
OCR data extraction converts text in images into structured, machine-readable output, and the choice of approach matters significantly depending on the document type. Traditional models like Tesseract, EasyOCR, Surya, TrOCR, and DocTR transcribe visible text reliably, while vision-language models such as Florence-2, PaliGemma 2, GPT-4o, and Gemini go further by interpreting context, expanding abbreviations, inferring missing fields, and structuring output for downstream systems. This post walks through concrete Python examples using both Tesseract and GPT-4o to extract batch numbers, manufacturing dates, and expiration dates from a product label image.
In computer vision and artificial intelligence (AI), OCR (Optical Character Recognition) is a process used to extract text from images and convert it into an editable and searchable format. It enables computers to recognize and process textual information from images.
In this blog, we will dive into the practical aspects of using computer vision to extract text from images and integrate it into real-world applications. We'll explore popular OCR models. Additionally, we will also learn how to use Vision Language Models (VLMs) that enhance OCR data extraction by combining visual and linguistic understanding, offering powerful insights for text analysis.
For our example in this blog we will use following input image 'label.jpg' and programmatically read its contents.

Let's get started!
Vision Language Models (VLMs) for OCR
Vision-Language Models (VLMs) enhance OCR by integrating visual data with contextual understanding, enabling more accurate and meaningful text extraction. Unlike traditional OCR systems that focus solely on transcribing text from images, VLMs such as GPT-4o integrate text recognition with contextual understanding. This integration enables them to:
- Interpret Context-Specific Abbreviations: VLMs can accurately decipher abbreviations based on the surrounding context. For example, they can determine that "sat." refers to "saturated" and "cholest." denotes "cholesterol" by analyzing the content and structure of the document.
- Predict Missing Information: By recognizing patterns within the data, VLMs can infer missing details. For instance, they might identify a food item based on its nutritional profile, even if the item's name is absent, by correlating the nutritional information with common food profiles.
- Intelligently Structure Data for Downstream Applications: VLMs can organize extracted information in a manner that aligns with the requirements of subsequent processes. This capability is particularly beneficial for tasks such as populating databases, generating reports, or feeding data into other analytical tools.
UsingVLMs for OCR tasks enhances the processing of unstructured or semi-structured text. OCR data extraction using VLMs is suitable for complex datasets like product information etc. Their ability to understand and interpret context allows for more accurate and meaningful data extraction compared to traditional OCR methods. We will explore some popular VLM for OCR.
Florence-2
Microsoft's Florence-2 is an advanced vision-language model designed to perform a variety of computer vision and vision-language tasks, including Optical Character Recognition (OCR). By using a unified, prompt-based representation, Florence-2 can interpret and generate textual information from images with high accuracy.
Applications of Florence-2 in OCR:
- Text Recognition in Images: Florence-2 can accurately extract textual information from images, making it suitable for digitizing printed or handwritten documents, reading text in natural scenes, and processing forms or receipts.
- Contextual Understanding: The model's ability to comprehend visual context enhances its performance in interpreting ambiguous or stylized text, leading to more accurate OCR results in complex scenarios.
import requests
from PIL import Image
from transformers import AutoProcessor, AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("microsoft/Florence-2-large", trust_remote_code=True)
processor = AutoProcessor.from_pretrained("microsoft/Florence-2-large", trust_remote_code=True)
prompt = "<OCR>"
url = "label.jpg"
image = Image.open(url)
inputs = processor(text=prompt, images=image, return_tensors="pt")
generated_ids = model.generate(
input_ids=inputs["input_ids"],
pixel_values=inputs["pixel_values"],
max_new_tokens=1024,
num_beams=3,
do_sample=False
)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=False)[0]
parsed_answer = processor.post_process_generation(generated_text, task="<OCR>", image_size=(image.width, image.height))
print(parsed_answer)
The code will generate following output.
