
Mask R-CNN extends Faster R-CNN to produce pixel-level instance segmentation masks alongside standard bounding box detections. Its key architectural additions are a mask head branch that generates per-object segmentation outputs, ROIAlign (which replaces ROIPool to fix spatial misalignment), and a Feature Pyramid Network for multi-scale feature extraction. The model performs well on overlapping objects and complex scenes but carries high computational cost, struggles with very small objects, and requires a large annotated training set to reach strong accuracy.
Mask R-CNN, short for Mask Region-based Convolutional Neural Network, is an extension of the Faster R-CNN object detection algorithm used for both object detection and instance segmentation tasks in computer vision.
The significant changes introduced by Mask R-CNN from Faster R-CNN are:
- Replacing ROIPool with ROIAlign to handle the problem of misalignments between the input feature map;
- The region of interest (ROI) pooling grid, and;
- The use of Feature Pyramid Network (FPN) that enhances the capabilities of Mask R-CNN by providing a multi-scale feature representation, enabling efficient feature reuse, and handling scale variations in objects.
What sets Mask R-CNN apart is its ability to not only detect objects within an image but also to precisely segment and identify the pixel-wise boundaries of each object. This fine-grained segmentation capability is accomplished through the addition of an extra "mask head" branch to the Faster R-CNN model.
In this blog post, we will take an in-depth look at Mask R-CNN works, where the model performs well, and what limitations exist with the model.
Without further ado, let’s begin!
What is Mask R-CNN?
Mask R-CNN is a deep learning model that combines object detection and instance segmentation. It is an extension of the Faster R-CNN architecture.
The key innovation of Mask R-CNN lies in its ability to perform pixel-wise instance segmentation alongside object detection. This is achieved through the addition of an extra "mask head" branch, which generates precise segmentation masks for each detected object. This enables fine-grained pixel-level boundaries for accurate and detailed instance segmentation.
