
The Roboflow Inference Server is a Docker-based application that lets you run object detection, instance segmentation, and classification models locally, on the edge, or via Roboflow's hosted API, all through the same set of routes so you can swap deployment targets without changing code. This launch post covers the key capabilities: support for custom trained models, built-in access to auxiliary models like CLIP, and a documented API that returns predictions as structured JSON. The server runs on hardware ranging from Raspberry Pi to server-grade machines and supports offline inference once the model is fetched.
Computer vision has revolutionized the way we interact with the world, enabling building solutions such as driverless cars and defect identification with precision on manufacturing lines. However, for everyone – including skilled practitioners in the field – the laundry list of prerequisites and required plumbing can still be daunting.
A notable challenge is deciding how you are going to run inference on a model. When you have a trained model ready to use, how will you deploy it on a device that meets your use case? This is a time-consuming process to complete manually, especially if you decide to change inference devices further down the line.
Today we are announcing the launch of the new Roboflow Inference Server, a Docker-based application that seamlessly integrates with Roboflow to help you deploy your custom computer vision models. Our inference server provides a robust, field-tested solution for deploying your model to the edge.
When utilizing the Inference Server, you’ll be able to:
- Change deployment targets, offline to online or hosted API to edge or from Jetson to Raspberry Pi, without touching any code;
- Deploy object detection, instance segmentation, and classification models locally, offline, or on the edge and;
- Immediately use the latest models, like CLIP, across deployment targets.
In this blog post, we’ll walk through the capabilities of the Roboflow inference server and some simple examples of how to use the server.
What is the Roboflow Inference Server?
The Roboflow Inference Server is an application you can deploy via Docker through which you can run your model and retrieve predictions. The Inference Server runs locally but is also hosted by Roboflow. You can query our API or a locally-deployed model to get predictions.
If you opt to deploy your model locally, you will need to connect to the internet to retrieve the model. When you train new models so they can be retrieved. During inference, no internet connection is required. This is ideal if you need your models to run in an environment where stable network connectivity is hard to maintain.
Let’s talk about a few of the features available in the server.
Support for Custom Trained Models
Roboflow makes it easy to train custom computer vision models for a variety of tasks including Object Detection, Instance Segmentation, and Classification. All of these tasks are supported by the Roboflow Inference Server.
Support for Auxiliary Models
In addition to custom trained computer vision models, Roboflow also makes it easy to run some common public models that we refer to as Core Models. The first core model available for use in the Roboflow Inference Server is CLIP by OpenAI.
CLIP can help you make sense of images by computing embeddings, which essentially compresses the information in an image into a much more manageable piece of data. These embeddings make it possible to quickly compare images. Additionally, CLIP can process language and compute embeddings for that language. This enables comparing a human language sentence to an image, which can be used for image search.
Inference Server Usage
There are two ways to use the inference server. You can use the hosted endpoint or a local deployment. To query the hosted endpoint, use this code:
curl -XPOST "https://detect.roboflow.com/MODEL_NAME/VERSION?api_key=API_KEY&image=IMAGE_URL"To find your Roboflow model name and version, view our guide on this topic. You can find our API key by following the API key guide in the Roboflow documentation.
To use a local endpoint, first install and run the Docker container associated with the server:
docker run -it –rm –network=host roboflow/roboflow-inference-server-cpuNow, you can query the server using this syntax:
curl -XPOST "http://localhost:9001/MODEL_NAME/VERSION?api_key=API_KEY&image=IMAGE_URL"
Deploy Environments
Now that we’ve discussed what the server can do, let’s talk about the environment in which you can use the Roboflow Inference Server.
Hosted Deployment
The easiest way to take advantage of all of the capabilities of the Roboflow Inference Server is to use hosted model endpoints. This means that you can make requests to your own custom Roboflow API endpoint to get the results you’re after. We take care of the infrastructure so you can worry less about machine learning operations and focus more on using the results from inference.
Local Deploy
For some applications, you may want to host your models on your own machines. The Roboflow Inference Server can run on nearly any computer that is capable of running Docker containers. Docker images are published by the target environment.
The most flexible images are the `cpu` and `arm-cpu` images. As the name suggests, they’ll use your cpu to run your models. To increase performance, you can spin up the inference server on a GPU equipped machine and use the `trt` image.
Running a model on GPU will boost the performance of your model compared to CPU. If the GPU you’re using is TRT (TensorRT) capable, the inference server will use an optimized runtime which will maximize the performance of your model.
Lastly, you may want to run your model on an edge device. Edge devices are small computers capable of running in remote environments. For this, the Roboflow Inference Server is deployable to NVIDIA Jetson devices. On Jetsons the inference server uses an optimized runtime to squeeze a lot of performance out of a relatively small machine.
The Roboflow Inference API
The Roboflow Inference Server implements a common API. This means you can switch between target environments seamlessly without needing to change your client code. Furthermore, you can switch between local deployments and a Roboflow hosted endpoint without changing anything.
To infer with a model using the Roboflow Inference Server, we first need to set up an inference endpoint. This can be done one of two ways:
- Use an endpoint that is automatically created for every model hosted on Roboflow. These endpoints are always available and highly scalable or;
- Start a Roboflow Inference Server docker container in the environment of your choice.
How to Start the Roboflow Inference Server
For these examples, we will use a Google Cloud VM with an 8 core CPU and an attached NVIDIA V100 GPU. The minimum prerequisite for running a Roboflow Inference Server is to have Docker installed on your target device.
