
Artificial intelligence (AI) is evolving beyond just single-modality learning, that is, systems trained on just one type of input, such as only images or only text. Today’s leading models, including OpenAI’s GPT-5, Google’s Gemini, Microsoft’s Florence-2, and Meta’s Llama 3.2 Vision, are multimodal models that can interpret and reason over multiple forms of data, such as images, text, audio, and video. This allows them to perform complex perception and reasoning tasks that were once impossible for traditional vision or language models.
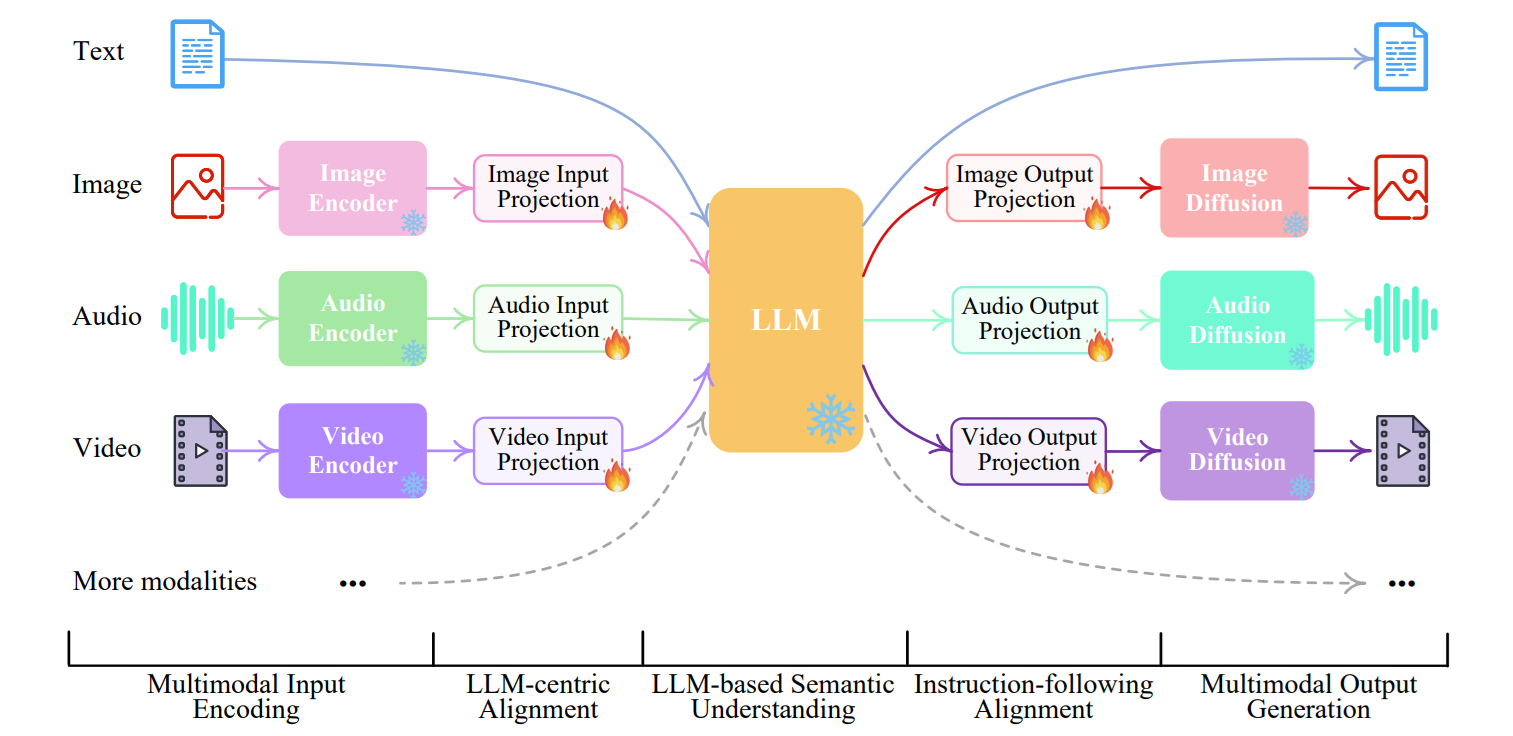
Multimodal annotation is the foundational step in building such systems. It refers to the process of labeling datasets that combine different modalities, for example:
- Image-Text pairs: Product photos with descriptions or medical scans with diagnostic notes.
- Video-Audio: Surveillance footage paired with environmental sound recordings.
- Audio-Text: Speech clips annotated with transcripts or emotional tone.
Unlike traditional image labeling, multimodal annotation requires understanding relationships between data types. Annotators must connect what is seen in an image to what is described in accompanying text. For example, an image might show a robotic arm assembling a metal component while a sensor displays shows “Torque Limit Exceeded” . The accompanying caption reads “Robot halted due to excess torque during tightening process”.
The annotator must verify that the visual evidence (stopped arm position, torque-sensor warning on screen, and unfinished assembly) correctly matches the textual description. This ensures that the dataset teaches the model to relate visual conditions (machine behavior, warning indicators) to contextual text (error messages or operator logs), which is important for applications like automated fault diagnosis and predictive maintenance. When done well, these datasets enable advanced applications such as:
- Visual Question Answering (VQA): A model receives both an image and a textual question, then generates an answer based on visual content. For example, given a photo of a factory control panel, the model can answer, “What is the current warning message on the display?” or “Which machine is offline?”
- Image Captioning: The automatic generation of natural-language descriptions that summarize the contents of an image. For example, the system produces captions such as “A robotic arm tightening bolts on an engine housing” or “Worker calibrating pressure gauges in assembly line B.”
- Generative Dialogue Agents: Interactive AI systems that can see and discuss visual inputs. For example, an automated camera system uploads a snapshot of a machine panel, and the AI agent replies, “The coolant temperature appears too high, check valve 3B.”
- Audio-Visual Event Detection: Recognizing and classifying events that are characterized by both visual and auditory signals. For example, recognizing events like “metal collision,” “bearing noise,” or “safety alarm triggered” by combining vibration audio with camera feeds.
- Automated Report Generation: Producing structured or narrative text summaries derived from visual or multimodal inputs. For example, after analyzing images from a thermal camera, the model generates a maintenance report noting “Overheating detected near motor housing, recommend inspection of fan unit.”
As industries adopt these systems, multimodal annotation is becoming a key enabler for AI based perception and decision-making in healthcare, manufacturing, robotics, autonomous driving, agriculture, sports analytics, and more.
What Are Multimodal Annotation Tools?
Traditional annotation requires a single type of data, or modality. For example, adding bounding boxes around objects in images, drawing segmentation masks in videos, or marking named entities in text. Each of these tasks focuses on one data form only.
Multimodal annotation, on the other hand, brings several data types together in one dataset. This means annotating not just images or text separately but also linking them, such as pairing an image with its caption, connecting a spoken sentence to its transcript, or matching a video scene to its audio description.
The goal is to teach AI models how different kinds of information relate to each other. A multimodal annotation workflow usually involves several key steps such as:
- Data preparation: Cleaning and organizing raw inputs such as images, videos, text, or audio recordings so they can be labeled consistently.
- Annotation: Using specialized tools that allow annotators to view and label multiple modalities at once, for example, viewing an image with its associated text.
- Alignment: Ensuring that elements across modalities correspond correctly (e.g., the right sentence matches the right video frame or the right caption matches the right region in an image).
- Quality control: Checking the dataset for consistency and accuracy. Mistakes in one modality can cause problems in others. For example, a misaligned caption can confuse the model. Techniques like cross-checking between modalities or using multiple reviewers to help prevent errors.
- Integration: Finally, the labeled data from different modalities are combined into a single structured format that can be used to train multimodal AI models.
Multimodal annotation tools allow researchers and developers to build richer, more realistic datasets that actually reflect how humans naturally combine vision, sound, and language when understanding the world.
What Are Data Modalities?
A data modality refers to the type or form of information that an AI system can receive, process, or learn from. Each modality captures the world in a different way as visual, textual, auditory, or sensory and provides a unique layer of understanding.
Common modalities used in AI are:
- Images and Video (Visual): Provide spatial and temporal details such as color, texture, motion, and object interactions.
