
Visual Question Answering (VQA) is a computer vision task that combines image analysis with natural language processing so a model can answer free-form questions about a picture, such as counting objects, identifying relationships, or reading text. Common approaches include attention-based mechanisms and Bayesian methods, with models like Pix2Struct (optimized for documents and interfaces), BLIP-2 (high accuracy with fewer parameters), and GPT-4 with Vision each offering different tradeoffs. Benchmarks like WUPS, METEOR, and BLEU measure how well model answers match ground truth, and datasets like COCO-QA provide structured training and evaluation ground.
Have you ever wondered if computers could not only see but also understand what's in a picture and answer questions about it? That's exactly what the academic Visual Question Answering (VQA) field of research is all about. VQA involves teaching computers to connect the dots between images and language.
This blog post serves as your introduction to the fundamentals of Visual Question Answering, providing insights into its workings and exploring different approaches for its application.
What is VQA?
Picture this scenario: You present the computer with a snapshot of a park and throw a question its way, asking, "How many trees are there?" Now, the computer doesn't just stop at counting the trees in the picture; it goes further by grasping the concept behind "how many."
This undertaking falls within the field of Visual Question Answering, where the computer engages in two critical domains. First off, there's the part where the computer analyzes the picture, identifying and counting the trees, known as computer vision. Then, there's the second aspect where the computer comprehends and responds in a human-like manner, referred to as natural language processing (NLP).
VQA is like training the computer to not only "see" the visual elements but also to "understand" and "speak" about them when prompted with questions.
For example, you could ask questions like:
- How many forklifts are in an image?
- Is there a forklift close to a wooden pallet?
- Do any workers not have hardhats on?
- Does the pictured box have a label?
- Read the text on the pictured label.
Researchers strive to make VQA models that would be able to respond to questions like those above, among many others. If you have a question about an image, a VQA model should be able to understand and process it.
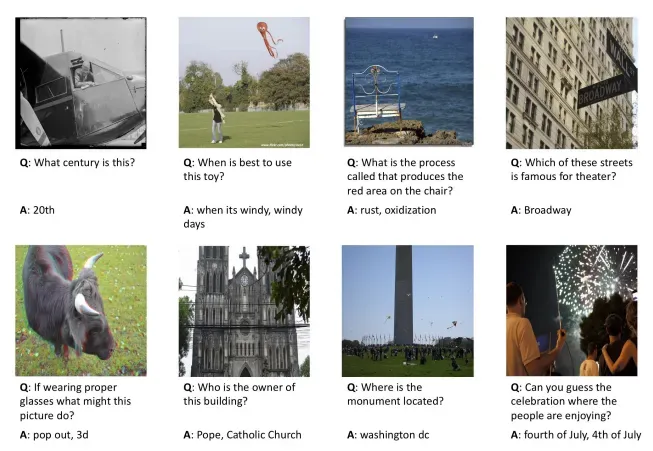
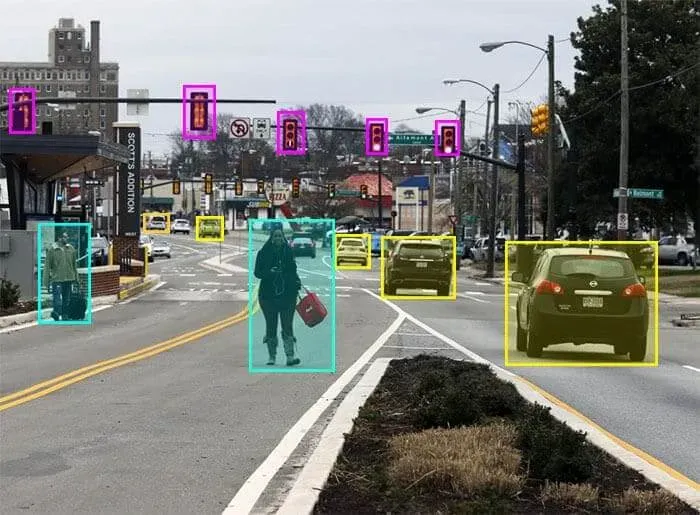
Visual Question Answering examples. Source
Approaches to VQA
Within this section, our exploration will delve into the intricacies of Visual Question Answering. Initially, we will provide an overview of a general approach to VQA, followed by a closer examination of three distinct methodologies: the Bayesian approach, Attention-based mechanisms, and the CLIP model.
