
Excitement is building in the artificial intelligence community around MIT's recent release of liquid neural networks. The breakthroughs that Hasani and team have made are incredible. In this post, we will discuss the new liquid neural networks and what they might mean for the vision field.
Let's get started with a video explanation of what a liquid neural network is and why they are important. After the video, we'll discuss the concepts of liquid neural networks in text to help you solidify your understanding.
Video version of this post. Don't forget to subscribe to our YouTube.
The Backdrop: Before Liquid Neural Networks
Artificial intelligence research and applications involve the construction and training of deep neural networks. Until liquid neural networks, all deep learning systems have shared the same vulnerability - namely, that they learn a fixed mapping from input data to output prediction based on the training data that they are shown, making them brittle to the shifting environment around them. Furthermore, most deep learning models are context independent. For example, when applying an object detection model or a classification model to a video, the video will be processed frame by frame without relying on the context around it.
Inferring frame by frame (without context) on the Roboflow Ranch
To fix this problem, developers and engineers using artificial intelligence typically gather very large, representative datasets and engage in active learning to continuously improve their systems through re-training cycles as new edge cases are discovered.
However, all of this re-labeling, re-training and re-deployment can be tedious - wouldn't it be nice if the network you were using learned to adapt to new scenarios online?
Enter the Liquid Neural Network.
What is a Liquid Neural Network?
The liquid neural network is a form of recurrent neural network where the network learns continuously as new data is fed in. This type of neural network has shown strong performance and making predictions based on sequences such as text streams, or time series data from scientific measurements. Liquid neural networks were defined by initially defined by a team of researchers at MIT.
The liquid approach is in contrast to traditional neural networks where a model needs to be retrained and redeployed if new scenarios need to be learned.
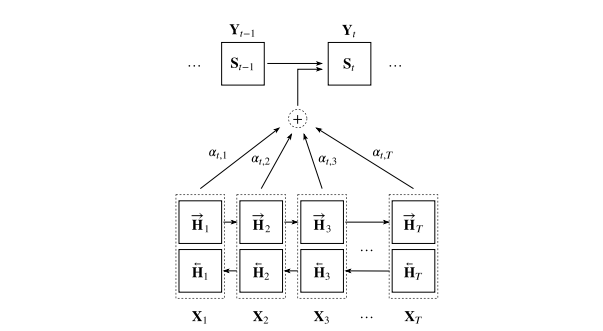
Recurrent neural networks exceed the performance of normal, feed forward neural networks when the input data is a sequence, because they can more efficiently keep track of relevant information at different parts of the sequence.
The liquid neural network builds on the recurrent neural network by making hidden states that are dynamic on the time constant in the time series. At each prediction step, the liquid neural network is computing both the predicted outcome as well as the formation of the next hidden state, evolving in time.

For more implementation details, we recommend a deep dive into the liquid neural network paper.
The Liquid Neural Network Promise
The liquid neural network is shown to improve on time series modeling across a variety of domains - human gestures, human activities, traffic, power, ozone, sequential MNIST, and occupancy. These initial results are promising.
The long term goal of a liquid neural network is to form a system that is flexible with scene and time, eventually unlocking a system that does not have to be consistently improved via active learning.
How do Liquid Neural Networks Impact Vision?
In the long term, architectures like liquid neural networks may dramatically improve our ability to train resilient models in video processing, that are able to adapt around their changing environment.
However, the impact of liquid neural networks on vision is a long way off. The initial experiments in the liquid neural network repository are all time series based, not based on images and video.
Processed files:
1. Vectorial velocity of left hand (x coordinate)
2. Vectorial velocity of left hand (y coordinate)
3. Vectorial velocity of left hand (z coordinate)
4. Vectorial velocity of right hand (x coordinate)
5. Vectorial velocity of right hand (y coordinate)
6. Vectorial velocity of right hand (z coordinate)
7. Vectorial velocity of left wrist (x coordinate)
8. Vectorial velocity of left wrist (y coordinate)
9. Vectorial velocity of left wrist (z coordinate)
10. Vectorial velocity of right wrist (x coordinate)
11. Vectorial velocity of right wrist (y coordinate)
12. Vectorial velocity of right wrist (z coordinate)
13. Vectorial acceleration of left hand (x coordinate)
14. Vectorial acceleration of left hand (y coordinate)
15. Vectorial acceleration of left hand (z coordinate)
16. Vectorial acceleration of right hand (x coordinate)
17. Vectorial acceleration of right hand (y coordinate)
18. Vectorial acceleration of right hand (z coordinate)
19. Vectorial acceleration of left wrist (x coordinate)
20. Vectorial acceleration of left wrist (y coordinate)
21. Vectorial acceleration of left wrist (z coordinate)
22. Vectorial acceleration of right wrist (x coordinate)
23. Vectorial acceleration of right wrist (y coordinate)
24. Vectorial acceleration of right wrist (z coordinate)
25. Scalar velocity of left hand
26. Scalar velocity of right hand
27. Scalar velocity of left wrist
28. Scalar velocity of right wrist
29. Scalar velocity of left hand
30. Scalar velocity of right hand
31. Scalar velocity of left wrist
32. Scalar velocity of right wrist
33. phase:
-- D (rest position, from portuguese "descanso")
-- P (preparation)
-- S (stroke)
-- H (hold)
-- R (retraction)
Example data for the time series data for gestures in liquid neural networks
Generalizing to image and video for application from their repository, will inevitably involve future research and construction from the lab at MIT.
Conclusion
Liquid neural networks are a new breakthrough in recurrent neural networks, creating a model that adopts flexibly through time. The research, however, is in progress and it will likely be a while before we see these networks making an impact over incumbent strategies in computer vision.
For more on recent research in computer vision, check out our posts on:
If you'd like to get started training the current state of the art in computer vision, check out:
Cite this Post
Use the following entry to cite this post in your research:
Jacob Solawetz. (Feb 12, 2021). Liquid Neural Networks in Computer Vision. Roboflow Blog: https://blog.roboflow.com/liquid-neural-networks/