- Text (Linguistic): Conveys symbolic meaning, context, and relationships between entities (for example, a written report or caption).
- Audio: Carries tone, rhythm, and environmental cues that describe sound events or speech.
- Sensor or Time-Series Data: Includes temperature, vibration, or motion signals collected over time, often used in IoT or industrial monitoring.
Why Do Multiple Modalities Matter?
Humans naturally combine multiple senses to understand the world, i.e. seeing, hearing, and reading context simultaneously. Similarly, AI systems that learn from multiple data modalities gain a more holistic understanding. For example:
- A video may show a robotic arm moving, but only when paired with text does the system know the task is “welding a chassis.”
- An image might show a control panel with lights on, but the text can explain that it indicates “overheating detected.”
- A sound recording may capture machine noise, while sensor data confirms rising vibration levels.
- By combining modalities, models can achieve richer context, higher accuracy, and stronger reasoning than those trained on single data types.
Understanding these different data modalities is the foundation for multimodal annotation. The next step is learning how annotation tools bring these diverse data types together into a single, structured dataset.
How to Choose a Multimodal Annotation Tool
Multimodal annotation is still relatively new compared to image-only or video-only annotation. There are only a few platforms currently support it, and even those are still improving their capabilities. Because of that, choosing the right tool requires evaluating not just the interface, but how well it handles the complexity of connecting different data types, such as images, text, audio, or sensor inputs into a single coherent dataset. Below are the key factors to consider when selecting a multimodal annotation platform.
Supported Modalities and Editors
The most basic requirement is that the tool can import, display, and label all the data types your project needs. For computer vision tasks, that typically means support for:
- Images and videos (for visual context)
- Text data (captions, metadata, instructions, or prompts)
- Audio or sensor data, if your workflow involves synchronized sound or measurements
For example, if your goal is to train a model that interprets both machine-panel images and their textual error logs, your platform must let you view and label both simultaneously ideally within a single interface.
AI-Assisted Labeling and Active Learning
Labeling multimodal data manually can be time-consuming and expensive. Modern tools increasingly include AI-assisted options such as:
- Pre-labeling with existing models (e.g., object detection or OCR to mark text regions automatically).
- Auto-suggestion features for bounding boxes, captions, or key phrases.
- Active learning workflows that automatically identify uncertain or diverse samples for human review.
Even simple automation can dramatically speed up annotation and help maintain consistency across modalities.
Workflow Management and Quality Control
Since multimodal datasets are complex, managing annotation workflows is just as important as labeling itself. Look for tools that offer:
- Version control and dataset tracking.
- Review and approval stages to verify annotations before export.
- Cross-modality validation, ensuring that text descriptions match the corresponding image or audio.
- Multi-annotator review to reduce bias and increase reliability.
Quality control is important, a small error in text alignment or incorrect visual reference can propagate through the dataset and degrade model accuracy.
Integration, Export Formats, and Automation
The platform should easily integrate with your existing ML workflow. Important aspects include:
- Standardized export formats (such as JSON, CSV, or COCO-style schemas for multimodal data).
- API or SDK access for automating uploads, downloads, and active learning loops.
- Compatibility with major machine learning frameworks so that your annotated data can be directly used for model training or fine-tuning.
If your project involves multimodal vision-language models, check whether the tool supports exporting paired data (e.g., image + text prompt + answer) for training.
Collaboration and Scalability
Multimodal projects usually involve multiple contributors such as data scientists, subject experts, and quality reviewers. A scalable annotation tool should provide:
- Role-based access control.
- Task assignment and progress tracking.
- Real-time dashboards for monitoring annotation status.
- Communication tools or comments for reviewer feedback.
These features become crucial as the size of your dataset and annotation team grows.
Cost and Licensing
Pricing models vary widely:
- Some tools charge per image, label, or annotation hour.
- Others offer subscription tiers with different levels of support or API access.
- Open-source tools are free but often lack advanced multimodal editing or automation.
When budgeting, consider not just licensing fees but also the cost of training annotators, managing workflows, and ensuring data quality. Multimodal annotation tools are still evolving, but they are essential for building the next generation of AI systems that combine vision, language, and sound.
When choosing a platform, prioritize flexibility, accuracy, and workflow transparency over just features. The right tool will help your team align visual and textual data seamlessly and enable richer, context-aware models that go far beyond traditional computer vision tasks.
Multimodal Annotation Tools
In this section, learn about three tools that can be used to annotate multimodal dataset for training multimodal AI models.
Roboflow
Roboflow is widely recognized for its computer vision workflow capabilities, and recently expanded its platform to support multimodal annotation. Introduced in late 2024, this update allows users to label and review multimodal datasets. This is a key step toward training vision-language models. With this addition, teams can now prepare datasets suitable for models that understand both visual inputs and textual context.
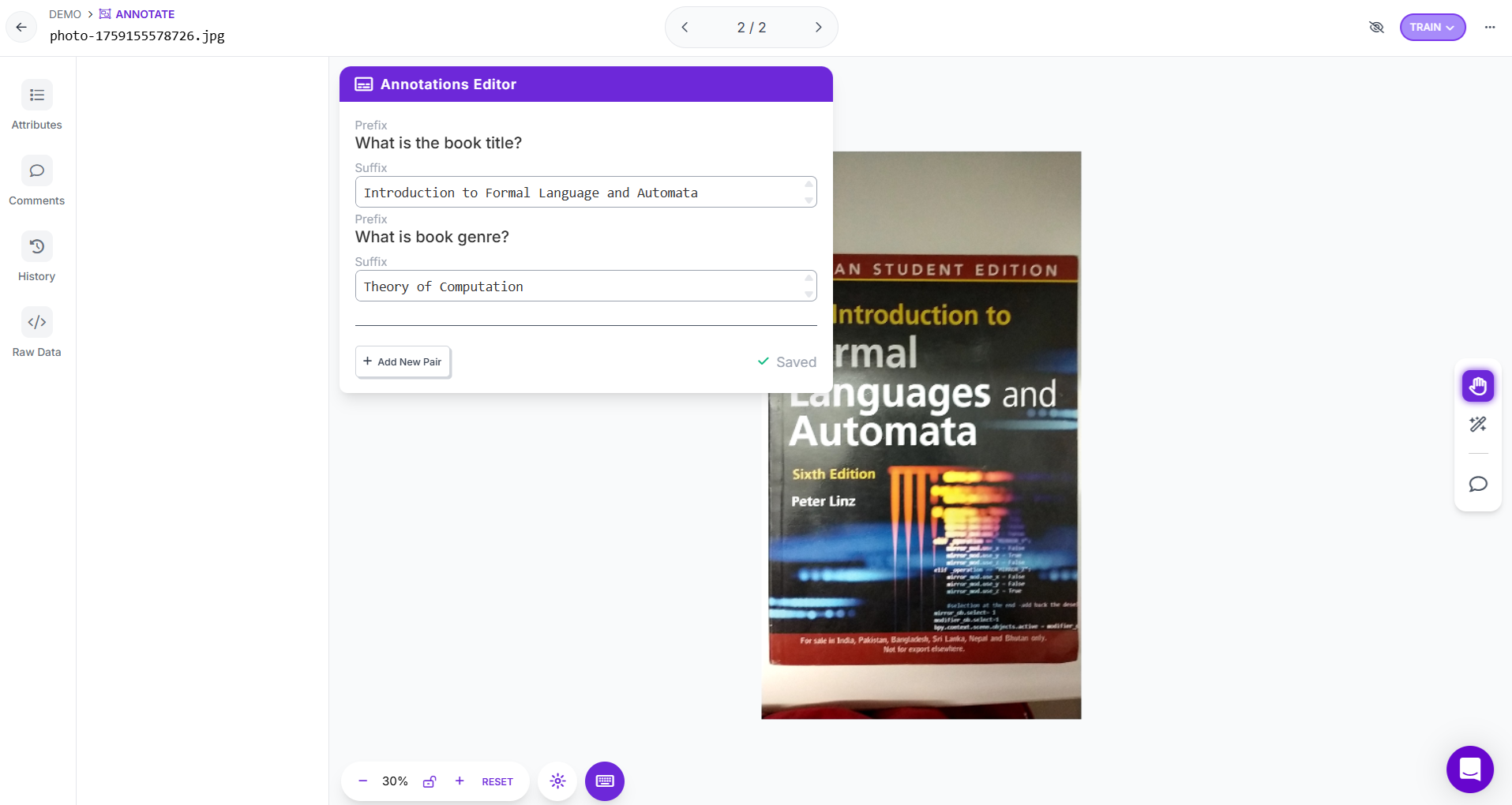
Following are the key features of Roboflow focusing on multimodal annotations:
- Multimodal Project Type: Roboflow allows to create specialized project designed for multimodal annotation as well as training. This setup enables pairing images with text inputs, allowing annotation tasks that combine both visual and linguistic information. It is useful for vision–language training use cases like image captioning or Visual Question Answering (VQA).
