
Large Language Models (LLMs), especially LLMs with vision capabilities like GPT-4, have an extensive range of applications in industry. For example, LLMs can be used to answer questions about a given subject, write code, explain an infographic, identify defects in products, and more.
With that said, LLMs have significant limitations. One notable limitation is that models are expensive to train and fine-tune, which means customizing large models to specific use cases is prohibitive. As a result, the knowledge on which a model was trained may be stuck in the past or not relevant to your domain.
This is where Retrieval Augmented Generation, or RAG, comes in. With RAG, you can retrieve documents relevant to a question and use the documents in queries to multimodal models. This information can then be used to answer a question.
In this guide, we are going to talk about what RAG is, how it works, and how RAG can be applied in computer vision. Without further ado, let’s get started!
What is Retrieval Augmented Generation (RAG)?
Retrieval Augmented Generation (RAG) is a technique to retrieve context for use in prompting Large Language Models (LLMs) and Large Multimodal Models (LMMs). RAG starts with searching a series of documents that contain text or image files for content that is relevant to a query. Then, you can use the text and/or image context in a prompt. This enables you to ask questions with additional context that is not available to a model.
RAG attempts to solve a fundamental problem with the current generation of LMMs: they are frozen in time. LMMs such as GPT-4 are trained infrequently due to the high capital costs and resources required to train a model. Consequently, it is difficult to train a model for a specific use case, which means many rely on base models such OpenAI’s GPT series.
RAG helps overcome these problems. With the RAG approach to programmatically writing information rich prompts, you can provide contextual information in a prompt. For example, consider an application that uses LMMs to answer questions about software documentation. You could use RAG to identify documents relevant to a question (i.e. “what is {this product}”)? Then, you can include those documents in a prompt, with direction that the documents are context.
With RAG, you can provide documents that:
- Contain your own data;
- Are relevant to a query, and;
- Represent the most up to date information you have.
RAG enables you to supercharge the powers of LMMs. The LMM has a vast body of knowledge while RAG enables you to augment those capabilities with images and text relevant to your use case.
How RAG Works
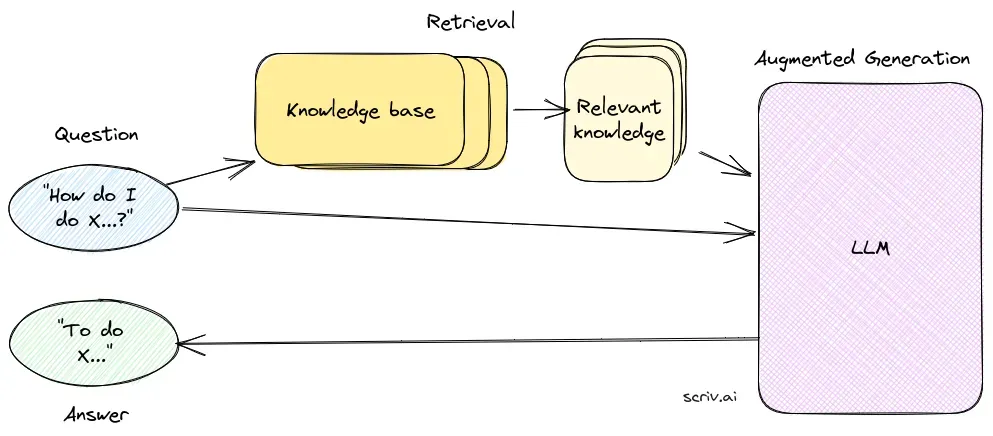
A flow chart showing how RAG works. Image sourced from and owned by Scriv.ai.
At a high level, RAG involves the following steps:
- A user has a question.
- A knowledge base is searched to find context that is relevant to the query.
- The context is added to a prompt that is sent to an LMM.
- The LMM returns a response.
To use RAG, you need to have a database of content to search. In many approaches, a vector database is used, which stores both text or image data (i.e. a page of documentation or an image of a car part) and vectors which can be used to search the database.
Vectors are numeric representations of data which are calculated using a machine learning model. These vectors can be compared to find similar documents. Vector databases enable semantic search, which means you can find documents that are most related to a prompt. For example, you could provide a text query “Toyota” and retrieve images related to that prompt.
To get a feel for how semantic search works in a real application, try querying this dataset in Roboflow Universe to find images.
Next, you need a question from a user or an application. Consider an application that values cars. You could use RAG to search a vector database for images of mint condition car parts that are related to the specific model of car that a user has (i.e. “Toyota Camry car doors”). These images could then be used in a prompt, such as:
“The images below show Toyota Camry car doors. Identify whether any of the images contain scratches or other damage. If an image contains any damage, describe the damage in detail.”
Below the prompt, you would provide reference images from a vector database (the mint condition car parts) and the image that has been submitted by a user or an application (the part that should be valued). If the user submitted an image that contains a scratch, the model should identify the scratch and describe the issue. This could then be used as part of a report reviewed by a person to decide how to value the car, or an automated system.
Using RAG in Computer Vision
Over the years, computer vision has been greatly influenced by developments in the field of natural language processing.
The RAG approach was originally developed for use exclusively for use with text and LLMs. But, a new generation of models are available: LMMs with vision capabilities. These models are able to answer natural language questions with images as references.
With RAG, you can retrieve relevant images for a prompt, enabling you to provide visual information as a reference when asking questions. Microsoft Research published a paper in October 2023 that notes performance improvements when providing reference images in a prompt as opposed to asking a question with no references.
For example, the paper ran a test to read a speed meter. Using GPT-4V with two examples (few-shot learning) resulted in successfully reading the speed meter, a task that GPT-4V could not accomplish with one or no examples.
There are many possibilities to use RAG as part of vision applications. For example, you could use RAG to build a defect detection system that can refer to existing images of defects. Or you could use RAG as part of a logo detection system that can reference existing logos in your database which may be obscure and unknown by an LMM.
You can also use RAG as part of a few-shot labeling system. Consider a scenario where you have 1,000 images of car parts that you want to label to train a fine-tuned model that you can run at the edge, on device. You could use RAG with an existing set of labeled images to provide context for use in labeling the rest of a dataset.
Conclusion
Retrieval Augmented Generation (RAG) helps address the constraint that LMMs are trained in one large training job; they are infrequently retrained, too. With RAG, you can provide relevant contextual information in a prompt that will then be used to answer a question.
RAG involves using a vector database to find information related to a query, then using that information in a prompt.
Traditionally, RAG was used with text data. With the advent and continued development of multimodal models that can use images as inputs, RAG has a myriad of applications in computer vision. With a RAG-based approach, you can retrieve images relevant to a prompt and use them in a query to a model such as GPT-4.
Cite this Post
Use the following entry to cite this post in your research:
James Gallagher. (Nov 16, 2023). What is Retrieval Augmented Generation?. Roboflow Blog: https://blog.roboflow.com/what-is-retrieval-augmented-generation/