{'<OCR>': 'Mfg. Lic. No. 09 of 1983\nBatch No. :\nS24010\nDate of Mfg. : 03-2024\nExpiry date :\n08-2025\nMaximum\nRetail Price Rs.\n20.99\n(Inclusive of\nall taxes)\nSTORE BELOW 25℃.\nPROTECT FROM LIGHT.\n'}
PaliGemma 2
PaliGemma 2 is an advanced VLM developed by Google, building upon its predecessor, PaliGemma, to enhance performance across a wide range of tasks, including OCR.
Key Features of PaliGemma 2 for OCR:
- Enhanced Text Recognition: PaliGemma 2 excels in detecting and recognizing text within images, effectively handling various fonts, styles, and orientations. This capability is crucial for accurately extracting textual information from diverse visual content.
- Table Structure Recognition: The model demonstrates proficiency in understanding and reconstructing table structures from images, facilitating the extraction of organized data from documents such as spreadsheets and forms.
- Molecular Structure Recognition: PaliGemma 2 can interpret and digitize molecular diagrams, enabling the conversion of complex chemical structures into machine-readable formats, which is valuable for scientific research and documentation.
- Music Score Recognition: The model is capable of transcribing musical notations from sheet music images into digital formats, aiding in music digitization and analysis.
Following is the code example of using Paligemma-2 for OCR extraction.
from transformers import (
PaliGemmaProcessor,
PaliGemmaForConditionalGeneration,
)
from transformers.image_utils import load_image
import torch
import cv2
model_id = "google/paligemma-3b-mix-224"
image = cv2.imread("label.jpg")
model = PaliGemmaForConditionalGeneration.from_pretrained(model_id, torch_dtype=torch.bfloat16, device_map="auto").eval()
processor = PaliGemmaProcessor.from_pretrained(model_id)
# Instruct the model to extract the text
prompt = "ocr"
model_inputs = processor(text=prompt, images=image, return_tensors="pt").to(torch.bfloat16).to(model.device)
input_len = model_inputs["input_ids"].shape[-1]
with torch.inference_mode():
generation = model.generate(**model_inputs, max_new_tokens=100, do_sample=False)
generation = generation[0][input_len:]
decoded = processor.decode(generation, skip_special_tokens=True)
print(decoded)
The code will generate following output.
Mfg. Lic. No. 09 of 1983
Batch No. : S24010
Date of Mfg. : 03-2024
Expiry date : 08-2025
Maximum
20.99
Retail Price Rs.
(inclusive of
all taxes)
STORE BELOW 25°C. PROTECT FROM LIGHT.
Gemini
Google's Gemini is an advanced multimodal AI model that integrates vision and language understanding, enabling it to perform a variety of tasks, including OCR. Gemini is capable to interpreting and analyzing both textual and visual information within images and documents.
Gemini's applications in OCR:
- Enhanced Text Extraction: By its multimodal capabilities, Gemini can extract text from images with higher accuracy, even in challenging scenarios involving complex backgrounds or varied fonts.
- Contextual Understanding: Gemini's ability to interpret visual context allows it to disambiguate text that may be unclear or ambiguous when considered in isolation. This improves the quality of OCR outputs.
Following is the example of using Gemini for OCR data extraction from image.
import google.generativeai as genai
from IPython.display import Markdown
from PIL import Image
import cv2
from google.colab import userdata
GEMINI_API_KEY=userdata.get('GEMINI_API_KEY')
genai.configure(api_key=GEMINI_API_KEY)
import httpx
import base64
# Load your local image
local_image_path = "label.jpg" # Replace with the path to your image
with open(local_image_path, "rb") as image_file:
image_content = image_file.read()
# Choose a Gemini model
model = genai.GenerativeModel(model_name="gemini-1.5-pro")
# Create a prompt
prompt = "extract text from image."
response = model.generate_content(
[
{
"mime_type": "image/jpeg",
"data": base64.b64encode(image_content).decode("utf-8"),
},
prompt,
]
)
Markdown(">" + response.text)
The code will generate following output:
Mfg. Lic. No. 09 of 1983 Batch No.: S24010 Date of Mfg.: 03-2024 Expiry date: 08-2025 Maximum Retail Price Rs. 20.99 (Inclusive of all taxes)
STORE BELOW 25°C. PROTECT FROM LIGHT.