Two critical enhancements integrated into Mask R-CNN are ROIAlign and Feature Pyramid Network (FPN). ROIAlign addresses the limitations of the traditional ROI pooling method by using bilinear interpolation during the pooling process. This mitigates misalignment issues and ensures accurate spatial information capture from the input feature map, leading to improved segmentation accuracy, particularly for small objects.
FPN plays a pivotal role in feature extraction by constructing a multi-scale feature pyramid. This pyramid incorporates features from different scales, allowing the model to gain a more comprehensive understanding of object context and facilitating better object detection and segmentation across a wide range of object sizes.
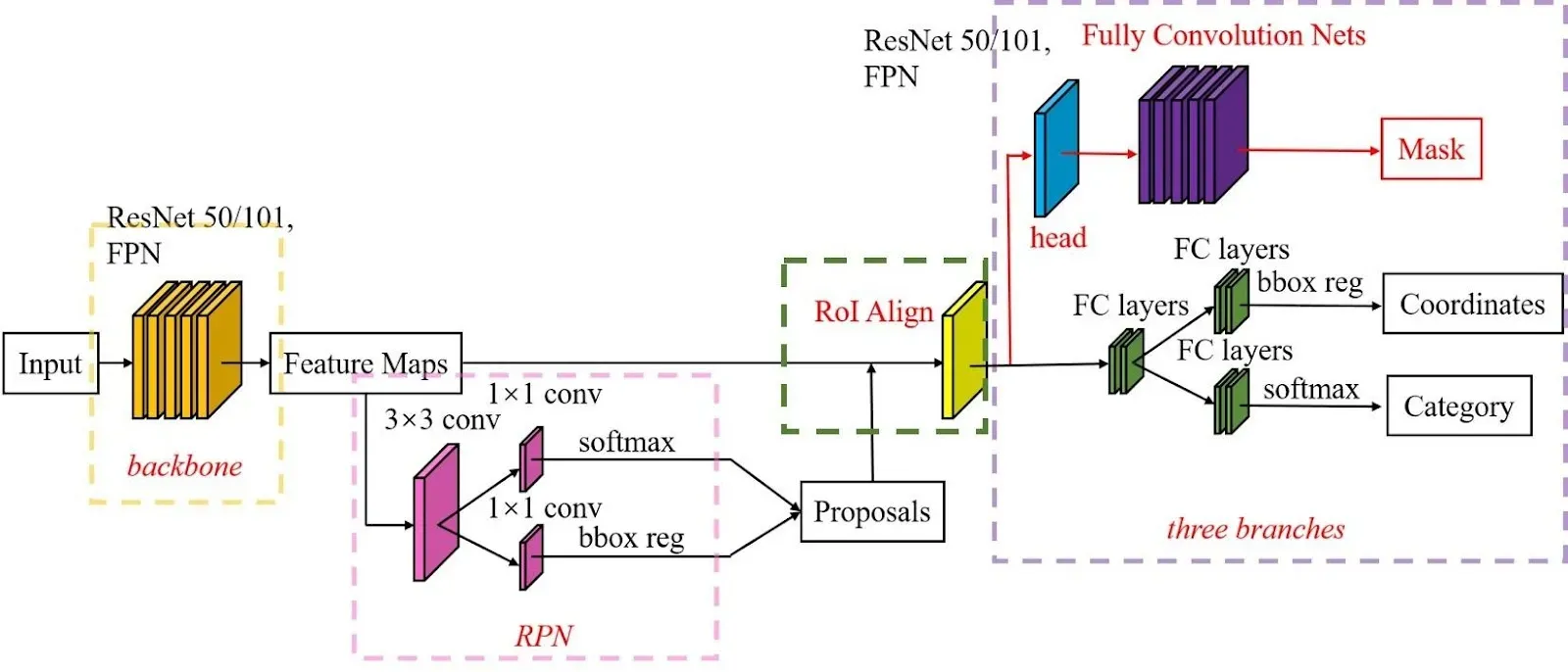
Mask R-CNN Architecture
The architecture of Mask R-CNN is built upon the Faster R-CNN architecture, with the addition of an extra "mask head" branch for pixel-wise segmentation. The overall architecture can be divided into several key components:
Backbone Network
The backbone network in Mask R-CNN is typically a pre-trained convolutional neural network, such as ResNet or ResNeXt. This backbone processes the input image and extracts high-level features. An FPN is then added on top of this backbone network to create a feature pyramid.
FPNs are designed to address the challenge of handling objects of varying sizes and scales in an image. The FPN architecture creates a multi-scale feature pyramid by combining features from different levels of the backbone network. This pyramid includes features with varying spatial resolutions, from high-resolution features with rich semantic information to low-resolution features with more precise spatial details.
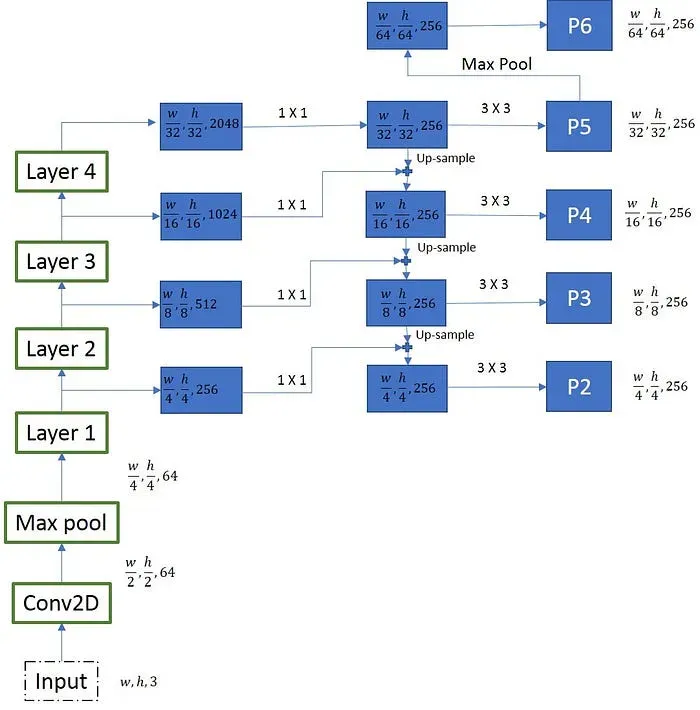
The FPN in Mask R-CNN consists of the following steps:
- Feature Extraction: The backbone network extracts high-level features from the input image.