- Prompt-Based Annotation: Each annotation includes a prompt (a text question or instruction) that defines what the model should learn from the image. For example, “How many players are in this image?” or “Describe what action is being performed.”
- Text-Response Labeling: Annotators view the image alongside the text prompt and enter the correct response or answer directly into a text field. This produces structured image-text pairs suitable for Visual Question Answering (VQA) or image description tasks.
- Dataset Versioning and Export: After labeling, datasets can be versioned and exported in JSON or other structured formats that preserve both image paths and associated text data, making them ready for training modern vision–language models.
- Visual Review and Quality Assurance: The Roboflow interface lets reviewers instantly verify whether the text responses correctly describe what’s visible in the image to help ensure semantic alignment between modalities.
- Collaboration and Project Management: The platform includes role-based permissions, analytics, and version tracking to help teams manage labeling projects efficiently and monitor progress in shared datasets.
Roboflow extends its strengths in computer vision into the emerging space of multimodal annotation with a clean, user-friendly interface and seamless dataset management. It’s built-in export options ensure compatibility with popular vision-language model formats. At present, Roboflow can be used for multimodal projects focused on captioning, visual question answering, and image description.
Labelbox
Labelbox is a data annotation platform built to support multimodal AI projects. It provides a unified workspace for labeling and managing diverse data types including images, text, video, audio, documents, and geospatial data. Through its Label Blocks interface, Labelbox enables teams to view and annotate multimodal data, bringing context and structure to datasets used for training vision-language and generative AI models. Its flexible ontology design, attachment system, and review workflows make it a powerful tool for organizations working on large-scale, context-rich data pipelines.
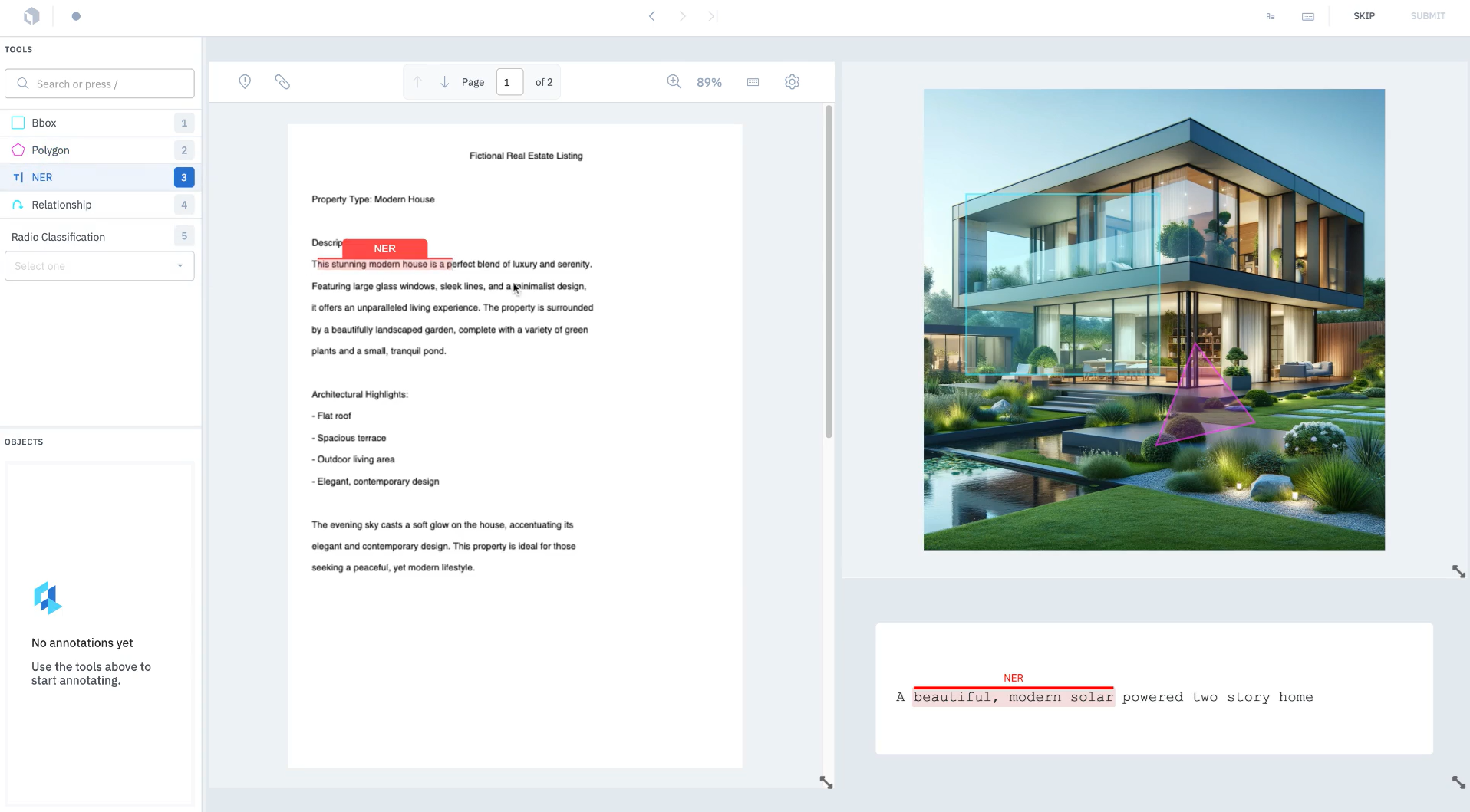
Following are the key features of Labelbox focusing on multimodal annotations:
- Support for Multiple Modalities: The tool supports a wide range of data types such as images, text, video, audio, and sensor data and allows combining these modalities in a single labeling task.
- Unified Labeling Interface: Labelbox’s Label Blocks is the integrated platform/interface designed to handle different modalities in one unified workspace.
- Attachment-Based Editor with Context & Instructions: In the editor, annotators can view attachments or supplementary data (such as documents, transcripts, or metadata) alongside the main asset. Instructions, context, and information panels can be attached at the data-row level to help guide annotation.
- Workflow: Labelbox Workflows let teams create step-by-step labeling and review processes. Each task (like labeling, review, or rework) can be customized with rules. This helps manage quality, assign roles, and move data rows smoothly through the annotation pipeline.
- Customizable Data Row Information: Labelbox allows customizing the data-row tab to include metadata fields, tags, media attributes, and instructions. This helps annotators see relevant context while labeling.
- Collaboration, Versioning & Quality Control: The Labelbox supports project management features such as versioning, review workflows, and collaborative annotation.
Labelbox's attachment-based editor, customizable workflow panels, and support for both local and global judgments make it well suited for enterprise applications that require precise context alignment across modalities. However, engineering teams that prioritize data privacy, security, and full control - especially when working with proprietary or sensitive datasets - often use Roboflow.
SuperAnnotate
SuperAnnotate is an end-to-end AI data platform for multimodal annotation, dataset management, and model evaluation. It combines automation with human expertise to deliver high-quality labeled data across diverse modalities, including images, videos, text, and audio. It also provides multimodal templates that let you start your annotation schema with predefined layout structures for common vision-language tasks. The platform enables teams to design custom workflows, automate repetitive tasks, and maintain strong quality control through human-in-the-loop review. With built-in analytics and collaboration tools, SuperAnnotate serves as a complete environment for managing data pipelines and evaluating AI models throughout their lifecycle.
Following are the key features of SuperAnnotate focusing on multimodal annotations:
- Support for multiple modalities: SuperAnnotate’s broad modality support means that it can handle and label multiple forms of data such as images, video, text, and audio within one unified project. This is essential for preparing datasets used to train multimodal models, which learn to understand and relate information across different sensory inputs.