GPT-4o
GPT-4o, introduced by OpenAI in May 2024, is a multimodal AI model capable of processing and generating text, images, and audio. Its advanced capabilities have significantly enhanced OCR tasks, offering improvements in accuracy, efficiency, and contextual understanding.
GPT-4o's applications in OCR:
- Enhanced Text Extraction: GPT-4o improves the accuracy of text extraction from images, even in challenging scenarios involving noisy or distorted text.
- Contextual Understanding: The model's deep language comprehension enables it to interpret text within its visual context which improves accuracy in recognizing complex or stylized fonts.
- Data Extraction and Transformation: Its multimodal capabilities enable efficient extraction and transformation of data from complex images and documents.
Following is the example of using GPT-4o for OCR data extraction:
import os
import base64
from openai import OpenAI
from google.colab import files
from IPython.display import Image, display
# Set your OpenAI API key
os.environ['OPENAI_API_KEY'] = 'OPENAI_API_KEY' # Replace with your actual API key
def encode_image_to_base64(image_path):
"""Convert image to base64 string"""
with open(image_path, 'rb') as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
def extract_text_from_image(image_path, prompt):
"""Extract text from image using GPT-4 Vision"""
client = OpenAI()
# Encode image
base64_image = encode_image_to_base64(image_path)
# Prepare messages
messages = [
{
"role": "user",
"content": [
{"type": "text", "text": prompt},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}"
}
}
]
}
]
# Make API call
response = client.chat.completions.create(
model="gpt-4o",
messages=messages,
max_tokens=500
)
return response.choices[0].message.content
image_path = "label.jpg"
# Extract text
prompt = "Please extract text from image"
try:
result = extract_text_from_image(image_path, prompt)
print("\nExtracted Text:")
print(result)
except Exception as e:
print(f"An error occurred: {str(e)}")
The code will generate following output.
Extracted Text:
Mfg. Lic. No. 09 of 1983
Batch No. : S24010
Date of Mfg. : 03-2024
Expiry date : 08-2025
Maximum Retail Price Rs. 20.99
(Inclusive of all taxes)
STORE BELOW 25°C. PROTECT FROM LIGHT.
Traditional OCR Models
Traditional OCR models are built specifically for the purpose of OCR. While multimodal models are increasingly used for OCR, traditional models are worth knowing and exploring when evaluating solutions.
Tesseract
Tesseract is a widely-used open-source Optical Character Recognition (OCR) engine that converts images of text into machine-readable text. Originally developed by Hewlett-Packard (HP) between 1984 and 1994, it was created as a superior alternative to other commercial OCR engines of the time, which "failed miserably." By 1995, Tesseract ranked among the top three OCR engines in terms of character accuracy.
The software was later released as open-source in 2005 and has since been maintained by the open-source community, with significant contributions from Google, which sponsored its development from 2006 until 2019. Notable advancements include the introduction of a machine learning-based technique called LSTM (Long Short-Term Memory) in Version 4, and the release of Version 5 in 2021. Following are the key features of Tesseract:
- Multilingual Support: Tesseract can recognize text in over 100 languages, including complex scripts such as Chinese, Japanese, Arabic, and Hebrew. It also supports right-to-left text orientation, making it suitable for a diverse range of applications.
- Custom Language Training: Users can train Tesseract to recognize new fonts and languages, enhancing its adaptability to specific needs. This feature is particularly useful for specialized document types or less common languages.
- Integration with Python via Pytesseract: With the Python wrapper Pytesseract, developers can easily incorporate Tesseract into Python projects. This allows them to automate OCR tasks with minimal code.
Following is the example of using Tesseract.
from PIL import Image
import pytesseract
import cv2
# Open an image file
image_path = 'label.jpg' # Replace with your image path
image = cv2.imread(image_path)
# Use Tesseract to extract text
extracted_text = pytesseract.image_to_string(image)
# Print the extracted text
print(extracted_text)
The code will generate following output.