How VQA Works
Broadly speaking, the methodologies in VQA can be delineated as follows:
- Extract features from the question
- Extract features from the image
- Combine the features to generate an answer
When it comes to text features, methods like employing Bag-Of-Words (BOW) or utilizing Long Short-Term Memory (LSTM) encoders are viable options. Regarding the image features instead, the commonly favored choice is to use pre-trained Convolutional Neural Networks (CNNs). As for answer generation, the prevalent approach often involves modeling the problem as a classification task.
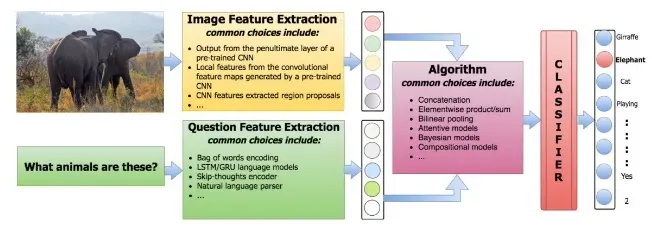
Hence, the primary distinction among various methodologies lies in the manner they integrate textual and image features. For instance, some approaches opt for a straightforward combination through concatenation, followed by input into a linear classifier. Conversely, others employ Bayesian models to deduce the inherent relationships between the feature distributions of the question, image, and answer.
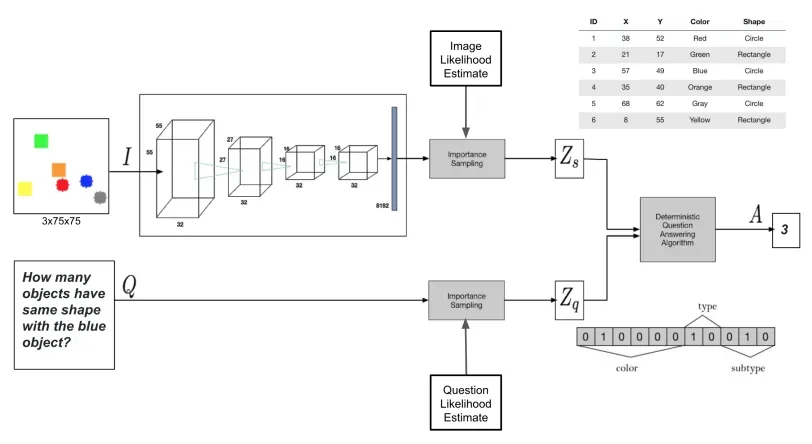
Bayesian Approach
The Bayesian approach introduces a distinctive framework centered on probabilistic VQA modeling. Unlike deterministic methods, Bayesian models assign probabilities to different outcomes, addressing the inherent uncertainties associated with both visual and linguistic domains. This approach incorporates prior knowledge, leveraging pre-existing information about objects, scenes, or relationships within images. By doing so, it provides a more nuanced understanding, allowing the system to make informed decisions based on contextual familiarity.
One key strength of the Bayesian approach is its ability to quantify uncertainty. Instead of offering a singular answer, the model indicates the level of confidence or uncertainty associated with its response. This is particularly valuable in scenarios where the system may encounter ambiguous or complex queries.
Given that VQA involves the integration of visual and textual modalities, Bayesian models excel at inferring relationships between these two elements. The interconnectedness of visual content from images and linguistic content from questions is seamlessly navigated, contributing to a more comprehensive comprehension of the task.
An essential aspect of the Bayesian approach lies in effectively combining information sources. By considering the joint probability distribution of features from both images and questions, the model generates answers that are not only contextually relevant but also reflective of the intricate interplay between different modalities.