- Feature Fusion: FPN creates connections between different levels of the backbone network to create a top-down pathway. This top-down pathway combines high-level semantic information with lower-level feature maps, allowing the model to reuse features at different scales.
- Feature Pyramid: The fusion process generates a multi-scale feature pyramid, where each level of the pyramid corresponds to different resolutions of features. The top level of the pyramid contains the highest-resolution features, while the bottom level contains the lowest-resolution features.
The feature pyramid generated by FPN enables Mask R-CNN to handle objects of various sizes effectively. This multi-scale representation allows the model to capture contextual information and accurately detect objects at different scales within the image.
Region Proposal Network (RPN)
The RPN is responsible for generating region proposals or candidate bounding boxes that might contain objects within the image. It operates on the feature map produced by the backbone network and proposes potential regions of interest.
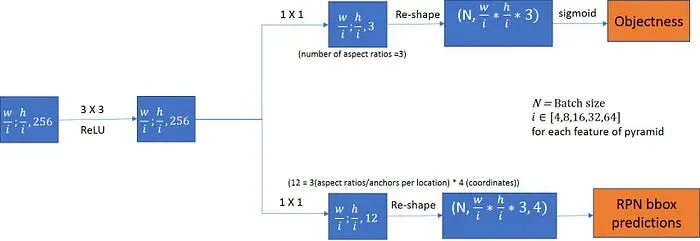
ROIAlign
After the RPN generates region proposals, the ROIAlign (Region of Interest Align) layer is introduced. This step helps to overcome the misalignment issue in ROI pooling.
ROIAlign plays a crucial role in accurately extracting features from the input feature map for each region proposal, ensuring precise pixel-wise segmentation in instance segmentation tasks.
The primary purpose of ROIAlign is to align the features within a region of interest (ROI) with the spatial grid of the output feature map. This alignment is crucial to prevent information loss that can occur when quantizing the ROI's spatial coordinates to the nearest integer (as done in ROI pooling).
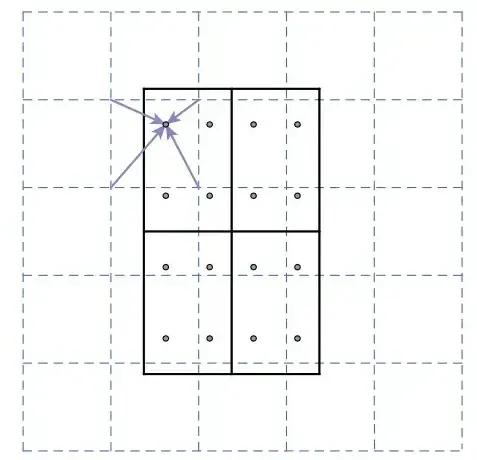
The ROIAlign process involves the following steps:
- Input Feature Map: The process begins with the input feature map, which is typically obtained from the backbone network. This feature map contains high-level semantic information about the entire image.
- Region Proposals: The Region Proposal Network (RPN) generates region proposals (candidate bounding boxes) that might contain objects of interest within the image.
- Dividing into Grids: Each region proposal is divided into a fixed number of equal-sized spatial bins or grids. These grids are used to extract features from the input feature map corresponding to the region of interest.
- Bilinear Interpolation: Unlike ROI pooling, which quantizes the spatial coordinates of the grids to the nearest integer, ROIAlign uses bilinear interpolation to calculate the pooling contributions for each grid. This interpolation ensures a more precise alignment of the features within the ROI.
- Output Features: The features obtained from the input feature map, aligned with each grid in the output feature map, are used as the representative features for each region proposal. These aligned features capture fine-grained spatial information, which is crucial for accurate segmentation.
By using bilinear interpolation during the pooling process, ROIAlign significantly improves the accuracy of feature extraction for each region proposal, mitigating misalignment issues.
This precise alignment enables Mask R-CNN to generate more accurate segmentation masks, especially for small objects or regions that require fine details to be preserved. As a result, ROIAlign contributes to the strong performance of Mask R-CNN in instance segmentation tasks.