Mfg. Lic. No. 09 of 1983
Batch No. : S240 10
Date of Mfg. : 03-2024
Expiry date : 08-2025
Maximum
Retail Price Rs. 20.99
(Inclusive of
all taxes)
STORE BELOW 25°C.
PROTECT FROM LIGHT.
EasyOCR
EasyOCR is an open-source Python library designed for Optical Character Recognition (OCR), enabling the extraction of text from images and scanned documents. Developed by Jaided AI, it leverages deep learning models built on the PyTorch framework to deliver accurate and efficient text recognition. The key features of EasyOCR are following:
- Multi-Language Support: EasyOCR supports over 80 languages, including complex scripts like Chinese, Japanese, Arabic, and Devanagari, making it versatile for global applications.
- Ease of Use: The library offers an API which allow users to perform OCR with minimal code. Its simplicity makes it accessible to both beginners and experienced developers.
- Pre-trained Models: EasyOCR comes with pre-trained models that can be used out-of-the-box, eliminating the need for extensive training.
Following is the code example to use EasyOCR.
import easyocr
import cv2
import matplotlib.pyplot as plt
# Load the image
image_path = 'label.jpg'
image = cv2.imread(image_path)
# Initialize EasyOCR Reader
reader = easyocr.Reader(['en']) # Specify language(s), e.g., 'en' for English
# Perform OCR
results = reader.readtext(image_path)
# Print the extracted text
for _, text, _ in results:
print(text)
The following will be the output.
Batch No_
524010
Date of Mfg:
03-2024
Expiry date
08-2025
Maximum
Retail Price Rs.
20.99
(Inclusive of
all taxes)
STORE BELOW 25"€.
Surya
Surya is an open-source OCR toolkit designed to process multilingual documents. It supports text recognition in over 90 languages and offers features such as line-level text detection, layout analysis, reading order detection, and table recognition. Surya is capable of handling various document types, including PDFs, images, Word documents, and PowerPoint presentations. Following are the key features of Surya OCR:
- Multilingual OCR: Surya can recognize text in more than 90 languages, making it suitable for diverse applications requiring multilingual document processing.
- Line-Level Text Detection: It automatically identifies the location of each line of text within a document, facilitating precise text extraction.
- Layout Analysis: Surya detects various document elements, including tables, images, headings, and more, enabling comprehensive document parsing.
- Reading Order Detection: It determines the correct reading sequence of text elements, which is essential for maintaining the logical flow of content.
- Table Recognition: Surya identifies rows and columns within tables, allowing for accurate extraction and interpretation of tabular data.
Following is the example of using Surya OCR.
from PIL import Image
from surya.ocr import run_ocr
from surya.model.detection.model import load_model as load_det_model, load_processor as load_det_processor
from surya.model.recognition.model import load_model as load_rec_model
from surya.model.recognition.processor import load_processor as load_rec_processor
# Load the image
IMAGE_PATH = 'label.jpg' # Replace with the path to your image
image = Image.open(IMAGE_PATH)
# OCR setup
langs = ["en"] # Specify the language
det_processor, det_model = load_det_processor(), load_det_model()
rec_model, rec_processor = load_rec_model(), load_rec_processor()
# Perform OCR
predictions = run_ocr([image], [langs], det_model, det_processor, rec_model, rec_processor)[0]
# Extract text from the OCR predictions
text = [line.text for line in list(predictions)[0][1]]
# Print Recognizing Text
print(text)
The code will show following output.
['', 'Mfg. Lic. No. 09 of 1983', 'Batch No. : $24010', 'Date of Mfg .: 03-2024', 'Expiry date : 08-2025', 'Maximum', '1.20.99', 'Retail Price Rs.', '(Inclusive of', 'all taxes)', 'STORE BELOW 25°C', 'PROTECT FROM LIGHT.']
TrOCR
TrOCR (Transformer-based Optical Character Recognition) is an end-to-end OCR model developed by Microsoft Research that usesTransformer architectures for both image understanding and text generation. TrOCR uses a unified Transformer framework to enhance its capability to recognize both printed and handwritten text. Following are the key features of TrOCR:
- Transformer Architecture: TrOCR uses a unified Transformer-based model for text recognition which eliminating the need for separate text detection and recognition components.
