
Apple's new M4 chips have been generating a lot of buzz, especially among folks interested in machine learning and computer vision. At Roboflow, we're always eager to get our hands on the latest hardware to see how it performs on computer vision tasks.
When the M1 chips launched in 2020, we ran some machine vision training benchmarks on them against our Intel-based Macs. So when we got a couple of the new M4 Mac Minis in the office, we knew we had to put them through their paces!
Using our open-source Roboflow Inference benchmarking suite, we compared the M4 and M4 Pro to a range of previous-gen Apple Silicon devices. We tested everything from the OG M1 to the beastly M4 Max, with a few M2 and M3 MacBook Airs thrown in for good measure.
Here's how the lineup shook out:
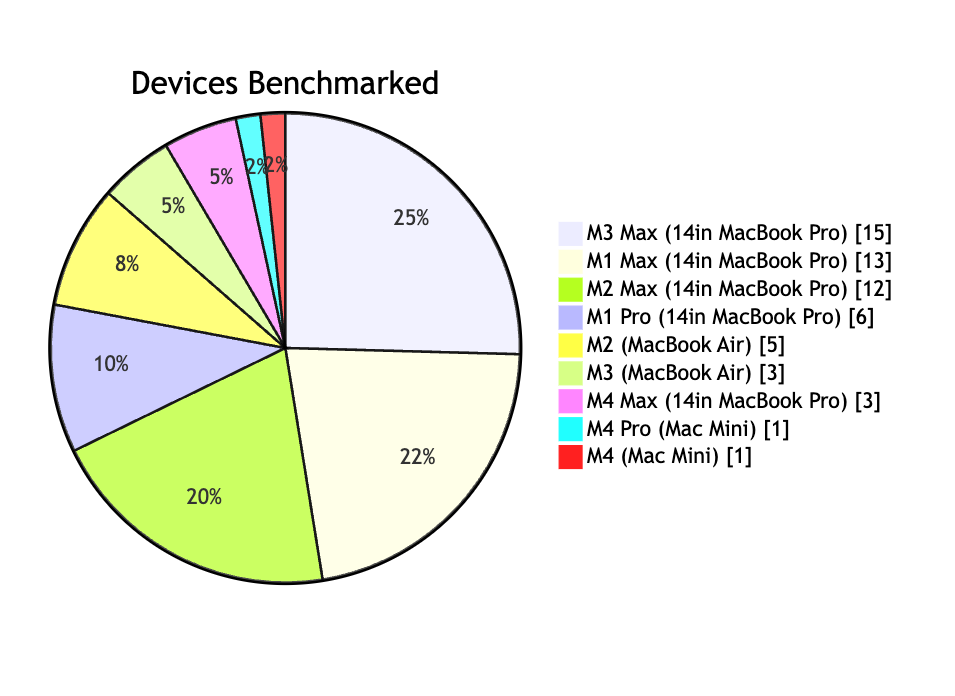
We have a pretty even distribution of Apple Devices across the previous 3 generations. Max chips have been our favorite chips to get, since we can really take advantage of the additional CPU and GPU cores for building computer vision tools.
Each device was benchmarked with 50 computer vision models, covering everything from tiny object detection nets to giant, state-of-the-art segmentation models. Here's a list of the models we tested:
YOLOv8
- Base Models: yolov8n-640, yolov8n-1280, yolov8s-640, yolov8s-1280, yolov8m-640, yolov8m-1280, yolov8l-640, yolov8l-1280, yolov8x-640, yolov8x-1280
- Segmentation Models: yolov8n-seg-640, yolov8n-seg-1280, yolov8s-seg-640, yolov8s-seg-1280, yolov8m-seg-640, yolov8m-seg-1280, yolov8l-seg-640, yolov8l-seg-1280, yolov8x-seg-640, yolov8x-seg-1280
- Pose Models: yolov8n-pose-640, yolov8s-pose-640, yolov8m-pose-640, yolov8l-pose-640, yolov8x-pose-640, yolov8x-pose-1280
YOLOv10
- Base Models: yolov10n-640, yolov10s-640, yolov10m-640, yolov10b-640, yolov10l-640, yolov10x-640
YOLOv11
- Base Models: yolov11n-640, yolov11n-1280, yolov11s-640, yolov11s-1280, yolov11m-640, yolov11m-1280, yolov11l-640, yolov11l-1280, yolov11x-640, yolov11x-1280
- Segmentation Models: yolov11n-seg-640, yolov11s-seg-640, yolov11m-seg-640, yolov11l-seg-640, yolov11x-seg-640
YOLO-NAS
- Base Models: yolo-nas-s-640, yolo-nas-m-640, yolo-nas-l-640
The models were benchmarked with the following command, using the inference CLI tool:
inference benchmark python-package-speed --warm_up_inferences 50 --model_id $MODEL --benchmark_requests 100
Fast, Faster, Fastest
So how'd the new chips stack up? In a word: fast.
