
4M: Massively Multimodal Masked Modeling, released by Apple in 2024, is a leap forward in the field of multimodal machine learning. This model, building upon the growing capabilities of large language models, addresses critical challenges in vision models which have traditionally been highly specialized and limited to a single modality and task.
The 4M architecture introduces a multimodal training scheme that leverages a unified Transformer encoder-decoder with a masked modeling objective across diverse input/output modalities such as text, images, geometric, and semantic data, as well as neural network feature maps.
This approach achieves scalability by mapping all modalities into discrete tokens and performing multimodal masked modeling on a small randomized subset of these tokens. As a result, 4M can seamlessly handle a broad spectrum of vision tasks, excel in fine-tuning for unseen tasks or new input modalities, and function as a generative model conditioned on arbitrary modalities.
In this blog post, we will delve into the mechanics of 4M, exploring its architecture and examining its impact on multimodal learning and computer vision.
What is 4M?
4M, short for Massively Multimodal Masked Modeling, is a framework designed to address the limitations of current vision models by leveraging the capabilities of large language models. Unlike traditional vision models that are often restricted to single modalities and tasks, 4M aims to create a versatile, scalable model capable of handling multiple input and output modalities, such as text, images, 3D data, and more.
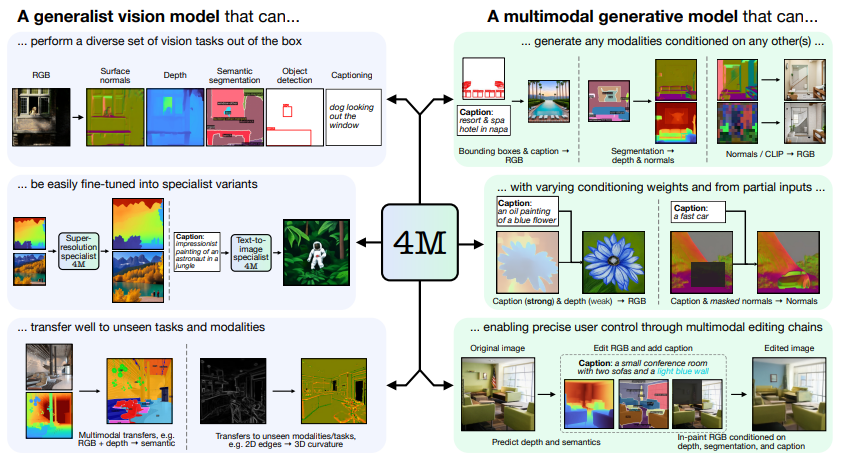
The power of 4M lies in its multimodal training scheme, which involves using a single unified Transformer encoder-decoder. This model is trained with a multimodal masked modeling objective, which allows it to learn rich, shared representations across various modalities.
By mapping different types of data into discrete tokens using modality-specific tokenizers, 4M ensures compatibility and scalability without the need for separate task-specific encoders and heads. 4M achieves efficiency through strategic input and target masking, where only a small subset of tokens from all modalities is selected as inputs, and another small subset is designated as targets.
This approach prevents computational costs from escalating as the number of modalities increases, ensuring scalable training.
How does 4M work?
The 4M architecture and training objective were designed to ensure compatibility and scalability across various modalities while maintaining conceptual simplicity and computational efficiency. This is achieved by converting all modalities, including images, text, sparse data, and neural network feature maps, into sequences or sets of discrete tokens. This abstraction enables seamless mapping between different modalities by treating the prediction of one set of tokens from another in a unified manner.
Traditional tasks in vision, NLP, and other domains typically require different modeling choices, architectures, and loss functions, making joint training across multiple modalities challenging. By tokenizing all modalities into a unified representation space, 4M allows for the training of a single Transformer encoder-decoder to map between various modalities through token prediction.
Transformers have demonstrated scalability with data and model size across diverse tasks, particularly when paired with a scalable pre-training objective such as masked reconstruction. 4M leverages a multimodal masked modeling objective, training on randomized subsets of tokens to develop robust cross-modal predictive coding abilities.
4M Multimodal Training Scheme
Pre-training Modalities
The 4M model is trained on a diverse range of modalities including RGB, captions, depth, surface normals, semantic segmentation maps, bounding boxes, and tokenized CLIP feature maps. These modalities were selected to encompass various critical aspects.
Firstly, they combine semantic information (captions, semantic segmentation, bounding boxes, CLIP) with geometric data (depth, surface normals) and RGB images. When used as input modalities, they provide valuable priors about scene geometry and semantic content. They help to steer the types of representations the model learns when used as target tasks.
Secondly, these modalities vary in the format they use to encode information, comprising dense visual data (RGB, depth, surface normals, semantic segmentation), sparse or sequence-based data (captions, bounding boxes), and neural network feature maps (CLIP). This diversity facilitates rich interactions with the model for generative purposes, enabling semantically conditioned generation through captions, segmentation maps, and bounding boxes, and grounding generation on 3D information through geometric modalities.
The versatility of 4M in handling various modalities and benefiting from cross-modal training underscores its potential to extend to even more modalities.
Pseudo-labeled Multimodal Training Dataset
Training 4M requires a large, diverse, and aligned multimodal/multitask dataset encompassing all the pre-training modalities. However, most existing multimodal datasets either lack some of these modalities, are too small or lack diversity.
To address this, pseudo-labeling is employed on the publicly available Conceptual Captions 12M (CC12M) dataset, leveraging powerful off-the-shelf models to create a binding dataset. This approach only requires access to a dataset of RGB images, making it scalable to even larger web-scale image datasets.
Tokenization
Each modality is converted into sets or sequences of discrete tokens using modality-specific tokenizers. Captions and bounding boxes are treated as text and encoded with WordPiece.