- Pre-trained on Diverse Datasets: The model is pre-trained on large-scale synthetic data and fine-tuned with human-labeled datasets which enabling it to handle various fonts, layouts, and languages effectively. This extensive pre-training allows TrOCR to generalize well across different text styles and formats.
- Multilingual Support: TrOCR supports multiple languages, making it suitable for global applications. Its design allows for easy extension to additional languages by utilizing multilingual pre-trained models on the decoder side.
Following is the example of using TrOCR.
# Import required libraries
from transformers import TrOCRProcessor, VisionEncoderDecoderModel
from PIL import Image
import requests
# Load the TrOCR model and processor
processor = TrOCRProcessor.from_pretrained("microsoft/trocr-large-stage1")
model = VisionEncoderDecoderModel.from_pretrained("microsoft/trocr-large-stage1")
# Load an image
image_url = "label.jpg"
image = Image.open(image_url).convert("RGB")
# Preprocess the image
pixel_values = processor(images=image, return_tensors="pt").pixel_values
# Perform OCR
output = model.generate(pixel_values)
# Decode the text
decoded_text = processor.tokenizer.decode(output[0], skip_special_tokens=True)
# Print the extracted text
print("Extracted Text:", decoded_text)
DocTR
DocTR (Document Text Recognition) is an open-source library developed by Mindee for OCR tasks, leveraging deep learning to provide high-performance text detection and recognition in documents. Following are the key features of DocTR:
- End-to-End OCR Pipeline: DocTR offers a pipeline that integrates both text detection and recognition to enable efficient extraction of textual information from various document formats.
- Deep Learning Models: The library uses deep learning architectures which ensure high accuracy in text extraction tasks.
- Easy Integration: With a user-friendly API, DocTR can be easily integrated into existing workflows.
You can use DocTR via Roboflow OCR API. Following is the example.
import os
from inference_sdk import InferenceHTTPClient
from google.colab import userdata
# Retrieve the API key from Colab Secrets
api_key = userdata.get('ROBOFLOW_API_KEY')
# Set the API key as an environment variable
os.environ['ROBOFLOW_API_KEY'] = api_key
CLIENT = InferenceHTTPClient(
api_url="https://infer.roboflow.com",
api_key=os.environ['ROBOFLOW_API_KEY']
)
result = CLIENT.ocr_image(inference_input="label.jpg")
print(result)
It will generate following output.
{'result': 'Mfg. Lic. No. 09 of 1983 Batch No. : $24010 Date of Mfg.: 03-2024 Expiry date : 08-2025 Maximum Retail Price Rs. 20.99 (Inclusive of all taxes) STORE BELOW 25°C. PROTECT FROM LIGHT.', 'time': 2.0814746169999125, 'parent_id': None}
Building an OCR Application
To build an OCR text extraction example application, we will use both techniques i.e. OCR models and VLM to extract and interpret text from images. The user interface is designed with Gradio. This application is designed to identify product details, such as Product ID, batch numbers, manufacturing dates, expiry dates etc. from packaging labels.
This use-case is particularly valuable in industries like retail, logistics, and healthcare, where tracking and verifying product information is crucial. For example, Product ID enables precise tracking and management of products throughout their lifecycle. Batch numbers can help trace the origin of a product in the event of a recall, while manufacturing and expiry dates ensure product safety and regulatory compliance. Automating the extraction of this data reduces manual effort, minimizes errors, and improves operational efficiency. This application can be used for inventory management, quality control, consumer safety, or regulatory purposes.