- Dedicated Multimodal Project Type: SuperAnnotate includes a special Multimodal project option (besides Image, Video/Audio, Text, etc.), enabling you to combine data modalities in a single task.
- Custom Form Builder & Templates: When creating a multimodal project, you can either use pre-existing templates or build your annotation UI from scratch. You can mix components (fields, displays) as needed to support your multimodal use case.
- Human-in-the-Loop Quality Assurance: SuperAnnotate combines automated labeling with human verification. Annotators can review and refine model suggestions to ensure each label meets quality standards, improving dataset reliability.
- Custom Workflows and Dataset Management: Users can design workflows to specific project needs, organize datasets, apply filters, and manage metadata. This helps teams handle large-scale multimodal projects efficiently.
- Model Evaluation and Integration: Beyond labeling, SuperAnnotate supports model evaluation and integration with major cloud services such as AWS, Google Cloud, and Azure, enabling teams to train, test, and improve models directly within the ecosystem.
- Project Management and Analytics: The platform provides dashboards and analytics tools for tracking labeling progress, monitoring performance metrics, and coordinating team activity which is essential for collaborative, enterprise-scale projects.
SuperAnnotate supports multiple data modalities and lets teams create flexible workflows that makes it ideal for large projects that handle different kinds of AI data. The platform’s human-in-the-loop review process helps maintain accuracy and consistency in annotations. However, teams that want to go beyond annotation and build full computer vision systems often use Roboflow's complete end-to-end platform.
Multimodal Annotation Using Roboflow
With a user friendly interface, users can define prompts, upload images, and provide text-based responses all within the same workspace in Roboflow. This workflow helps create structured image-text pairs that can train advanced vision–language models such as GPT-5 or Florence-2. In this section we will explore how to label a multimodal dataset. Just follow these simple steps:
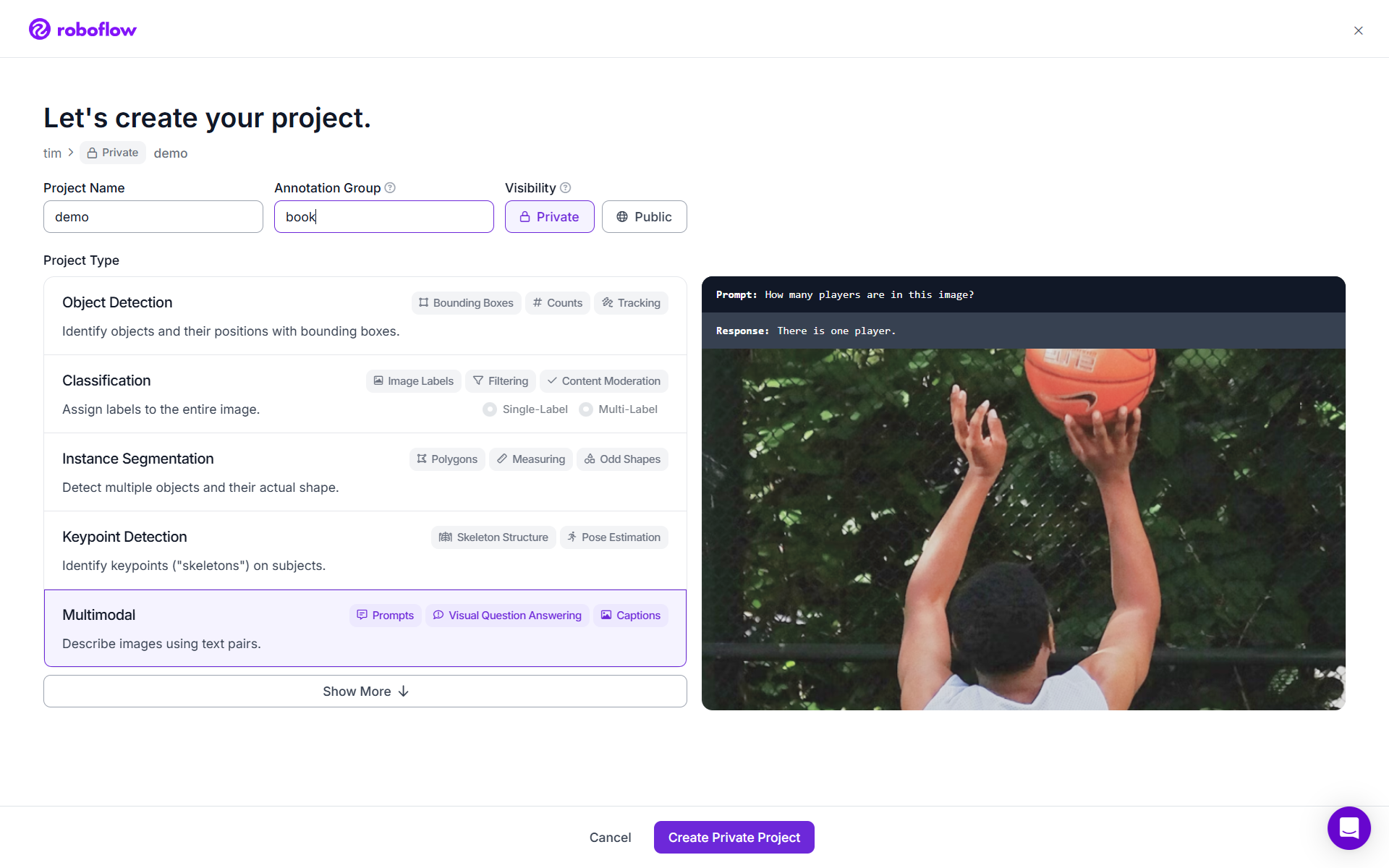
Step # 1: Create a New Project
- Go to your Roboflow workspace, click Create Project → enter your project name (e.g., “demo”).
- Select Project Type -> Multimodal. This mode is designed for datasets that combine image + text pairs. It supports use cases like visual question answering (VQA) and image captioning.
- Choose your annotation group (e.g., “book”) and visibility (Private or Public).
- Click Create Private Project to start.
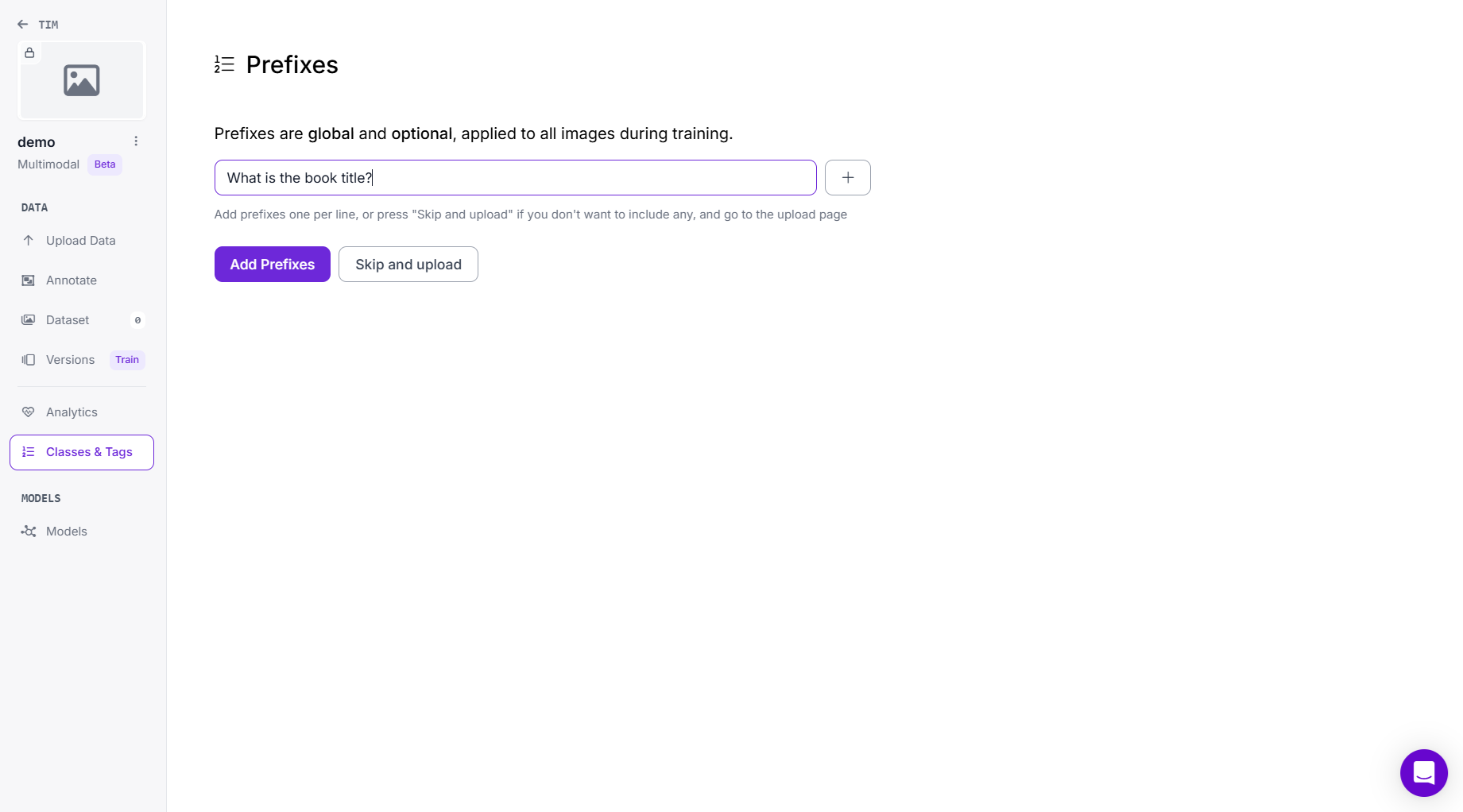
Step #2: Add Prefix Prompts
Once the project is created, Roboflow will prompt you to define prefixes. These are questions or instructions that apply to all images. Each prefix defines what the model will learn to answer from the image. A prefix can either be:
- Identifier-style prefix
- Looks like a placeholder token (e.g., <TOTAL> or <PREFIX>).