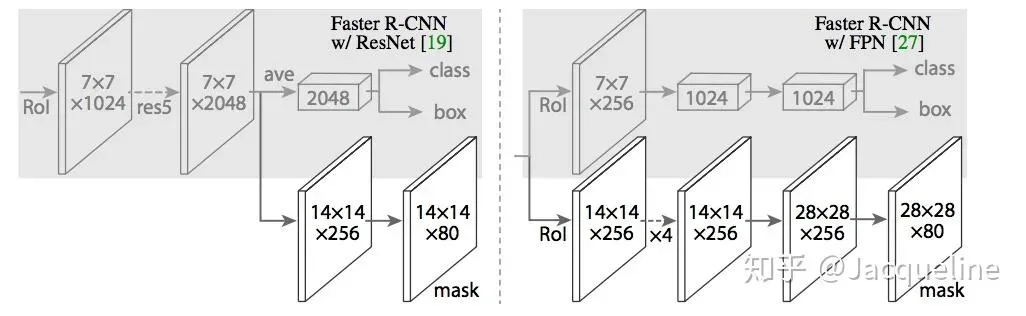
Mask Head
The Mask Head is an additional branch in Mask R-CNN, responsible for generating segmentation masks for each region proposal. The head uses the aligned features obtained through ROIAlign to predict a binary mask for each object, delineating the pixel-wise boundaries of the instances. The Mask Head is typically composed of several convolutional layers followed by upsample layers (deconvolution or transposed convolution layers).
During training, the model is jointly optimized using a combination of classification loss, bounding box regression loss, and mask segmentation loss. This allows the model to learn to simultaneously detect objects, refine their bounding boxes, and produce precise segmentation masks.
Mask R-CNN Performance
In the table below we show the instance segmentation Mask R-CNN performance and some visual results on COCO test dataset.
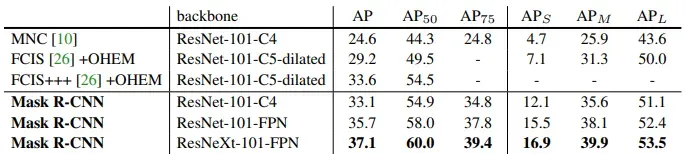
The COCO 2015 and 2016 segmentation challenges were won by the MNC and FCIS models, respectively. Surprisingly, Mask R-CNN achieved better results than the more intricate FCIS+++, which incorporates multi-scale training/testing, horizontal flip testing, and OHEM. It's noteworthy that all the entries represent outcomes from individual models.

Mask R-CNN Limitations
Mask R-CNN excels in multiple areas, making it a powerful model for various computer vision tasks such as object detection, instance segmentation, multi-object segmentation, and complex scene handling.
However, Mask R-CNN has some limitations to consider:
- Computational Complexity: Training and inference can be computationally intensive, requiring substantial resources, especially for high-resolution images or large datasets.
- Small-Object Segmentation: Mask R-CNN may struggle to accurately segment very small objects due to limited pixel information.
- Data Requirements: Training Mask R-CNN effectively requires a large amount of annotated data, which can be time-consuming and expensive to acquire.
- Limited Generalization to Unseen Categories: The model's ability to generalize to unseen object categories is limited, especially when data is scarce.
Conclusion
Mask R-CNN merges object detection and instance segmentation, providing the capability to not only detect objects but also to precisely delineate their boundaries at the pixel level. By using a Feature Pyramid Network (FPN) and the Region of Interest Align (ROIAlign), Mask R-CNN achieves strong performance and accuracy.
Mask R-CNN does have certain limitations, such as its computational complexity and memory usage during training and inference. It may encounter challenges in accurately segmenting very small objects or handling heavily occluded scenes. Acquiring a substantial amount of annotated training data can also be demanding, and fine-tuning the model for specific domains may require careful parameter tuning.
Cite this Post
Use the following entry to cite this post in your research:
Petru P.. (Aug 9, 2023). What is Mask R-CNN? The Ultimate Guide.. Roboflow Blog: https://blog.roboflow.com/mask-rcnn/