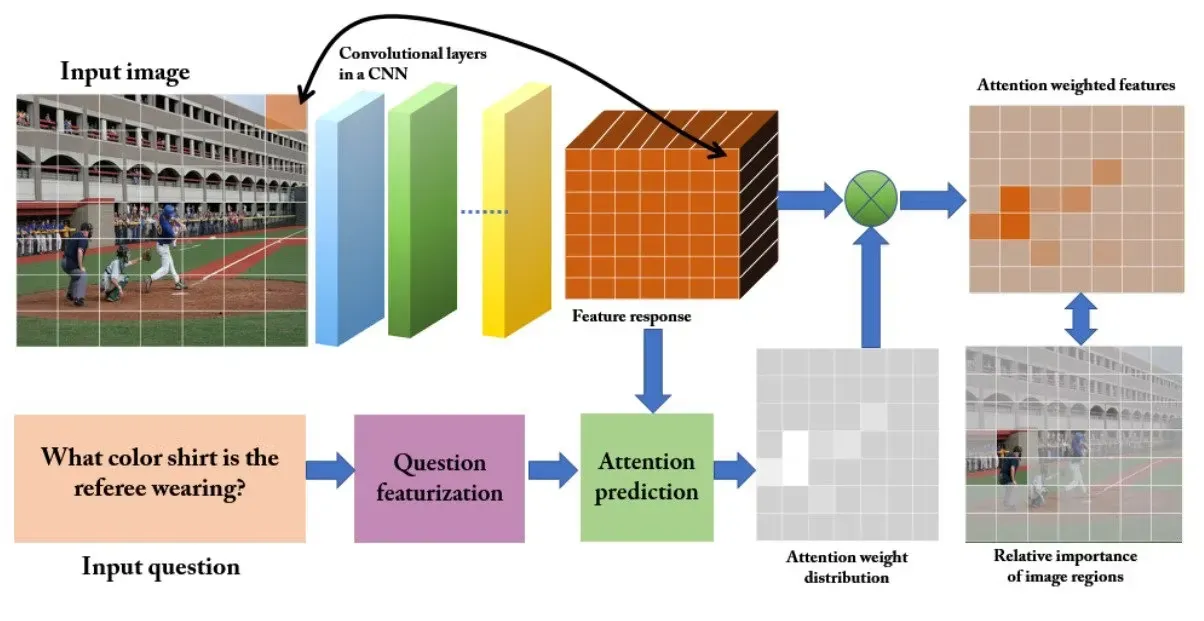
Attention-based approach
Attention-based approaches aim to guide the algorithm's focus towards the most crucial details in the input. Consider a question like "What color shirt is the referee wearing?" In this case, the region of the image containing the main character becomes more relevant than others, just as the words "color", "shirt" and "referee" hold more informative weight compared to the rest.
In Visual Question Answering, the prevalent strategy involves employing spatial attention to generate features specific to regions for training Convolutional Neural Networks. Determining the spatial regions of an image can be accomplished in various ways. One common method entails projecting a grid onto the image. Once applied, the significance of each region is assessed based on the specifics of the question.
Another approach involves the automatic generation of bounding boxes for use in training the model. A bounding box highlights a specific region of interest in an image. By proposing regions, the question is then employed to evaluate the relevance of features for each, allowing for the selective extraction of information necessary to answer the question.
Popular VQA Models
In this section, we are going to describe some common algorithms that perform VQA.
Pix2Struct
Pix2Struct is a deep learning model that tackles visual question answering (VQA) by leveraging the power of image-to-text translation. Pix2Struct is an encoder-decoder transformer model. The encoder part analyzes an image, breaking it down into its visual components. On the other hand, the decoder excels in comprehending and producing textual content.
Here's a deeper dive into how Pix2Struct tackles Visual Question Answering:
- Pre-processing: The input to Pix2Struct for VQA consists of two parts: the image itself and the question as text. Pix2Struct utilizes a technique called "variable-resolution input representation" for the image. This means it doesn't resize the image to a fixed size, but instead breaks it down into smaller patches that can vary in size depending on the image content. The question is kept in its original text format.
- Joint Representation Learning: Unlike many VQA models that process the image and question separately, Pix2Struct takes a unique approach. It presents both the image patches and the question text simultaneously to the encoder. The encoder, a Transformer-based architecture, is adept at processing different types of inputs together: it analyzes the visual information from the image patches and the semantic meaning of the question to create a combined representation.
- Reasoning and Answer Generation: The decoder part of Pix2Struct takes the combined representation from the encoder. By considering both the visual and textual information, the decoder reasons about the answer to the question in the context of the image. It then generates the answer as a sequence of words.