- Useful when fine-tuning models like Florence-2, which expect a structured token input rather than a full natural language question.
- The model sees <TOTAL> and knows it should output “the total value shown in the image.”
- Question-style prefix
- A natural language question like “What is the total in this image?”
- Works well for models like GPT-4o or general VQA (Visual Question Answering) setups that understand full language prompts.
- Annotators see the question and then enter the answer (e.g. “$56.58”).
So you can choose whether your prefix is a symbolic token or a full question, depending on your target model architecture and training format.
In this example I used following prefix:
- “What is the book title?”
- “What is the book genre?”
Type each prefix and click Add Prefixes, then proceed to upload data.
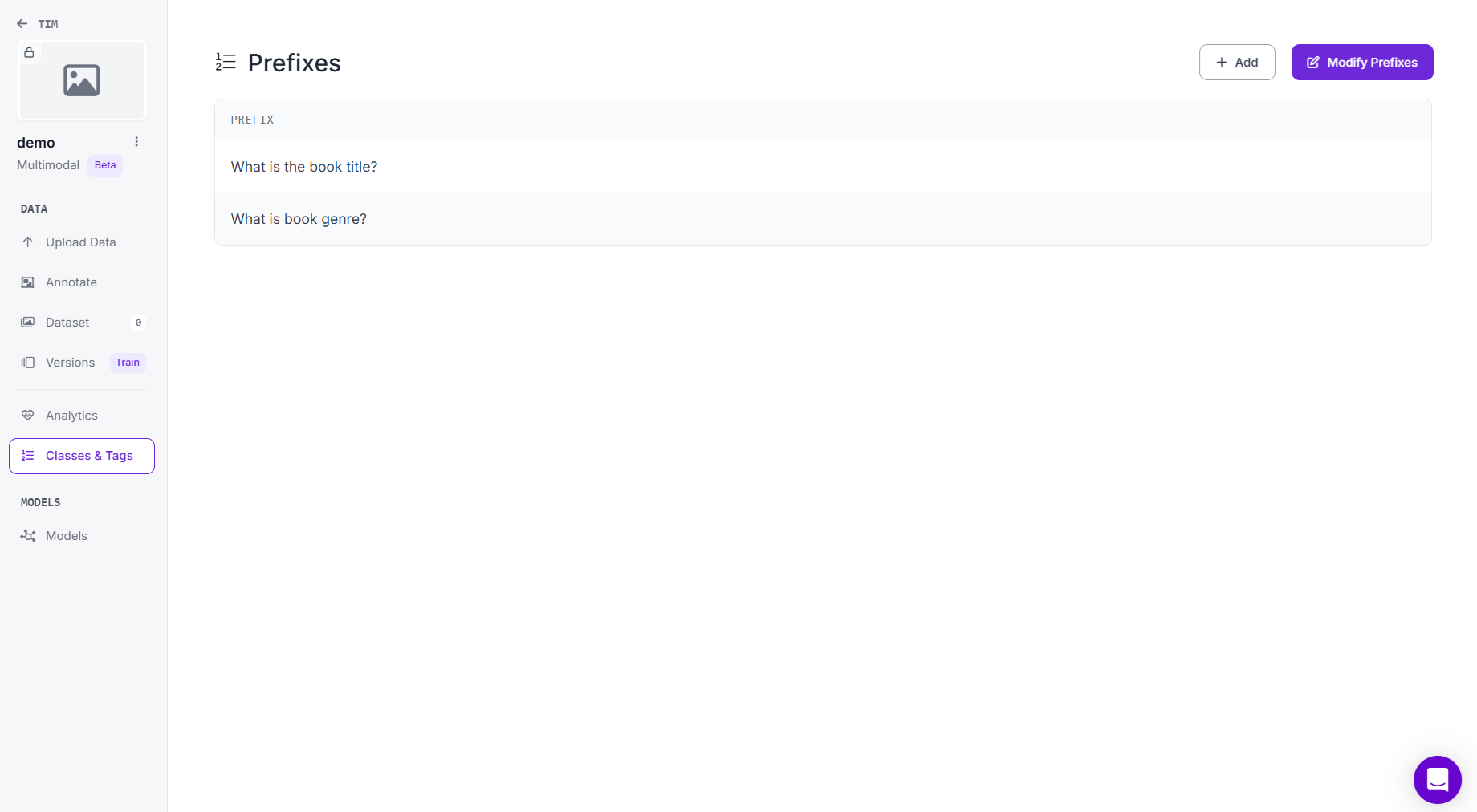
Step # 3: Upload Images
Go to the Upload Data tab on the left panel. You can upload data via multiple methods:
- Drag-and-drop image files or folders.
- Scan QR Code to upload directly from your smartphone using the Roboflow mobile upload app.
- Search Roboflow Universe for open datasets.
