
In 2020, Facebook AI Research introduced Detection Transformers (DETR), presenting a new approach to object detection. DETR represents a significant departure from prior object detection systems in terms of architecture. It stands out as a framework that seamlessly integrates Transformers as a central building block within the object detection pipeline.
DETR achieved performance levels on par with state-of-the-art methods available in 2020, including the well-established and highly optimized Faster R-CNN baseline, when applied to the demanding COCO object detection dataset. Moreover, it accomplishes this while considerably simplifying and streamlining the architecture, marking a noteworthy evolution in the field of computer vision.
In this blog post, we will embark on an in-depth exploration of DETR, offering a thorough insight into its internal mechanisms and operations.
What is DETR?
DETR (DEtection TRansformer) is a deep learning model for object detection. DETR leverages the Transformer architecture, originally designed for natural language processing (NLP) tasks, as its main component to address the object detection problem in a unique and highly effective manner.
The primary component of DETR's architecture is the Transformer. The Transformer is a neural network architecture known for its self-attention mechanism, which enables it to capture complex relationships and dependencies between elements in a sequence or set of data. In the context of DETR, the Transformer's self-attention mechanism plays a pivotal role in understanding the content and spatial relationships of objects in an image.
How DETR Detects Objects
DETR treats the object detection problem differently from traditional object detection systems like Faster R-CNN or YOLO. Below we outline how DETR approaches object detection.
- Direct Set Prediction: Instead of using the conventional two-stage process involving region proposal networks (RPNs) and subsequent object classification, DETR frames object detection as a direct set prediction problem. It considers all objects in the image as a set and aims to predict their classes and bounding boxes in one pass.
- Object Queries: DETR introduces the concept of "object queries." These queries represent the objects that the model needs to predict. The number of object queries is typically fixed, regardless of the number of objects in the image.
- Transformer Self-Attention: the transformer's self-attention mechanism is applied to the object queries and the spatial features (known as keys and values) extracted from the input image. This self-attention mechanism allows DETR to learn complex relationships and dependencies between objects and their spatial locations.
- Parallel Predictions: Using the information gathered from the self-attention mechanism, DETR simultaneously predicts the class and location (bounding box) for each object query. This parallel prediction is a departure from traditional object detectors, which often rely on sequential processing.
- Bipartite Matching: To ensure that each predicted bounding box corresponds to a real object in the image, DETR uses bipartite matching to associate predicted boxes with ground-truth objects. This step enhances the model's precision during training.
How Does DETR Work?
In this section, we will explain how DETR works by taking an in-depth look at its architecture and exploring each of its key components in detail to understand how it transforms the field of object detection. The overall DETR architecture is shown below.
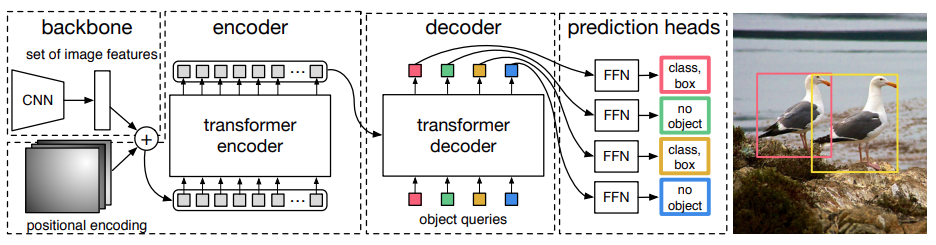
DETR begins by processing the input image through a Convolutional Neural Network (CNN) encoder. The primary role of the CNN encoder is to extract high-level feature representations from the image. These features retain spatial information about the objects in the image and serve as the foundation for subsequent operations. CNNs are well-known for their ability to capture hierarchical visual features.
The Transformers architecture adopted by DETR is shown in the picture below:
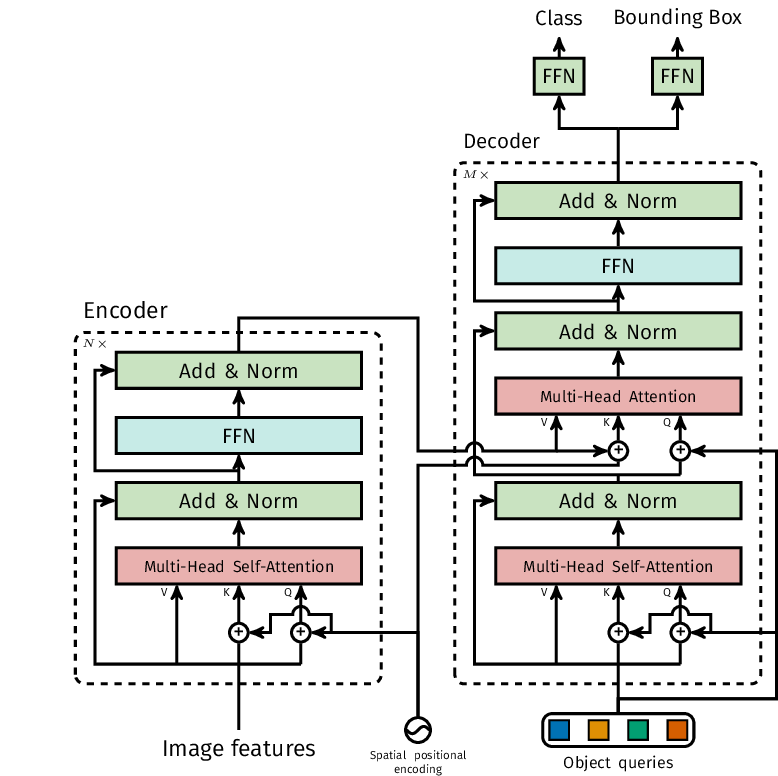
Since Transformers do not inherently possess spatial understanding, DETR adds positional encodings to the output of the CNN encoder. These positional encodings inform the model about the spatial relationships between different parts of the image. The encodings are crucial for the Transformer to understand the absolute and relative positions of objects.