Example #1: Using OCR Model
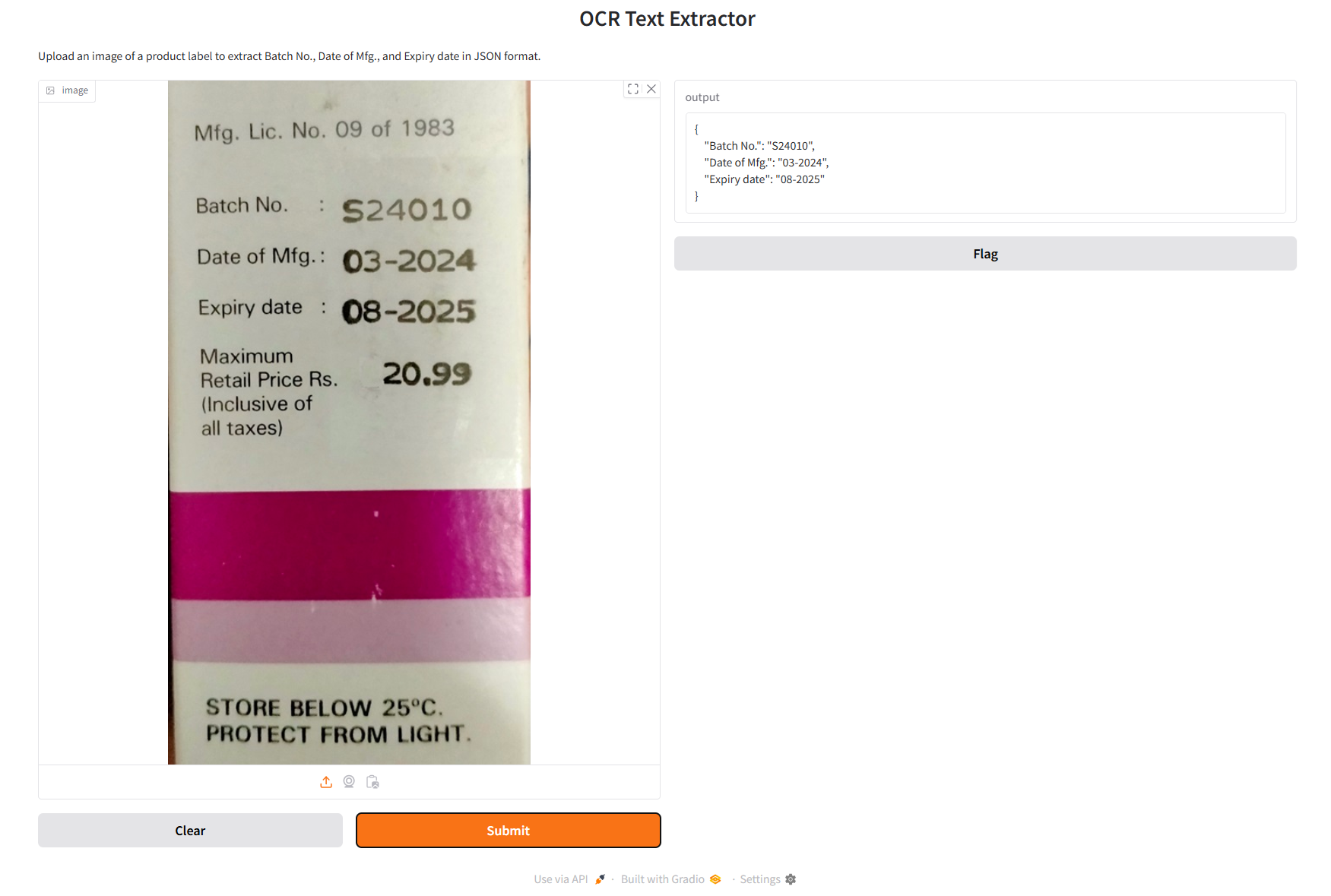
In this example, we will use Tesseract to extract OCR data from an image of a product label. Initially, all text from the product label image will be extracted. A specified pattern will be applied to extract key details such as the batch number, manufacturing date (Mfg. date), and expiration date from the extracted text. The application's interface is developed using Gradio. The extracted data is stored in JSON form which may be utilized for further processing.