First we’ll start a CPU inference server using this command:
$ docker run -it –rm –network=host roboflow/roboflow-inference-server-cpu
INFO: Started server process [1]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:9001 (Press CTRL+C to quit)We can see our machine pulled the image from Docker Hub and started it. By default, the image is listening on `localhost` port `9001`. If another port or host is desired, it is possible to provide custom configuration at runtime via environment variables. In this example, we set up the inference server to listen on port `8080`, the default HTTP port.
$ docker run -it –rm –network=host -e PORT=8080 roboflow/roboflow-inference-server-cpu
INFO: Started server process [1]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)If we want to use the GPU attached to our machine we need to use the trt image and give our docker container access to the GPU using the `--gpus` flag on the docker run command.
docker run -it –rm –network=host –gpus=all roboflow/roboflow-inference-server-trtMaking Requests to the Inference Server
Now that we have an inference server up and running, we can make requests. These requests provide an input image to the inference server and the response is the output from the model structured as JSON data.
When making requests, there are many options that change the way the inference server processes data. The full docs for any running inference server can be found at the `/docs` route. Additionally, the Roboflow documentation hosts a copy of the API specification.
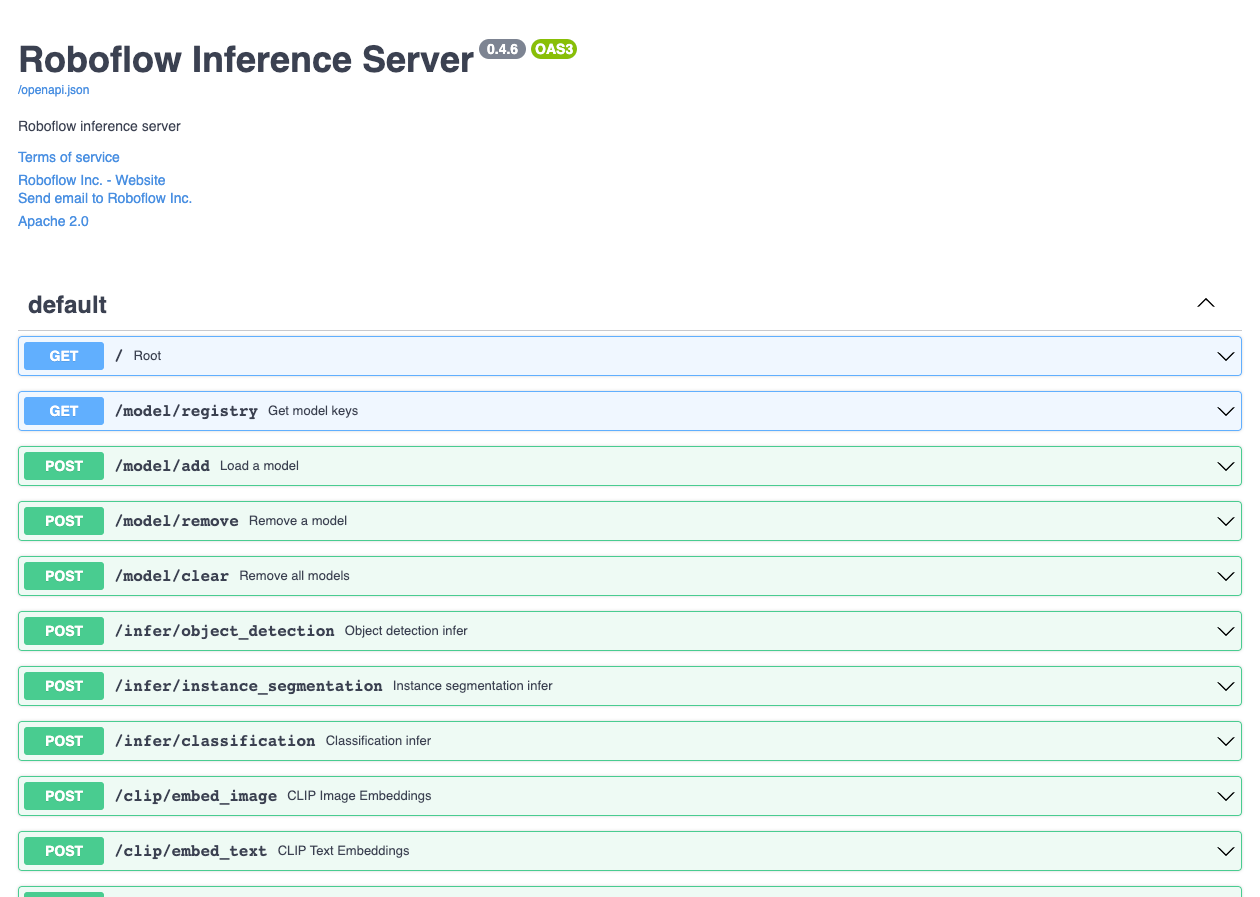
Hint: The available routes can vary by target environment. Use the `/docs` route in any environment to see what routes are available for any running inference server.
Conclusion
We are constantly making improvements to the Roboflow Inference Server and the Roboflow Inference API. We are aiming to open source the codebase and share what we have with the computer vision community. This will make it easy to run the inference server without docker and make it possible to deploy your own custom model with the Roboflow inference server.
We are excited to hear how you will use the Roboflow Inference Server to supercharge your software! Don’t forget, you can find the full documentation for using the inference here. And, you can post any questions or feedback on our forum.
Cite this Post
Use the following entry to cite this post in your research:
Paul Guerrie, Jay Lowe. (Mar 30, 2023). Launch: Updated Roboflow Inference Server. Roboflow Blog: https://blog.roboflow.com/updated-inference-server/