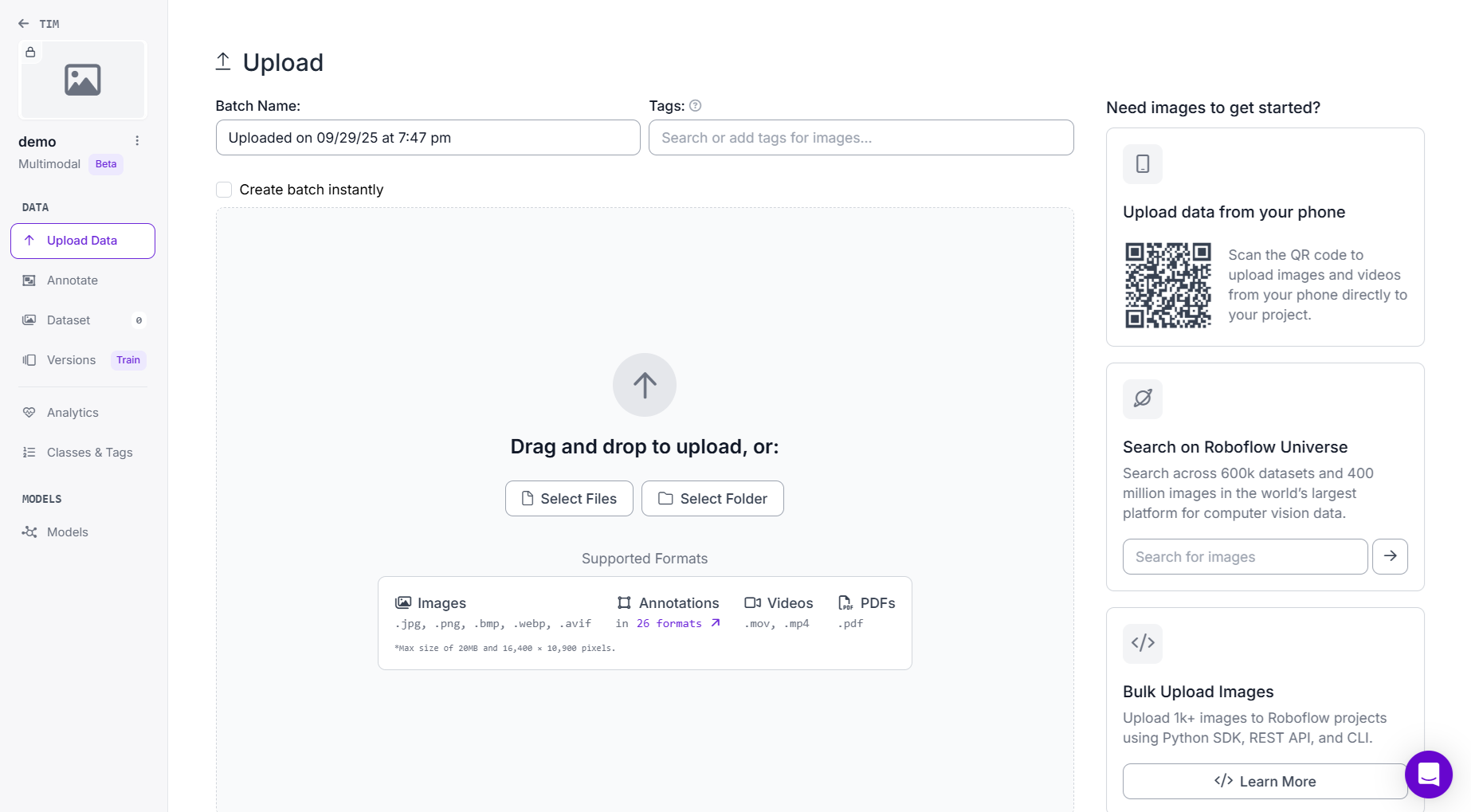
In my case, I used the QR code upload, this allows to capture and upload photos instantly from my phone.
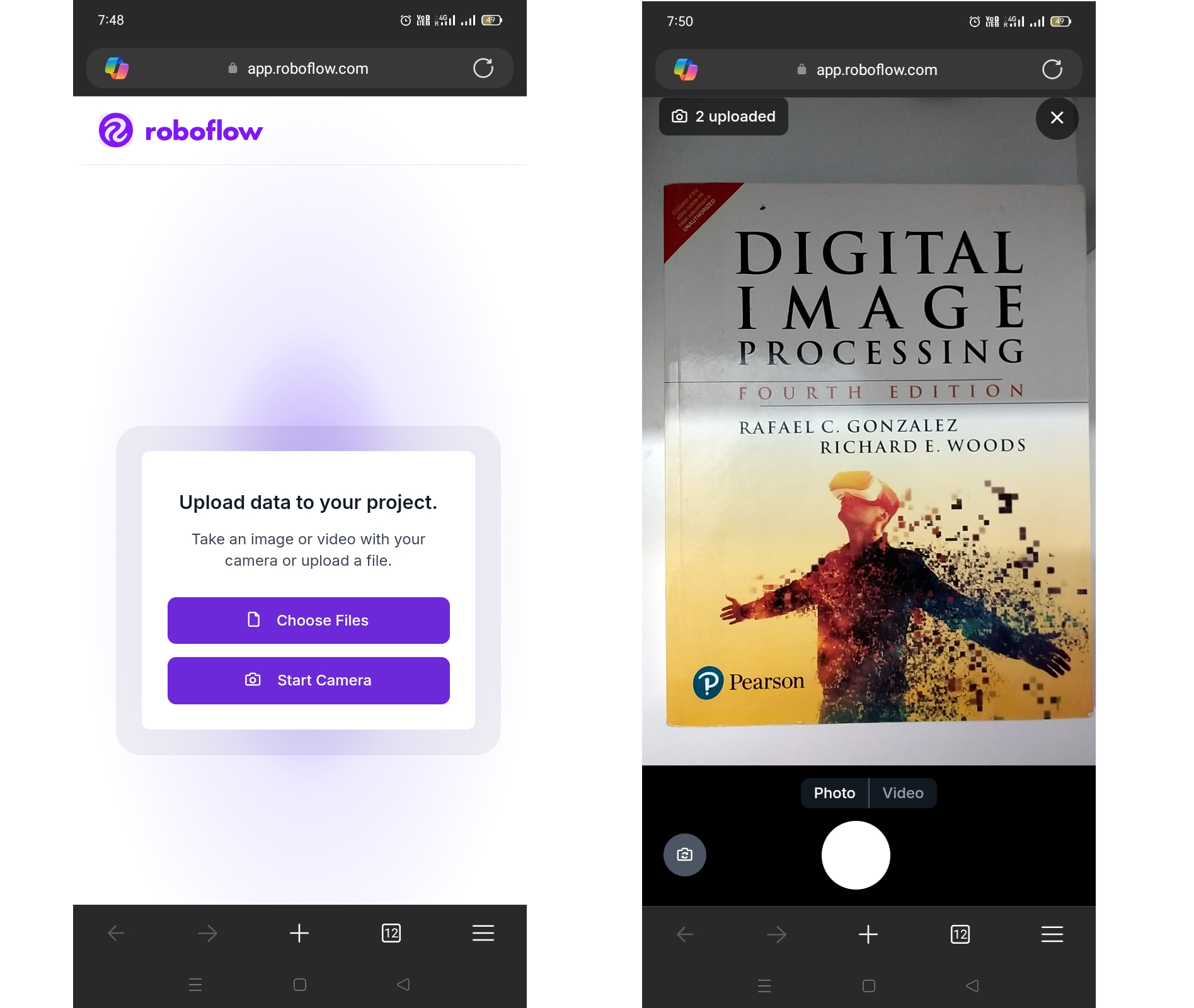
This method is useful for collecting real-world multimodal data quickly (like books, tools, or industrial components). You can upload the images on the go. Once uploaded, images appear in the batch under Upload Data.
