
YOLO-World is a zero-shot object detection model that accepts arbitrary text prompts rather than a fixed class list, which means prompt wording and confidence thresholds need careful tuning. This post covers six practical techniques: lowering confidence thresholds well below typical values, adding null classes to reduce false positives, using two-stage workflows, incorporating color and size descriptors, and filtering predictions by area in post-processing. It also notes current limitations, including weak spatial reasoning and inconsistent prompt performance across different production environments.
YOLO-World is a state-of-the-art, zero-shot object detection model. You can provide arbitrary text prompts to YOLO-World and ask the model to identify instances of those objects in an image, without any fine-tuning. There is no predefined list of classes; you need to try different prompts to see if the model can identify objects to an acceptable standard for your project.
In this guide, we are going to share five tips we have learned after experimenting extensively with YOLO-World. By the end of this guide, you will have tangible knowledge you can apply to more effectively identify objects with YOLO-World.
Without further ado, let’s get started!
YOLO-World Prompting Tips
Drop the Confidence
For most popular computer vision models, a confidence value above 80% generally represents “high confidence”. YOLO World does not follow this trend. You can expect confidence values as low as 5%, 1%, or even 0.1% to produce valid predictions.

While it would be normal to filter out all predictions under 80% for other popular models (like YOLOv8), YOLO World accurately predicts the doorknobs in this image with confidence levels between 23% and 35%.

Because YOLO World was trained on Microsoft COCO, confidence levels for COCO classes are much higher than other classes. In the example above, hair dryer (which is a class in COCO) has a confidence of 21% while many of the other objects have confidence under 10% or even 1%. To ensure each class is predicted correctly, varying confidence intervals at the class level is important. Setting a confidence of 15% would ensure we don’t see the false positive for hair dryer on the right side of the image, but almost all of the moisturizer class would not be detected.
Add Null Classes
A null class is a class which you are not interested in, but ask a model to detect because it improves performance of a class which you care about. As an example, let’s try to use YOLO World to detect a license plate.

Oops! The model is predicting the object we care about (the license plate), but it is falsely detecting the car as a license plate. In cases where you observe a secondary object being falsely detected as the object of interest, it is often useful to add the secondary object as a class. See what happens when car is added as a class.

Fixed! Even though we aren’t necessarily interested in the location of the car, calling it as a class prevented the false prediction for the object we do care about, license plate.
Use Two-Stage Workflows
A two-stage workflow chains models together, where the output of the first stage model is the input of the second stage model. As an example, let’s try to detect people’s eyes in a crowd.

We miss many eyes, even when setting a low 0.3% confidence threshold. To improve performance, we can use a two-stage workflow with the following steps:
- Detect faces.
- For each face, crop and detect eyes.
Here’s how it works:

First, we detect all of the faces. Note how we found many more faces than sets of eyeballs. This is because faces are larger objects and therefore easier to detect. Now, let’s crop these predictions and run the second-stage eyeball model:

Not too bad! We’ve picked out several eyes that our initial model missed. Interestingly, in all of these cases there is an eyeball detection that takes up almost the entire area of the image. This is a common error associated with YOLO World (which we’ll discuss later in this blog).
Take Advantage of Color

YOLO World has a strong sense of color. In the above example, it is able to differentiate between green and red strawberries. Even the one false positive (on the bottom-left) is the “reddest” of the green strawberries. Again, we see the same error as the previous example where a large and high-confidence green strawberry prediction takes up most of the screen.

Take the above image of a FIRST Robotics competition, which shows blue and red teams competing over neutral yellow objectives. In cases where the objects being detected are novel and unlikely to be detected with other prompts, a strong sense of color is critical.
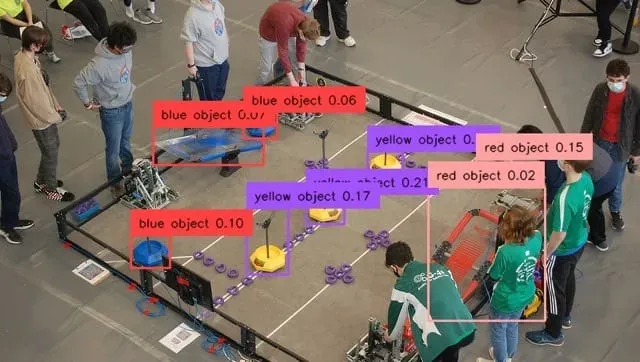
We can detect these objects easily using a simple color query without focusing on the actual object itself. This method is useful in any case where normal descriptive prompts fail.
Use Words that Describe Size

In this image, we are querying YOLO World for two classes: cookie and metal filing. Even at low confidence, the metal defect is not detected.
Here is the same image at the same confidence level, but we use the prompt small metal filing.

Now the defect is detected!
Post-Processing Improvements
There are some peculiarities of YOLO World that can not be solved by prompting alone. In the examples so far, we’ve already seen a couple. This section outlines these peculiarities and methods for dealing with them.
Vary Confidence per Class
As we saw in the hair dryer example, different classes can have different ideal confidence thresholds on the same image. Unlike other popular object detection models, these zones can differ significantly.
For instance, the prompt person might have the best results above 70% confidence, but blue helicopter might have the best results above 0.5%. If you try to apply the same confidence threshold for both classes, you will either see false positives for person or false negatives for blue helicopter.
As a solution, we recommend filtering predictions with unique class-level confidence thresholds. This ensures
Filter Predictions by Size
One of the more frustrating challenges with YOLO World is that it often predicts groups of objects in addition to isolating individual objects. To make things worse, these group predictions often have high confidence and therefore cannot be filtered by traditional methods.
As a solution, we recommend filtering out predictions that have an area greater than a certain percentage of the entire image. This value should differ class-to-class, and perhaps not apply to certain classes which you expect to fill an entire image.
Challenges
Spatial Prompts


YOLO World does not know left from right, and struggles with other directional references. You may need to resort to other methods (like post-processing) if you are trying to detect the interaction, movement, or rotation of different objects in an image.
Varying Performance Across Contexts
YOLO World is impressive in that, for a given image, you can often find a combination of prompts and parameters that produce an accurate result.
However, early tests suggest that it is more difficult to find prompts that hold up across various environments and contexts. Because the ideal confidence threshold can vary image-to-image, one prompt that works on example images may not work on the entire corpus of production data.
In cases where you find yourself changing prompt and parameter setting in different environments, it is probably best to use YOLO World outputs to train a custom model which will generalize better across settings.
Cite this Post
Use the following entry to cite this post in your research:
Jacob Witt. (Feb 23, 2024). Tips and Tricks for Prompting YOLO World. Roboflow Blog: https://blog.roboflow.com/yolo-world-prompting-tips/