For bounding boxes, Pix2Seq approach is used, turning object detection into a sequence prediction task. RGB, depth, normals, semantic segmentation maps, and CLIP feature maps are tokenized using learned vector quantized autoencoders (VQ-VAE).
Unlike Unified-IO, which uses an RGB pre-trained VQ-GAN for all image-like modalities, modality-specific tokenizers are utilized. This method allows us to include neural network feature maps that are challenging to represent with existing image tokenizers. Although tokenizing modalities introduce a small computational overhead during inference, this overhead is avoided during pre-training by pre-computing the tokens when assembling our multimodal dataset.
4M Model Architecture
The 4M architecture is focuses on efficiency, scalability, and simplicity. It largely follows the design of a standard Transformer encoder-decoder but includes several key modifications to support the joint modeling of diverse modalities such as RGB images, semantic segmentation, captions, and bounding boxes.

Multimodal Encoder
The encoder is essentially a standard Transformer encoder but includes modality-specific learnable input embedding layers that convert token indices into vectors. Each token from a specific modality receives a learnable modality embedding and sine-cosine positional embeddings, either 1D for sequences or 2D for dense modalities. To enhance transfer learning capabilities, the encoder can also process RGB pixels using a learnable patch-wise linear projection, allowing it to function as a Vision Transformer backbone.
Multimodal Decoder
The decoder is designed to handle tokens from both dense image-like and sequence-like modalities, with a different approach for each. However, there are two common features: all tokens can attend to any encoder tokens in the cross-attention layers, ensuring access to all encoded information, and attention masks are used to separate decoder tokens of different modalities, ensuring consistency in outputs.
For dense image-like modalities, the decoder inputs are mask tokens along with modality and positional information, and the decoder predicts the masked content. For sequence-like modalities, the inputs include modality, positional, and content information, and the decoder predicts the next token in the sequence using a causal mask to ensure tokens are only influenced by preceding tokens. Cross-entropy loss is applied to all target tasks, removing the need for task-specific loss balancing and improving training stability.
Input and Target Masking
Efficient training on multiple modalities is achieved by encoding only a small set of visible tokens when performing masked image modeling, significantly reducing computational costs. However, the disparity between the low number of input tokens and the higher number of target tokens can increase computational costs in the decoder.
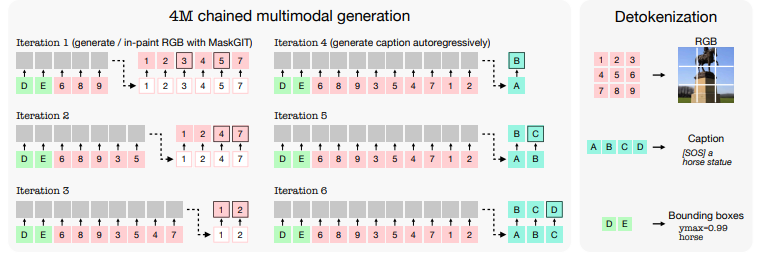
To address this, 4M uses target masking, decoding only a randomly sampled subset of masked-out tokens. By fixing the number of input and target tokens, 4M maintains low training costs while supporting pre-training on many modalities. Input tokens per modality are sampled using a symmetric Dirichlet distribution, and the same approach is used for target tokens. Dense modality tokens are sampled uniformly at random, and span masking is applied to sequence modalities.
4M Model Performance Benchmarks and Comparison

4M excels in transferring to various downstream tasks, outperforming baseline models in detection, segmentation, and depth estimation.
Although 4M is outperformed by more specialized models like DeiT III on ImageNet-1K, it proves to be a highly versatile vision model that greatly benefits from pre-training on multiple pseudo-labeled tasks. Preliminary tests with a larger 4M-XL model, which has 2.7 billion parameters, revealed overfitting to the pseudo-labeled CC12M dataset, resulting in limited additional improvements on downstream tasks. This suggests that a larger dataset or data augmentations are needed to fully leverage the potential of larger 4M models.
Conclusion
4M is a versatile framework for training multimodal and multitask models, achieving high performance across various vision tasks and showing robust transfer to diverse downstream applications.
The model excels in tasks such as in-painting and any-to-any generation, enabling extensive editing capabilities with a single model. Enhancing 4M with additional modalities like edges, sketches, human poses, videos, or multi-view imagery further enriches its capabilities in spatial-temporal generation. Improved tokenizers and training on larger, higher-quality datasets also contribute significantly to enhancing performance and the quality of generated outputs.
Cite this Post
Use the following entry to cite this post in your research:
Petru P.. (Jul 9, 2024). What is 4M? Apple's Massively Multimodal Masked Modeling. Roboflow Blog: https://blog.roboflow.com/4m-massively-multimodal-masked-modeling-apple/