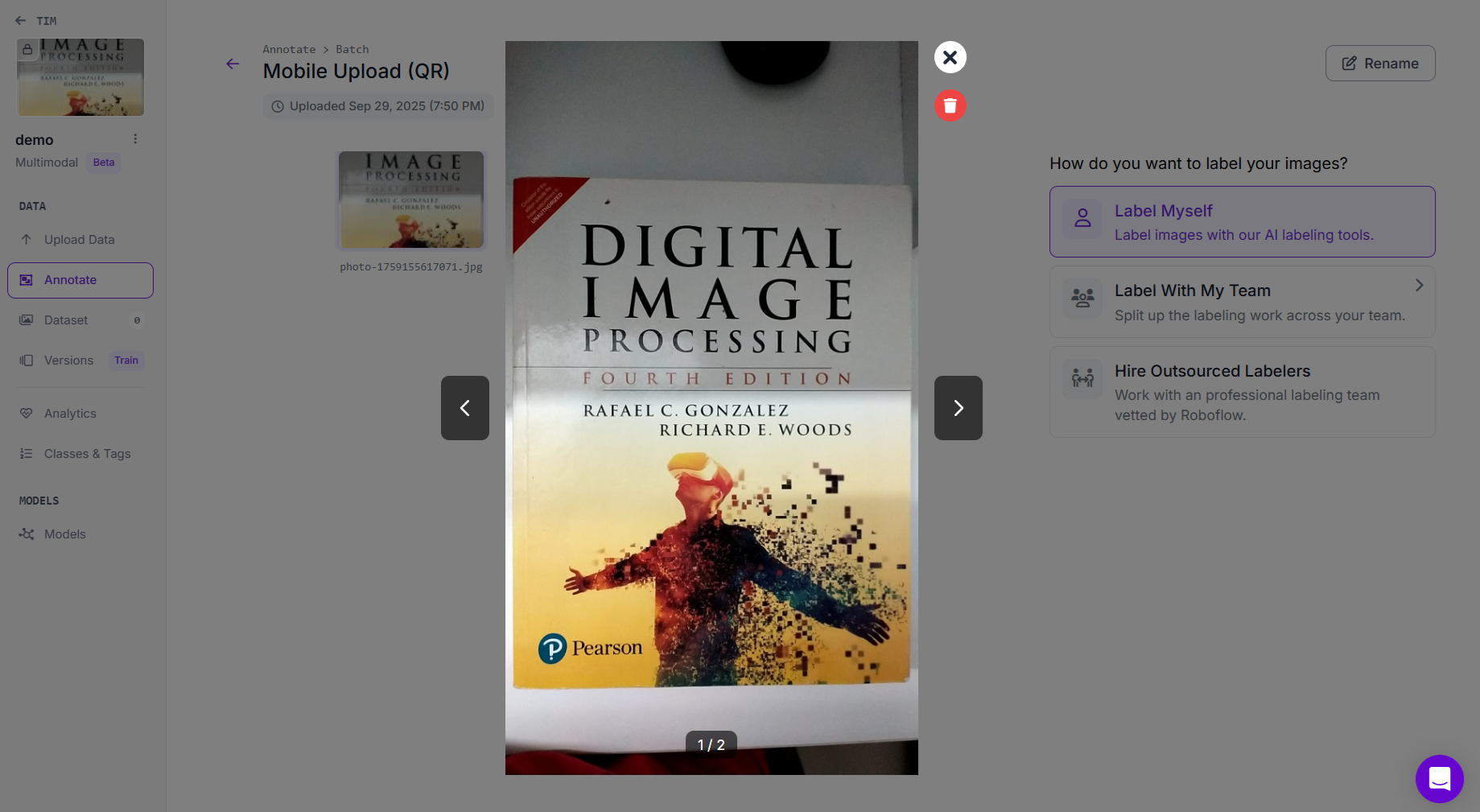
Step # 4: Annotate the Dataset
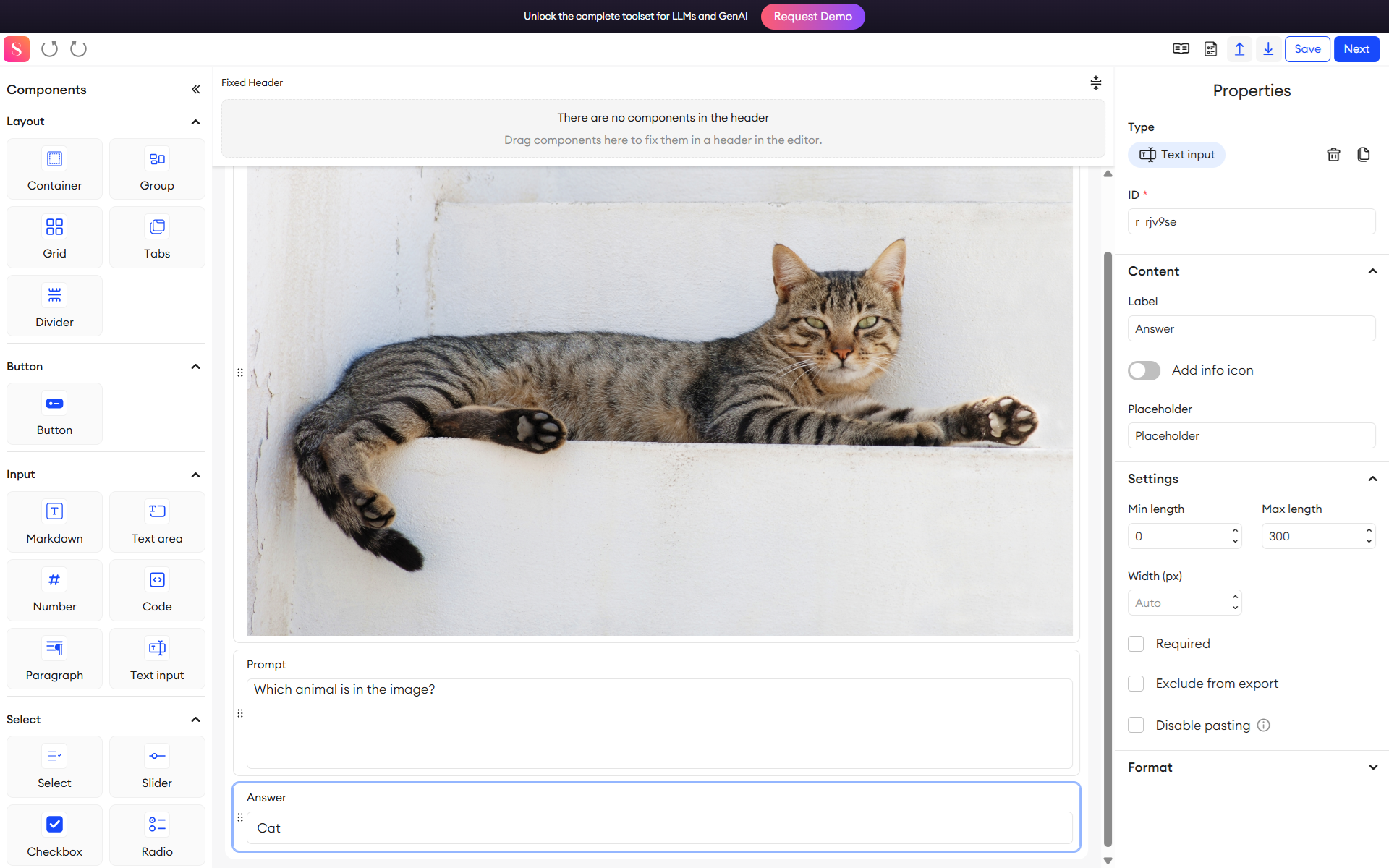
Go to Annotate from the left sidebar. Select an uploaded image to open the annotation interface. For each prefix (question or instruction), enter the corresponding text response.
For example:
Prefix: What is the book title?
Response: “Digital Image Processing”
Prefix: What is the book genre?
Response: “Computer Vision”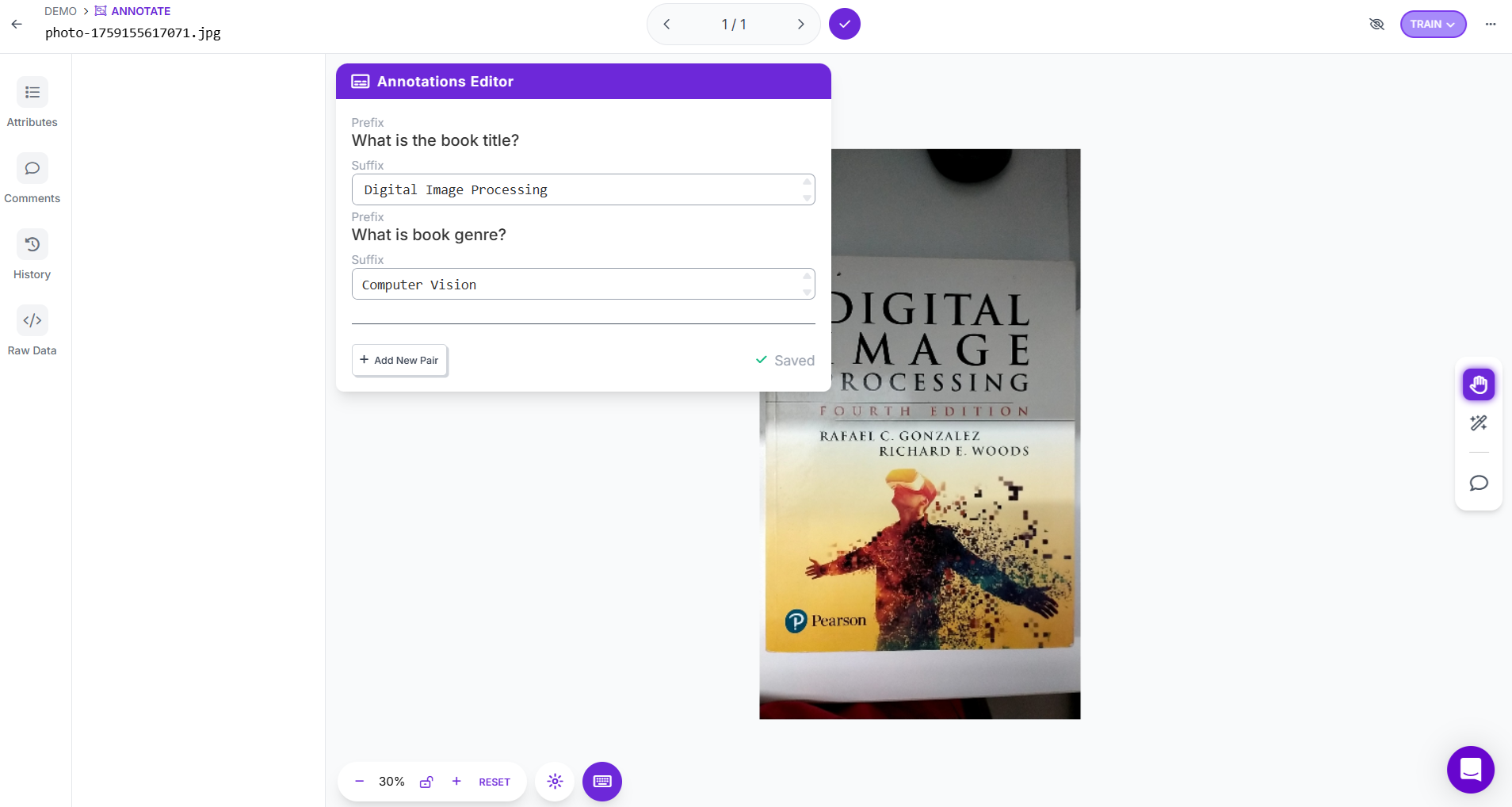
Save your responses they are stored as pairs linking the image and text.