BLIP-2
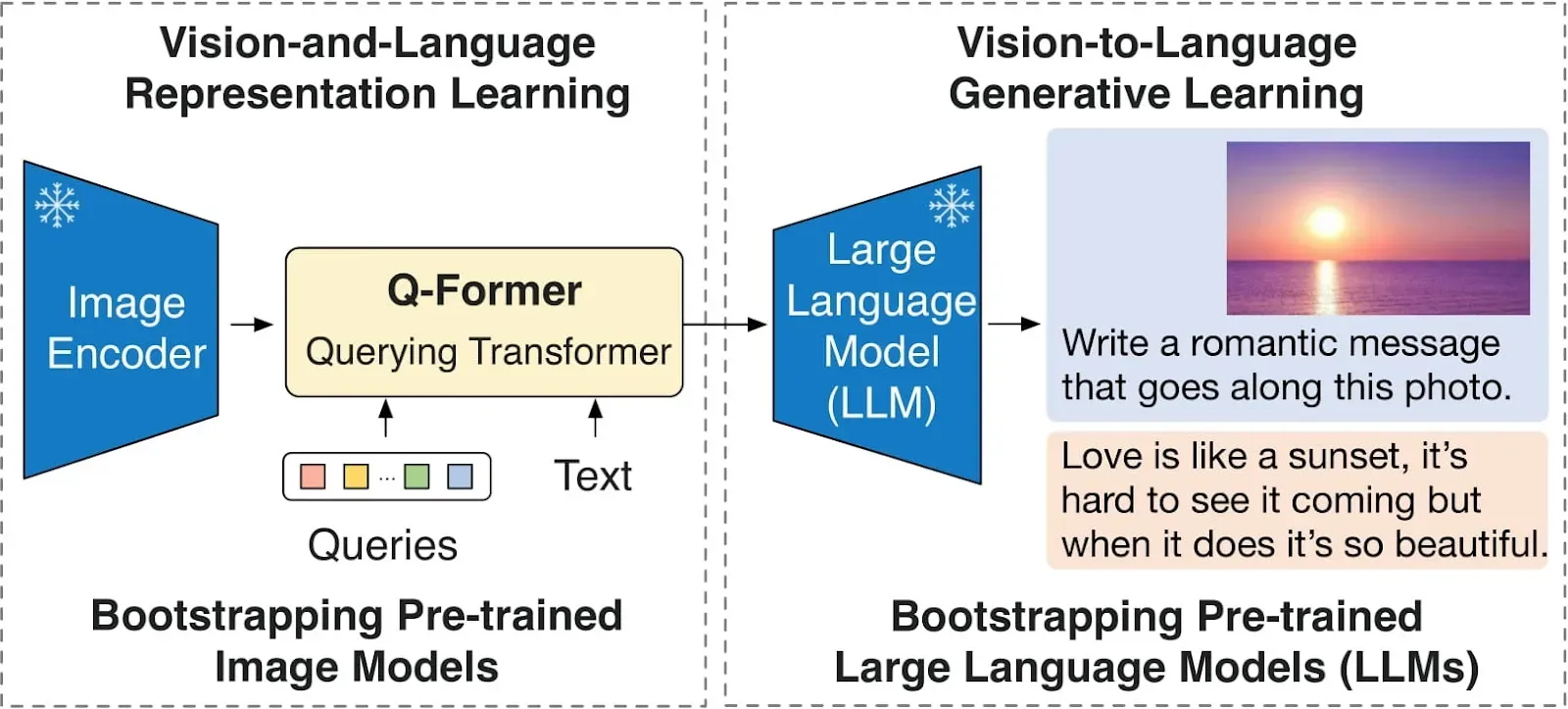
BLIP-2 (Bootstrapping Language-Image Pre-training) is a VQA model that tackles the task with an emphasis on efficiency. Unlike some VQA models that require massive amounts of computational power, BLIP-2 achieves performance comparable to state-of-the-art with a more streamlined approach.
BLIP-2 acts as a bridge between two pre-trained components: a frozen image encoder and a large language model (LLM). The image encoder, though not trainable in BLIP-2, is already adept at extracting visual features from images. The LLM, also pre-trained, brings its expertise in understanding and generating text. The key component in BLIP-2 is a lightweight neural network architecture called the Querying Transformer, or Q-Former for short. This clever model goes through two stages of training:
- Representation Learning: In the first stage, the Q-Former is trained to learn a common language for both the image and text representations. It essentially acts as a translator, learning to convert the visual features from the image encoder into a format that the LLM can understand.
- Generative Learning: Once the Q-Former can translate between the two modalities, it undergoes a second training phase. Here, it focuses on generating text descriptions that accurately reflect the image content. This step further strengthens the connection between visual information and textual understanding.
GPT-4 with Vision
GPT-4 with Vision, often referred to as GPT-4V, is a groundbreaking advancement in VQA.
Unlike traditional VQA models that analyze text and image separately, GPT-4 with Vision operates as a unified system.
GPT-4 with Vision incorporates a powerful text processing component based on the GPT-4 language model, known for its exceptional natural language understanding capabilities. But here's the twist: GPT-V also integrates a vision processing module that allows it to directly analyze visual features within an image.
Here is a breakdown of how GPT-4 with Vision answers questions about images:
- Input Integration: An image and a question are presented as input.
- Joint Representation Learning: GPT-V doesn't process them separately. Instead, it creates a combined representation where the textual information from the question and the visual features from the image are interwoven.
- Reasoning and Answer Generation: Leveraging this rich multimodal representation, GPT-V reasons the answer to the question in the context of the image. It then utilizes its language expertise to generate a comprehensive textual answer.
