
When you are building computer vision applications, you will inevitably come across the term “inference.” Inference means running your model on an input to receive an output.
For example, consider an object detection model trained to identify defects in bottle tops. “Running inference” on this model would mean to run the model on an input image. The model will then return “bounding boxes” which correspond to the location of objects in the image that the model has been trained to identify.
In this guide, we are going to talk about what inference is in the context of computer vision, different approaches to running inference, and how to choose an inference server. Without further ado, let’s get started!
What Is Inference?
Inference means running an AI model with an input to retrieve some kind of output. In the context of computer vision, inference means passing an image to a model to retrieve whatever the model has been trained to return. An object detection model will return bounding boxes that correspond to objects in an image; a segmentation model will return pixel-perfect polygons of objects in an image; a classification model will return one or more labels for a whole image.

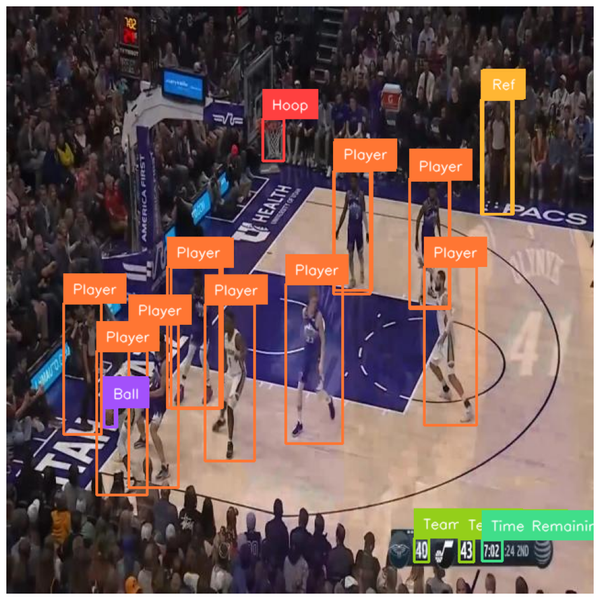

Inference Steps
The inference process involves a few steps: pre-processing, running inference, and post-processing.
Before running a model, you may want to pre-process your data in some way. Many inference servers – which let you run models – will, for example, automatically resize images to be the right resolution for the model that you want to use.
When your input data is ready, the model can then “infer” on your data. This involves running all the low-level algorithms that a model uses to return an output.
After running a model, many models or inference servers apply – or can apply, if configured – various post-processing techniques. For object detection, for example, an inference server may run Non-Maximum Suppression (NMS). This is an algorithm that lets you remove duplicate and closely-overlapping bounding boxes.
The pre- and post-processing steps required to run an image through a model (to “run inference”) vary between models.
After Inference
Once you have results from the inference step (bounding boxes for object detection, segmentation masks for image segmentation, labels for classification, etc.) the next step is to integrate the results into your application. In the context of enterprise applications, you can think of the next step as implementing business logic.
For example, you may be running an object detection model trained to identify defects on a manufacturing line. If a defect is found by your model, the assembly line could be set up to automatically move the defective product for manual inspection. The defect could also be logged so the line can monitor the incidence rate of defects over time.
Synchronous and Asynchronous Inference
Models are either run in real time (synchronously) or in batches (asynchronously). Which method you choose depends on your business requirements and the speed at which your trained model can run.
Running Inference in Real Time
Many state-of-the-art computer vision models can run in real time. For example, RF-DETR, the current state-of-the-art in object detection, can run at dozens of frames per second on an NVIDIA GPU like a T4.
To run inference in real time, you will typically train a smaller model. For computer vision, smaller models are typically given labels like Nano and Small. The smaller the model, the faster it will run.
There are many scenarios where models are run in real time, for example:
- If you are inspecting products in a manufacturing facility that are on an assembly line, you need real-time performance.
- If you are monitoring security camera footage overnight for entrances into a building, you will need real-time performance.
- If you are building a mobile application that is interactive, the model needs to run in real-time so that the application maintains its interactivity.
Models that are capable of running in real time typically run in milliseconds (ms). You will see ms commonly used to measure inference times in model benchmarks. For example, the Nano version of RF-DETR can return predictions in 2.32ms on an NVIDIA T4 GPU.
Running Inferences in Batches
There are also scenarios where you want to run a model asynchronously. This means running a model at any time, such as on a defined schedule (daily). Running a model on data in batches is called “batch processing”.
Batch processing is commonly used to process high volumes of data that have already been collected for which you do not need real-time insights. For example, you may process a large catalogue of archived video footage or images in batches. Or you may process data that has been collected on a given day in a batch at the end of the day.
Running Inference
There are two main ways to run a computer vision model:
- Using the SDK provided by a model, such as the rfdetr Python package for RF-DETR, or;
- Using an inference server such as Roboflow Inference.
SDKs provided by models will implement everything you need to run a model. With that said, they often do not have all the features you might want or need in a production environment. For example, SDKs often have to be wrapped in boilerplate code to be accessible as a REST API, or extended with your own code to support video processing.
This is where an Inference server comes in.
Inference servers allow you to run models as a “microservice”. This means that your model can run as an endpoint that all of your applications can call, rather than as code running directly within your application.
Running your model as a “microservice” with an inference server offers several advantages. First, microservices can be scaled up using modern infrastructure tools like Kubernetes to support higher or lower workloads depending on load.
Second, microservices are isolated from the rest of your application, which means you can manage their dependencies in a separate environment. This is notable because many vision models have extensive dependencies and can be hard to configure, particularly when designed for GPU edge deployment setups like an NVIDIA Jetson with TRT configured.