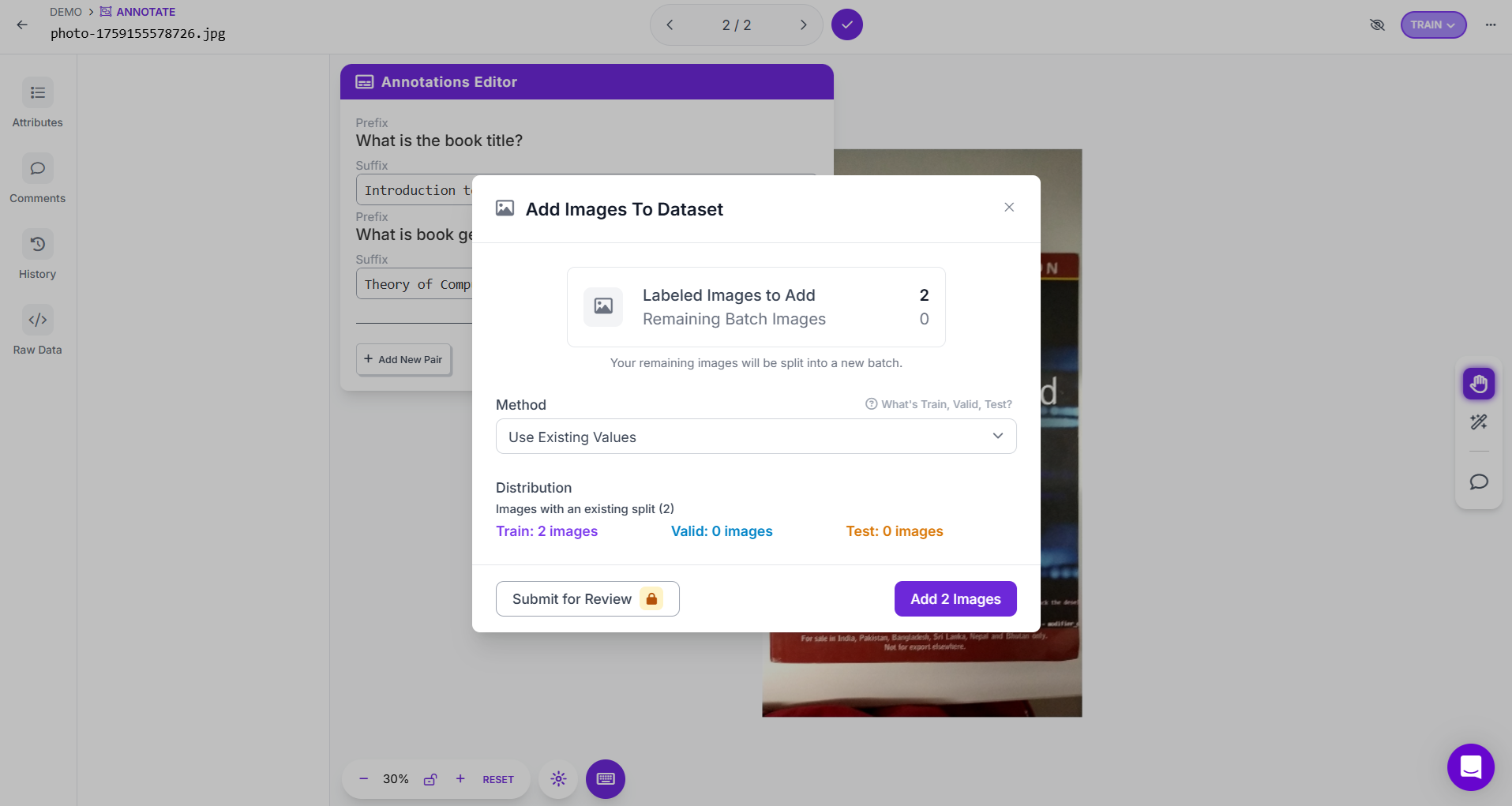
Step # 5: Add to Dataset and Version It
After labeling, add images to Dataset. Choose your data split (Train, Validation, Test) or keep existing splits. Click Add Image to confirm.
When ready, go to the Versions tab -> click Generate New Version. This step bundles your labeled data into a ready-to-export format.
Step #6: Export or Train Models
Once your dataset version is created, you can:
- Export in formats like OpenAI or JSONL, compatible with GPT, LLaVA, or Florence-2 vision-language models.
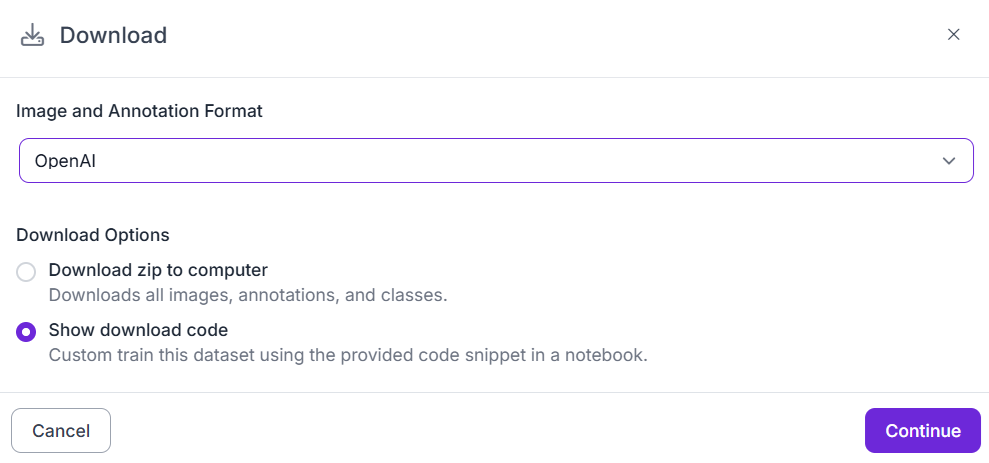
- Or use Roboflow Train to fine-tune your own multimodal model directly inside the platform.
Multimodal Annotation Tools Conclusion
Multimodal annotation is important for training next-generation AI systems that can see, hear, and understand language together. As models like GPT-5, Gemini, and Florence-2 evolve toward unified multimodal reasoning, tools such as Roboflow make it possible to create high-quality, context-rich datasets linking images, text, audio, and video.
Cite this Post
Use the following entry to cite this post in your research:
Timothy M. (Sep 30, 2025). Multimodal Annotation Tools. Roboflow Blog: https://blog.roboflow.com/multimodal-annotation-tools/