On the popular yolov8n-640 model, the M4 Pro clocked an insane 92.6 frames per second. That's nearly 3X faster than the M1 Max!
Check out the full results:
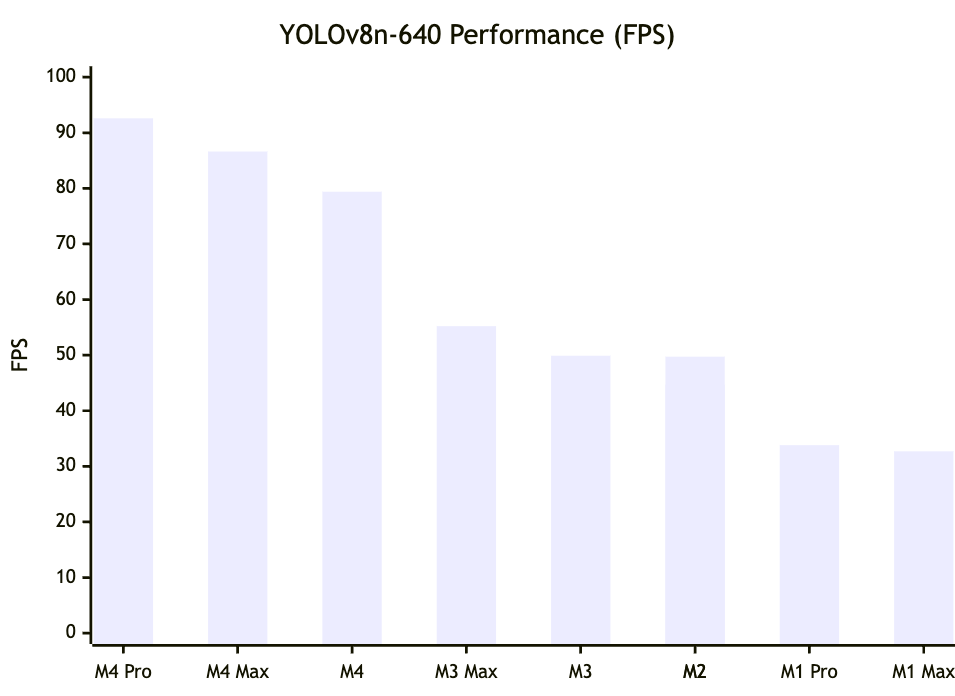
But the M4's dominance wasn't just limited to the small models. On the full-size YOLOv8 and YOLOv11, the M4 and M4 Pro still posted huge gains over their predecessors – in some cases, 50-100% speedups!
The 14" MacBook Pro models with the M1 Max, M2 Max, and M3 Max held their own against the new Mac Minis on these larger workloads. We speculate that the more robust thermal envelope of the laptop chassis helps when you're pushing the silicon to its limits.
Big Gains on Segmentation
One area where the M4 chips really shined was on segmentation models. These networks, which predict a class label for every pixel in an image, are notoriously compute-heavy. But the M4 was able to run inference fast.
On the yolov11m-seg model at 640x640 resolution, the M4 Max operated at 8 FPS: 30% more than the M3 Max and 70% more than the M1 Max. For a model that was previously a struggle to run in real-time, this is a game-changer.

