-as-a-service/