import gradio as gr
from PIL import Image
import pytesseract
import cv2
import re
import json
import numpy as np
def process_image(image):
# Convert Gradio input image to OpenCV format
image = np.array(image)
# Use Tesseract to extract text
extracted_text = pytesseract.image_to_string(image)
print("Extracted Text:\n", extracted_text) # Debug: Print raw extracted text
# Define regex patterns for the desired fields
patterns = {
"Batch No.": r"Batch No\.?\s*:\s*(.+)",
"Date of Mfg.": r"Date of Mfg\.?\s*:\s*(.+)",
"Expiry date": r"Expiry date\s*:\s*(.+)"
}
# Extract data using regex
data = {}
for key, pattern in patterns.items():
match = re.search(pattern, extracted_text, re.IGNORECASE) # Ignore case for robustness
if match:
data[key] = match.group(1).strip() # Strip extra spaces
# Convert to JSON format
json_output = json.dumps(data, indent=4)
return json_output
# Define Gradio interface
iface = gr.Interface(
fn=process_image,
inputs=gr.Image(type="pil"), # Accept image input
outputs="text", # Display extracted JSON as text
title="OCR Text Extractor",
description="Upload an image of a product label to extract Batch No., Date of Mfg., and Expiry date in JSON format."
)
# Launch the interface
iface.launch()
The following data will be extracted in the JSON format:
{
"Batch No.": "S24010",
"Date of Mfg.": "03-2024",
"Expiry date": "08-2025"
}
The following image shows how the application work:
Example #2: Using GPT-4o VLM
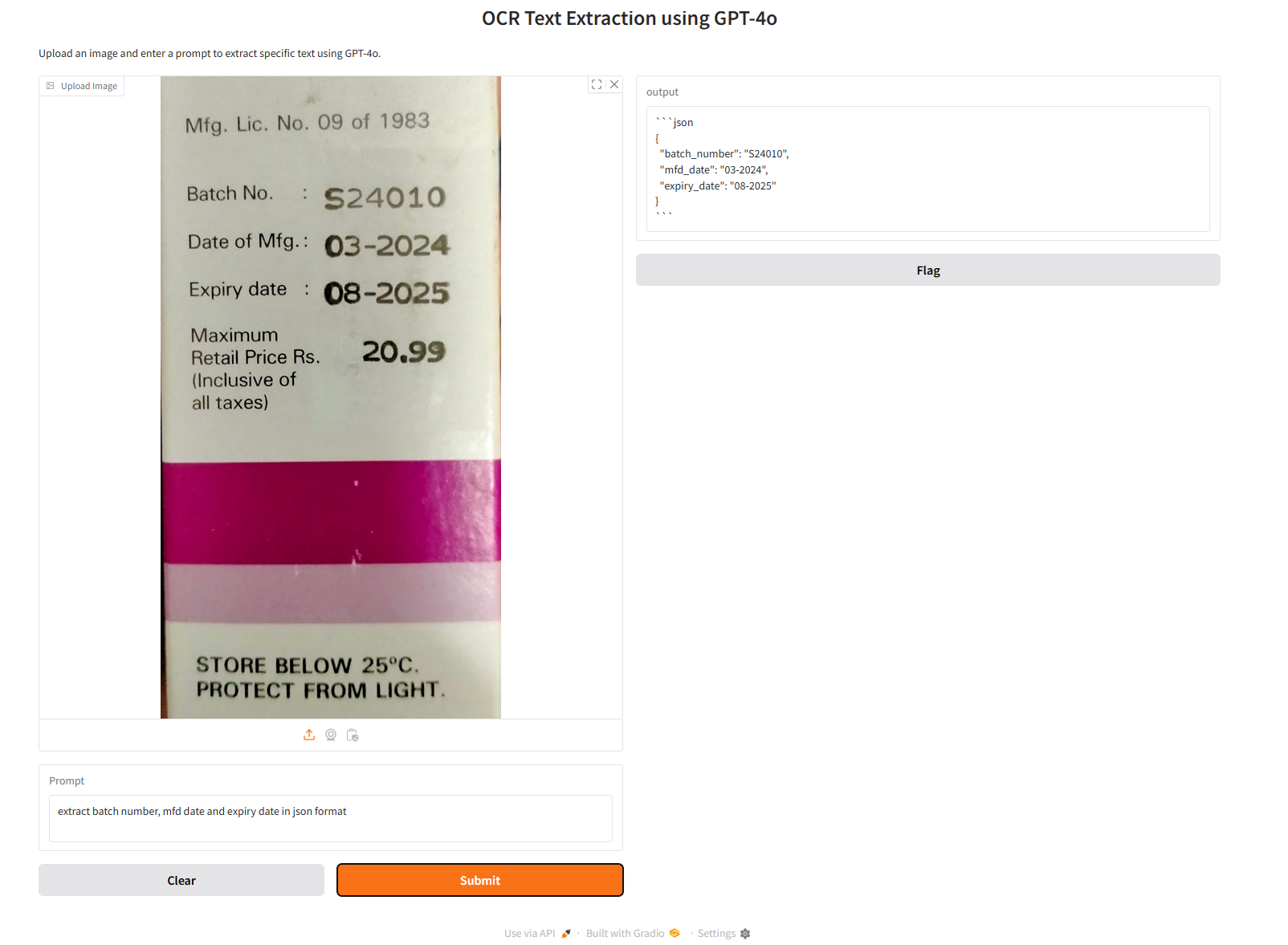
In this example we will use GPT-4o VLM for extracting OCR data from the image of a product label. The user interface for the application is built using Gradio. Following is the code.
import os
import base64
from openai import OpenAI
import gradio as gr
from PIL import Image
from io import BytesIO
# Set your OpenAI API key
os.environ['OPENAI_API_KEY'] = 'OPENAI_API_KEY'
def encode_image_to_base64(image):
"""Convert image to base64 string"""
buffered = BytesIO()
image.save(buffered, format="JPEG")
return base64.b64encode(buffered.getvalue()).decode('utf-8')
def extract_text_from_image(image_path, prompt):
"""Extract text from image using GPT-4 Vision"""
client = OpenAI()
# Encode image
base64_image = encode_image_to_base64(image_path)