This ability to process information jointly grants GPT-V several advantages: by considering both visual and textual cues simultaneously, GPT-V gains a richer understanding of the context behind a question. This deeper understanding allows GPT-V to generate more accurate and natural language answers compared to models relying solely on separate processing.
Other multimodal language models like Claude 3 Opus by Anthropic, CogVLM (open source), and Gemini by Google, are also capable of visual question answering.
VQA Evaluation Metrics
In computer vision and language processing tasks, the most commonly-used benchmark is traditional accuracy. While this suffices for many task types, it tends to not be ideal for open-ended answers such as those returned by VQA models.
Consider, for instance, if the correct answer is "oak tree," should the response "tree" be considered entirely incorrect? Similarly, when faced with the query "What animals appear in the image?" and the image depicts dogs, cats, and rabbits, how inaccurate should we view the response "cats and dogs"?
These intricate challenges demand thoughtful consideration to ensure a meticulous evaluation of diverse approaches in VQA.
Let's explore some commonly utilized metrics.
WUPS measure
The WUPS measure estimates the semantic distance between an answer and the ground truth, yielding a value between 0 and 1. Utilizing WordNet, it computes similarity by considering the semantic tree distance of terms shared between the answer and the ground truth. To counter the tendency to assign relatively high values to disconnected terms, the authors suggest scaling down scores below 0.9 by a factor of 0.1.
METEOR and BLEU measure
METEOR, drawing inspiration from machine translation, assesses the quality of generated answers by considering precision, recall, and penalty terms. BLEU, originally designed for translation evaluation, has found application in VQA by measuring the similarity between the generated and reference answers based on n-grams.
VQA Datasets
Like many task types in natural language processing and computer vision, there are several open VQA datasets you can use in training and evaluating VQA models.
The complexity of the Visual Question Answering field necessitates datasets that are sufficiently expansive to encompass the vast array of possibilities inherent in questions and image content within real-world scenarios. Many of these datasets incorporate images from the Microsoft Common Objects in Context (COCO), featuring 328,000 images with 91 types of objects easily recognizable by a 4-year-old, totaling 2.5 million labeled instances.
Let's see some of the available datasets.
COCO-QA dataset
The COCO-QA dataset comprises 123,287 images sourced from the COCO dataset, with 78,736 training and 38,948 testing Question-Answer (QA) pairs. To generate this extensive set of QA pairs, the authors employed an NLP algorithm, which automatically derived questions from COCO image captions. For instance, given a caption like "Two chairs in a room," a question such as "How many chairs are there?" would be generated. It's important to note that all the answers are limited to a single word.
However, this approach has some drawbacks: the questions are subject to the inherent limitations of NLP, resulting in instances where they are oddly formulated, contain grammatical errors, or are, in some cases, entirely incomprehensible.
DAQUAR dataset
DAQUAR dataset encompasses 6,794 training and 5,674 test question-answer pairs, derived from images within the NYU-Depth V2 Dataset. This results in an average of approximately 9 pairs per image.
While DAQUAR represents a commendable effort, the NYU dataset is limited to indoor scenes, occasionally featuring challenging lighting conditions that pose difficulties in answering questions.
Visual QA dataset
In comparison to other datasets, the Visual QA dataset is considerably larger. It encompasses 204,721 images sourced from the COCO dataset and incorporates an additional 50,000 abstract cartoon images. Each image is associated with three questions, and each question has ten corresponding answers, resulting in over 760,000 questions with approximately 10 million answers.
The generation process involved a team of researchers from Amazon creating the questions and another team crafted the answers. Despite careful considerations in the dataset design, such as including popular answers to heighten the challenge of inferring question types from answer sets, certain issues have surfaced. Notably, some questions prove too subjective to have a single correct answer. In such cases, a most likely answer may be provided.
Conclusion
Being able to ask a question about an image to a computer and retrieve a coherent answer is no longer science fiction. Pioneering models like Pix2Struct, BLIP-2, and GPT-V have taken our strides forward.
Pix2Struct's approach opens doors for documents and interfaces. BLIP-2 demonstrates impressive efficiency, achieving top results with less. GPT-V, a game-changer, processes both image and text together, leading to a deeper understanding of visuals. VQA holds immense potential to transform how computers interact with visuals.
Cite this Post
Use the following entry to cite this post in your research:
Petru P.. (Mar 13, 2024). What is Visual Question Answering (VQA)?. Roboflow Blog: https://blog.roboflow.com/what-is-vqa/