The huge speedup on segmentation tasks opens up exciting new possibilities for applications like real-time background removal, portrait mode video, and augmented reality effects. We can't wait to see what our users build with this!
Under the Hood
So what's driving these impressive performance gains, especially on hefty computer vision workloads? A big part of the story is the Scalable Matrix Extension (SME) built into the M4 chip.
SME is a set of dedicated hardware that accelerates matrix multiplication, which is the core building block of neural networks. By parallelizing these operations across a grid of simple multiply-accumulate units, SME can crunch through the millions of calculations needed for tasks like object detection and segmentation.
The M4's SME brings several key improvements over previous generations:
-
More compute units. The M4 packs in up to 16x16 arrays of multiply-accumulate units, a big step up from prior designs. This allows it to work through larger matrix operations in fewer clock cycles.
-
Wider data paths. SME operates on 512-bit vector registers, double the width of the 256-bit registers in the M1. This means it can process twice as many numbers in parallel.
-
Support for more data types. In addition to the usual 8-bit, 16-bit, and 32-bit integer formats, the M4's SME adds support for 16-bit brain floating point (BFloat16). This compact format is a good fit for neural network inference.
-
Higher clock speeds. Early analysis suggested the M4's SME runs at around 3.9 GHz, nearly matching the CPU clock. By keeping the matrix units fed with data, the chip can sustain an impressive 2 TFLOPS on 32-bit floating point math.
Altogether, these enhancements allow the M4 to tear through matrix-heavy computer vision workloads far faster than any previous Apple Silicon chip.
History of SME and AMX on Apple Silicon
Previous generations of Apple Silicon chips also had dedicated hardware accelerators for matrix operations, but they were in a proprietary implementation called Apple Matrix eXtensions (AMX). AMX functionality was only available to developers who used the coreML framework, which is a framework that Apple created for machine learning. This made it difficult for developers to take advantage of the new hardware accelerators, as they had to write their own code to use the hardware, rather than rely on their normal tools to just work with the hardware.
Over the years, Apple has been working on getting the pieces of AMX that they needed brought into the ARM Scalable Matrix Extension (SME) reference design. With the release of the M4, Apple has removed AMX and replaced it with SME, removing the need to use coreML and making it eaiser for software to take advantage of the new SME instructions on the chip.
Upgrading Our Machines
Impressed by these benchmarks, we've decided to upgrade our developers still using M1-based laptops to the new M4 Max MacBook Pros. The 64GB of unified memory will be a boon for working with large models and datasets.
We're excited to get our hands on these new machines to make the development experience even smoother for our engineering team. From faster model iterations to quicker builds, the M4 Max will supercharge our workflows and allow faster testing, experimentation, and iteration
And of course, all that performance headroom means we can spend more time tackling juicy computer vision challenges, like when we recently fixed a customer issue and deployed the change in under 30 minutes. That's the kind of responsiveness we strive for!
Just the Beginning
We're thrilled to see the leaps in performance made possible by the latest Apple Silicon. From enabling new applications on resource-constrained edge devices to drastically accelerating model iteration cycles, breakthroughs in hardware continue to push the boundaries of what's possible with computer vision.
But we also know that making this technology truly accessible to every developer will take more than just fast chips. It requires intuitive software, robust infrastructure, and a thriving ecosystem of tools and community support.
At Roboflow, we're committed to building that ecosystem and empowering developers everywhere to bring their computer vision ideas to life. Whether you're a student working on a class project, a startup building a new product, or an enterprise deploying at scale, we want to be your partner in this exciting journey.
So here's to the new M4 and the exciting future of computer vision! If you're as pumped as we are, we'd love to hear from you. Give us a shout on X or drop us a line. And if you want to help us build the future of computer vision tooling, we're hiring!
References
Cite this Post
Use the following entry to cite this post in your research:
Alex Norell. (Dec 13, 2024). Putting the New M4 Macs to the Test. Roboflow Blog: https://blog.roboflow.com/putting-the-new-m4-macs-to-the-test/