Inference servers may implement several helpful tools for you to build logic on top of your model. For example, Roboflow Inference lets you run Workflows.
Workflows are multi-stage computer vision applications built around a model. You can build Workflows in a web interface using your model weights, then get the code you need to run the Workflow on your hardware.
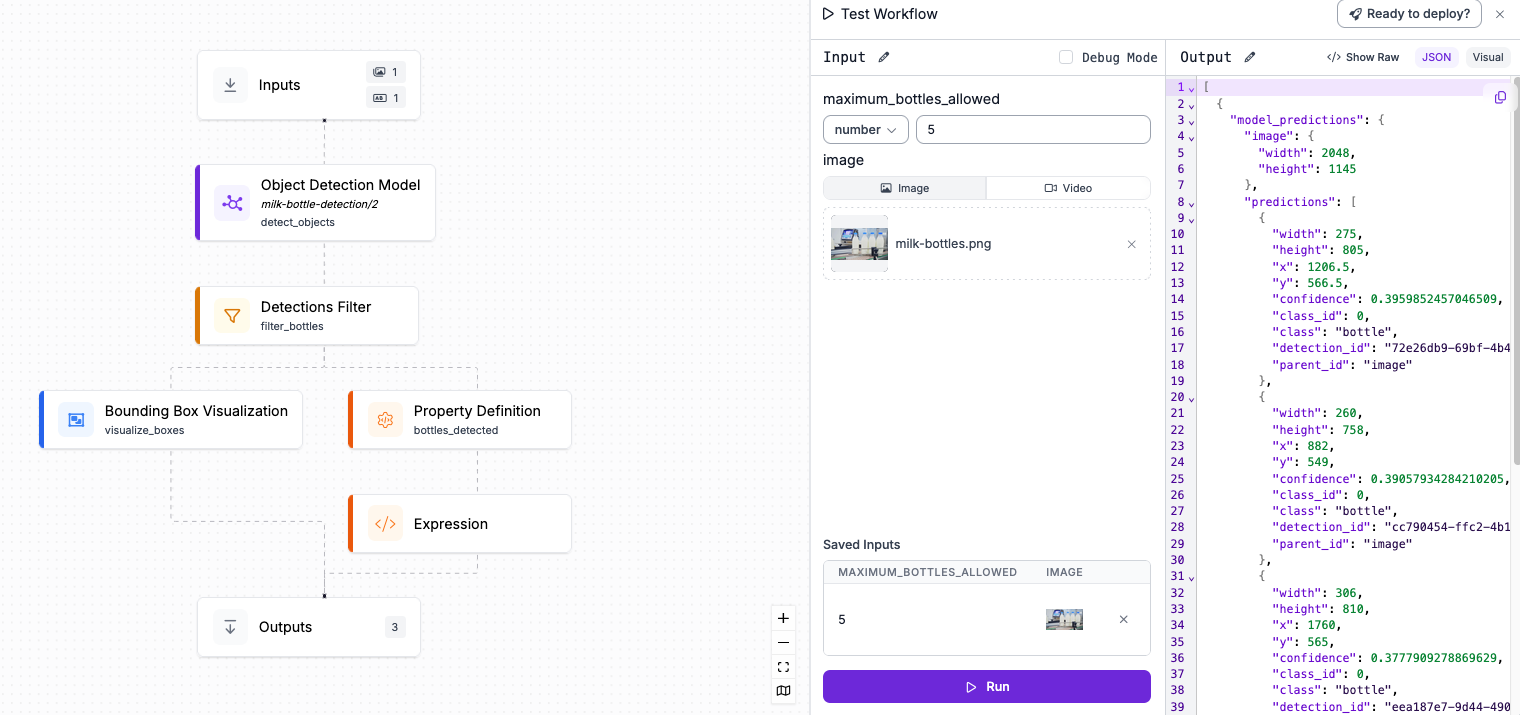
You can use Roboflow Workflows to track objects in a video, smooth predictions across video frames, filter predictions, run consensus algorithms with multiple models, and more.
What to Look For in an Inference Server
There are several inference servers available that you can use to run models. When you are choosing an inference server, there are a few things for which you should look out.
First, look at what models are supported. Does the inference server support state-of-the-art models? Second, look at any benchmarking data available. How fast does the inference server run? The inference server may also provide utilities for you to run your own benchmarks. This is ideal for evaluating the performance of the server and a model on your own hardware.
Next, look for the capabilities of the server and see if they meet your requirements. For example, if you are going to be processing video, look for servers that have features specifically for video. Roboflow Inference supports object tracking in videos, smoothing predictions across video frames, and more.
Inference servers may also provide utilities for monitoring your models and managing your devices. Roboflow Inference offers an extension for enterprises that makes it easy to check device health, update models, set up new Workflows, and more.
Inference in Computer Vision Conclusion
Inference in computer vision means the process of running a model.
Before running inference, a model may pre-process input data (i.e. an image) so that it is ready for the model. The model software will then “run inference” on the input data and return predictions. The type of predictions will vary by model (i.e. Bounding boxes for object detection, masks for segmentation).
The results from inference can then be integrated into an application. For instance, you may log results from a model, or use the results in additional business logic.
You can run models directly using model software or using an inference server. Inference servers are designed both to run models and to provide additional utilities useful for running models, such as video processing tools, model and device monitoring, and more.
Ready to start running inference on a model? Check out our gallery of 100+ templates of computer vision applications. All of our templates include models that you can run, as well as additional logic that uses the output from model inference to do something.
Cite this Post
Use the following entry to cite this post in your research:
James Gallagher. (Oct 3, 2025). What Is Inference In Computer Vision?. Roboflow Blog: https://blog.roboflow.com/inference-computer-vision/