DETR introduces the concept of "object queries," "keys," and "values." These components are central to the self-attention mechanism within the Transformer. The object queries are learnable representations of the objects that the model aims to predict.
The number of object queries is typically predetermined and does not depend on the number of objects in the image. Keys and values correspond to spatial features extracted from the CNN encoder's output. Keys represent the spatial locations in the image, while values contain feature information. These keys and values are used for self-attention, allowing the model to weigh the importance of different image regions.
The heart of the DETR architecture lies in its use of multi-head self-attention. This mechanism allows DETR to capture complex relationships and dependencies between objects within the image. Each attention head can focus on different aspects and regions of the image simultaneously. Multi-head self-attention enables DETR to understand both local and global contexts, improving its object detection capabilities.
To ensure that each predicted bounding box corresponds to a real object in the image, DETR employs a technique called bipartite matching. This process associates predicted bounding boxes with ground-truth objects from the training data, helping to refine the model during training.
DETR Strengths and Disadvantages
Having explored the fundamentals of DETR and its operational principles, it becomes imperative to examine the advantages and drawbacks inherent in this widely adopted object detection framework. Grasping the merits and limitations of DETR can empower you to make well-informed choices when selecting an approach tailored to your unique computer vision requirements.
Strengths of DETR
Below are some of the key strengths of the DETR architecture.
- End-to-End Object Detection: DETR offers an end-to-end solution for object detection, eliminating the need for separate region proposal networks and post-processing steps. This simplifies the overall architecture and streamlines the object detection pipeline.
- Parallel Processing: DETR predicts object classes and bounding boxes for all objects in an image simultaneously, thanks to the Transformer architecture. This parallel processing leads to faster inference times compared to sequential methods.
- Effective use of Self-Attention: the use of self-attention mechanisms in DETR enables it to capture complex relationships between objects and their spatial contexts. This results in improved object detection accuracy, especially in scenarios with crowded or overlapping objects.
Disadvantages of DETR
Below are some of the disadvantages of the DETR architecture.
- High Computational Resources: training and using DETR can be computationally intensive, especially for large models and high-resolution images. This may limit its accessibility for researchers and practitioners without access to powerful hardware.
- Fixed Object Query Count: DETR requires specifying the number of object queries in advance, which can be a limitation when dealing with scenes containing varying numbers of objects. An incorrect number of queries may lead to missed detections or inefficiencies.
DETR Performance
Upon its initial release, the primary objective of the authors was to surpass the Faster R-CNN baseline with DETR. However, in the present context, the enhanced Faster R-CNN ResNet50 FPN V2 exhibits superior performance compared to DETR models.
Let's proceed to examine the performance comparison in more detail.
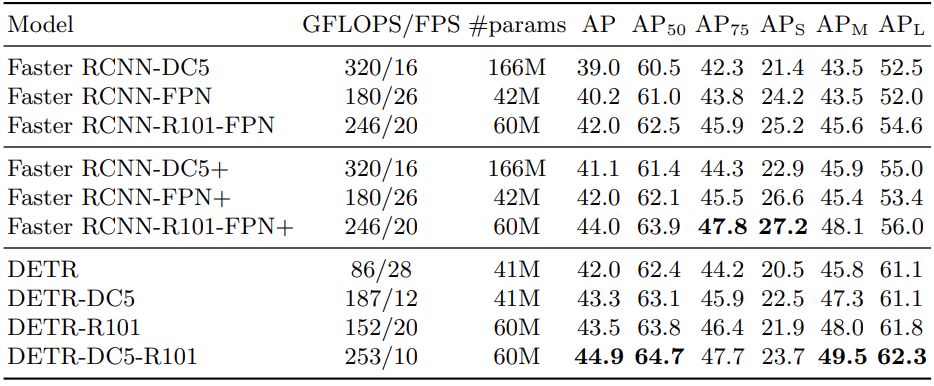
From the above image, we can observe that there are four distinct DETR models under consideration. The first is the basic DETR model built using a ResNet50 backbone. The second variation employs a ResNet101 backbone.
The "DC5" designation signifies an improved albeit slower model. This variant incorporates the use of a dilated C5 stage, enhancing the resolution of feature maps in the final stage of the CNN backbone. The subsequent upscaling by a factor of two leads to more accurate detection of smaller objects.
It is worth noting that the DC5 models do not result in an increase in the number of parameters.
Upon closer examination, it is evident that the DETR DC5 model with a ResNet101 backbone, boasting an impressive 44.9 mAP, emerges as the top-performing model among the entire ensemble.
Conclusion
The fundamental breakthrough that distinguishes DETR from other model architectures lies in its integration of the Transformer architecture to directly anticipate object classes and delineate bounding boxes for all objects within an image as an integrated set.
This innovative approach streamlines the object detection process by obviating the necessity for traditional region proposal mechanisms. Instead, DETR adopts a holistic perspective, efficiently handling all objects within an image in a single pass.
Moreover, DETR capitalizes on the intrinsic strength of the Transformer's self-attention mechanism. By doing so, DETR grasps intricate object relationships and spatial contextual cues that contribute significantly to its overall effectiveness. This mix of attributes resulted in an object detection framework that is not only highly efficient but also highly competitive in terms of performance, giving a pivotal advancement in the domain of computer vision.
Cite this Post
Use the following entry to cite this post in your research:
Petru P.. (Sep 25, 2023). What is DETR (Detection Transformers)?. Roboflow Blog: https://blog.roboflow.com/what-is-detr/