# Prepare messages
messages = [
{
"role": "user",
"content": [
{"type": "text", "text": prompt},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}"
}
}
]
}
]
# Make API call
response = client.chat.completions.create(
model="gpt-4o",
messages=messages,
max_tokens=500
)
return response.choices[0].message.content
def gradio_interface(image, prompt):
"""Gradio interface function"""
try:
result = extract_text_from_image(image, prompt)
return result
except Exception as e:
return f"An error occurred: {str(e)}"
# Create Gradio interface
iface = gr.Interface(
fn=gradio_interface,
inputs=[
gr.Image(type="pil", label="Upload Image"),
gr.Textbox(lines=2, placeholder="Enter your prompt here...", label="Prompt")
],
outputs="text",
title="OCR Text Extraction using GPT-4o",
description="Upload an image and enter a prompt to extract specific text using GPT-4o."
)
# Launch the interface
iface.launch()
While running the above code and specifying the following prompt
extract batch number, mfd date and expiry date in json format
You will get following output.
{
"batch_number": "S24010",
"mfd_date": "03-2024",
"expiry_date": "08-2025"
}
The image below shows how the application works.
Conclusion
In this blog, we explored OCR data extraction and demonstrated examples of extracting information from images using OCR models and VLMs. Additionally, we learned how to build an OCR data extraction application using Tesseract and GPT-4o to identify and extract specific information, such as batch numbers, manufacturing dates, and expiration dates, from a product label image.
This application is highly valuable for automating data entry processes in industries such as manufacturing, retail, and logistics, where extracting and managing product information from labels is critical for inventory tracking, compliance, and quality control. There are many other OCR models like MMOCR and VLMs like Claude 3, Phi-3.5, QwenVL, CogVLM which can be used for OCR data extraction.
Cite this Post
Use the following entry to cite this post in your research:
Timothy M. (Jan 14, 2025). What is OCR Data Extraction?. Roboflow Blog: https://blog.roboflow.com/ocr-data-extraction/